计算机的发展历程
世界上的第一个计算机
冯诺依曼机构体系
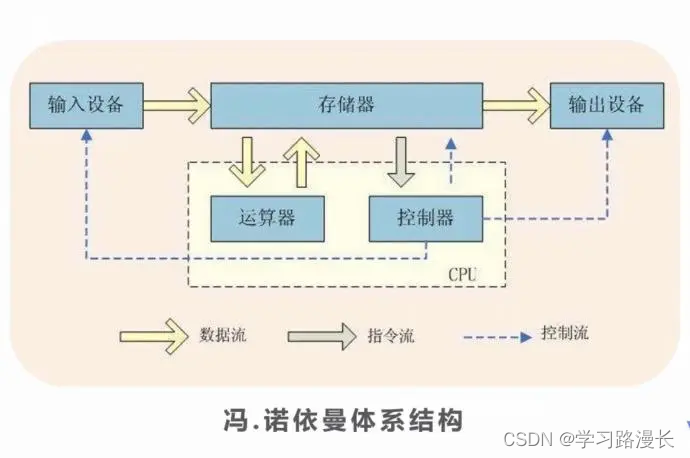
1.存储器
(包括内存(存储空间小,访问速度快,成本高,掉电后数据丢失)
外存(硬盘,软盘,U盘,光盘)),存储空间小,访问速度慢,成本低,掉电后数据仍在
2.CPU(中央处理单元,计算机最核心的部分,用于算术运算和逻辑判断),
关于CPU的主流架构
1.x86/x64架构,给桌面端/服务器来使用的
2.arm架构 给移动端/嵌入式使用的,性能更弱,功耗低
3.RISC-V(V是罗马数字5)一套开源的CPU指令架构
关于CPU的核心参数
1.核心数可以查看自己的任务管理器里的性能
最早的cpu都是单个核心(CPU里面只有一个人在干活,)
2.频率:cpu的运算速度,使用频率来描述,可以理解成一秒钟执行多少个指令(机器语言(二进制)=>汇编语言(单词符号),最终都要翻译成cpu上执行的二进制指令),CPU的频率会根据任务量的多少进行调整,不同的cpu支持的指令是不同的,x86/arm的指令是不能通用的
cpu中的寄存器:存储数据靠:内存和硬盘,实际上,cpu在运算时,先把数据从内存读到cpu里,才能进行运算,寄存器就是cpu存储数据的部分,存储空间比内存更小,速度也比内存更快(好几个数量级),断掉后丢失数据,成本也比内存更高
先打cpu引入了缓存,分为L1,L2,L3,空间依次增大,速度依次降低,某个内存的数据经常使用,寄存器放不下,就可以放到缓存中,数据使用的频率越高放在L1,依次类推缓存对于某些场景的性能提升非常大
cpu执行指令的基本过程
一个cpu能执行那些指令,可以认为是cpu最初设计的时候,就已经写死了
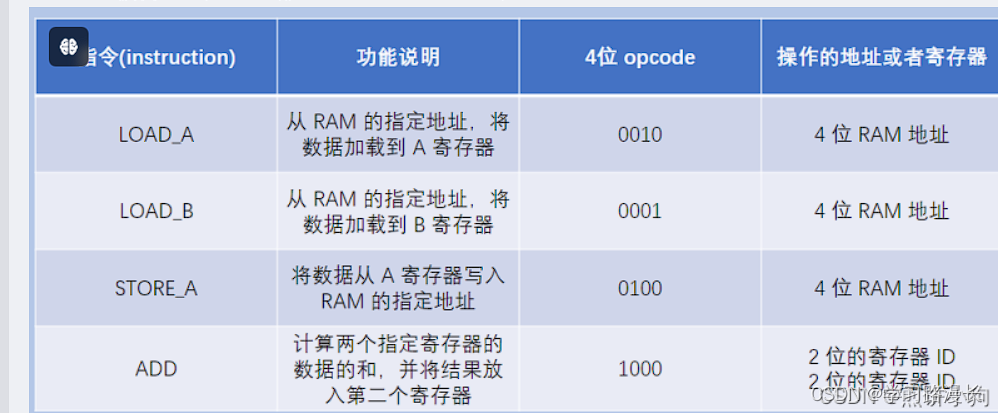
假设每个指令只有8个bit,前四个bit是操作码(opcode),表示指令是干啥的,后4个bit是操作数(类似于参数)
给定一段的内存空间,以及里面的数据,此处可以认为程序计数器从0开始,接下来从0号地址开始执行指令,一个地址对于一个数据
我们要知道用编程语言写好的文件,先编译成可执行文件(exe)(包含了程序执行时执行的指令和依赖的数据),进行双击运行exe时,操作系统就会把exe加载到内存当中,
在cpu中有一个特殊的寄存器"程序计数器"(在exe加载到内存后,就能被系统自动设置好),保存了接下来要从那个位置开始执行指令,同时随着指令的执行,这里的值也会随之更新,默认情况下是自增加一,如果遇到跳转类语句则会设置成其他的值,
执行指令的三个重要阶段
1.取指令(cpu从内存中读取到指令内容到cpu内部.有专门的寄存器保存读取到的指令,不是上述的寄存器a,b)
2.解析指令,识别出指令是干啥的,以及对应的功能和操作数.
