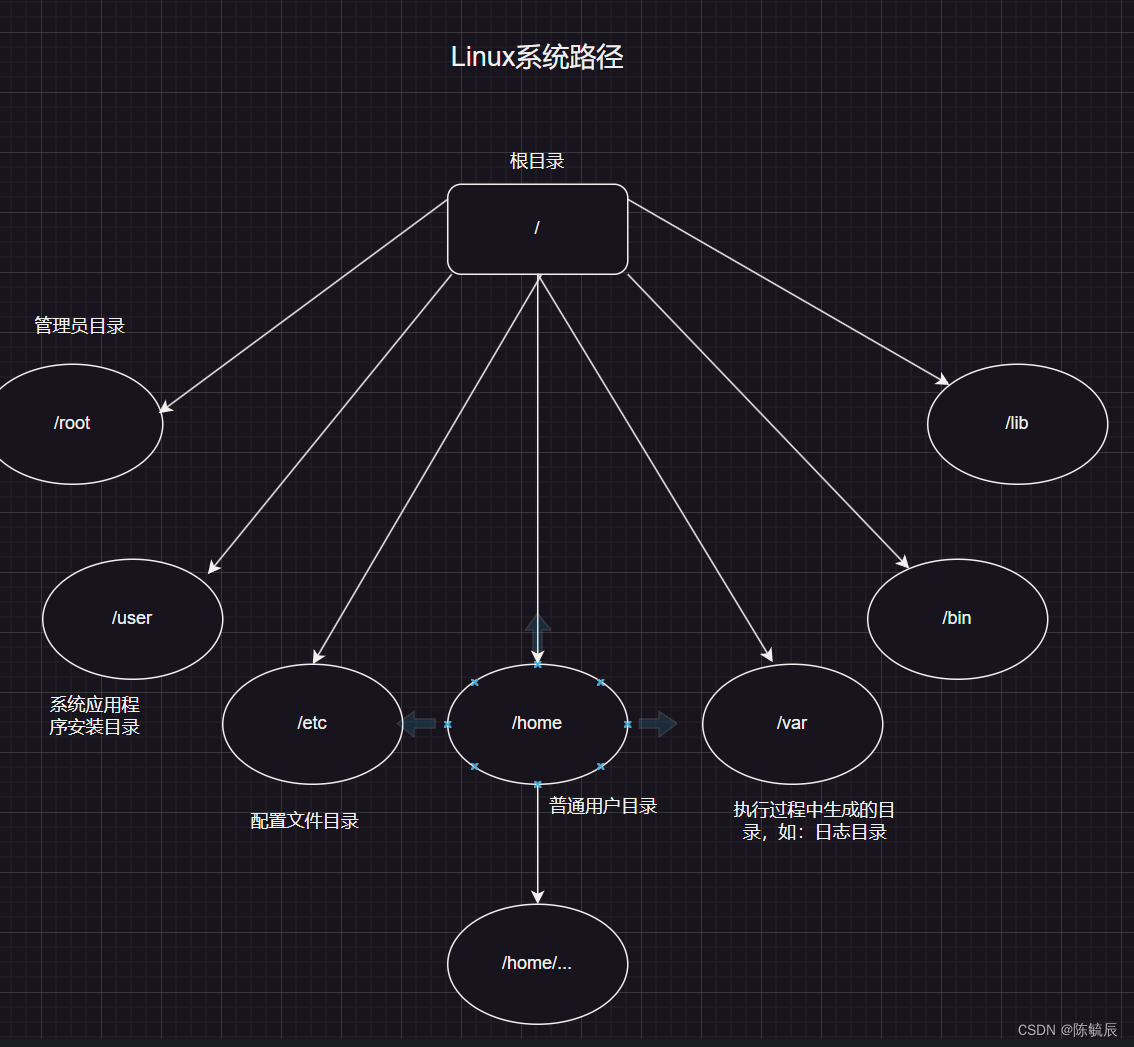
1、什么是buffer/cache ?
buffer/cache其实是作为服务器系统的文件数据缓存使用的,尤其是针对进程对文件存在read/write操作的时候,所以当你的服务进程在对文件进行读写的时候,Linux内核为了提高服务的读写速度,则将会把文件放在此处的buffer/cache中进行缓存使用,由于Linux服务的特点便是任何事物都会以文件的形式进行存在,所以你会发现不管你是否对文件做了大规模的读写,机器的buffer/cache是一直都存在的,并且持续的增高不下,这是因为服务器所产生的网络连接也好,用户协议的(UDP)套接字也好,这部分的数据系统都会为应用程序创建对应的文件描述符,而这些文件描述符的使用,则又都会重新进入buffer/cache中做读写使用,所以这也是你的机器始终都会存在较高buffer/cache的原因,因为所有的文件读写都会用到buffer/cache,在内存合理的情况下。
2、需要注意的一些特点
在服务内存够用的情况下,Linux内核为了加快对文件的读写效率会将文件放入buffer/cache中以保证读写效率,但其实,尽管当你的应用程序对文件的读写运行结束后,buffer/cache也不会自动释放该部分内存,而是作为缓冲进行保留,等到你的服务进程在下一次进行相同文件的读写时就可以直接使用,省去了各种重新进行内存初始化的操作;所以这将会导致,当你的应用进程频繁对不同的文件进行读写时,你会发现服务所可以直接使用的free内存将会越来越少的一个重要原因;难道buffer/cache在这样无休止的缓存当中就不会自动释放?当然不是,当服务器在内存压力较大的情况下时,则将会自动进行内存的回收,作为free空间分给其它进程使用,这其中主要回收的一个内存则是buffer/cache的缓冲区内存块。
3、如何进行手动 buffer/cache 回收?
除了在系统进程内存使用较大压力的情况下进行内存的回收外,我们也可以进行手动的buffer/cache回收,但由于buffer/cache主要是用于文件的读写使用,所以进行文件回收时,一般常伴随系统的IO彪高,因为系统内核也对比cache中的数据与硬盘中的数据是否一致,如果不一致需要写回硬盘,然后才能进行内存的回收。
3.1将内存中数据强制先刷新到磁盘中
sync;
3.2清理Buffer缓存区域
echo 3 > /proc/sys/vm/drop_caches 表示清除pagecache和slab分配器中的缓存对象
echo 1 > /proc/sys/vm/drop_caches:表示清除pagecache。
echo 2 > /proc/sys/vm/drop_caches:表示清除回收slab分配器中的对象(包括目录项缓存和inode缓存)
注:slab分配器是内核中管理内存的一种机制,其中很多缓存数据实现都是用的pagecache。
4、监控报警可用内存空间不足常规的解决方案如下:
增加内存(增加成本)
增加虚拟内存(影响性能)
定期清理缓存(echo 1 > /proc/sys/vm/drop_caches)
5、问题分析
5.1 监控系统负载情况
通过监控系统负载情况(vmstat 1),确定是页面缓存(cache项)占用量大,并且释放页面缓存后,从块设备读入数据量(bi项)会马上增加,如果bi或bo长期不等于0,表示内存不足。

