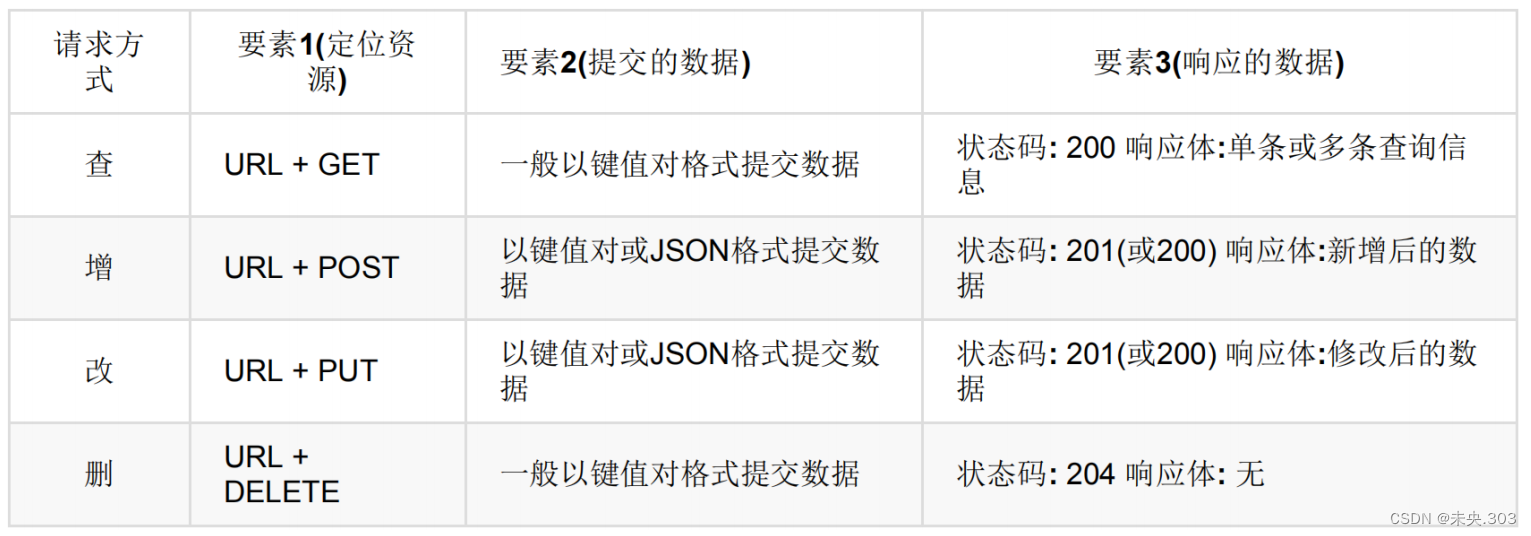
Hive常规操作
hive常用交互命令
-e执行sql语句
[root@master ~]# hive -e "show databases";
-f执行sql脚本
[root@master ~]# hive -f /usr/local/demo.sql
查看hive中输入的所有命令
[root@master ~]# cat ~/.hivehistory
操作库
创建库
语法:
create dtabase 库名称;
案例:
hive> create database demo;
查看库
查看所有数据库
hive> show databases;
查看数据库信息
语法:
desc database 库名称;
案例:
hive> desc database demo;
查看数据库详细信息
语法:
desc database extended 库名称
案例:
hive> desc database extended demo;
使用库
语法:
use 库名称;
案例:
hive> use demo;
修改库
语法:
alter database 库名称 set dbproperties( )
使用alter database命令为某个数据库的dbproperties设置键-值对属性值,用于描述数据库的属性信息,数据库的其他数据信息无法更改,包括数据库所在目录地址
案例:
hive> alter database demo set dbproperties('createtime'='20220620');
删除库
删除空数据库
语法:
drop database 库名称;
案例:
hive> drop database demo;
删除存在的数据库
语法:
drop databse if exists 库名称
案例:
hive> drop database if exists demo;
删除不为空的数据库
语法:
drop database 库名称 cascade;
案例:
hive> drop database demo cascade;
操作表
创建表
语法:
create [external] table [if not exists] table_name
(col_name data_type [comment col_commment],....)
[commetn table_comment]
[partitioned by (col_name data_type [comment col_commnet,]...)]
