文章目录
- 前言
- 一、文本相似度算法的选择
- 二、常见的文本相似度算法介绍
- 三、使用示例
- 1、引入jar包
- 2、方法示例
- 3、Jaccard源码剖析
- 4、Jaccard源码解释
- 写在最后
前言
产品今天提了个需求,大概是这样的,来,请看大屏幕。。。额。。。搞错了,重来!来,请看需求原型
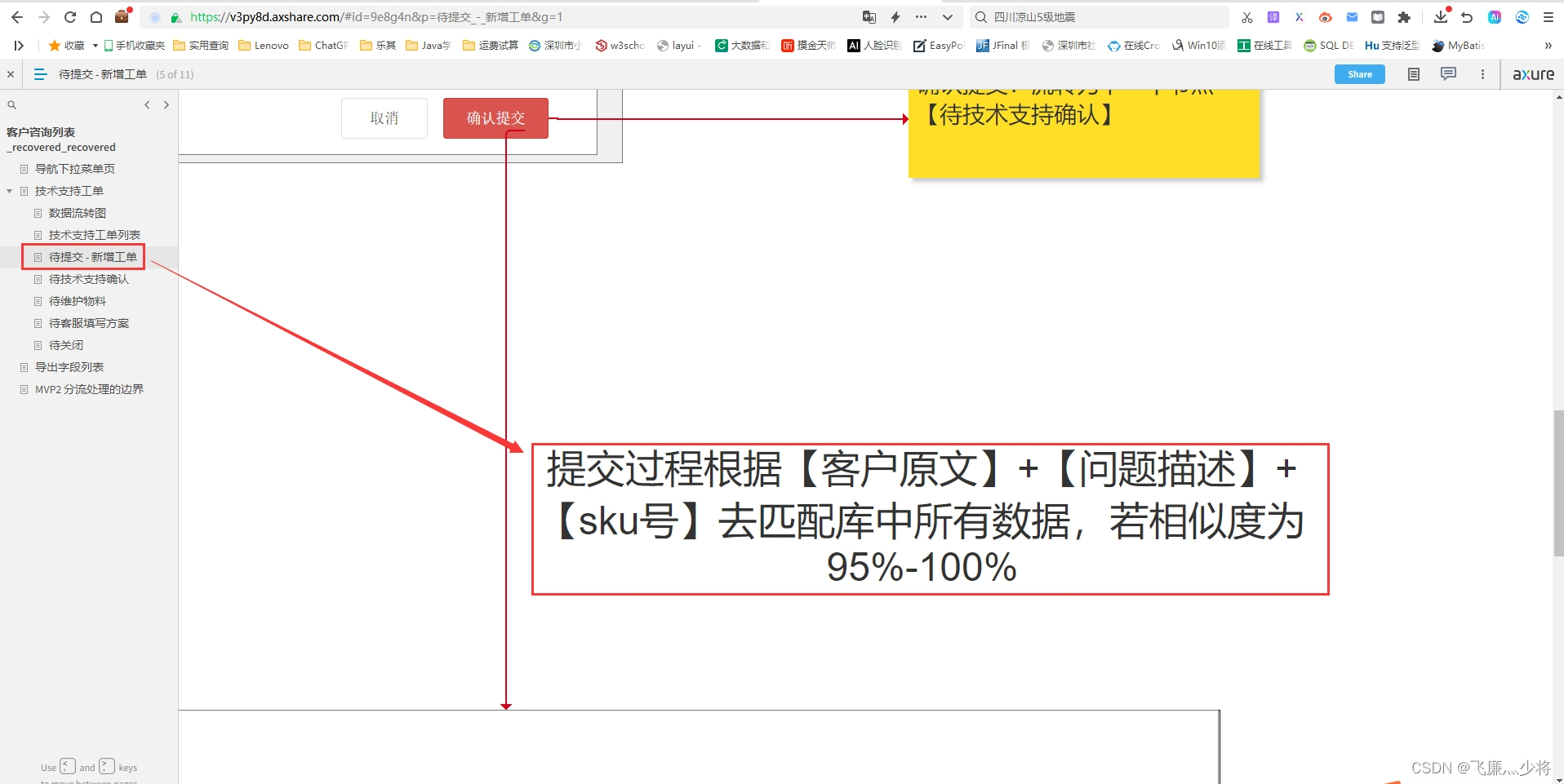
需求原型清晰明了,就不做过多解释了
一、文本相似度算法的选择
文本相似度其实很好理解,按照字面意思,就是两个字符串比较,根据一定的规则来返回两个字符串的相似度。
按照需求来说的话,我需要的只是文本的匹配,对于准确性的要求可能没有那么高,所以,这里选择Apache Jaccard的算法就能满足需求
二、常见的文本相似度算法介绍
1.Levenshtein距离: Levenshtein距离算法在计算字符串相似度时需要考虑所有的插入、删除和替换操作,因此对于长字符串来说,时间复杂度较高。然而,这个算法比较准确,能够捕捉到字符串间的细微差异。(后面只会说一下调用示例,不会过重说明)
2.Jaccard相似度:Jaccard相似度算法计算集合的交集和并集的比值,是一种基本的相似度度量。它对字符串长度不敏感,计算速度相对较快。但是,它对于字符顺序不敏感,并且只考虑字符出现与否,而不考虑出现的频率。 (这里着重说明一下)
3.Cosine相似度: Cosine相似度算法将字符串视为向量,并计算它们的夹角余弦值。这个算法在计算文本相似度时,考虑了字符的频率和顺序。它也适用于处理较长的字符串,但在比较两个字符串之间的相似度时,需要先将其向量化,因此相对复杂一些。(其实Cosine相似度我也看了下源码,也度娘了一下其中的原理,由于个人数学不好,看到一大串的数学公式,感觉头都大了,就没深究^ o ^。感兴趣的同学可以自行度娘,并深入研究一下 )
三、使用示例
1、引入jar包
Levenshtein、Jaccard和Cosine都是 Apache公司的,所以引入一个就可以了
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-text</artifactId><version>1.10.0</version></dependency>
2、方法示例
Jaccard相似度: 用于计算两个集合之间的相似度,可以将字符串视为字符的集合,计算它们的交集和并集的比值。Jaccard相似度的取值范围是0到1,值越接近1表示相似度越高。
Jaccard示例如下:
import org.apache.commons.text.similarity.JaccardSimilarity;// Jaccard文本相似度
public static void main(String[] args) {String str1 = "收到钢化膜其中一张破裂+收到钢化膜其中一张破裂要求补发一张+3191";String str2 = "收到后钢化膜有一张碎了角+收到后钢化膜有一张碎了角,请补发+3191";// Jaccard匹配文本相似度JaccardSimilarity jacc = new JaccardSimilarity();Double jaccardSimilarity = jacc.apply(str1, str2);System.out.println("Jaccard===>文本相似度:" + jaccardSimilarity);
}
Jaccard计算结果:

Levenshtein距离示例如下:
Levenshtein距离:也称为编辑距离,用于计算两个字符串之间的最小编辑操作次数(插入、删除、替换)来转换一个字符串为另一个字符串。编辑距离越小,表示两个字符串越相似。
import org.apache.commons.text.similarity.JaccardSimilarity;// Jaccard文本相似度
public static void main(String[] args) {String str1 = "收到钢化膜其中一张破裂+收到钢化膜其中一张破裂要求补发一张+3191";String str2 = "收到后钢化膜有一张碎了角+收到后钢化膜有一张碎了角,请补发+3191";int distance = LevenshteinDistance.getDefaultInstance().apply(str1, str2);double levenshteinSimilarity= 1 - (double) distance / Math.max(str1.length(), str2.length());System.out.println("Levenshtein===>文本相似度:" + levenshteinSimilarity);
}
Levenshtein计算结果:

3、Jaccard源码剖析
