最近专栏来了很多的新手小白,对科研实验的过程感到困惑和无从下手,这篇文章就来讲解一下整体的科研流程,从选择数据集到发表论文的各个步骤,并针对大家在实验中常犯的错误进行解答。并且为大家提供通向我其他相关博客的指引,这里面很多内容我都在其他博客单独讲过。
还有什么疑问欢迎大家提出来,这个文章会不停的更新下去~

文章目录
- 准备工作
- 明确改进场景/数据集
- 明确改进任务
- 明确改进基线
- 实验设备准备
- 改进答疑队友
- Q1:训练集,验证集,测试集怎么分?
- Q2:用一个小数据集测试效果,再换大数据集?
- Q3:预训练权重到底用不用,怎么用?
- Q4:训练结果图怎么看?怎么看收敛和过拟合?
- Q5:订阅了专栏后,怎么开始
- Q6:训练技巧
准备工作

明确改进场景/数据集
首先,我们应选择一个具体的细分场景进行实验,这样更容易取得成果;而不是直接选择COCO数据集来开发通用的检测算法(像 YOLOv5/6/7/8/9/10 那样),因为这对新手而言难度较大,成本也很高。
目前,检测场景的应用非常非常广泛。以下是一些常见的场景。我建议选择较为冷门的场景,因为这些通常更容易出成果。像烟雾、绝缘子、安全帽和火焰这类常见的检测对象,我并不推荐,因为相关研究已经非常丰富,知网随便一搜便能找到大量文献,水文还就喜欢做这些场景。
下面是一些智慧城市的场景,大家可以参考下,寻找一个自己感兴趣的方向:



其实这部分最重要的就是数据集问题,很多同学选择场景其实就是看自己能搞到什么数据集,一般常见的获取数据集方法有四种:
- 开源数据集
- 私有数据集
- 自制数据集
- 购买数据集
四种方法中我最推荐用前两种方法。首先说开源数据集,这其实是最好的选则,一方面可以增加你论文的说服力,另一方面这样的数据集用的人多,起码不会出现标注上的问题,标注质量能得到保证;还有些同学从开源的大数据集中抽一部分或者一类,这样其实也行的,论文交代清楚就行;这种开源的数据集很多很多,各种比赛都会开源,当然COCO数据集,Object365啥的就没必要尝试了。VOC还是可以试试的。
私有数据集指的是你自己个人有的,或者你们实验室私有的,这种数据集只有你有,你不开源其他人是用不了的。所以,你懂的。
至于自制数据集,除非必要,尽量避免自行制作。整个过程包括拍摄照片、数据清洗、标注和核对,非常耗时耗力。
如果你就是想自制数据集,那我这里也给你点思路,数据量少直接上在线的标注网站,推荐 makesense,简单易上手,不用配环境,这篇文章讲过用法。数据量大就自己本地搭建一个,比较稳定,常见的就是 labelImg ;除此之外还有很多半自动标注的,比如 GroundingDINO 系列;另外我个人推荐一个项目:X-AnyLabeling,据说还不错。

购买数据集当成私有数据集是我最不推荐的方式,很多时候还不如自制数据集,主要是无良奸商太多了,数据集质量参差不齐,有些商家甚至会从开源数据集中提取数据后声称是自行标注的,或者将开源数据集冒充为私有数据集出售,如果这种情况在论文中被发现,怎么解释。相比之下,自制数据集虽然比较耗时,但至少能确保数据的来源和质量。
这里我强烈推荐大家看我这篇文章,完整的数据集处理、训练、验证、推理 我都详细讲过了。
下面是另外一些常见的场景:
| 编号 | 常见场景 |
|---|---|
| 1 | 行人检测 |
| 2 | 布匹缺陷检测 |
| 3 | PCB(印刷电路板)缺陷检测 |
| 4 | 船舶检测 |
| 5 | 摔倒行为检测 |
| 6 | 驾驶员疲劳检测 |
| 7 | 烟雾检测 |
| 8 | 火焰检测 |
| 9 | 电力系统中绝缘子的损坏检测 |
| 10 | 水下目标检测 |
| 11 | 细胞检测 |
| 12 | 番茄成熟度检测 |
| 13 | 农作物病虫害检测 |
| 14 | 水稻生长情况检测 |
| 15 | 动物种类识别 |
| 16 | 植物病害检测 |
| 17 | 车辆检测与识别 |
| 18 | 交通标志识别 |
| 19 | 无人机检测 |
| 20 | 体育运动员动作分析 |
| 21 | 安全帽佩戴检测 |
| 22 | 商品识别与分类 |
| 23 | 表情识别 |
| 24 | 药品包装检查 |
| 25 | 果蔬分类和质量评估 |
| 26 | 垃圾分类 |
| 27 | 食品安全监控 |
| 28 | 历史文物识别保护 |
| 29 | 海洋生物研究 |
| 30 | 遗迹探索 |
| 31 | 夜视监控 |
| 32 | 肺部疾病X光分析 |
| 33 | 手势识别 |
| 34 | 机场行李安全检查 |
明确改进任务

