接上篇继续:
Python零基础-中【详细】-CSDN博客
目录
十七、网络编程
1、初识socket
(1)socket理解
(2)图解socket
(3)戏说socket
(4)网络服务
(5)通信协议
2、基于UDP实现客户端与服务端通信
(1)使用socket开发的基本格式
(2)基于UDP开发服务端
(3)基于UDP开发客户端
3、基于TCP实现客户端与服务端通信
(1)基于TCP实现客户端与服务端
# 服务端实现
# 客户端实现
(2)通信改进
# 服务端实现
# 客户端实现
4、使用requests模块发生http请求
(1)安装requests模块
(2)使用requests模块发送get请求
十八、多进程与多线程
1、线程与进程的区别
(1)概念
(2)区别与联系
2、python中的多线程
(1)多线程的使用场景
(2)如何新建线程
(3)使用_thread模块创建线程
(4)使用threading创建线程
# 方式1
# 方式2
3、线程的状态及其转换
4、不可忽略的线程安全性问题
5、多进程
十九、正则表达式
1、正则表达式理解
(1)正则表达式理解
(2)正则表达式作用
(3)正则表达式特点
(4)python中使用正则表达式
# findall方法
# match方法
# search方法
2、元字符
(1)元字符理解
(2)元字符参考表
3、使用正则表达式匹配单一字符
(1)元字符参考表
(2)相关ASCII表
(3)使用正则,匹配字符串中所有的数字
(4)使用正则,匹配字符串中所有的非数字
(5)使用正则匹配换页符
(6)使用正则,匹配换行符
(7)使用正则,匹配回车符
4、正则表达式之重复出现数量匹配
(1)匹配0次到无限次
(2)匹配一次或多次
(3)匹配零次或一次
(4)匹配n次
(5)匹配至少n次
(6)匹配n次以上,m次以下
5、使用正则表达式匹配字符集
6、正则表达式之边界匹配
(1)匹配整个字符串开头
(2)匹配整个字符串的结尾位置
(3)匹配单词开头
7、正则表达式之组
(1)组的理解
(2)简单使用
(3)命名组
(4)命名组使用
8、正则表达式之贪婪与非贪婪
(1)理解
(2)应用
二十、实战之原生互联网爬虫
1、爬虫的道德与法律
2、爬虫之robots协议
(1)robots协议理解
(2)robots协议主要功能
(3)robots协议的写法
(4)解读robots协议(以小米官网为例)
3、爬虫的主要作用及其实现思路
(1)爬虫的作用
(2)实现思路
(3)爬虫五大件
4、爬虫网络环境搭建
(1)Hbuilder环境搭建
(2)爬虫应用
5、爬虫之抓取电商数据
(1)分析实现思路
(2)编写代码
# 定义结果类
# 编写主代码
十七、网络编程
1、初识socket
(1)socket理解
官方定义:套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信,网络套接字是IP地址与端口的组合。
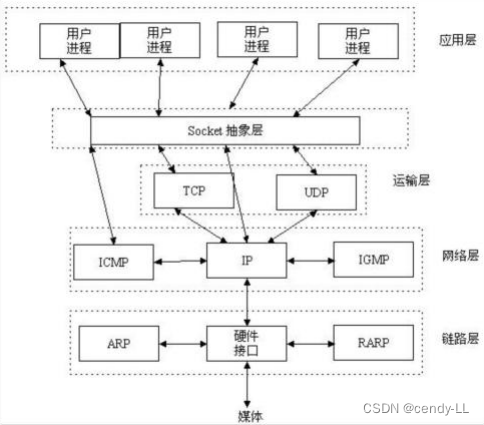
(2)图解socket
socket是一个接口,在用户进程与TCP/IP协议之间充当中间人,完成TCP/IP协议的书写,用户只需理解接口即可
(3)戏说socket
以打电话为例:
要想打通一个电话,背后涉及到非常复杂的技术,包括但不限于手机与基站之间通信、将电信号转换成声音等,但是作为用户,我们是否需要知道这些技术如何实现,打电话时我又是否需要自己去实现这些非常复杂的东西?显然是不用的。我们只要拿起手机,按下号码和拨号键,便能与想通信的人通信。
同理,socket也是充当类似的角色,tcp、ip背后的通信机制也是非常复杂,这个时候用户并不需要理解或者实现这些东西,这些都由socket去处理了,用户所要做的,就是针对socket提供的接口去进行对应的处理(类似于拿起手机,按下号码和拨号键),就能实现网络通信了。
打电话需要以下的步骤:
- 确定对方的手机号
- 拨打
- 对方接通
- 开始通话
- 话结束后,双方挂断
(4)网络服务
在python里面,提供了两个级别访问的网络服务
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
- 高级别的网络服务模块 SocketServer,它提供了服务器中心类,可以简化网络服务器的开发。
(5)通信协议
通信协议可分为TCP、UDP
- TCP(Transmission Control Protocol传输控制协议)是一种面向连接的,可靠的,基于字节流的传输通信协议。
- UDP(User Data Protocol,用户数据报协议)是无连接的,即发送数据之前不需要建立连接,UDP尽最大努力交付,即不保证可靠交付(类似于发短信,我只管发,能不能接受到跟我关系不大)
2、基于UDP实现客户端与服务端通信
(1)使用socket开发的基本格式
socket.socket(family,type,proto)- family: 套接字家族,可以使用AF_UNIX或者AF_INET
- type: 套接字类型可以根据是面向连接(TCP)的还是非连接分(UDP)为 SOCK_STREAM 或 SOCK_DGRAM
- protocol: 一般不填默认为0
AF_INET需经过多个协议层的编解码,消耗系统cpu,并且数据传输需要经过网卡,受到网卡带宽的限制。AF_UNIX数据到达内核缓冲区后,由内核根据指定路径名找到接收方socket对应的内核缓冲区,直接将数据拷贝过去,不经过协议层编解码,节省系统cpu,并且不经过网卡,因此不受网卡带宽的限制,AF_UNIX的传输速率远远大于AF_INET。
AF_INET不仅可以用作本机的跨进程通信,同样的可以用于不同机器之间的通信,其就是为了在不同机器之间进行网络互联传递数据而生。而AF_UNIX则只能用于本机内进程之间的通信。
(2)基于UDP开发服务端
import socket# 接收方要有手机,并且开机
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server.bind(("127.0.0.1", 8888))
print("UDP 服务端启动")# 开机之后一直等着我跟他通信
while True:# 接收到信息,信息里面包括客户端发送的内容以及客户端的信息(ip,端口)data, client = server.recvfrom(1024)print("接受到客户端发来的消息:", data.decode('utf-8'))server.sendto("您好,这是服务端".encode("utf-8"), client)
(3)基于UDP开发客户端
import socket# 同样的,要有手机
