pdf拆分成有图和无图的pdf(方便打印)
原因
打印图片要彩印,每次都要手动弄,打印的时候很麻烦;
随着打印次数的增加,时间就越来越多
为解决此问题,使用python写一个exe解决这个问题
历程
- 找一个python的GUI界面
- 找到
tkinter - 寻找拖拽文件的依赖
tkinterdnd2 - 找打包python打包成exe的
pyinstaller依赖 - 打包异常,移除tkinter图标
- tkinterdnd2打包exe运行异常,移除
tkinterdnd2 - 使用
windnd替换tkinterdnd2实现文件拖拽 - 文件太宽采用A3打印,所以扩展输出类型
- 打包文件
pyinstaller --onefile --windowed --icon=pdf.ico .\ChangePDF.py打包
exe

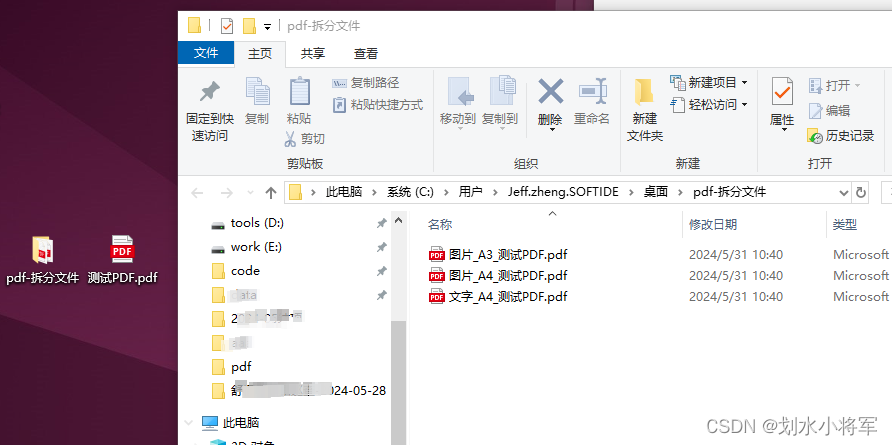
源码
'''
@Author: Jeff.zheng
@Date : 2024/5/28
@Desc : 读取PDF,拆分成两个有图像和无图像的文件;
'''
import os
import shutil
import tkinter as tk
import fitz
import windnd# 输入
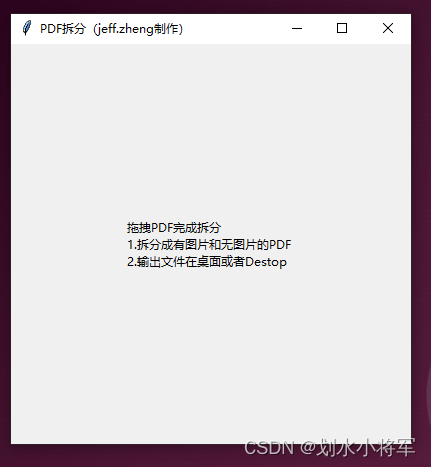
def readPDF(pdfPath):fileName = os.path.splitext(os.path.basename(pdfPath))[0]pdfDoc = fitz.open(pdfPath)picturePDFA4 = fitz.open()picturePDFA3 = fitz.open()wordPDF = fitz.open()for pageNum in range(len(pdfDoc)):# 选择当前页page = pdfDoc[pageNum]image_list = page.get_images(full=True) # 获取页面上所有图片的信息# 检查是否有图片if image_list:print(f"Page {pageNum + 1} contains images.")width = page.rect.widthprint(f"{pageNum + 1} 宽度==>", width)if width > 700:print("A3")picturePDFA3.insert_pdf(pdfDoc, from_page=pageNum, to_page=pageNum)else:print("A4")picturePDFA4.insert_pdf(pdfDoc, from_page=pageNum, to_page=pageNum)else:wordPDF.insert_pdf(pdfDoc, from_page=pageNum, to_page=pageNum)print(f"Page {pageNum + 1} does NOT contain images.")if len(picturePDFA4) > 0 or len(wordPDF) > 0 or len(picturePDFA3) > 0:initDir()if len(picturePDFA4) > 0:writePDF(picturePDFA4, "图片_A4_" + fileName)root.after(2000, initLabel)if len(picturePDFA3) > 0:writePDF(picturePDFA3, "图片_A3_" + fileName)root.after(2000, initLabel)if len(wordPDF) > 0:writePDF(wordPDF, "文字_A4_" + fileName)root.after(2000, initLabel)def initLabel():changeLabel(label, "拖拽PDF完成拆分 \n1.拆分成有图片和无图片的PDF \n2.输出文件在桌面或者Destop", "black")def initDir():needPath = os.path.join(os.path.expanduser("~"), "Desktop") + '\\pdf-拆分文件'if not os.path.exists(needPath):os.makedirs(needPath)else:try:shutil.rmtree(needPath)os.makedirs(needPath)print(f"{needPath} 已被成功删除。")except OSError as e:print(f"删除{needPath}时发生错误: {e.strerror}")# 输出
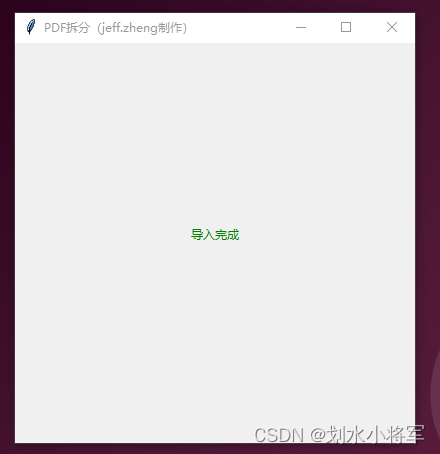
def writePDF(pdfFile, pdfName):needPath = os.path.join(os.path.expanduser("~"), "Desktop") + '\\pdf-拆分文件'savePath = os.path.join(needPath, f"{pdfName}.pdf")pdfFile.save(savePath)pdfFile.close() # 关闭新文档def draggedFiles(files):filePath = '\n'.join((item.decode('gbk') for item in files))fileType = os.path.splitext(os.path.basename(filePath))[1].lower()if fileType == '.pdf':readPDF(filePath)changeLabel(label, "导入完成\n", "green")else:changeLabel(label, "导入失败\n 1.请导入PDF,不支持其他格式\n 2.检查格式,请重新拖放文件 \n", "red")def changeLabel(myLabel, text, fg):myLabel.config(text=text)myLabel.config(fg=fg) # 绿色if __name__ == '__main__':root = tk.Tk()root.title("PDF拆分(jeff.zheng制作)")root.geometry("400x400")# 调用函数创建居中文本的Labeltext = "拖拽PDF完成拆分 \n1.拆分成有图片和无图片的PDF \n2.输出文件在桌面或者Destop"frame = tk.Frame(root, padx=10, pady=10) # 创建一个带有内边距的Frame以帮助居中frame.pack(fill=tk.BOTH, expand=True) # 让Frame填充父容器并扩展# 计算Frame的宽度和高度,以便根据这些尺寸来定位Labelframe.update_idletasks() # 确保frame尺寸已经计算label = tk.Label(frame, text=text, justify=tk.LEFT, anchor='w') # 设置文本左对齐label.place(relx=0.5, rely=0.5, anchor='center') # 使用place定位,通过relx和rely实现垂直居中windnd.hook_dropfiles(root, func=draggedFiles)# 运行Tkinter事件循环root.mainloop()exe下载地址
https://download.csdn.net/download/qq_44309969/89380597