5.2监控io情况
通过监控io情况(iostat -x -k 1)也可以看出

5.3监视磁盘I/O使用状况
基于此可以猜测是有进程在频繁的读取文件导致,监视磁盘I/O使用状况(iotop -oP),释放页面缓存后有几个sed命令读取文件进程占用IO很高。

生产环境遇到服务buffer/cache 过高如何排查是由那几个进程引起的(hcache 的使用方式)
6、使有hcache缓存文件
全局显示10个最大的被缓存文件
[root@java ~]# hcache -top 10
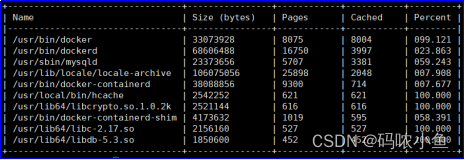
注:查看指定进程ID所使用的buffer/cache的使用情况:hcache -pid 16322

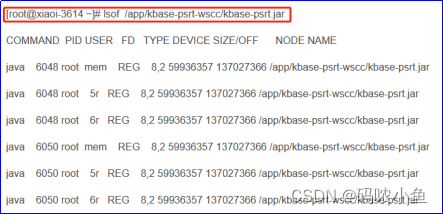
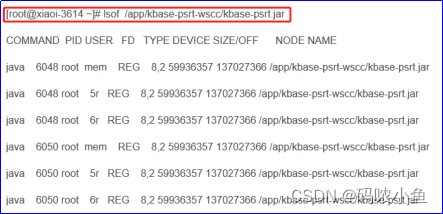
7、使用losf查看当前所开启该文件的所有进程
通过上述所获取到的被缓存最大的文件名称后,可以直接通过 lsof file_name 得到当前所开启该文件的所有进程信息;
7.1显示使用 kbase-psrt.jar 的进程信息
7.2 获取当前进程号所打开的所有文件信息
更多关于lsof的使用,可以参考如下链接:https://www.cnblogs.com/sparkbj/p/7161669.html
8、内存详细信息
存放内存详细信息文件:/proc/meminfo
查看更详细的内存信息:
cat /proc/meminfo|grep -E "Buffer|Cache|Swap|Mem|Shmem|Slab|SReclaimable|SUnreclaim"
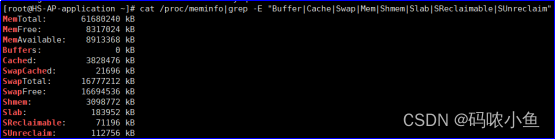
- MemFree:空闲的物理内存
- MemAvailable:可用的物理内存,MemFree+Buffers+Cached
- Buffers:(Buffer Cache)对磁盘块设备数据的缓存
- Cached:(Page Cache)对文件系统上文件数据的缓存,MemFree+SReclaimable
- SwapTotal:虚拟内存,利用磁盘空间虚拟出的一块逻辑内存
- Shmem:进程间共同使用的共享内存
- Slab:Linux内存管理机制
- SReclaimable:Slab可回收部分
- SUnreclaim:Slab不可回收部分
9、清除缓存策略:
定期清理缓存:echo 1 > /proc/sys/vm/drop_caches
- 1:清除page cache
- 2:清除slab分配器中的对象(包括目录项和inode)
- 3:清除page cache和slab分配器中的对象