辐射场方法最近在基于多张照片或视频进行新视角合成方面取得了革命性进展。然而,实现高视觉质量仍然需要耗时且计算成本高的神经网络,而最近的快速方法不可避免地在速度和质量之间进行了权衡。对于无界和完整的场景(而不是孤立的物体)以及1080p分辨率的渲染,目前没有任何方法能够实现实时显示速率。我们引入了三个关键要素,使我们能够在保持竞争性训练时间的同时,实现最先进的视觉质量,并且能够在1080p分辨率下实现高质量实时(≥30 fps)新视角合成。首先,从相机校准期间生成的稀疏点开始,我们用3D高斯表示场景,这保留了连续体积辐射场的优化场景所需的理想属性,同时避免了空白空间中的不必要计算;其次,我们进行3D高斯的交替优化/密度控制,特别是优化各向异性的协方差,以实现对场景的准确表示;第三,我们开发了一种支持各向异性投影的快速可见性感知渲染算法,这不仅加速了训练,还实现了实时渲染。我们在几个已建立的数据集上展示了最先进的视觉质量和实时渲染。
1 引言
网格和点是最常见的3D场景表示,因为它们是显式的,并且非常适合基于GPU/CUDA的快速光栅化。相比之下,最近的神经辐射场(NeRF)方法构建在连续场景表示的基础上,通常通过体积光线投射优化多层感知器(MLP)来实现捕获场景的新视角合成。同样,目前最有效的辐射场解决方案也是基于连续表示,通过插值存储在如体素【Fridovich-Keil和Yu等人,2022】或哈希网格【Müller等人,2022】或点【Xu等人,2022】中的值。虽然这些方法的连续性有助于优化,但渲染所需的随机采样成本高且可能导致噪声。我们介绍了一种新方法,结合了两者的优点:我们的3D高斯表示允许以最先进(SOTA)的视觉质量和具有竞争力的训练时间进行优化,而我们的基于瓦片的投影解决方案确保了在多个先前发布的数据集【Barron等人,2022;Hedman等人,2018;Knapitsch等人,2017】(见图1)上以1080p分辨率实现最先进质量的实时渲染。
我们的目标是允许使用多张照片捕获的场景实现实时渲染,并以与先前最有效方法相当的优化时间创建表示。最近的方法实现了快速训练【Fridovich-Keil 和 Yu 等人,2022;Müller 等人,2022】,但难以达到当前最先进的 NeRF 方法所获得的视觉质量,即 Mip-NeRF360【Barron 等人,2022】,其训练时间最长可达48小时。快速但质量较低的辐射场方法可以根据场景实现互动渲染时间(10-15帧每秒),但在高分辨率下无法达到实时渲染。
我们的解决方案建立在三个主要组件的基础上。首先,我们引入了3D高斯作为灵活且富有表现力的场景表示。我们从与之前类似 NeRF 的方法相同的输入开始,即通过结构光(SfM)【Snavely 等人,2006】校准的相机,并用作为 SfM 过程的一部分免费生成的稀疏点云初始化3D高斯集合。与大多数需要多视图立体(MVS)数据【Aliev 等人,2020;Kopanas 等人,2021;Rückert 等人,2022】的基于点的解决方案不同,我们仅使用 SfM 点作为输入就能实现高质量结果。需要注意的是,对于 NeRF 合成数据集,我们的方法即使使用随机初始化也能达到高质量。我们展示了3D高斯是一个优秀的选择,因为它们是可微的体积表示,但也可以通过将它们投影到2D并应用标准的α混合进行非常高效的光栅化,使用与 NeRF 等效的图像生成模型。我们方法的第二个组件是3D高斯属性的优化——3D 位置、透明度 α、各向异性协方差和球谐系数(SH)——交替进行自适应密度控制步骤,在优化过程中我们会添加和偶尔移除3D高斯。优化过程产生了对场景合理紧凑、无结构且精确的表示(对所有测试场景,1-5百万个高斯)。我们方法的第三个也是最后一个元素是我们的实时渲染解决方案,该解决方案使用快速 GPU 排序算法并受到基于瓦片的光栅化的启发,遵循最近的研究【Lassner 和 Zollhofer 2021】。然而,得益于我们的3D高斯表示,我们可以执行尊重可见性排序的各向异性投影——通过排序和α混合——并通过跟踪所需的多个排序投影实现快速且准确的反向传播。
总结一下,我们提供了以下贡献:
- 引入了各向异性3D高斯作为高质量、无结构的辐射场表示。
- 一种3D高斯属性的优化方法,交替进行自适应密度控制,为捕获的场景创建高质量的表示。
- 一种快速的、可微的 GPU 渲染方法,该方法感知可见性,允许各向异性投影和快速反向传播,以实现高质量的新视角合成。
我们在先前发布的数据集上的结果表明,我们可以从多视图捕获中优化我们的3D高斯,并达到或超过之前最优质量隐式辐射场方法的质量。我们还可以实现与最快方法相似的训练速度和质量,更重要的是,我们首次提供了高质量的新视角合成的实时渲染。
