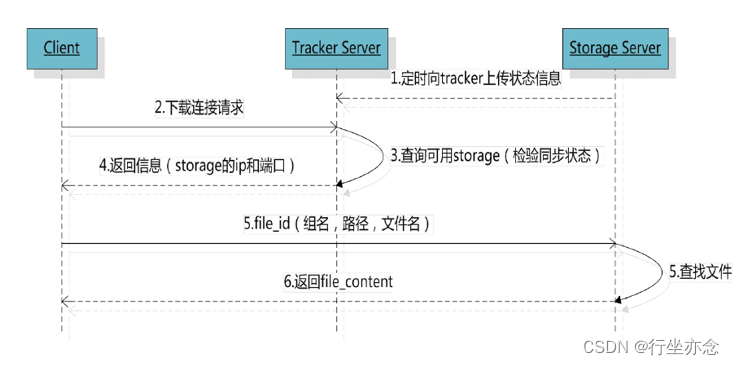
1、Pandas 连接
Pandas 连接的操作实例
Pandas具有与SQL等关系数据库非常相似的功能齐全的高性能内存中连接操作。
Pandas提供单个功能merge作为DataFrame对象之间所有标准数据库联接操作的入口点
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True)
在这里,我们使用了以下参数:
left − 一个DataFrame对象。
right − 另一个DataFrame对象。
on − 列(名)加入上。必须在左右DataFrame对象中都找到。
left_on − 左侧DataFrame中的列用作键。可以是列名,也可以是长度等于DataFrame长度的数组。
right_on − 右侧DataFrame中的列用作键。可以是列名,也可以是长度等于DataFrame长度的数组。
left_index − 如果为True,则使用左侧DataFrame的索引(行标签)作为其连接键。如果DataFrame具有MultiIndex(分层),则级别数必须与右侧DataFrame中的连接键数匹配。
right_index − 相同的使用作为left_index为正确的数据帧。
how − “左”,“右”,“外”,“内”之一。默认为内部。每种方法已在下面描述。
sort − 排序的结果数据框中加入字典顺序按键。默认情况下为True,在许多情况下,设置为False将大大提高性能。
现在让我们创建两个不同的DataFrame并对其执行合并操作。
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(left)
print(right)
运行结果
id Name subject_id
0 1 Alex sub1
1 2 Amy sub2
2 3 Allen sub4
3 4 Alice sub6
4 5 Ayoung sub5id Name subject_id
0 1 Billy sub2
1 2 Brian sub4
2 3 Bran sub3
3 4 Bryce sub6
4 5 Betty sub5
1.1、在一个键上合并两个数据框
import pandas as pd
left = pd.DataFrame({'id': [1, 2, 3, 4, 5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id': ['sub1', 'sub2', 'sub4', 'sub6', 'sub5']})
right = pd.DataFrame({'id': [1, 2, 3, 4, 5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id': ['sub2', 'sub4', 'sub3', 'sub6', 'sub5']})
print(pd.merge(left, right, on='id'))
运行结果
id Name_x subject_id_x Name_y subject_id_y
0 1 Alex sub1 Billy sub2
1 2 Amy sub2 Brian sub4
2 3 Allen sub4 Bran sub3
3 4 Alice sub6 Bryce sub6
4 5 Ayoung sub5 Betty sub5
1.2、在多个键上合并两个数据框
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left,right,on=['id','subject_id']))
运行结果
id Name_x subject_id Name_y
0 4 Alice sub6 Bryce
1 5 Ayoung sub5 Betty
1.3、合并使用“how”参数
合并的how参数指定如何确定要在结果表中包括哪些键。如果左侧或右侧表中均未出现组合键,则联接表中的值为NA。
这里的一个总结如何选择和他们的SQL等价的名字:
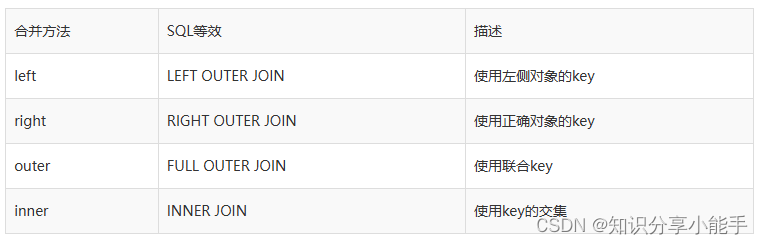
1.4、左连接
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left, right, on='subject_id', how='left'))
运行结果
id_x Name_x subject_id id_y Name_y
0 1 Alex sub1 NaN NaN
1 2 Amy sub2 1.0 Billy
2 3 Allen sub4 2.0 Brian
3 4 Alice sub6 4.0 Bryce
4 5 Ayoung sub5 5.0 Betty
1.5、右连接
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left, right, on='subject_id', how='right'))
运行结果
id_x Name_x subject_id id_y Name_y
0 2.0 Amy sub2 1 Billy
1 3.0 Allen sub4 2 Brian
2 NaN NaN sub3 3 Bran
3 4.0 Alice sub6 4 Bryce
4 5.0 Ayoung sub5 5 Betty
1.6、外连接
import pandas as pdleft = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})print(pd.merge(left, right, how='outer', on='subject_id'))
运行结果
id_x Name_x subject_id id_y Name_y
0 1.0 Alex sub1 NaN NaN
1 2.0 Amy sub2 1.0 Billy
2 NaN NaN sub3 3.0 Bran
3 3.0 Allen sub4 2.0 Brian
4 5.0 Ayoung sub5 5.0 Betty
5 4.0 Alice sub6 4.0 Bryce
1.7、内连接
连接将在索引上执行。联接操作接受调用它的对象。因此,a.join(b)不等于b.join(a)。
import pandas as pdleft = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})print(pd.merge(left, right, on='subject_id', how='inner'))
运行结果
id_x Name_x subject_id id_y Name_y
0 2 Amy sub2 1 Billy
1 3 Allen sub4 2 Brian
2 4 Alice sub6 4 Bryce
3 5 Ayoung sub5 5 Betty

![[240605] FreeBSD 发布 v14.1 | ChatGPT 出现故障,部分用户无法使用](https://img-blog.csdnimg.cn/direct/c13fc962611d4adbbba6759e961935a8.png#pic_center)