目前 YOLOv8 框架支持五大主要视觉任务:分类、检测、分割、关键点识别和旋转框检测,订阅我专栏的同学们,你们可以在这五种任务中任选一个做改进,我的改进专栏会涵盖这五种任务,并且我写的 YOLO-Magic 系列框架 也给大家提供了上百种 yaml 文件,覆盖所有的任务(分类没写,这个过于简单),大家可以直接上手实验,对代码能力差的同学非常友好!直接喂到你嘴边了,求你张嘴吃点吧!
下面给大家简单介绍下这几种任务,我一般推荐大家选择检测任务,检测日常应用最广泛,而且我博客也是主讲的检测。
-
分类(Classification)
任务解释:分类是将输入的图像分配到预定义的类别的过程。比如,给你一张图,你给他分成"🐱"或"🐕",这是最基础的计算机视觉任务,也是最简单的任务,在图片内容复杂时,单标签的分类没有什么应用价值。
常见应用场景:
- 动物识别:在野生动物监控中,自动识别图像中的动物种类。
- 车辆分类:在交通监控系统中,区分不同类型的车辆,如卡车、轿车、摩托车等。
- 表情识别:在社交软件或安全监控中,识别人脸表情,如快乐、悲伤、惊讶等。
-
检测(Detection)
任务解释:检测不仅识别图像中的对象,还确定其位置,通常表示为矩形边界框。比如图片中有个🐕,用矩形框给🐕框起来。
常见应用场景:
- 行人检测:在城市监控和自动驾驶系统中,检测街道上的行人以预防事故。
- 安全帽检测:在建筑工地监控安全规范,检测工人是否佩戴安全帽。
- 火焰和烟雾检测:在安全监控系统中,快速检测起火点或烟雾,以早期预防火灾。
-
分割(Segmentation)
任务解释:分割是在像素级别上识别和分类图像中的每个部分,可以是语义分割(识别不同的语义区域)或实例分割(区分不同的对象实例)。
常见应用场景:
- 医学图像分割:在医学成像中,如MRI或CT扫描,精确分割不同的组织和器官,用于更好的疾病诊断。
- 道路分割:在自动驾驶技术中,分割和识别道路、人行道、障碍物等,以安全导航。
- 农田分析:在农业监控中,分割不同的作物区域,监测作物健康和生长状况。
-
关键点(Keypoint Detection)
任务解释:关键点检测涉及识别图像中的特定点,这些点通常是对象的重要部分,如人体的关节面部关键点。
常见应用场景:
- 人体姿态估计:在体育分析或人机交互中,检测人体各关节的位置,分析人体姿态。
- 面部关键点检测:在面部识别或动画制作中,识别面部的关键点如眼睛、鼻子、嘴巴等,用于进一步的表情分析或面部动画。
-
旋转框定向目标检测(OBB)
任务解释:方向有界框检测是在检测任务中的一个变体,不仅识别对象的位置还包括其方向,其实就是可以旋转的矩形框。
常见应用场景:
- 船舶检测:在海上交通监控中,检测船只的位置及其航向,用于交通管理和避免碰撞。
- 停车位监控:在停车场管理系统中,检测车辆的精确位置和停放角度,优化停车资源分配。
- 航拍图像分析:在城市规划或军事侦察中,通过航拍图像检测目标物体的方向和位置。
明确改进基线
既然大家都订阅了我的专栏,那这个问题就不用你们考虑了,YOLOv8 的框架叫做 ultralytics ,这个框架就可以理解为代码基线,里面不仅有 YOLOv8 算法,还有完整的 RT-DETR 和 YOLOv10。
你们唯一要选的就是初始一次实验选择 yolov8n 还是 yolov8s,这里就根据数据集的类别和数量选,一般情况小于3000张,n足够了;但是你选 s 也行,这没什么太多的讲究,这两个尺寸一般情况下在对比实验时都会跑一次的。选太大尺寸的模型没啥必要了,模型越大占用显存越多,训练越慢,收敛越难。
这里回答一个大家经常担心的问题,比如经常有老师说:“你这个太老了,YOLO已经更新到v10了”
实际上,对于这种担心是没有必要的。首先,需要明确的一点就是,YOLOv9 是在 YOLOv5 的框架上开发的,而 YOLOv10 则是基于 YOLOv8 的框架。因此,我们不能武断地说一个版本“老了”。关键在于你如何撰写和展示你的成果,也就是我们常说的讲故事。即使你的工作是在 YOLOv5 框架上进行的改进,也完全可以将其描述为你提出的一个新变体,例如 “xxYOLO/YOLOxx”。你们订阅我的专栏不仅仅学会的是改进的 v8,而是整个框架,未来我把 v10 集中进来,你们依然也会直接上手改进。所以你选择了这个专栏就意味着你永远不用担心框架过时,我会让他保持最新!你们只管实验,代码我来解决!
总的来说就是,基线的选择并不能决定你的工作“老不老”,基线代码只会影响你改进的效率和难度。
实验设备准备
首先要明确一点,如果你没有显卡想用 CPU 来进行实验,建议你放弃这个想法!
至少应配备一块显卡,因为 CPU 与 GPU 在性能上的差距实在太大。当别人完成 100 100 100次实验时,你可能连 1 1 1次都未完成,等你做完实验,YOLO 可能已经更新到 YOLOv99 了。即便大家自己的笔记本有显卡我也不太推荐,一方面是因为显存较小,运行速度慢;另一方面,长时间满负荷运行会严重损害机器,但主要还是因为显存小速度慢。
那么,怎么办呢?答案是租! AutoDL 现在租48G显存的A40显卡的机器每小时的费用仅需两块多,能极大地加快实验速度,因为你可以设置非常大的batch size。我建议大家至少上一个 RTX 3090 显卡。
另外,关于 IDE 的选择,虽然 Pycharm 很好用,但我个人更推荐 VScode ,尤其是在远程连接云服务器时,VScode的用户体验远胜于 Pycharm 。后续我会分享一些我常用的 VScode 插件和配置。
有关 AutoDL 云服务器训练 YOLOv8 的手把手视频教程,大家请看:我的哔哩哔哩