[cloustered by (col_name,col_name)]
[sorted by (col_name [asc|desc],....)into num_buckets buckets]
[stored as fire_format]
[location hdfs_path]
[like]
- create table :
- 创建一个指定名称的表,如果相同名称的表存在,则抛出异常,用于可以使用
if not exists选项忽略这个异常
- 创建一个指定名称的表,如果相同名称的表存在,则抛出异常,用于可以使用
- external:
- 关键字创建一个外部表,在建表的同时指定一个指向实际数据的路径location,hive创建内部表时,会将数据移动到数据仓库指向的路径;如果创建外部表,仅记录数据所在的路径,不会对数据的位置做任何改变,在删除表时,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
- commnet:
- 为表和列添加注释
- partitioned by
- 创建分区表
- cloustered by
- 创建分桶表
- sorted by
- 桶内排序
- stored as
- 指定存储文件类型,常见的类型有二进制文件(sequencefile),文本(textfile),列式存储格式文件(rcfile),如果文本数据是纯文本,可以使用stored as textfile。如果需要压缩存储,可以使用stored as sequencefile。
- location
- 指定表在hdfs上的存储位置
- like
- 允许用户复制现有的表结构,但不是复制数据
基本数据类型
| 数据类型 | 描述 |
|---|---|
| BOOLEAN | 逻辑布尔值(TRUE/FALSE) |
| TINYINT | 一个字节有符号整数,范围为-128到127 |
| SMALLINT | 两个字节有符号整数,范围为-32768到32767 |
| INT | 四个字节有符号整数,范围为-2147483648到2147483647 |
| BIGINT | 八个字节有符号整数,范围为-9223372036854775808到9223372036854775807 |
| FLOAT | 单精度浮点数,范围为-3.4028235E38到3.4028235E38 |
| DOUBLE | 双精度浮点数,范围为-1.7976931348623157E308到1.7976931348623157E308 |
| STRING | 字符串类型 |
| VARCHAR | 可变长度字符串类型 |
| CHAR | 定长字符串类型 |
| DATE | 日期类型,格式为YYYY-MM-DD |
| TIMESTAMP | 时间戳类型,以秒为单位存储时间戳 |
| BINARY | 二进制数据类型 |
| ARRAY | 数组类型,用于存储一组相同类型的元素 |
| MAP | 映射类型,用于存储键值对 |
| STRUCT | 结构体类型,用于存储不同类型的字段组成的记录 |
| UNIONTYPE | 联合类型,用于表示多个可能的数据类型 |
创建普通表
hive (demo)> create table if not exists student(> id int,> name varchar(20)> calss string> );
VARCHAR和STRING都是用来表示字符串类型的数据。
-
VARCHAR是可变长度字符串类型, -
