目录
一,关于动静态库
1.1 什么是库?
1.2 认识动静态库
1.3 动静态库特征
二,静态库
2.1 制作静态库
2.2 使用静态库
三,动态库
3.1 制作动态库
3.2 使用动态库一些问题
3.3 正确使用动态库三种方法
3.3.1 方法一:添加系统环境变量
3.3.2 方法二:改配置文件
3.3.3 方法三:软链接方案
五,一些问题解答
5.1 为什么gcc编译的时候没有指明过库名也能编译?
5.2 为什么要有库?
5.3 进程是如何访问到库中的所有函数的?
一,关于动静态库
1.1 什么是库?
一个可执行程序,由一堆源文件和一堆头文件经过预处理,编译,汇编,链接四个步骤后得来。
我们先写几个简单的头文件和源文件,如下代码:
mymath.h
#pragma onceextern int Add(int x, int y);
mymath.c
#include "mymath.h"int Add(int a, int b)
{return a + b;
}
myprint.h
#pragma once extern void Printf(int x, int y);
myprint.c
#include <stdio.h>
#include "myprint.h"void Printf(int a, int b)
{printf("hello %d\n", Add(a, b));
}
main.c
int main()
{Printf(10, 20);return 0;
}
gcc mymain.c mymath.c myprint.c -o my.exe
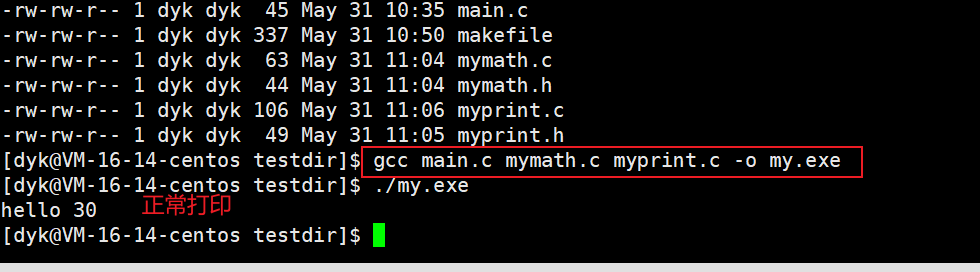
① 一般来说,程序都是先通过汇编之后形成.o文件,然后就将所有的.o文件进行链接最终形成可执行程序。那么,如果我把我的.h和.o给别人,别人能用吗?
②当然是可以的,在Linux操作系统下,只需要cp *.o /home/user/ 把.o和.h拷贝到其它用户目录下,其它用户目录就可以使用了。