改进答疑队友
这其实是你必备的,一群志同道合的伙伴会解决你很多问题,而且也可以在学习路上给到很多的帮助,订阅了 YOLOv8 改进实战的同学记得进群,除了有答疑外还有一些博客的相关代码,YOLOv8-Magic 框架就是进来才能获取的,本人亲自维护!

Q1:训练集,验证集,测试集怎么分?
首先说三个集合是干啥的,举一个通俗的例子:
-
训练集(Training Set):
训练集就像是你在驾校练习时所驾驶的那部分道路。你在这些路段上一遍又一遍地练习,通过不断的重复,你的驾驶技能逐渐提升。在机器学习中,训练集用来训练或者“教育”你的模型。模型通过分析这些数据,尝试学习到数据中的模式和规律,从而做出准确的预测。 -
验证集(Validation Set):
验证集好比是你在不同的驾驶场景下进行模拟考试的路段。这些路段用来检测你的驾驶技能是否真的达标,以及你是否准备好去参加真正的驾驶考试。在机器学习中,验证集用来测试模型在训练过程中的表现。开发者利用这些数据来调整模型设置(如调整模型参数),以便模型能更好地学习和预测。 -
测试集(Test Set):
测试集则相当于你的实际驾驶考试,是在完全未知的路段进行的。你之前没有在这些路段上练习过,因此,它能准确地反映出你的驾驶技能。在机器学习中,测试集用来评估模型在完全未知数据上的表现。这帮助你了解模型在实际应用中能达到怎样的效果。
在划分数据集的问题上,网络上确实有许多不同的建议,如 8:1:1、7:2:1等。其实关键在于确保你的训练集足够大,足以支持模型的训练。在这种情况下,你可以根据自己的需要自由划分,2:1:1 的比例也是完全没问题的。
关于数据集应该分成几个部分,上面的解释大家也看到了,三个数据集——训练集、验证集和测试集,各有其独特的功能。最理想的做法是分为三部分:这样可以在论文中准确地报告测试集上的精度,这是最标准的做法。
但是现在很多论文就划分为两个数据集,一个用于训练,另一个用于测试。这种方法也是可行的,取决于你的数据量。如果大家不想在数据处理上审稿人指出问题,建议直接采用三个数据集的划分方法。这样既符合标准,也能更有效地评估模型性能。
Q2:用一个小数据集测试效果,再换大数据集?
“我先用一个小数据集测试一下这个改进的效果,然后再在我的大数据集上实验,这样岂不是节省了资源,又加快了实验进度,我真实个天才!”
经典的错误,标准的零分!首先,我给大家提供的改进点都是已发表论文里面的,有效性人家已经验证过了,不需要你验证了,理论上每个模块都是正确的。其次,深度学习模型在不同数据上的泛化能力是不一样的!!
举一个最简单的例子,你在A数据集涨点的改进,在B,C数据集都可能不涨点。反过来也是,A,B,C数据集都不涨点的改进,在你的Z数据集上就涨点了!
所以,给你提供A数据集上的实验结果(特别还是那种自己的小数据集),对你改进你自己的数据集没有任何意义!
但是,说到这里,其实有一个技巧,不一定有效,上面的做法肯定是错的,但是我们可以从自己的数据集再抽一部分,形成一个小的,用这个小的实验,有效的改进点再换到自己的大数据集。切记,不到万不得已,别用这个技巧,可能让你走弯路!