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 有对方的号码(ip,端口)
client.sendto("您好,我是客户端".encode('utf-8'), ("127.0.0.1", 8888))
# 接受服务端的响应
data, server = client.recvfrom(1024)
print(data.decode("utf-8"))
client.close()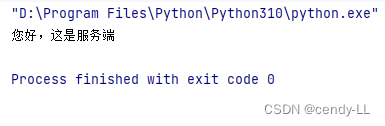
3、基于TCP实现客户端与服务端通信
(1)基于TCP实现客户端与服务端
# 服务端实现
import socketserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("127.0.0.1", 8888))
server.listen(5)
print("服务端已经启动,等待客户端连接======》")
client, address = server.accept()
print("已经建立连接")
data = client.recv(1024)
print("服务端接收到的数据:", data.decode("utf-8"))
print("请输入回复的内容:")
client.send(input().encode("utf-8"))
server.close()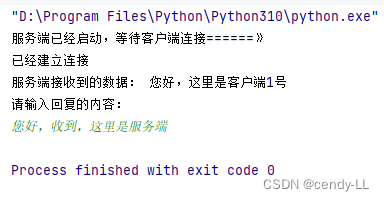
# 客户端实现
import socketclient = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(("127.0.0.1", 8888))
print("客户端已启动,已完成连接")
print("请输入要发送的内容:")
client.send(input().encode("utf-8"))
data = client.recv(1024)
print("接收到服务端的响应:", data.decode("utf-8"))
client.close()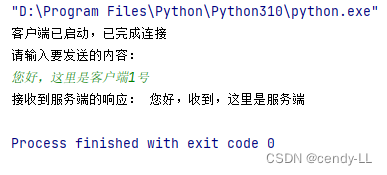
(2)通信改进
修改上面的程序,使客户端可以和服务端聊天,直到客户端发送close内容,则关闭双方通信
# 服务端实现
import socketserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("127.0.0.1", 9999))
# 同一时刻 ,允许多少客户端跟我通信
server.listen(5)
print("服务端已启动,等待客户端连接=======》")
client, address = server.accept()
print("客户端已经连接")while True:recv = client.recv(1024)msg = recv.decode("utf-8")if msg == "close":print("服务端关闭=======》")server.close()breakprint("客户端发送的内容:", msg)print("请输入回复内容:")client.send(input().encode("utf-8"))
# 客户端实现
import socket# 要有手机
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 拨打电话
client.connect(("127.0.0.1", 9999))# 通话
while True:print("请输入要发送的内容:")send_data = input()client.send(send_data.encode("utf-8"))if send_data == "close":client.close()print("关闭连接")breakdata = client.recv(1024).decode("utf-8")print("接受到服务端响应:", data)
4、使用requests模块发生http请求
(1)安装requests模块
如果标红,则直接点击提示安装即可
(2)使用requests模块发送get请求
import requestsresult = requests.get("")
text = result.content
print(text.decode('utf-8'))十八、多进程与多线程
1、线程与进程的区别
(1)概念
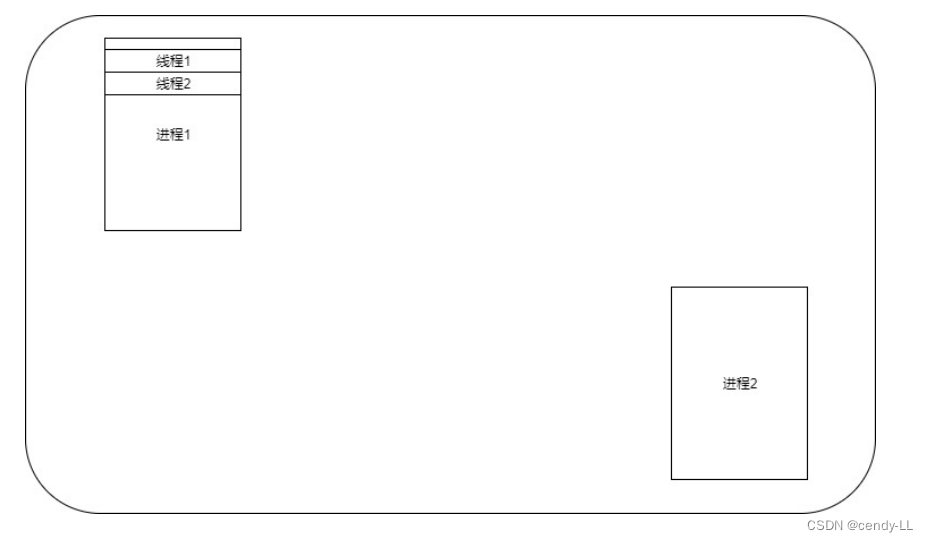
进程:是系统理资源的基本单位进行分配和管
线程:进程的一个执行单元,是进程内调度的实体、是CPU调度和分派的基本单位,是比进程更小的独立运行的基本单位。线程也被称为轻量级进程,线程是程序执行的最小单位
(2)区别与联系
一个程序至少一个进程,一个进程至少一个线程(至少会有一个主线程)
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵,而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式进行,如何处理好同步与互斥是编写多线程程序的难点
多进程程序更健壮,进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响;而线程只是一个进程中的不同执行路径,线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,所以可能一个线程出现问题,进而导致整个程序出现问题
2、python中的多线程
(1)多线程的使用场景
- 把占用时间的操作放后台处理
- 提升用户体验
- 加快程序运行速度
(2)如何新建线程
在python3之前的版本,可以使用thread、threading 两个模块新建线程
在python3中,可以可以使用_thread、threading 两个模块新建线程,thread 模块已被废弃,为了兼容性,Python3 将 thread 重命名为 "_thread"
threading是高级模块,对_thread进行了封装,所以在平常的开发中,更加推荐使用threading模块
(3)使用_thread模块创建线程
基本语法:
_thread.start_new_thread(函数, 函数入参)示例:
import _thread
import time# 为线程定义一个函数
def print_name(thread_name):count = 0while count < 5:time.sleep(1)count += 1print(thread_name)_thread.start_new_thread(print_name, ("Thread-1",))