③但是一些稍微大一点的项目,.o文件会非常非常多,所以我们得把所有的.o文件打个包,这个打包的过程就叫做形成库的过程,这个打好的包就叫做库。
④我们目前见到的库绝大多数其实都是一堆目标文件(.o)的集合,库的文件中并不包含主函数,但是提供了大量的方法以供调用。
1.2 认识动静态库
我们先通过一个最简单的代码来认识库:
#include<stdio.h>
int main()
{printf("hello world\n");return 0;
}
我们gcc编译后生成test可执行程序,运行后成功在屏幕上打印hello world。
我们用ldd test来查看一个可执行程序所依赖的库文件,如下图:
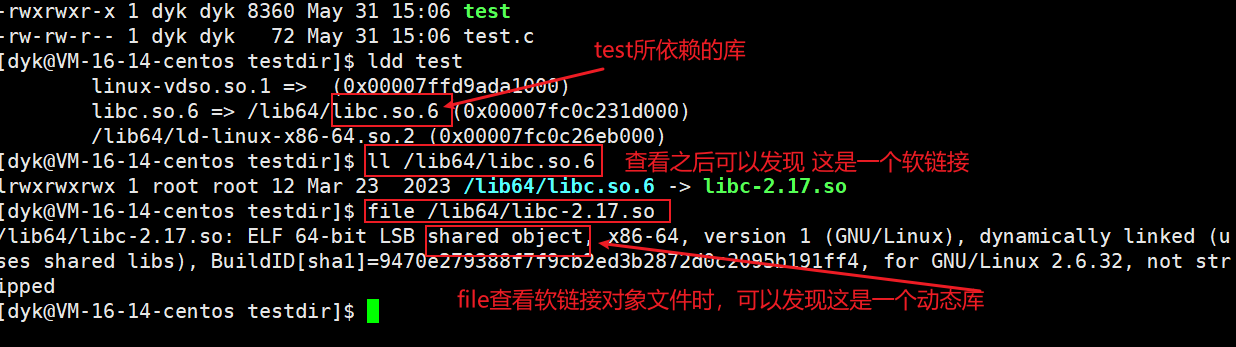
- 在Linux中,.so为后缀的是动态库,.a为后缀的是静态库
- 在Windows中,.dll为后缀的是动态库,.lib为后缀的是静态库
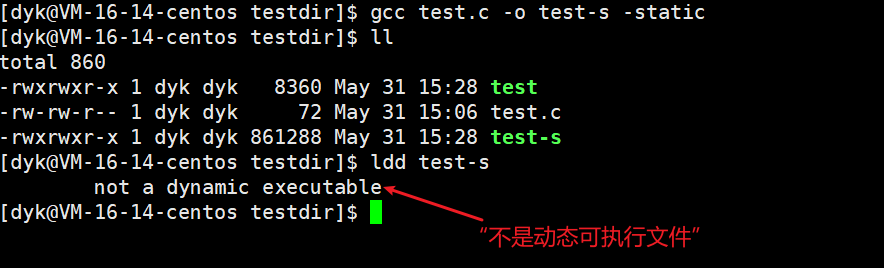
gcc/g++默认是动态链接的,但是我们也可以强制让它变成静态链接,在后面携带一个-static选项即可,如下图:
我们也可以用file查看文件的详细属性:

1.3 动静态库特征
静态库:
静态库是程序在遍历链接时把库的代码原封不动地全部拷贝到源文件中一起编译
优点:使用静态库生成地可执行程序可以直接独立运行,不再需要动态库
缺点:使用静态库生成地可执行程序空间会大很多,就拿上面的图来看,test-s的大小是test的一百多倍。而且这只是包含了一个头文件,当有多个静态程序同时加载相同的库,那么内存会存在大量的重复代码
动态库:
动态库是在程序运行时才会去链接相应的动态库代码的,多个程序共享使用库的代码。
一个与动态库链接的可执行文件只包含了它用到的函数入口地址的一个表,而不是外部函数所在文件的所有数据。在可执行文件运行前,调用的函数所在的库由操作系统从磁盘上先搞到物理内存中,这个过程称为动态链接。然后动态库在多个程序间共享,节省了内存和磁盘的空间,具体步骤如下图:
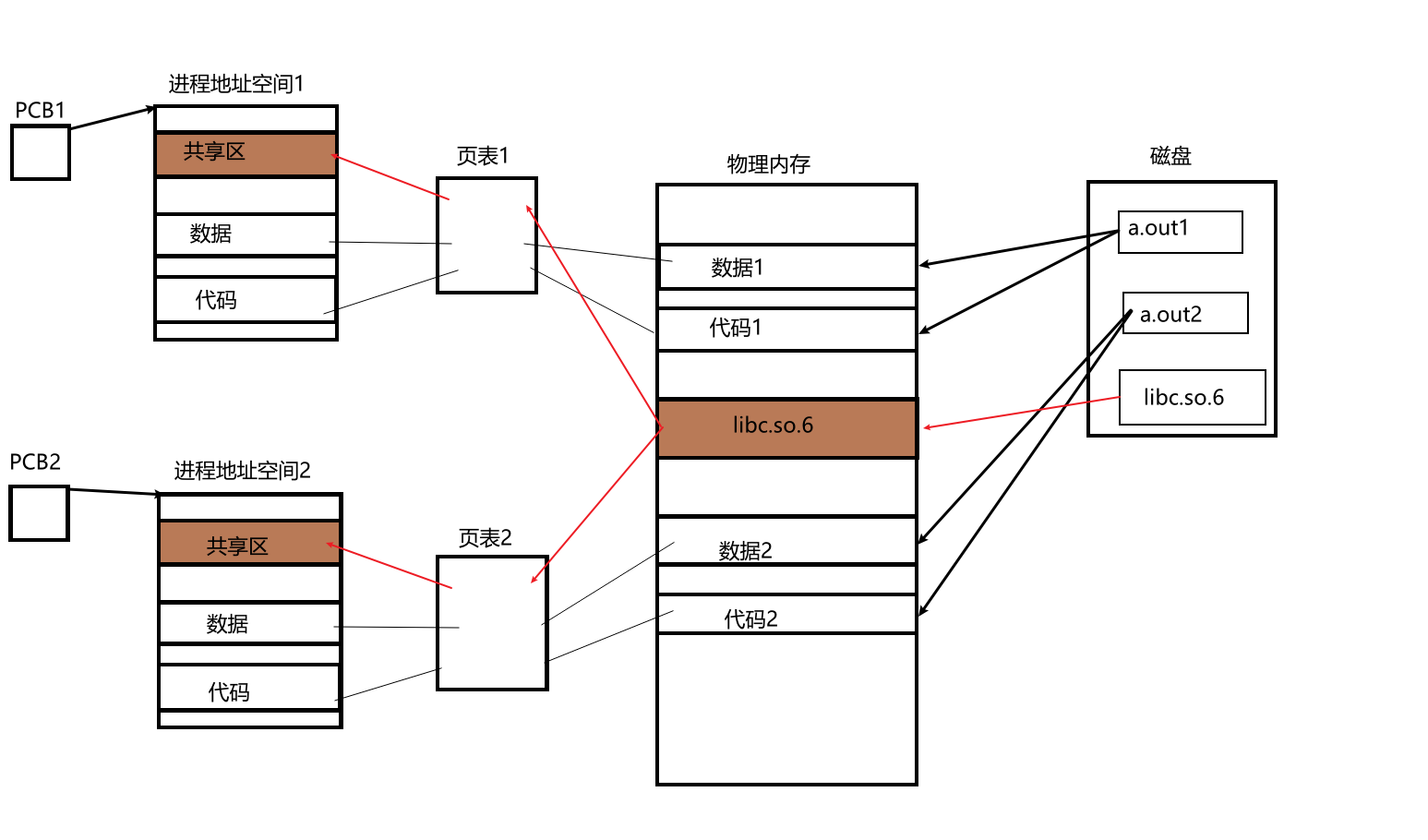
- 首先,动态库是一个独立的文件,可执行程序也是一个独立的文件,所以动态库和可执行程序是可以分批加载的
- 地址空间最下面的代码区,中间一大块是堆栈,而且堆栈相对而生,但是堆栈中间有一大块镂空区域,我们叫做共享区
- a.out先加载到内存里面,如果在执行时需要访问库代码,这个时候操作系统就把位于磁盘上的动态库的某一个方法加载到物理内存里,然后通过页表建立映射关系,把该方法的虚拟地址放进进程的共享区中
- 然后进程就可以从代码区转到共享区执行完方法再把结果拿回代码区,减少了额外拷贝,只需要改下虚拟地址即可
- 这样,一个进程动态链接后物理内存中的该方法就可以继续为其它的调用这个方法的进程服务,这也就是为什么我们两次运行一个程序,第二次运行比第一次快很多,因为第一次加载的数据,第二次就不需要加载了,可以直接用
优点:能节省磁盘和内存空间,并且多个用到相同动态库的程序同时运行时,库文件会通过进程地址空间进行共享,内存中不会存在重复代码
缺点: 必须依赖动态库,并且动态库的使用比静态库复杂很多,下面的内容会有体会
二,静态库
2.1 制作静态库
就上面的mymath.h和myprintf.h而言,我们可以把它俩打个包,如下图:
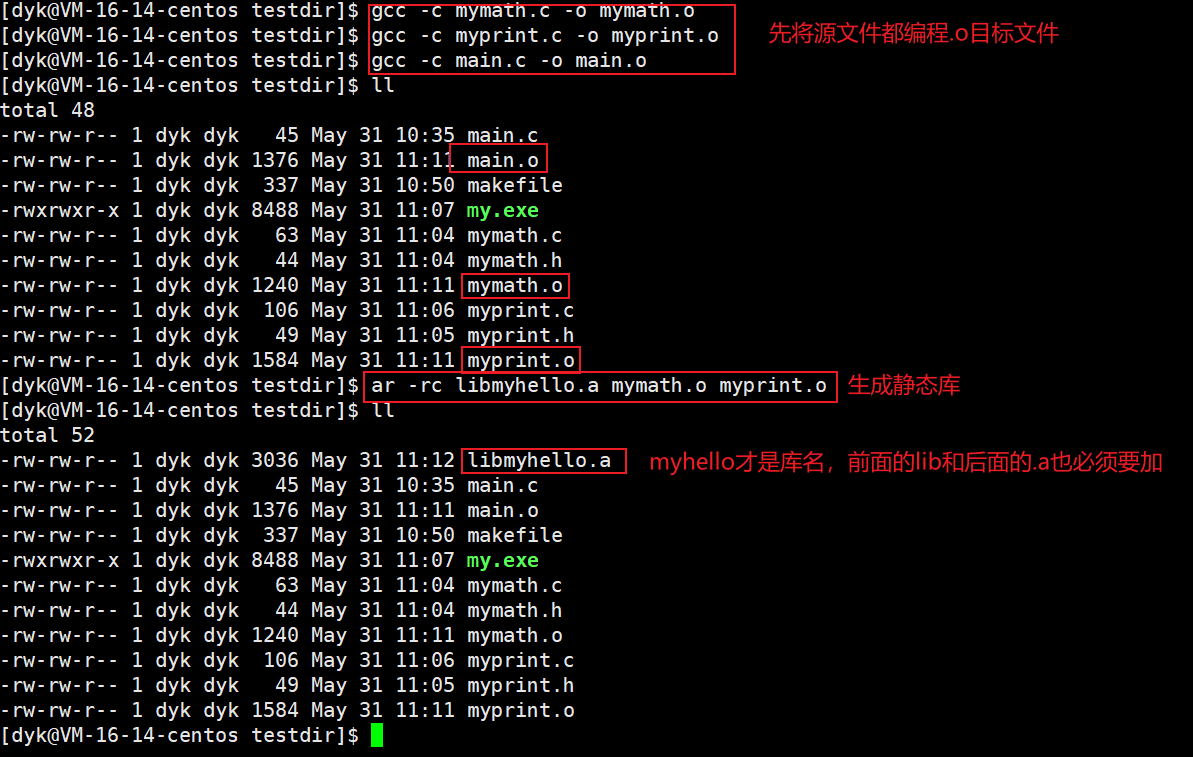
ar命令是gnu的归档工具,常用于将目标文件打包为静态库,下面是一些常用选项:
- -r(replace):若静态库文件当中的目标文件有更新,则用新的目标文件替换旧的
- -c(create):建立静态库文件
- -t:列出静态库中的文件
- -v(verbose):显示库的详细信息
一个稍微大的项目都有至少5各源文件,我们一个一个打太慢了,所以我们可以用makefile使其自动化:
libmyhello.a:mymath.o myprint.oar -rc libmyhello.a mymath.o myprint.o