2 相关工作
我们首先简要回顾传统的重建方法,然后讨论基于点的渲染和辐射场工作,探讨它们的相似性;辐射场是一个广阔的领域,所以我们只关注直接相关的工作。关于该领域的全面综述,请参见最近的优秀综述【Tewari 等人,2022;Xie 等人,2022】。
2.1 传统场景重建和渲染
最早的新视角合成方法基于光场,最初是密集采样【Gortler 等人,1996;Levoy 和 Hanrahan,1996】,然后允许非结构化捕获【Buehler 等人,2001】。结构光(SfM)的出现【Snavely 等人,2006】开辟了一个新的领域,在这个领域中,一组照片可以用来合成新视角。SfM 在相机校准过程中估计一个稀疏点云,最初用于简单的3D空间可视化。随后,多视图立体(MVS)在这些年里产生了令人印象深刻的完整3D重建算法【Goesele 等人,2007】,推动了多个视图合成算法的发展【Chaurasia 等人,2013;Eisemann 等人,2008;Hedman 等人,2018;Kopanas 等人,2021】。所有这些方法将输入图像重新投影并混合到新的视图相机中,并使用几何形状来指导这种重新投影。这些方法在许多情况下产生了出色的结果,但通常无法完全从未重建的区域恢复,或者在 MVS 生成不存在的几何形状时无法从“过度重建”中恢复。最近的神经渲染算法【Tewari 等人,2022】大大减少了此类伪影,并避免了将所有输入图像存储在 GPU 上的高昂成本,在大多数方面超越了这些方法。
2.2 神经渲染和辐射场
深度学习技术早期就被用于新视角合成【Flynn 等人,2016;Zhou 等人,2016】;CNN 被用来估计混合权重【Hedman 等人,2018】,或者用于纹理空间解决方案【Riegler 和 Koltun,2020;Thies 等人,2019】。使用 MVS 的几何形状是大多数这些方法的主要缺点;此外,使用 CNN 进行最终渲染经常会导致时间抖动。
Soft3D【Penner 和 Zhang,2017】率先使用体积表示进行新视角合成;随后提出了结合体积光线投射的深度学习技术【Henzler 等人,2019;Sitzmann 等人,2019】,在几何表示中建立了连续可微分的密度场。使用体积光线投射进行渲染由于查询体积所需的大量样本而成本显著。神经辐射场(NeRFs)【Mildenhall 等人,2020】引入了重要性采样和位置编码以提高质量,但使用了大型多层感知器(MLP),这对速度有负面影响。NeRF 的成功引发了大量后续方法,这些方法通过引入正则化策略来解决质量和速度问题;当前新视角合成的图像质量处于最前沿的是 Mip-NeRF360【Barron 等人,2022】。虽然渲染质量非常出色,但训练和渲染时间仍然非常高;我们能够在提供快速训练和实时渲染的同时,在某些情况下达到或超过这种质量。
最新的方法主要通过利用三个设计选择来实现更快的训练和/或渲染:使用空间数据结构存储(神经)特征,这些特征随后在体积光线投射过程中进行插值,不同的编码和 MLP 容量。这些方法包括不同的空间离散化变体【Chen 等人,2022b,a;Fridovich-Keil 和 Yu 等人,2022;Garbin 等人,2021;Hedman 等人,2021;Reiser 等人,2021;Takikawa 等人,2021;Wu 等人,2022;Yu 等人,2021】,代码本【Takikawa 等人,2022】,以及诸如哈希表【Müller 等人,2022】的编码,允许使用更小的 MLP 或完全不使用神经网络【Fridovich-Keil 和 Yu 等人,2022;Sun 等人,2022】。其中最值得注意的方法是 InstantNGP【Müller 等人,2022】,它使用哈希网格和占用网格加速计算,并使用更小的 MLP 表示密度和外观;以及 Plenoxels【Fridovich-Keil 和 Yu 等人,2022】,它使用稀疏体素网格插值连续密度场,并能够完全不使用神经网络。两者都依赖球谐函数:前者直接表示方向效应,后者将其输入编码到颜色网络。虽然这两种方法都提供了出色的结果,但这些方法仍可能难以有效表示空白空间,部分取决于场景/捕获类型。此外,图像质量在很大程度上受到用于加速的结构化网格选择的限制,渲染速度受到为每个光线投射步骤查询大量样本的需要的影响。我们使用的无结构、显式 GPU 友好的 3D 高斯在没有神经组件的情况下实现了更快的渲染速度和更好的质量。
2.3 点基渲染和辐射场