_thread.start_new_thread(print_name, ("Thread-2",))while 1:pass
(4)使用threading创建线程
# 方式1
基本语法:
threading.Thread(group=None, target=None, name=None,args=(), kwargs=None, *, daemon=None)参数说明:
- group:在当前的版本保持为None,不要进行修改
- target: 这个线程要干的活(函数)
- name: 线程名
- args: 上面target参数的入参(),tuple类型,对应taget参数中的可变参数
- kwargs:上面target参数的入参,dict类型,对应taget参数中的关键字参数
示例:
import threadingdef my_fun():print("Hello world")threading.Thread(target=my_fun).start()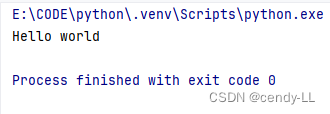
# 方式2
除了直接使用threading.Thread的方式创建线程之外,也可以直接通过继承
import threadingclass MyThread(threading.Thread):def run(self):print("hello world")thread = MyThread()
thread.start()
3、线程的状态及其转换

4、不可忽略的线程安全性问题
下面的程序,多次运行得到的结果都不太一样
import threadingclass MyThread(threading.Thread):sum = 0def run(self):for i in range(1000000):MyThread.sum += 1thread = MyThread()
thread2 = MyThread()
thread3 = MyThread()
thread.start()
thread2.start()
thread3.start()
thread.join()
thread2.join()
thread3.join()print(MyThread.sum)
线程安全性问题的三要素:
- 多线程环境下
- 共享变量
- 并发对共享变量进行修改
如何解决线程安全性问题
- 单线程化
- 不要共享变量
- 对共享变量的操作串行化
前面两个条件在现实开发中相对不可取,那么就剩下第三个--将并发修改串行化,这个时候就要使用到锁
import threadingclass MyThread(threading.Thread):sum = 0lock = threading.Lock()def run(self):with MyThread.lock:for i in range(1000000):MyThread.sum += 1thread = MyThread()
thread2 = MyThread()
thread3 = MyThread()
thread.start()
thread2.start()
thread3.start()
thread.join()
thread2.join()
thread3.join()print(MyThread.sum)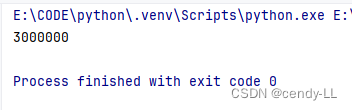
5、多进程
多进程使用Multiprocessing 模块,总体的使用跟多线程差不多
# 为线程定义一个函数
import multiprocessing
import timedef print_name(thread_name):count = 0while count < 5:time.sleep(1)count += 1print(thread_name)if __name__ == "__main__":process = multiprocessing.Process(target=print_name, args=("多进程",))process.start()process.join()
十九、正则表达式
1、正则表达式理解
(1)正则表达式理解
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念
(2)正则表达式作用
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串,在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本
(3)正则表达式特点
- 灵活性、逻辑性和功能性非常强
- 可以迅速地用极简单的方式达到字符串的复杂控制
(4)python中使用正则表达式
# findall方法
python中,要使用正则表达式,需要导入re模块,基本格式如下:
re.findall(pattern, string, flags=0)参数说明如下:
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
flags可选值如下:
| 可选值 | 描述 |
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据 Unicode 字符集解析字符,这个标志影响 \w \W \b \B |
| re.X | 该标志通过给予更灵活的格式以便将正则表达式写的更易于理解 |
简单使用:
import restr = "hell0,my name is cendy"result = re.findall("cendy", str)
print(result)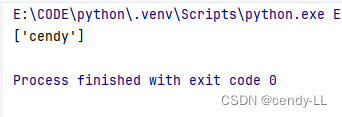
# match方法
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回 none
import res = 'hello world'
result = re.match('hello', s)
print(result.group(0))
要获取匹配的结果,可以使用group(n);匹配结果有多个的时候,n从0开始递增,当匹配结果有多个的时候,也可以使用groups()一次性获取所有匹配的结果
# search方法
re.search 扫描整个字符串并返回第一个成功的匹配
import res = 'hello world hello'
result = re.search('hello', s)