STRING是固定长度字符串类型。
创建分区表
hive (demo)> create table if not exists demo_tab_01(colume01 string)> partitioned by (colume02 string)> row format delimited> fields terminated by '\t';
create table if not exists demo_tab_01(column01 string): 创建了一个名为demo_tab_01的表,其中包含一个名为column01的列,数据类型为STRING。IF NOT EXISTS语句用于确保在表不存在时才创建该表,避免了重复创建表的情况。partitioned by (column02 string): 指定了表的分区方式。它表示根据名为column02的列进行分区,该列的数据类型为STRING。分区可以帮助提高查询性能,并且可以更有效地管理数据。row format delimited: 指定了数据的行格式为分隔符格式。这意味着Hive将使用特定的分隔符来识别和分隔每行中的字段数据。fields terminated by '\t': 指定了字段之间的分隔符。在这种情况下,字段之间的分隔符是制表符\t,表示字段之间使用制表符进行分隔。
创建外部表
hive (demo)> create external table if not exists demo_tab_02(id int,name string)> row format delimited fields terminated by '\t';
create external table if not exists demo_tab_02(id int, name string): 创建了一个名为demo_tab_02的外部表,其中包含两列,分别是id和name,分别的数据类型分别是整数类型和字符串类型。row format delimited fields terminated by '\t': 指定了数据的行格式为分隔符格式,字段之间的分隔符是制表符\t。这意味着Hive将使用制表符来识别和分隔每行中的字段数据。
删除数据表
语法:
drop table 表名称;
案例:
hive (demo)> drop table student;
修改表
修改内部表为外部表
语法:
alter table 表名称 set tblproperties('external'='true/false')
使用SET TBLPROPERTIES子句来设置表的属性,将其标记为外部表。
external是一个特殊的表属性,用于指示表是否为外部表
案例:
hive (demo)> alter table demo_tab_01 set tblproperties('external'='true');
修改外部表为内部表
语法:
alter table 表名称 set tblproperties('external'='true/false')
案例:
hive (demo)> alter table demo_tab_01 set tblproperties('exterual'='false');
重命名表
语法:
alter table 旧表名称 rename to 新名称;
案例:
hive (demo)> alter table demo_tab_01 rename to demo_new_01;
添加字段信息
语法:
alter table 表名称 add columns(字段 数据类型);