mymath.o:mymath.cgcc -c mymath.c -o mymath.o
myprint.o: myprint.cgcc -c myprint.c -o myprint.o.PHONY:hello
hello:mkdir -p hello/libmkdir -p hello/includecp -rf *.h hello/includecp -rf *.a hello/lib.PHONY:clean
clean:rm -rf *.o libmyhello.a hello
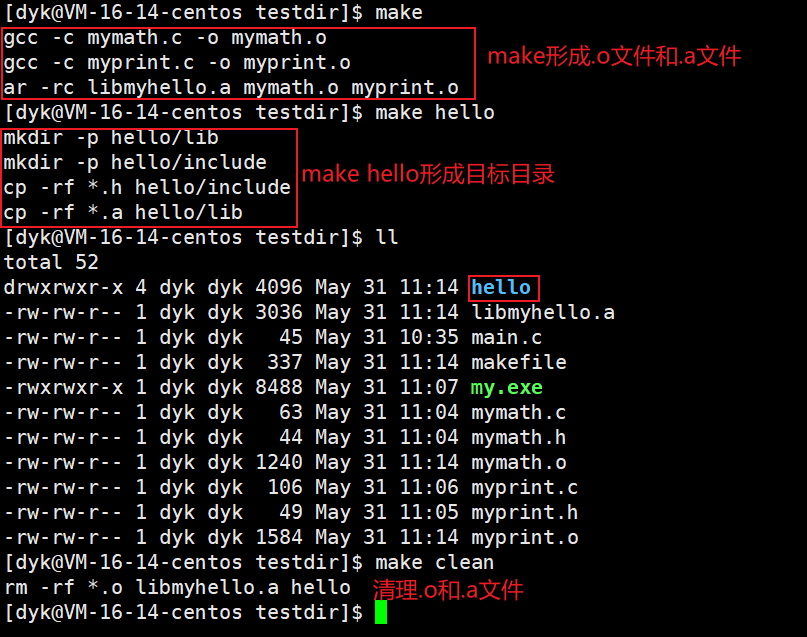
2.2 使用静态库
经过上面的步骤后我们形成了静态库,hello目录的include包含我所有的.h文件,lib包含.a文件。
我们可以先把main.c和hello之外的文件全干掉:
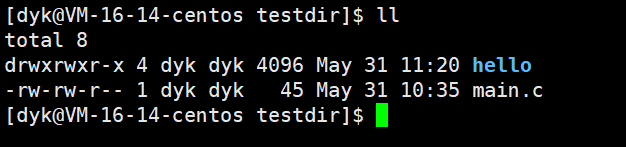
方法一:
gcc的头文件默认搜索路径是:/usr/include 库文件的默认搜索路径是:/lib64 或者 /usr/lib64
我们可以把我们的文件拷贝到这两个目录下:
sudo cp -rf hello/include/* /usr/include/ sudo cp -rf hello/lib/libmyhello.a /lib64添加了之后,会发现还是编译不过,因为我们自己实现的库还是第三方库,不是系统库也不是C标准库,所以我们需要这样:
gcc main.c -o main -lmyhello
-l 表示要链接库,然后我们之前的.a文件去掉前面的lib和后面的.a剩下的就是库名
方法二:
但是,我们非常不见直接把我们现在写的库文件安装到系统目录下,因为我们目前写的库文件,还没有经过可靠性验证,建议测试完成后直接删掉
sudo rm /usr/include/myprint.h
sudo rm /usr/include/mymath.h
sudo rm /lib64/libmyhello.a