Q3:预训练权重到底用不用,怎么用?

先说结论,看情况。这次我回答的详细点。
举个简单的例子,模型就像一把锁,而预训练权重则类似于这把锁的钥匙。每把锁都有自己独特的内部结构,决定了只有特定形状的钥匙才能打开它。
深度学习中的模型是指由多层神经网络构成的特定结构,这些结构定义了数据如何被处理和传递。就像锁的机械结构,决定了钥匙需要什么样的形状和尺寸才能匹配。
预训练权重则是这把锁专用的钥匙,它包含了所有必要的细节和形状,以适应锁的内部结构。这些权重通过在大量数据上的训练获得,已经被优化,可以很好地解决特定类型的问题。
将预训练权重应用于一个模型,就像是使用钥匙来开锁。如果钥匙和锁是为彼此设计的,那么锁就能被顺利打开,模型就能有效地完成任务。但如果你拿着一把钥匙去尝试开一个完全不同设计的锁,那么无论你怎么尝试,锁都不会打开。
这种情况在深度学习中也是类似的。如果一个模型的结构(锁的设计)和预训练权重(钥匙)不匹配,那么权重将无法在这个模型上发挥作用,模型也无法正确执行任务。所以说,选择正确匹配的模型和预训练权重就像是为特定的锁挑选合适的钥匙。
再引申到YOLO算法,你官方项目下载的那个 yolov5s.pt 就是预训练的权重(🔑钥匙),yolov5s.yaml 就是模型的结构(锁🔒);只有yolov5s.pt 才能打开 yolov5s.yaml。也就是说,只有 yolov5s.pt 才能完美的匹配 yolov5s.yaml ;yolov5s.pt 是没办法匹配上你的 mobilenet-yolov5.yaml 的!
再说一个细节,YOLO 项目的匹配机制有点特殊,权重和模型从第一层开始匹配,按顺序尽可能多地匹配,这就像是钥匙插入锁孔,相当于钥匙插进锁孔,即便只插入一半也能发挥点作用。
所以说,当你改了模型的后面几层,只要是不改第一层,加载权重时仍然能匹配上部分层,理论上权重也会发挥点正向作用。
但是,这里需要注意控制实验中的变量!很多同学在基线模型中使用了预训练权重,相当于给基线加上了蓝BUFF。
自己的模型也加载官方给的那个权重,而如果你的模型结构与官方提供的权重不匹配,相当于你的模型吃不到蓝BUFF,这对你改进是不利的!
我建议直接统一都不加!那什么时候才加载预训练权重呢?
如果你的数据集很少,那么权重可能对你的模型精度影响很大,加了权重90%,不加30%;那这个时候你就得考虑加载预训练权重了!
怎么加载预训练权重,两种思路:
- 如果你不想改主干,那简单,基线模型和改进模型都加载官方的权重,误差也差不太多(其实不是很严谨);
- 如果你想改主干,那你改进的模型得先去大数据集预训练一个权重,再加载这个权重训练你的小数据集。
怎么冻结主干训练?
这篇文章 我给了大家训练脚本,里面有个 freeze 参数,主干网络 0-9一共十层,想冻结整个主干网络就让 freeze=9 ,冻结主干的意思就是,主干这部分使用预训练权重的参数,训练时只更新主干外的层的参数,冻结可以让你训练的更快,搞清楚自己的需求和情况,别乱用。