案例:
hive (demo)> alter table demo_tab_02 add columns(age int);
修改字段信息
语法:
alter table 表名称 change column 旧字段 新字段 数据类型;
案例:
hive (demo)> alter table demo_tab_02 change column id new_id string;
替换列
语法:
alter table 表名称 replace columns(字段 数据类型);
案例:
不会修改存储在hdfs中的数据,只是修改元数据的列而已。如果hdfs存储的是string,如果列replace列为int,则查不到对于的数据。
hive (demo)> alter table demo_tab_02 replace columns(age int);
删除表
删除表
语法:
drop table 表名称;
案例:
hive (demo)> drop table demo_new_01;
清空表
语法:
truncate table 表名称;
案例:
只能清空管理表,不能清除外部表
hive (demo)> truncate table demo_new_01;
分区表
概念
分表实际上是对于一个HDFS文件系统上的独立文件,该文件夹是该分区所有的数据文件。hive中的分区就是分目录,把一个大的数据集切割成多个小的数据集,在查询是可以通过where选定指定的分区查询对应的数据
操作
创建分区表
hive (demo)> create table if not exists demo_tab_01(colume01 string)> partitioned by (colume02 string)> row format delimited> fields terminated by '\t';
查看分区信息
hive (demo)> show partitions demo_tab_01;
查看分区表结构
hive (demo)> desc formatted demo_tab_01;
查看分区数据
hive (demo)> select * from demo_tab_01;
hive (demo)> select * from demo_tab_01 where colume01 = 1;
增加单个分区
hive (demo)> alter table demo_tab_01 add partition (colume01 = 'yyyy');
添加多个分区
hive (demo)> alter table demo_tab_01 add partition (colume01 = 'yyyy') partition (colume01 = 'xxxx') partition (colume01 = 'nnnn');
删除单个分区
hive (demo)> alter table demo_tab_01 drop partition (colume01 = 'yyyy');
删除多个分区
hive (demo)>alter table demo_tab_01 drop partition (colume01 = 'yyyy') partition (colume01 = 'xxxx') partition (colume01 = 'nnnn');
操作数据
通过insert语句向表中插入数据
insert into table 表名称 [partition] values(数据)