print(result.group(0))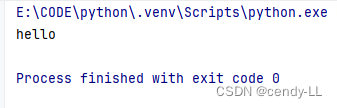
2、元字符
(1)元字符理解
正则表达式语言由两种基本字符类型组成:原义(正常)文本字符和元字符
元字符使正则表达式具有处理能力,所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)
(2)元字符参考表
| 元字符 | 描述 |
| \d | 匹配一个数字字符,等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符,等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符,等价于\x0c和\cL |
| \n | 匹配一个换行符,等价于\x0a和\cJ |
| \r | 匹配一个回车符,等价于\x0d和\cM |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等,等价于[ \f\n\r\t\v] |
| \S | 匹配任何可见字符,等价于[^ \f\n\r\t\v] |
| \t | 匹配一个制表符,等价于\x09和\cI |
| \v | 匹配一个垂直制表符,等价于\x0b和\cK |
| \w | 匹配包括下划线的任何单词字符,类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集 |
| \W | 匹配任何非单词字符,等价于“[^A-Za-z0-9_]” |
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符,例如,“\\n”匹配\n,“\n”匹配换行符;序列“\”匹配“\”而“(”则匹配“(”,即相当于多种编程语言中都有的“转义字符”的概念 |
| ^ | 匹配输入字行首,如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置 |
| $ | 匹配输入行尾,如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置 |
| \B | 匹配非单词边界,“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er” |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1”可以匹配“1_23” 中的“1”,但不能匹配“21_3”中的“1” |
| * | 匹配前面的子表达式任意次,例如,zo能匹配“z”,也能匹配“zo”以及“zoo”,等价于{0,} |
| + | 匹配前面的子表达式一次或多次(大于等于1次),例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,} |
| ? | 匹配前面的子表达式零或一次,例如,“do(es)?”可以匹配“do”或“does” ?等价于{0,1} |
| {n} | n是一个非负整数,匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o |
| {n,} | n是一个非负整数,至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o;“o{1,}”等价于“o+”。“o{0,}”则等价于“o*” |
| {n,m} | m和n均为非负整数,其中n<=m,最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组;“o{0,1}”等价于“o?” (注意:在逗号和两个数之间不能有空格) |
| ? | 当该字符紧跟在任何一个其他限制符(,+,?,{n},{n,},{n,m*})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
| . | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)” |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows” |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| (?<!pattern) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food” |
| [xyz] | 字符集合,匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| [^xyz] | 负值字符集合,匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符 |
| [a-z] | 字符范围,匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身 |
| [^a-z] | 负值字符范围,匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码 |
| \num | 匹配num,其中num是一个正整数,对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符 |
| \n | 标识一个八进制转义值或一个向后引用。如果*n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n*为一个八进制转义值 |
| \nm | 标识一个八进制转义值或一个向后引用。如果*nm之前至少有nm个获得子表达式,则nm为向后引用。如果*nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则*nm将匹配八进制转义值nm* |
| \nml | 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©) |
| \p{P} | 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode字符集七个字符属性之一:标点字符。其他六个属性:L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等);S:符号(比如数学符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。*注:此语法部分语言不支持,例:javascript |