所以我们目前我们要使用我们自己做的静态库,就需要这样:
gcc main.c -I ./hello/include/ -L ./hello/lib/ -lhello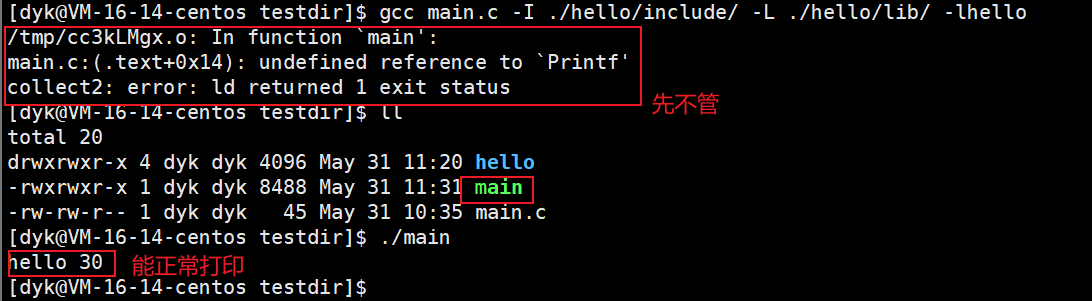
- -I:指定头文件搜素路径(因为编译器不知道你所包含的头文件在哪里,所以需要指定头文件搜索路径)
- -L:指定库文件搜索路径(头文件中只有Add函数和Printf函数的声明,并没有实现,所以需要指定链接库文件的搜素路径)
- -l:指明需要链接库文件路径下的哪一个库(在库文件的lib目录下可能会有大量的库文件,因此我么你需要指明链接库文件路径下的哪一个库)
三,动态库
3.1 制作动态库
动态库大致和静态库一样,但是又些区别。
动态库是以lib开头,以.so结尾的文件,我们还是以这几个文件为例
然后就是制作动态库,如下图:
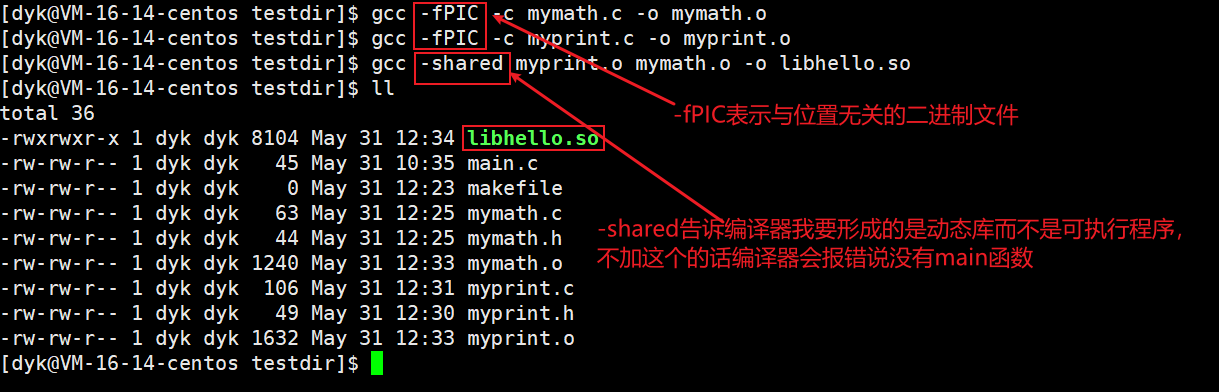 我们先生成.o目标文件,对应-fPIC有下面几个要注意的点:
我们先生成.o目标文件,对应-fPIC有下面几个要注意的点:
- -fPIC作用于编译阶段,其目的是告诉编译器产生与位置无关的代码,这时产生的代码中没有绝对地址,全都是相对路径,使代码可以被加载器加载到内存的任意位置都可以指向。这也是动态库的特点,它在内存中的位置不是固定的
- 如果不加-fPIC选项,则加载.so文件时,其里面的代码端引用的数据对象需要重定位,而重定位会蟹盖代码内容,这就导致每个使用这个.so的进程都会发生写时拷贝,因为每个进程的.so文件代码段和数据段在内存的映射位置不一样
然后我们可以不用ar命令来生成动态库,只需要在gcc命令加上-shared选项即可。
当然我们也一般用makefile来搞这个,如下:
.PHONY:all
add:libhello.so libhello.alibhello.so:mymath_d.o myprint_d.ogcc -shared mymath_d.o myprint_d.o -o libhello.so