案例
hive (demo)> insert into table student1 values (1,'zhangsan','hadoop');
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20240604084248_e1532893-2e9d-407f-8490-fcd1c11e3cda
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1717461478463_0001, Tracking URL = http://master:8088/proxy/application_1717461478463_0001/
Kill Command = /usr/local/hadoop-3.3.1/bin/hadoop job -kill job_1717461478463_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2024-06-04 08:43:05,784 Stage-1 map = 0%, reduce = 0%
2024-06-04 08:43:16,233 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.82 sec
MapReduce Total cumulative CPU time: 1 seconds 820 msec
Ended Job = job_1717461478463_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://master:8020/user/hive/warehouse/demo1.db/student1/.hive-staging_hive_2024-06-04_08-42-48_863_8941965166612581309-1/-ext-10000
Loading data to table demo1.student1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.82 sec HDFS Read: 4634 HDFS Write: 88 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 820 msec
OK
_col0 _col1 _col2
Time taken: 29.486 seconds分析执行日志
警告信息:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
这是一个警告信息,提醒用户Hive-on-MR(Hive on MapReduce)在Hive 2中已经被弃用,并可能在将来的版本中不再可用。建议使用不同的执行引擎(例如Spark、Tez)或者使用Hive 1.X版本。
查询信息:
Query ID = root_20240604084248_e1532893-2e9d-407f-8490-fcd1c11e3cda
Total jobs = 3
这是查询的ID以及该查询涉及的总作业数量。
启动作业:
Launching Job 1 out of 3
此时开始启动作业,这是三个作业中的第一个。
作业进度信息:
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1717461478463_0001, Tracking URL = http://master:8088/proxy/application_1717461478463_0001/