| \<\> | 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式<the>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"(注意:这个元字符不是所有的软件都支持的) |
| () | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用 |
| | | 将两个匹配条件进行逻辑“或”(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."(注意:这个元字符不是所有的软件都支持的) |
3、使用正则表达式匹配单一字符
(1)元字符参考表
此次涉及到的元字符如下:
| 元字符 | 描述 |
| \d | 匹配一个数字字符,等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符,等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符,等价于\x0c和\cL |
| \n | 匹配一个换行符,等价于\x0a和\cJ |
| \r | 匹配一个回车符,等价于\x0d和\cM |
| \v | 匹配一个垂直制表符,等价于\x0b和\cK |
| \t | 匹配一个制表符,等价于\x09和\cI |
| \S | 匹配任何可见字符,等价于[^ \f\n\r\t\v] |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等,等价于[ \f\n\r\t\v] |
| \w | 匹配包括下划线的任何单词字符,类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集 |
| \W | 匹配任何非单词字符,等价于“[^A-Za-z0-9_]” |
(2)相关ASCII表


(3)使用正则,匹配字符串中所有的数字
import restr = "hell0,1my334 5 6name is cendy"result = re.findall("\d", str)
print(result)
(4)使用正则,匹配字符串中所有的非数字
import restr = "hell0,1my334 5 6name is cendy"result = re.findall("\D", str)
print(result)
注意:非数字字符,包括空格等字符
(5)使用正则匹配换页符
import re# 这里只用chr将ASCII表中换页符转换成字符
str = "hell0,1my334 5 6name is cendy&" +chr(12)result = re.findall("\f", str)
print(result)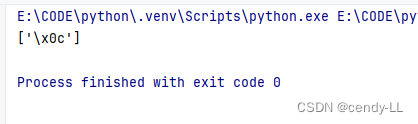
(6)使用正则,匹配换行符
import restr = "hell0,1my334 5 6name is cendy&" + chr(10)result = re.findall("\n", str)
print(result)
(7)使用正则,匹配回车符
import restr = "hell0,1my334 5 6name is cendy&" + chr(13)result = re.findall("\r", str)
print(result)
4、正则表达式之重复出现数量匹配
本次涉及到的元字符如下:
| 元字符 | 描述 |
| * | 匹配前面的子表达式任意次,例如,zo能匹配“z”,也能匹配“zo”以及“zoo”,等价于{0,} |
| + | 匹配前面的子表达式一次或多次(大于等于1次),例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,} |
| ? | 匹配前面的子表达式零或一次,例如,“do(es)?”可以匹配“do”或“does” ?等价于{0,1} |
| {n} | n是一个非负整数,匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o |
| {n,} | n是一个非负整数,至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o;“o{1,}”等价于“o+”。“o{0,}”则等价于“o*” |
| {n,m} | m和n均为非负整数,其中n<=m,最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组;“o{0,1}”等价于“o?” (注意:在逗号和两个数之间不能有空格) |
(1)匹配0次到无限次
【hello】 中 【o】 出现的次数是0次或者无限次
import res = "hello world helloo hell"
print(re.findall('hello*', s))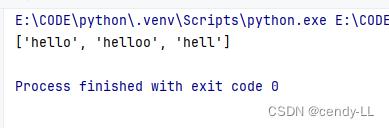
(2)匹配一次或多次
【hello】中【o】至少出现一次或者多次
import res = "hello world helloo hell"
print(re.findall('hello+', s))
(3)匹配零次或一次
【hello】中【o】出现零次或者一次
import res = "hell"
print(re.findall('hello?', s))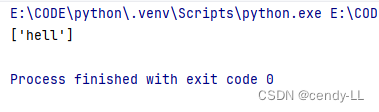
(4)匹配n次
【hello】中【o】出现n次,这里为出现2次
import res = "Helloo"
print(re.findall('Hello{2}', s))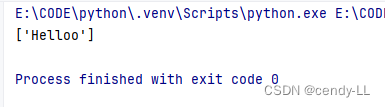
(5)匹配至少n次
【hello】中【o】至少出现n次,这里为至少出现2次
import res = "Helloooo"
print(re.findall('Hello{2,}', s))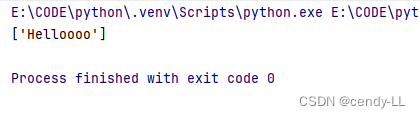
(6)匹配n次以上,m次以下
【hello】中【o】至少出现n次,至多出现m次
import res = "Helloooo"
print(re.findall('Hello{2,3}', s))
示例:
str = "李白 张三 李白板 李寻欢 李小白 李白白"1.找出里面所有姓李的人名
2.找出所有李白开头的人名str = "李白 张三 李四 王五 李寻欢 李白白 李白板 李小白"
print(re.findall("李\S*",str))
print(re.findall("李白+",str))