Q4:训练结果图怎么看?怎么看收敛和过拟合?
啥叫过拟合?
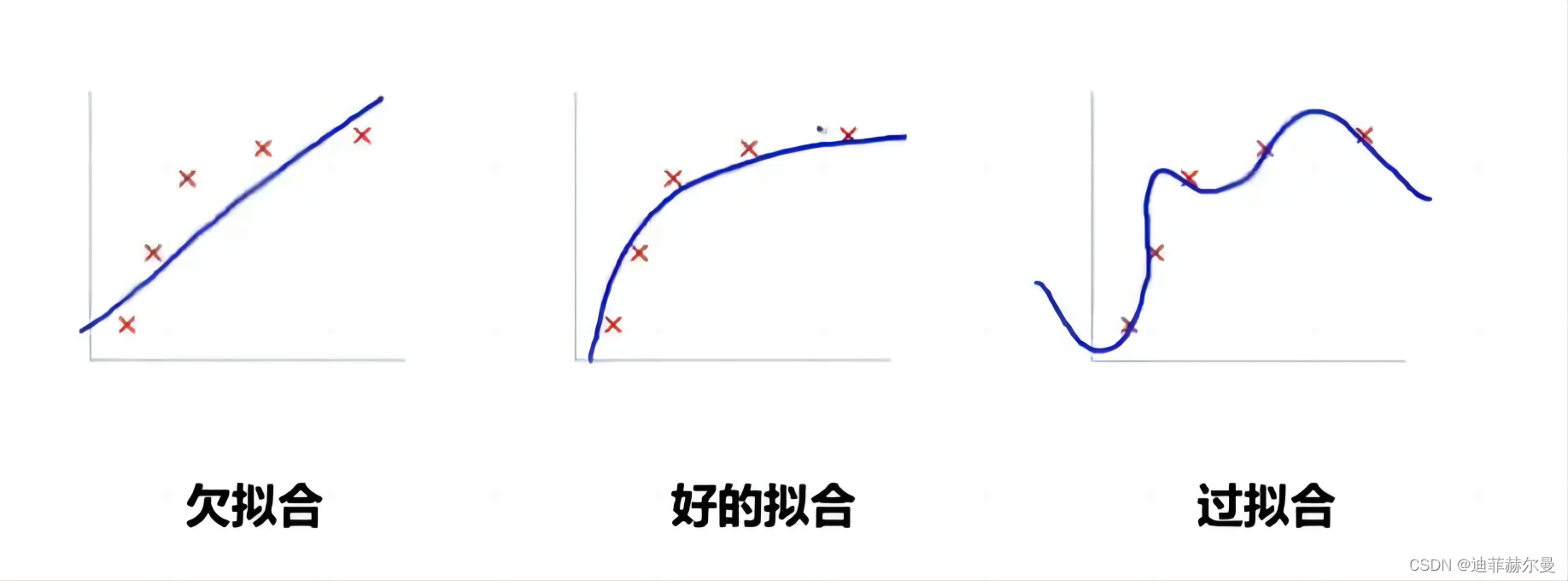
简单来说就是模型对于训练数据学得“太好了”,以至于它在处理新的、未见过的数据时表现得不好。
简单例子:如果你准备考试只死记硬背书本上的题目和答案,而不去理解其中的概念和原理,那么在考试中如果遇到稍微变化一点的题目,你可能就答不出来了。这就像过拟合,在训练过程中,模型学会了训练数据的每一个小细节,甚至包括其中的噪声和错误,但这种“过度学习”却使得它失去了泛化能力,也就是处理新情况的能力。
过拟合的模型在训练集上的表现可能非常好,准确率很高,但在新的或未知的数据集(测试集)上表现往往不佳。这是因为模型已经将训练数据中的特定特征和随机噪声学习得太彻底,而这些特征并不适用于其他数据。
防止过拟合的方法有很多,例如增加数据量,使用数据增强技术,简化模型的结构,或者使用正则化技术等,我们一般在YOLO里面就是通过训练结果的 result.png 判断,或者看 tensorboard 的结果。YOLO 一般有三个损失,只要 val 的 loss 翘起来了就是发生了过拟合。
怎么判断过拟合?
拿下面这张图来说,训练集的损失是持续下降的,验证集的 box_loss 和 cls_loss 也是持续下降的,但是 obj_loss 不降反升,这就是典型的过拟合,也就是我们俗称的 “翘起来了” ;
过拟合要不要处理?
这个展示的还算是比较轻微的情况,一般单 obj_loss 升了不处理影响也不大;
但三个 val_loss 都翘起来了,那绝对是严重过拟合,一定要处理下,最简单的方法就是减小你模型的参数量,早停机制什么的调参技巧你们搞不明白,减少参数量是非常简单粗暴的处理方式。