由于没有Reduce操作,所以减少任务的数量设置为0。然后开始作业,并提供作业的跟踪URL。
作业运行信息:
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
这是作业运行的信息,第一个阶段(Stage-1)有一个Mapper任务,没有Reducer任务。
作业执行进度:
2024-06-04 08:43:05,784 Stage-1 map = 0%, reduce = 0%
2024-06-04 08:43:16,233 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.82 sec
提供了作业的执行进度,显示了Mapper任务的完成情况。
作业结束信息:
Ended Job = job_1717461478463_0001
作业执行结束。
数据移动和加载信息:
Moving data to directory hdfs://master:8020/user/hive/warehouse/demo1.db/student1/.hive-staging_hive_2024-06-04_08-42-48_863_8941965166612581309-1/-ext-10000
Loading data to table demo1.student1
数据正在被移动到HDFS(Hadoop分布式文件系统)的特定目录,并加载到名为demo1.student1的Hive表中。HDFS通常使用8020端口进行通信,所以hdfs://master:8020/表示数据将被写入到HDFS的master节点,并通过8020端口进行通信
MapReduce任务启动信息:
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.82 sec HDFS Read: 4634 HDFS Write: 88 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 820 msec
显示了启动的MapReduce任务的情况,包括Mapper的数量、累计CPU时间以及HDFS读写情况。
查询结果:
OK
_col0 _col1 _col2
Time taken: 29.486 seconds
插入操作的结果,包括表的字段以及操作所花费的时间。
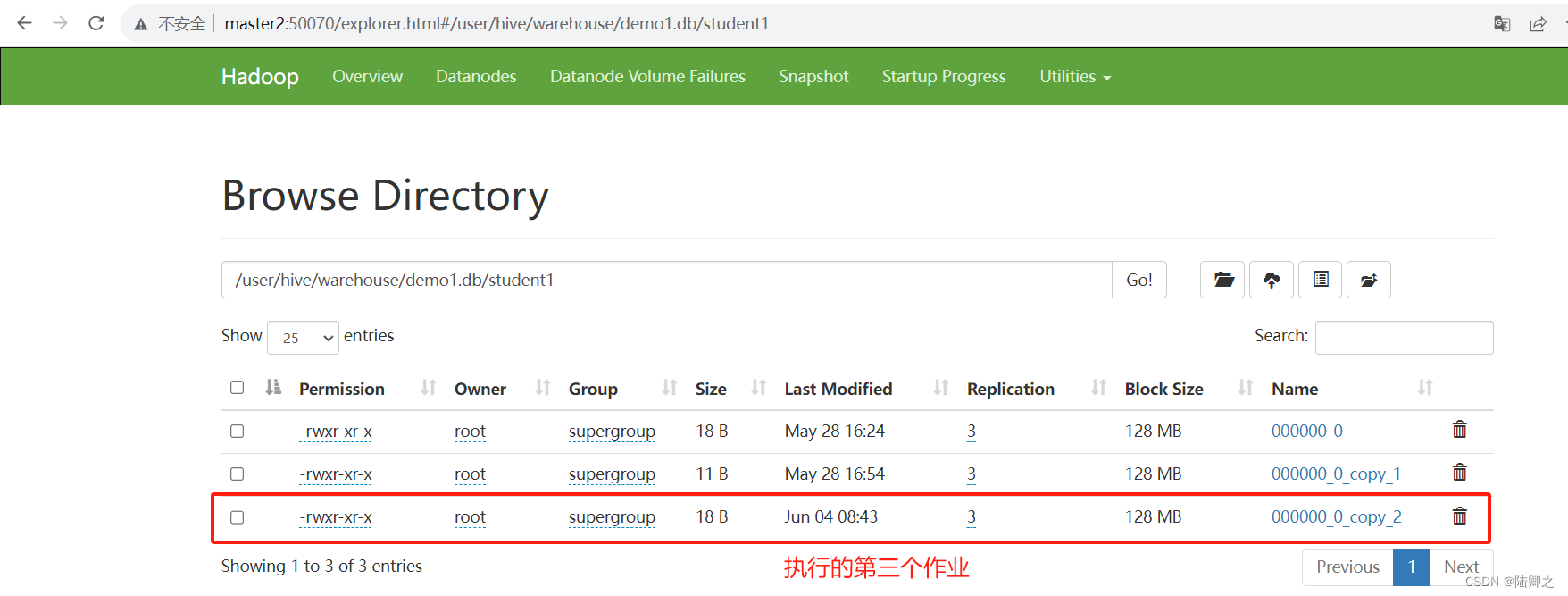
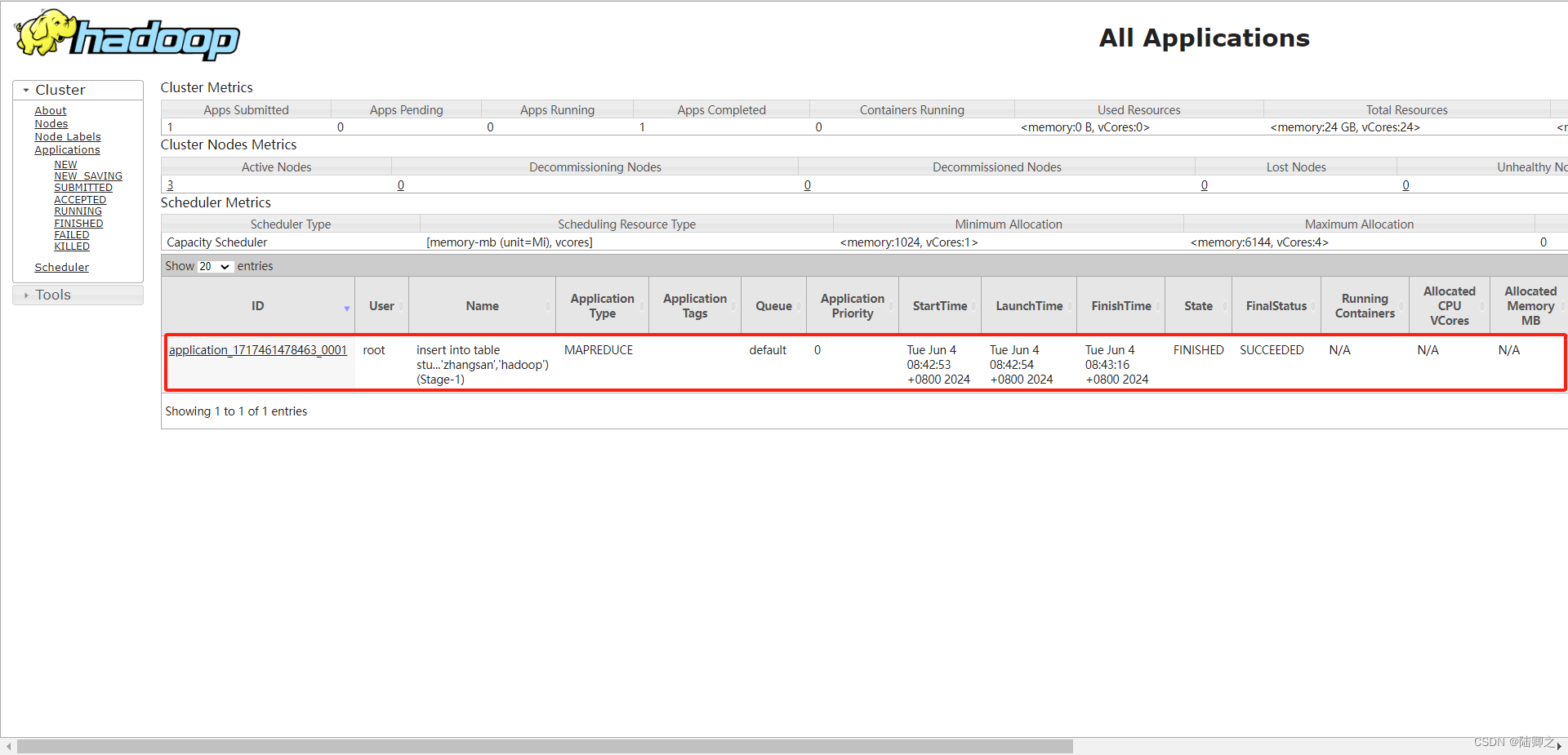
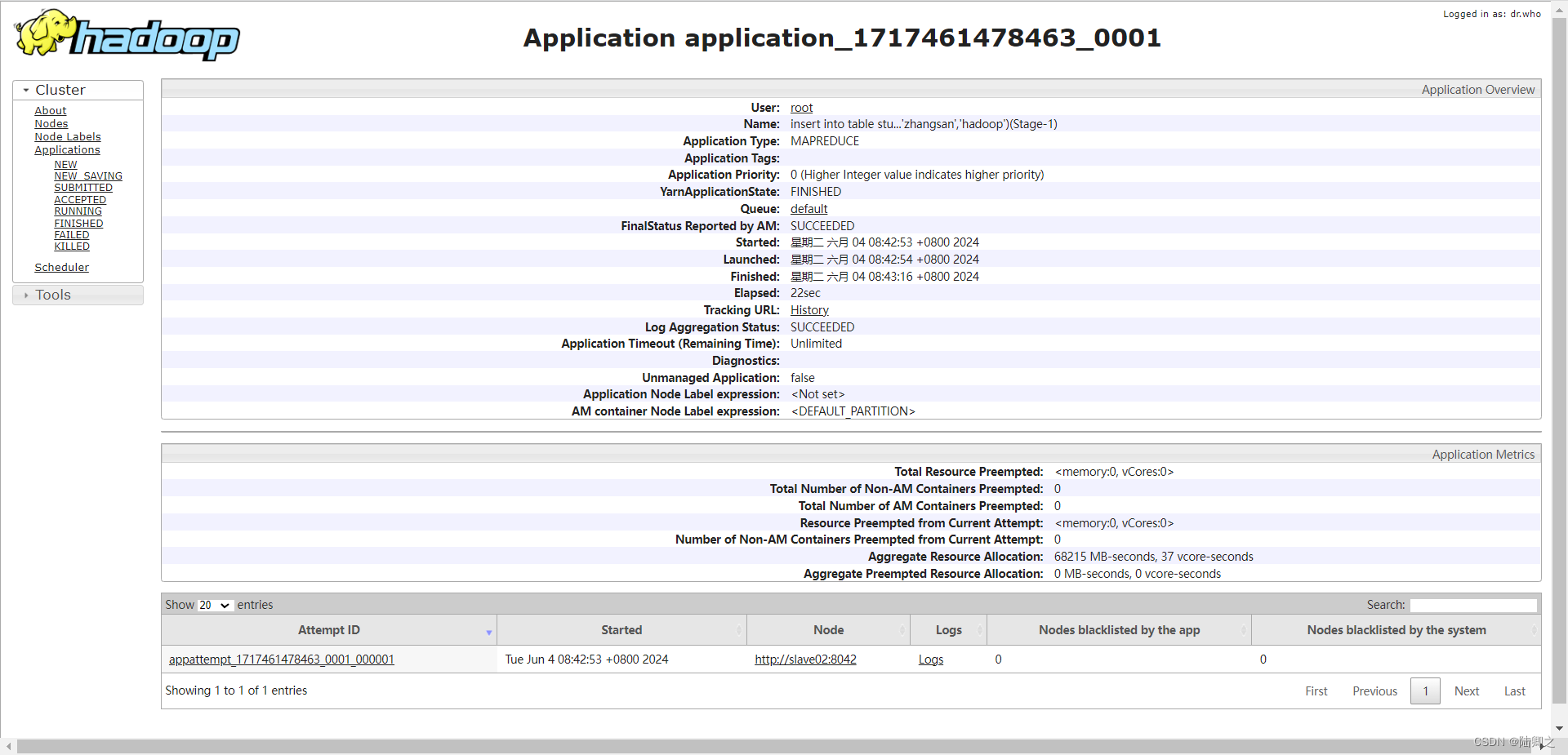
可以看到刚刚的插入语句使用slave02节点执行的
向表中导入数据
load data [local] inpath '路径' [overwirte] into table 表名称 [partition](partcol1=value1.....)]- load data:
- 表示加载数据
- local:
- 表示从本地中加载数据到hive表;否则从hdfs中加载数据到hive表
- inpath:
- 表示数据的路径
- overwirte:
- 表示覆盖表中已有的数据,负责表示追加数据
- into table:
- 表示加载到哪张表
- 表名称:
- 表示具体操作的哪张表
- partition:
- 表示上传到指定的分区中