print(re.findall("李白+\S*",str))
5、使用正则表达式匹配字符集
本次涉及到的元字符如下:
| 元字符 | 描述 |
| . | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food” |
| [xyz] | 字符集合,匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| [^xyz] | 负值字符集合,匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符 |
| [a-z] | 字符范围,匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身 |
| [^a-z] | 负值字符范围,匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符 |
使用正则表达式匹配字符集合,如下:
import res = "abc"
print(re.findall('a|b', s))
import restr = "110,120,210,170"result = re.findall("1[12]0", str)
print(result)
如果是连续的范围,可以使用横杠-
import restr = "110,120,210,170"result = re.findall("1[1-9]0", str)
print(result)
表示不是某范围之内的,可以使用^取反
import restr = "110,120,210,170,1c0,1a0"result = re.findall("1[^1-9]0", str)
print(result)
6、正则表达式之边界匹配
本次涉及到的元字符如下:
| 元字符 | 描述 |
| ^ | 匹配输入字行首,如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置 |
| $ | 匹配输入行尾,如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置 |
| \B | 匹配非单词边界,“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er” |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1”可以匹配“1_23” 中的“1”,但不能匹配“21_3”中的“1” |
(1)匹配整个字符串开头
import res = "cendy"
print(re.findall('^ce', s))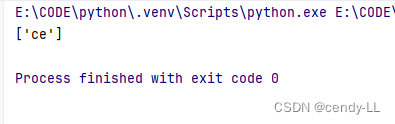
(2)匹配整个字符串的结尾位置
import res = "cendy ss ss ss"
print(re.findall('ss$', s))
(3)匹配单词开头
import res = "cendy xdaaa"
print(re.findall(r'\bxd', s))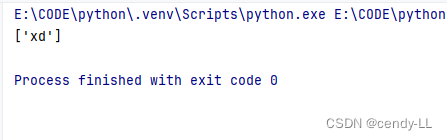
注意:这里只是匹配单词边界,而非整个单词
7、正则表达式之组
(1)组的理解
将括号() 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1到\9 的符号来引用
(2)简单使用
提取一段html代码里面的标题内容,如下:
import res = '''
<body>
<h1>标题问题内容</h1>
<h3 class="abc">我字体大小16px,去掉加粗</h3>
</body>
'''print(re.findall(r'<h1>(.*)</h1>[\s\S]*<h3.*>(.*)</h3>', s))
从输出结果看,返回了一个list,里面包着元组,这个时候,如果我想取里面第一个组,则:
import res = '''
<body>
<h1>标题问题内容</h1>
<h3 class="abc">我字体大小16px,去掉加粗</h3>
</body>
'''result = re.findall(r'<h1>(.*)</h1>[\s\S]*<h3.*>(.*)</h3>', s)
print(result[0][0])
print(result[0][1])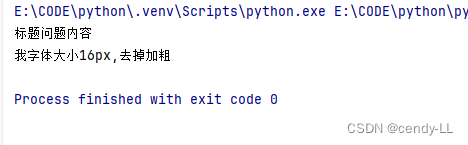
这个看起来就略显繁琐,而且也不太能看的懂,这个时候就可以使用命名组
(3)命名组
一个正则里可以有多个组,默认编号从1到9,但是具体在代码里面,都写在1,2,这样的东西,那么对阅读代码者来说就是一场噩梦。这个时候,命名分组的作用就来了:命名分组就是给具有默认分组编号的组另外再给一个别名 ,也就是说,我可以给这些编号取个容易看懂的名字
基本语法格式:
(?P<name>正则表达式)(4)命名组使用
命名组一般是跟search方法一起使用的
import res = '''
<body>
<h1>标题问题内容</h1>
<h3 class="abc">我字体大小16px,去掉加粗</h3>
</body>
'''result = re.search(r'<h1>(?P<h1>.*)</h1>[\s\S]*<h3.*>(?P<h3>.*)</h3>', s)
print(result.group('h1'))
print(result.group('h3'))
8、正则表达式之贪婪与非贪婪
(1)理解
之前进行重复数量匹配的时候,用的一系列元字符,总是会匹配最多结果;Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符 ,如果需要正则进行非贪婪的匹配,这个时候,就需要在正则表达式后面加个问号【?】
贪婪模式:
import res = 'hellooo '
print(re.findall(r'hello+', s))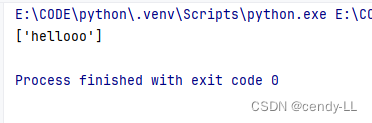
非贪婪模式:
import res = 'hellooo'
print(re.findall(r'hello+?', s))
(2)应用
对于下面的文本,分别提取出<div class="news">这个div中的两个div
<div class="news"><div class="content"><h3>This is a header</h3></div><div class="content"><h3>This is a heade2r</h3></div>