3.执行指令
初始情况下程序计数器的值为0,
通过一个简单的例子了解一下cpu的执行流程
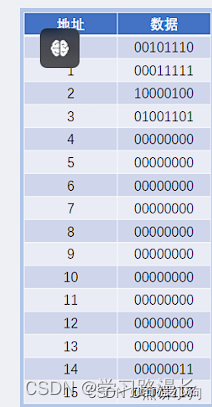
执行地址为0的指令
1).读取指令:那么读取第一个指令,地址为0,数据为00101110
2)解析指令:,前4位0010(LOAD_A)是操作码,后四位1110是操作数,把1110(表示了一个内存的地址,转化为十进制是14)地址的数据读取到寄存器A当中,
3),执行指令, 把地址位1110(十进制是14)的数据加载到寄存器A当中,A的值因该是00000011)(十进制应该是3),
第一条指令执行完成后,系统就会自动把程序计数器++从0->1
执行地址为1的指令
1).读取指令:那么读取第二个指令,地址为1,数据为00011110
2)解析指令:,前4位0001(LOAD_B)是操作码,后四位1111是操作数,把1110(表示了一个内存的地址,转化为十进制是14)地址的数据读取到寄存器B当中,
3),执行指令, 把地址位1110(十进制是14)的数据加载到寄存器B当中,B的值因该是00001110)(十进制应该是14),
第二条指令执行完成后,系统就会自动把程序计数器++从1->2
执行地址为2的指令
1).读取指令:那么读取第三个指令,地址为2,数据为10000100
2)解析指令:,前4位1000(ADD)是操作码,后四位0100是两位寄存器的ID(01是B,00是A),计算这两个寄存器的和并将结果放入到第二个寄存器中
3),执行指令, ,寄存器A存储的值是3,寄存器B的值是14相加结果是17,存储到寄存器A当中,此时寄存器A存储的值是17.
第三条指令执行完成后,系统就会自动把程序计数器++从2->3
执行地址为3的指令
1).读取指令:那么读取第四个指令,地址为3,数据为01001101
2)解析指令:,前4位0100(STORE_A)是操作码,后四位1101是一个操作数,是一个内存的地址
3),执行指令, 将寄存器A中的值写入到1101(十进制是13)的地址,找到地址为13的指令,把数据修改成0001 0001,
第三条指令执行完成后,系统就会自动把程序计数器++从3->4
执行地址为4的指令,数据全为0程序结束,这段指令就算结束,简单完成3+14这个过程
热补丁
对于java程序员来说,一个比较经典的指令集开发的场景,给程序打" 热补丁 ",比如,做一个服务器开发,,这个服务器非常重要,不能重启,最多是在某些特定的场景才能重启,但是发现服务器存在严重bug,但是不能修复bug重启程序,此时就可以考虑热补丁了
写的程序的指令,也是在内存中的,对应的有bug的代码,也是其中的一段指令,找到有bug的代码指令,直接修改这里的指令,修改成没有bug的版本,或者在这个指令上加入跳转指令,让有bug逻辑不去执行,而是新增加一个正确的指令.