import org.apache.commons.text.similarity.JaccardSimilarity;public static void main(String[] args) {String str1 = "收到钢化膜其中一张破裂+收到钢化膜其中一张破裂要求补发一张+3191";String str2 = "收到后钢化膜有一张碎了角+收到后钢化膜有一张碎了角,请补发+3191";int leftLength = str1.length();int rightLength = str2.length();if (leftLength == 0 && rightLength == 0) {System.out.println("文本相似度:" + 1.0);} else if (leftLength != 0 && rightLength != 0) {Set<Character> leftSet = new HashSet();for (int i = 0; i < leftLength; ++i) {leftSet.add(str1.charAt(i));}System.out.println("leftSet内容:" + JSONObject.toJSONString(leftSet));System.out.println("leftSet的Size:" + leftSet.size());Set<Character> rightSet = new HashSet();for (int i = 0; i < rightLength; ++i) {rightSet.add(str2.charAt(i));}System.out.println("rightSet内容:" + JSONObject.toJSONString(rightSet));System.out.println("rightSet的Size:" + rightSet.size());Set<Character> unionSet = new HashSet(leftSet);unionSet.addAll(rightSet);System.out.println("unionSet内容:" + JSONObject.toJSONString(unionSet));System.out.println("unionSet的Size:" + unionSet.size());int intersectionSize = leftSet.size() + rightSet.size() - unionSet.size();System.out.println("intersectionSize的Size:" + intersectionSize);double calRes = 1.0 * (double) intersectionSize / (double) unionSet.size();System.out.println("文本相似度:" + calRes);} else {System.out.println("文本相似度:" + 0.0);}
}
4、Jaccard源码解释
该函数用于计算两个字符串的文本相似度。使用字符集来表示字符串,并计算两个字符串的交集和并集,然后根据交集和并集的大小计算相似度。具体步骤如下:
- 初始化两个字符串str1和str2。
- 计算两个字符串的长度,分别保存在leftLength和rightLength变量中。
- 如果两个字符串长度都为0,则输出相似度为1.0。
- 如果两个字符串长度都不为0,则进行以下操作:
a. 创建一个字符集leftSet,将str1中的每个字符添加到leftSet中。
b. 输出leftSet的内容和大小。
c. 创建一个字符集rightSet,将str2中的每个字符添加到rightSet中。
d. 输出rightSet的内容和大小。
e. 创建一个字符集unionSet,并将leftSet中的元素复制到unionSet中。
f. 将rightSet中的元素添加到unionSet中。
g. 输出unionSet的内容和大小。
h. 计算交集的大小:intersectionSize = leftSet的大小 + rightSet的大小 - unionSet的大小。
i. 计算相似度:calRes = (double) intersectionSize / (double) unionSet的大小。
j. 输出相似度。 - 如果两个字符串长度不一致,则输出相似度为0.0。
写在最后
最佳算法的选择取应取决于实际应用中具体情况和要求,同时需要考虑多个方面,如算法的复杂度、字符串长度、算法的适用性、是否需要分词等等。
如果仅仅是需要计算几个短字符串之间的相似度,Jaccard相似度可能会是一个好的选择。
如果是需要捕捉字符串细微的差异并进行较高精度的匹配,Levenshtein距离可能会更合适。
如果需要处理的是文本数据,Cosine相似度可能是更好的选择。
此外,如果需要对于大规模的字符串匹配需求(如搜索引擎),更复杂的算法(如基于索引的搜索算法)可能会有更适合的算法。
原创不易,望一键三连 (^ _ ^)