怎么判断收敛?
每次跑完实验会在你的文件夹生成一个 results.png ,这个必须跑完整了才会生成,比如你设置300轮,跑到200轮你手动停止是不会生成的,这篇只说 results.png ,其他的文件都是干啥的,后面单出一篇文章。

我们通过这个图来分析模型的收敛情况,像我这个图就收敛的很好,由于我的这个mAP50很高了,其实加大epoch也没太大意义了,但是从图像看 mAP50-95 还是有上升趋势的,也就是说,加大 epoch 的情况下, mAP50-95 可能还会提升,
平时判断收敛怎么看?
直接看 val loss,val loss 平缓了就是收敛;或者直接看 mAP ,涨不动了就是收敛,就这么简单。

有时候还有这种情况,先跳到了很高,然后又降低了,这个其实也不用理会,可能初始化的参数刚好拟合你的部分数据,忽略就好了,看整体的趋势。

最差的情况大概就是这种,首先检查你的数据集标签是否正确,然后考虑下自己的网络结构,是否合理,是否过度设计,遇到这种情况,只能重开,换个结构继续跑。

第一次实验时建议直接跑300轮,同时关闭早停机制,然后分析我们的结果,这一步很重要,可以决定后面我们实验要跑多少轮!
假如你的数据集收敛很快,100轮就收敛了,后面你可以将基线和改进都设置 200 轮对比;如果你的300轮还没收敛,你可能得考虑加大epoch,或者稍微增加学习率。

Q5:订阅了专栏后,怎么开始
先把基础篇认认真真的看一遍,我不怕你们不会,就怕你们不学!专栏订阅都订阅了,一定要珍惜每一篇文章,特别是非改进类的文章,像我现在这篇,写一次耗费我大量的时间,且看且珍惜~
后面的改进,其实你从哪里入手都行,我个人建议新手先做模块级别的改进,也就是先加个注意力啥的练练手,先适应下流程和思路,后面大家自己就有想法了。

这部分其实是给大论文用的,可以增加算法级别的工作量:

这些脚本需要的时候来找就行了,基本满足大家的需求,我也在不断地增加中:

Q6:训练技巧
有个训练的小技巧,总有些同学反应,训练完了最终的精度没截图,不知道怎么看了,其实没存的话可以用 val.py 再验证一次的,但这我给大家一个小技巧,使用 nohup 指令,这个指令既可以保证终端关闭后进程不中断,也会将你终端打印的所有的信息存下来,你运行下面的指令后就会在你的路径下看到一个 nohup.out 文件,实时的在写入本来终端应该打印的内容,这样就算你出去玩了,回来时依然能看到最终打印出来的结果。
nohup python train.py &