mymath_d.o:mymath.cgcc -c -fPIC mymath.c -o mymath_d.o
myprint_d.o:myprint.cgcc -c -fPIC myprint.c -o myprint_d.olibhello.a:mymath.o myprint.oar -rc libhello.a mymath.o myprint.o
mymath.o:mymath.cgcc -c mymath.c -o mymath.o
myprint.o: myprint.cgcc -c myprint.c -o myprint.o.PHONY:output
output:mkdir -p output/libmkdir -p output/includecp -rf *.h output/includecp -rf *.a output/libcp -rf *.so output/lib.PHONY:clean
clean:rm -rf *.o *.a *.so output
先make生成.so文件,在make output生成目录
3.2 使用动态库一些问题
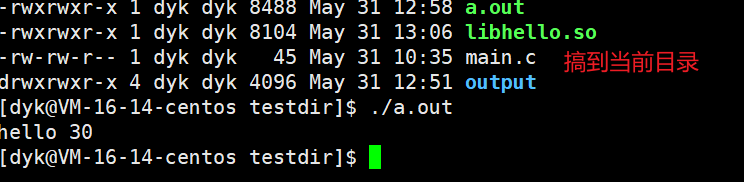
和静态库一样,我们只保留output目录和main.c

然后我们也可以用-I,-L和-l三个选项来生成可执行文件,如下图:

为什么呢,我们ldd a.out可以发现gcc默认使用 /lib64目录下的动态库而不是我们output目录里的那个:
当我们把.so搞到当前目录下发现又能用了。如下图:
如果我们只有静态库,gcc只能针对该库进行静态链接,如果我强转使用静态库,只能gcc main.c -I output/include -L output/lib -lhello -static 摈弃默认优先使用动态库的原则,而是直接使用静态库的方案。如果动静态库都存在,gcc默认用动态库
问题一:那为什么动态库运行报错了呢?