</div>贪婪模式下的匹配:
import res = '''
<div class="news"><div class="content"><h3>This is a header</h3></div><div class="content"><h3>This is a heade2r</h3></div>
</div>
'''
result = re.findall(r'<div class="content">([\s\S]*)</div>', s)
print(result)
从上图可以看到,中间的两个div的内容没有分别被提取,而是混成一块
非贪婪模式:
import res = '''
<div class="news"><div class="content"><h3>This is a header</h3></div><div class="content"><h3>This is a heade2r</h3></div>
</div>
'''
result = re.findall(r' <div class="content">([\s\S]*?)</div>', s)
print(result)
二十、实战之原生互联网爬虫
1、爬虫的道德与法律
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁止,但是利用爬虫技术获取数据这一行为是具有违法甚至是犯罪的风险的
爬虫应该遵守的道德
- 必须遵守被爬网站意愿,比如robots协议
- 不得干扰被访问网站的正常运营
爬虫的法律问题
- 严格遵守网站设置的robots协议
- 在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行
- 在设置抓取策略时,应注意避免抓取视频、音乐等可能构成作品的数据,或者针对某些特定网站批量抓取其中的用户生成内容
- 在使用、传播抓取到的信息时,应审查所抓取的内容,如发现属于用户的个人信息、隐私或者他人的商业秘密的,应及时停止并删除
- 严禁抓取涉及个人隐私的数据,包括公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息
2、爬虫之robots协议
(1)robots协议理解
Robots协议是国际互联网界通行的道德规范,基于以下原则建立:
- 搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权
- 网站有义务保护其使用者的个人信息和隐私不被侵犯
(2)robots协议主要功能
Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接;方便搜索引擎抓取网站内容;设置网站地图连接,方便引导爬虫爬取页面
(3)robots协议的写法
较为常见的有:
- User-agent:指定对哪些爬虫生效
- Disallow:指定要屏蔽的网址
(4)解读robots协议(以小米官网为例)
打开官网,在后面加上robots.txt,即可获得robots协议 [https://www.mi.com/robots.txt]
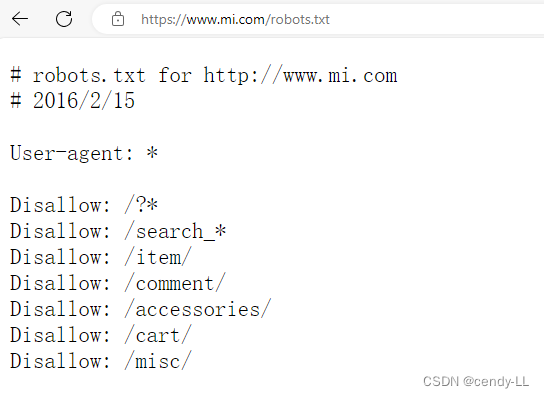
# robots.txt for http://www.mi.com
# 2016/2/15User-agent: *# 禁止/后带问号的
Disallow: /?*
# 禁止带search_的
Disallow: /search_*
# 禁止带/item/
Disallow: /item/
# 禁止带/comment/
Disallow: /comment/
# 禁止带/accessories/
Disallow: /accessories/
# 禁止带/cart/
Disallow: /cart/
# 禁止带/misc/
Disallow: /misc/3、爬虫的主要作用及其实现思路
(1)爬虫的作用
在我们浏览网页时,浏览器会渲染输出 HTML 、 JS 、 CSS 等信息;通过这些元素,我们就可以看到我们想要查看的新闻、图片、电影、评论、商品等等。一般情况下我们看到自己需要的内容,图片可能会复制文字并且下载图片保存,但是如果面对大量的文字和图片,我们人工是处理不过来的,同时比如类似百度需要每天定时获取大量网站最新文章并且收录,这些大量数据与每天的定时的工作我们是无法通过人工去处理的,这时候爬虫的作用就体现出来了
(2)实现思路

(3)爬虫五大件
- 爬虫调度器:主要是配合调用其他四个模块,所谓调度就是去调用其他的模板
- URL管理器:就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口
- HTML下载器:就是将要爬取的页面的HTML下载下来
- HTML解析器::就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器
- 数据存储器:就是将HTML下载器发送过来的数据存储到本地

4、爬虫网络环境搭建
(1)Hbuilder环境搭建
Hbuilder官网地址:https://www.dcloud.io/
进入官网后,点击下面图标,然后根据所需进行下载

下载完成后解压双击exe文件打开即可

(2)爬虫应用
获取测试的目标源码:https://codeload.github.com/Keraun/xiaomi/zip/master
打开Hbuilder,点击[文件--->导入--->从本地目录导入],选择打开解压后的网页源码文件夹,点击[运行--->运行到浏览器--->选择chrome],之后会自动为我们打开浏览器并加载页面

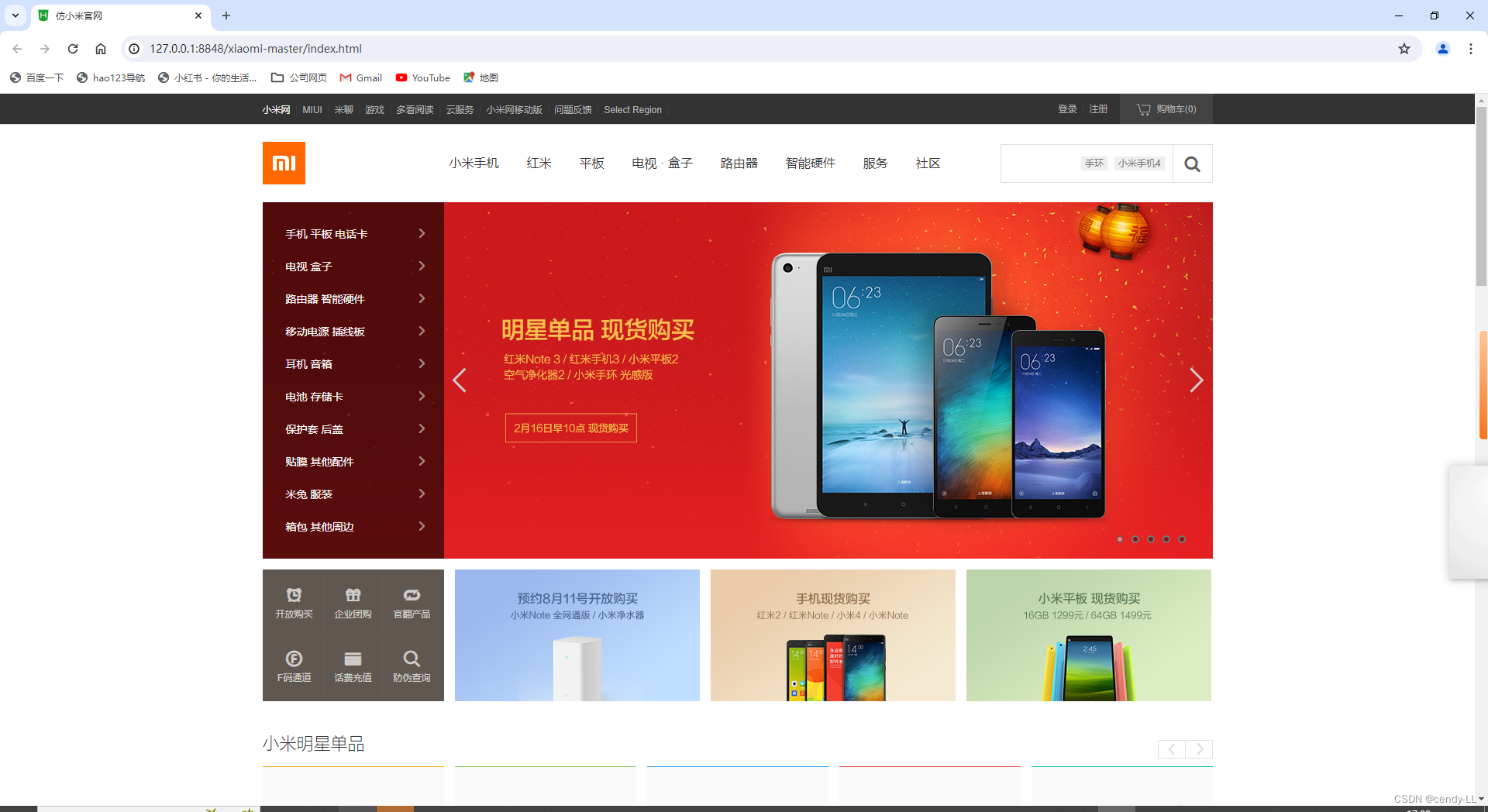
5、爬虫之抓取电商数据
(1)分析实现思路
- 明确抓取的需求
- 仔细观察待抓取网页特点
- 拉取网页
- 提取数据
(2)编写代码
# 定义结果类
首先,新建[product.py]文件,该文件中定义一个类,用来存储数据
# 结果类
class Product:def __init__(self, name, desc, price):self.name = nameself.desc = descself.price = pricedef __eq__(self, o: object) -> bool:return self.name == o.namedef __hash__(self) -> int:return hash(self.name)def __str__(self) -> str:return '产品名:%s 描述:%s 价格:%s' % (self.name, self.desc, self.price)# 以下是测试代码,可忽略