操作系统
常见的操作系统
windows,linux,macOs,Android,IOS
每个系统运行的程序都是不一样的(不能兼容的)
你如果在Windows上写了一个程序,之这个程序不能直接在Linux上直接使用,而Java可以"跨平台",是因为JVM,每个操作系统都有自己的JVM,虽然是不同的程序,但是都兼容同样的字节码文件,因此作为Java程序员不必考虑系统的差异
操作系统最重要的事情就是"管理"
1.管理不同的硬件设备
2.给软件提供稳定的运行环境
操作系统内核:操作系统的核心功能集合 ,操作系统 = 内核+配套的应用程序,对于操作系统内核来说,里面包含的功能是非常多的,其中有一个功能与我们开发息息相关,那就是进程管理,
进程的概念
进程:就是运行的程序,谈到一个应用程序,有两种状态,一台计算机就算不打开啥程序,自己也会有很多进程出来
1.没有运行时,是一个exe文件,躺在硬盘上(可执行文件),静态的没有发生改变,而进程会占据资源
2.运行的时候,exe就会被加载到内存中,并且cpu执行里面的指令,
执行进程中的指令,需要硬件资源(CPU,内存,磁盘,网络),进程是操作系统进行资源分配的基本单位
由于一个系统上进程比较多,所以需要管理
1)通过结构体(主流操作系统都是用c/c++写的)/类,把进程的各种属性表示出来,对于Linux来说,使用称为"PCB"进程控制块,这样的结构体来描述信息
2)组织通过数据结构,把上面多个结构体穿起来,并进一步的进行增删改查,简单认为,通过链表的方式,把上述多个PCB串在一起 (简化版本的说法,实际上更加的复杂)
a.创建一个新的进程(exe双击,运行起程序),就相当于创建了一个PCB结构体,并且插入到链表中,
b.销毁进程,就是把PCB从链表中删除,并释放这个结构体
c.查看进程列表,就是遍历这个链表,依次显示出对应的程序
关于PCB的信息
PCB是一个非常复杂的结构体,里面包含的属性非常多
1.PID进程的标识符,同一时刻,一个机器上,多个线程之间,PID唯一的不会重复,系统内部的很多操作,都是通过PID找到的对应的线程
2.内存指针(一组),描述进程依赖的指令和数据都在内存的哪个区域,操作系统,运行exe,就会读取exe的指令和数据,加载到内存中去,侧面表示出,进程的执行,需要一定的内存资源的
3.文件描述符表(顺序表/数组)描述了进程打开了那些文件->对于到硬盘上的数据,侧面反映出进程的执行需要一定的硬盘资源,进程中打开了那些文件,顺序表中就添加一项
进程的调度
操作系统,进程调度的关键,四个字,"分时复用",cpu运行进程1,运行一会cpu运行进程2,由于cpu计算速度非常快,在人们看来就是同时执行,我们称之为"并发执行"
"并行执行":现在有了多核cpu,每个核心和核心之间,微观上也能同时执行不同的进程.
由于并发/并行都是操作系统内核统一调度的,因此平时把并行/并发统称为"并发",对应的编程也成为"并发编程"
以下这几个属性就是用来支持 并发执行,调度过程的
4.进程状态
就绪状态的进程,是可以随时被调到CPU上执行指令的
阻塞状态的进程,无法调度到CPU上执行,之所以阻塞,是因为要做一些其他的工作,比如进行I/O操作(读写硬盘/网卡)已经接触过的进程阻塞,C语言的scanf和Java的Scanner
5.进程优先级
不同的进程,所分配到的资源不一样
6.进程的上下文
分时复用,一个进程执行一会之后,就要从cpu上调度走,过一段时间还会调度会cpu,就要沿着上次执行的结果(把之前执行的中间结果(各种cpu寄存器的值保存起来,已备下次使用)),继续往后执行
上下文对于进程来说,就是寄存器的值,cpu有很多寄存器,上下文会保存到PCB中 PCB是内存的数据把寄存器的值都保存到PCB特定的属性中,下次调度PCB就可以从这里的属性把数据恢复到对应的寄存器中
7.进程的记账信息
优先级的加持下,使不同的进程,吃到的资源,差异越来越大,操作系统,统计每个进程在CPU执行的时间,根据这个来进一步调整调度的策略
这几个属性相互配合,共同的构成了,进程调度的核心逻辑,虽然上述的调度过程是系统内核负责完成的,但是写程序的时候还是会收到影响



![[Redis]List类型](https://img-blog.csdnimg.cn/direct/c8a02bf5e0e64f8e9f97bc65fefdfde3.png)