根据1.2 的动态库原理可知,我们的程序和库是分批加载的,加载程序的时候动态库未加载,所以会报错
问题二:gcc编译的时候我不是已经告诉你库的位置了吗?
这里的“你”指的是gcc,你只是告诉了gcc库的位置,没有告诉可执行程序,所以你需要告诉你的加载器的位置
3.3 正确使用动态库三种方法
3.3.1 方法一:添加系统环境变量
与动态库有关的环境变量名为:LD_LIBRARY_PATH,其中LD是加载的意思,LIBRARY就是库的意思。
我们可以先查找我们库的路径,然后添加到该环境变量中,如下图:

但是该环境变量有缺点,就是当shell关闭后,环境变量就重置了
3.3.2 方法二:改配置文件
系统中存在一个默认的动态库搜搜路径:ls /etc/ld.so.conf.d/。我们只需要在这个路径下也创建一个.conf后缀的文件,然后把我们的库文件的路径vim写到里面就可以了,如下图:
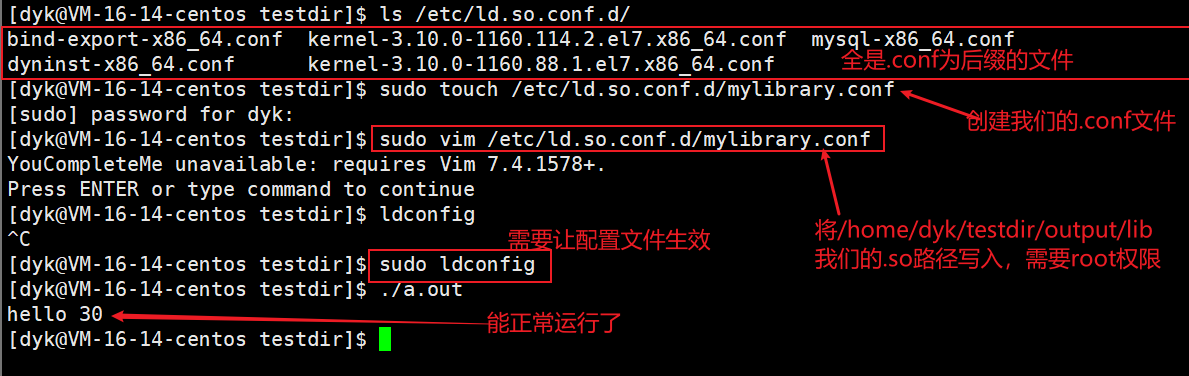
(建议测试完就rm掉,因为不建议改配置文件)
sudo rm /etc/ld.so.conf.d/mylibrary.conf 3.3.3 方法三:软链接方案
我们ldd a.out发现它默认使用的是动态库,且动态库路径为 /lib64/libhello.so,但是它找不到这个嘛,那么我们就用一个软链接将它那个.so和我们这个.so链接起来就好了,如下图:
sudo ln -s /home/dyk/testdir/output/lib/libhello.so /lib64/libhello.so (其实也可以直接把我们的libhello.so拷贝到这个目录下,也能正常运算a.out)
(其实也可以直接把我们的libhello.so拷贝到这个目录下,也能正常运算a.out)
五,一些问题解答
5.1 为什么gcc编译的时候没有指明过库名也能编译?
gcc就是用来编译C与语言的,gcc编译时默认就是找到C标准库,但是我们要链接的是哪一个库,编译器是不知道的,所有需要使用 -l 选项指明链接库文件路径下的具体的库名
5.2 为什么要有库?
站在使用库的人的角度来看,库的存在能大大减少开发的周期,大步幅提高软件本身的质量
站在编写库的人得角度,它得任务就是编写库,只需要关系库得实现,不关心库得使用,能使减少编写库得人的工作量,也能提高库的质量
5.3 进程是如何访问到库中的所有函数的?
每一个动态库被加载到内存,映射到进程的地址空间,映射的位置可能是不一样的,但是因为库里面是相对地址,每一个函数定位采用的是偏移量的方式。
换句话说,只要知道了这个库的相对地址,库的起始地址,就可以通过库的起始地址和虚拟地址 + 函数偏移量,就可以在自己的地址空间中访问库的所有函数了