# print(Product(1,1,1))
# 编写主代码
第一步,新建数据存储器-[data_storage.py]
# 数据存储器
class DataStorage:def storage(self, products):"""数据存储 为了方便直接打印提取的结果:param products: set结构:return:"""for i in products:print(i)第二步,新建url管理器-[url_manager.py]
url管理器中有一些旧的以及新的url来表示爬取过的和未爬取过的,都用set()结构来存储
#url管理器
class UrlManager:def __init__(self):self.new_urls = set()self.old_urls = set()def get_new_url(self):"""获取新的url:return: url"""return self.new_urls.pop()def add_new_url(self, url):"""添加新的url:param url: 新的url:return:"""self.new_urls.add(url)def add_old_url(self, url):"""添加已经爬取过的url:param url: 爬取过的url:return:"""self.old_urls.add(url)第三步,新建html下载器-[html_downloader.py]
该模块写好后进行测试,测试url="http://127.0.0.1:8848/xiaomi-master/index.html"
import requests# html下载器
class HtmlDownloader:def download(self, url):"""根据给定的url下载网页:param url: url:return: 下载好的文本"""result = requests.get(url)return result.content.decode("utf-8")# 以下是测试代码,可忽略
# downloader = HtmlDownloader()
# result = downloader.download("http://127.0.0.1:8848/xiaomi-master/index.html")
# print(result)
第四步,新建html解析器-[html_parser.py]
import refrom pythonProject.spider.html_downloader import HtmlDownloader
from pythonProject.spider.product import Productclass HtmlParser:item_pattern = r'<li class="brick-item">[\s\S]*?</li>'title_pattern = r'<h3 class="title"><a href="javascript:;">([\s\S]*?)</a></h3>'desc_pattern = r'<p class="desc">([\s\S]*?)</p>'price_pattern = r'<span class="num">([\s\S]*?)</span>'def parser(self, html):"""解析给定的html:param html: html:return: product set"""items = re.findall(self.item_pattern, html)# print(items)#定义一个result,放入最终要返回的数据result = set()for i in items:title = re.findall(self.title_pattern, i)desc = re.findall(self.desc_pattern, i)price = re.findall(self.price_pattern, i)result.add(Product(title[0], desc[0], price[0]))return result# 这里是测试代码,可忽略
# downloader = HtmlDownloader()
# html = downloader.download("http://127.0.0.1:8848/xiaomi-master/index.html")
# htmlParse = HtmlParser()
# result = htmlParse.parser(html)
# for i in result:
# print(i)
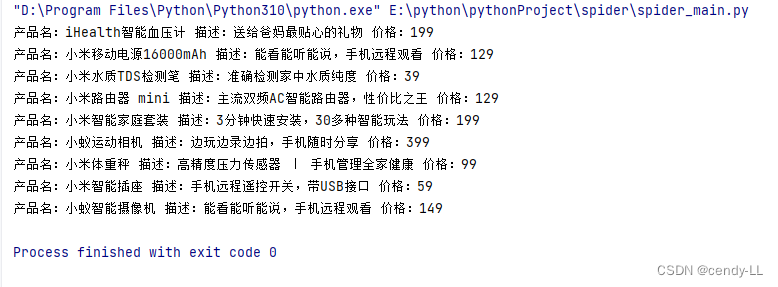
第五步,新建爬虫管理器-[spider_main.py]
from pythonProject.spider.data_storage import DataStorage
from pythonProject.spider.html_downloader import HtmlDownloader
from pythonProject.spider.html_parser import HtmlParser
from pythonProject.spider.url_manager import UrlManagerclass SpiderMain:def __init__(self):"""初始化方法,主要是将其他组件实例化"""self.url_manager = UrlManager()self.html_downloader = HtmlDownloader()self.html_parser = HtmlParser()self.data_storage = DataStorage()def start(self):"""爬虫的主启动方法:return:"""self.url_manager.add_new_url("http://127.0.0.1:8848/xiaomi-master/index.html")# 从url管理器里面获取urlurl = self.url_manager.get_new_url()# 将获取到的url使用下载器进行下载html = self.html_downloader.download(url)# 将html进行解析result = self.html_parser.parser(html)# 数据存储self.data_storage.storage(result)if __name__ == "__main__":main = SpiderMain()main.start()