文章目录
- 前言
- 一、两数之和
- 1.题目解析
- 2.算法原理
- 3.代码编写
- 二、判定是否互为字符重排
- 1.题目解析
- 2.算法原理
- 3.代码编写
- 三、 字⺟异位词分组
- 1.题目解析
- 2.算法原理
- 3.代码编写
- 总结
前言
哈希表是一个存储数据的容器,我们如果想要快速查找某个元素,就可以用哈希表,时间复杂度为O(1)。
一、两数之和
1.题目解析
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
2.算法原理
暴力解法
我们这里有两种暴露解法
解法一:

我们先固定right,left从right位置开始,一直寻找到n-1的位置。如果在某个位置发现了left+right=target。我们就返回这两个下标。否则right++,left=right,继续寻找。一直走到right=n-1为止。
解法二:
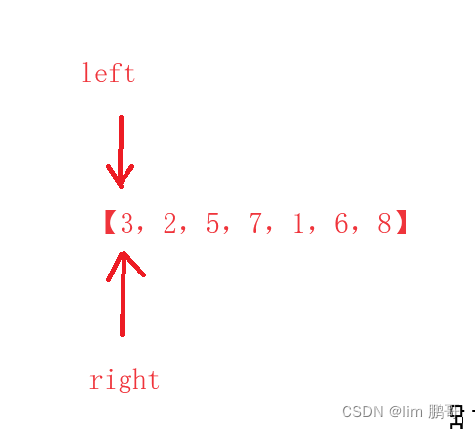
我们同样先固定right, left从0为止开始,一种走到right-1为止。
中间如果找到满足条件的就返回,如果找不到就继续right++,left从0为止开始寻找。一直走到right=n-1为止。
这两种算法时间复杂度为O(n*n),空间复杂度为O(1)
哈希解法
我们利用哈希表可以快速查找到一个值。
我们遇到一个值,先这个值与前面的值进行判断,查看是否有满足条件的。如果不满足,我们把这个值仍在哈希表中继续判断。
如果我们对另一种暴力解法进行优化,我们需要先把整个元素放在哈希表中,再进行二次遍历,因为可能存在元素相同的情况。
比如nums[ ]={2,4,6,-2,10};taarget=8.
r如果我们先固定4时,快速查找一遍,我们就会找到4,这就重复了,题目要求数组中同一个元素在答案里不能重复出现。
我们就只能另加判断处理了。
我们采用这种方法,将元素放入hash,同时见擦汗表中是否已经存在了当前元素所对应的目标元素(t-nums[ i ]),提高效率。
时间复杂度为O(n),空间复杂度O(n),空间换时间。
3.代码编写
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {//通过一个值快速查找到它的下标unordered_map<int,int>mp;int n=nums.size();for(int i=0;i<n;i++){int x=target-nums[i];if(mp.count(x)){return {i,mp[x]};}mp[nums[i]]=i;}return {-1,-1};}
};
二、判定是否互为字符重排
1.题目解析
给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。
示例 1:
输入: s1 = “abc”, s2 = “bca”
输出: true
示例 2:
输入: s1 = “abc”, s2 = “bad”
输出: false
说明:
0 <= len(s1) <= 100
0 <= len(s2) <= 100
2.算法原理
如果能够构成重排,哪个字符串中每个字符出现的次数一定是相同的。
解法1:STL中哈希
我们可以用两个库里的哈希表实现,s1和s2都丢到哈希表中,遍历一遍,判断每个元素的个数是否相同。
这样做很复杂
解法2:数组模拟哈希表
本道题目明确说明了都是小写字母,我们可以开一个大小为26的数组,模拟哈希表的完成。我们只需要进行26次判断就可以了。
解法3:一个哈希表解决
我们可以在第二个解法的基础上,用一个数组完成。
先把s1中的字母放到数组中,再对s2进行遍历,如果在数组中,就进行减减操作。如果减到负数了,说明不匹配,返回false。
小优化:如果s1和s2长度都不相同,肯定不符合要求。
时间复杂度O(n),空间复杂度O(26)
3.代码编写
class Solution {
public:bool CheckPermutation(string s1, string s2) {//小优化if(s1.size()!=s2.size()){return false;}int hash[26]={0};//s1存元素for(auto&e:s1){hash[e-'a']++;}//s2进行--判断for(auto&e:s2){if((--hash[e-'a'])<0){return false;}}return true;}
};
三、 字⺟异位词分组
1.题目解析
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
2.算法原理
互为字母异位词:排完序之后两个单词应该完全相同。
我们可以利用这个特性,将单词按照字典序排序。
排序后,单词相同的话,就划分到同一组中。
排序后单词与原单词需要互相映射,我们可以用哈希表完成。
相同的单词划分到一组,我们可以用vector完成。
3.代码编写
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string,vector<string>>mp;//所有字母异位词分组for(auto&e:strs){//排序string s=e;sort(s.begin(),s.end());mp[s].push_back(e);}//提取结果vector<vector<string>>ret;for(auto& [x,y] : mp){ret.push_back(y);}return ret;}
};
总结
以上就是今天要讲的内容。希望对大家的学习有所帮助,仅供参考 如有错误请大佬指点我会尽快去改正 欢迎大家来评论~~ 😘 😘 😘

![[matlab]折线图之多条折线如何绘制实心圆作为标记点](https://img-blog.csdnimg.cn/img_convert/2d927516fb3bc776d6a495772976fe68.png)