点基方法有效地渲染离散和非结构化的几何样本(即点云)【Gross 和 Pfister 2011】。在其最简单的形式中,点样本渲染【Grossman 和 Dally 1998】将一组非结构化点以固定大小进行光栅化,可以利用图形API本地支持的点类型【Sainz 和 Pajarola 2004】或在GPU上的并行软件光栅化【Laine 和 Karras 2011;Schütz 等人,2022】。尽管这种方法忠实于底层数据,但点样本渲染会出现孔洞、导致混叠,并且是严格不连续的。早期关于高质量点基渲染的工作通过“喷溅”比像素大的点原语(例如圆形或椭圆盘、椭球或表面元素)来解决这些问题【Botsch 等人,2005;Pfister 等人,2000;Ren 等人,2002;Zwicker 等人,2001b】。
近年来,差分点基渲染技术引起了关注【Wiles 等人,2020;Yifan 等人,2019】。点被增强了神经特征,并使用CNN渲染【Aliev 等人,2020;Rückert 等人,2022】,从而实现了快速甚至实时的视图合成;然而,它们仍然依赖于MVS进行初始几何,并因此继承了其伪影,尤其是在处理无特征/光滑区域或细结构时的过度或不足重建。
点基α混合和NeRF风格的体积渲染本质上共享相同的图像形成模型。具体来说,颜色C由沿射线的体积渲染给出:

其中,样本的密度σ、透射率T和颜色c在射线上的间隔δ_i上取样。这可以重新写为:
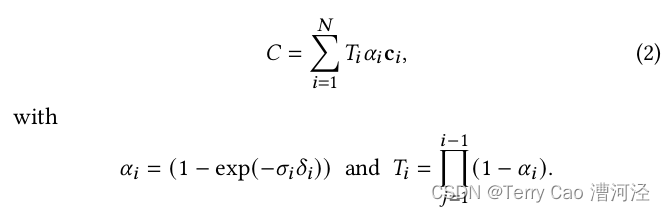
典型的神经点基方法(例如【Kopanas 等人,2022;2021】)通过混合N个重叠像素的有序点来计算像素的颜色C:
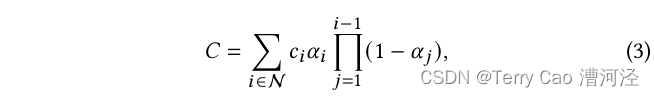
其中,c_i是每个点的颜色,α_i通过评估具有协方差Σ的二维高斯分布乘以每点学习的透明度来给出【Yifan 等人,2019】。
从方程2和方程3中,我们可以清楚地看到图像形成模型是相同的。然而,渲染算法非常不同。NeRFs是一种连续表示,隐式表示空/满空间;需要昂贵的随机采样来找到方程2中的样本,因而带来噪声和计算开销。相比之下,点是一种非结构化的离散表示,足够灵活,允许创建、销毁和位移几何体,类似于NeRF。这是通过优化透明度和位置实现的,如先前的工作所示【Kopanas 等人,2021】,同时避免了全体积表示的缺点。
Pulsar【Lassner 和 Zollhofer,2021】实现了快速的球体光栅化,这启发了我们的基于瓦片和排序的渲染器。然而,鉴于上述分析,我们希望在排序喷溅上保持(近似)常规α混合,以拥有体积表示的优势:我们的光栅化尊重可见性顺序,与他们的顺序无关方法相反。此外,我们对像素中的所有喷溅进行梯度反向传播并光栅化各向异性喷溅。这些元素共同贡献了我们结果的高视觉质量(见第7.3节)。此外,上述方法也使用CNN进行渲染,导致时间不稳定。然而,Pulsar【Lassner 和 Zollhofer,2021】和ADOP【Rückert 等人,2022】的渲染速度激励了我们开发快速渲染解决方案。
尽管专注于镜面效果,Neural Point Catacaustics的漫反射点基渲染轨道【Kopanas 等人,2022】通过使用MLP克服了这种时间不稳定性,但仍需要MVS几何作为输入。最新的方法【Zhang 等人,2022】在这一类别中不需要MVS,并且也使用SH进行方向处理;然而,它只能处理单个对象的场景并需要遮罩进行初始化。虽然对于小分辨率和低点数速度很快,但尚不清楚它如何扩展到典型数据集的场景【Barron 等人,2022;Hedman 等人,2018;Knapitsch 等人,2017】。我们使用3D高斯进行更灵活的场景表示,避免了对MVS几何的需求,并通过我们的基于瓦片的投影高斯渲染算法实现了实时渲染。
一种最近的方法【Xu 等人,2022】使用点来表示具有径向基函数方法的辐射场。他们在优化过程中使用了点剪枝和密集化技术,但使用体积光线投射,无法实现实时显示率。
在人类表现捕捉领域,3D高斯已被用于表示捕捉到的人体【Rhodin 等人,2015;Stoll 等人,2011】;最近它们被用于体积光线投射的视觉任务【Wang 等人,2023】。类似的背景下也提出了神经体积原语【Lombardi 等人,2021】。虽然这些方法启发了我们选择3D高斯作为场景表示,但它们专注于重建和渲染单个孤立对象(人体或面部)的特定情况,导致深度复杂性较小的场景。相比之下,我们对各向异性协方差的优化、交错的优化/密度控制和高效的深度排序渲染使我们能够处理完整、复杂的场景,包括室内和室外以及具有大深度复杂性的场景。
3. 概述
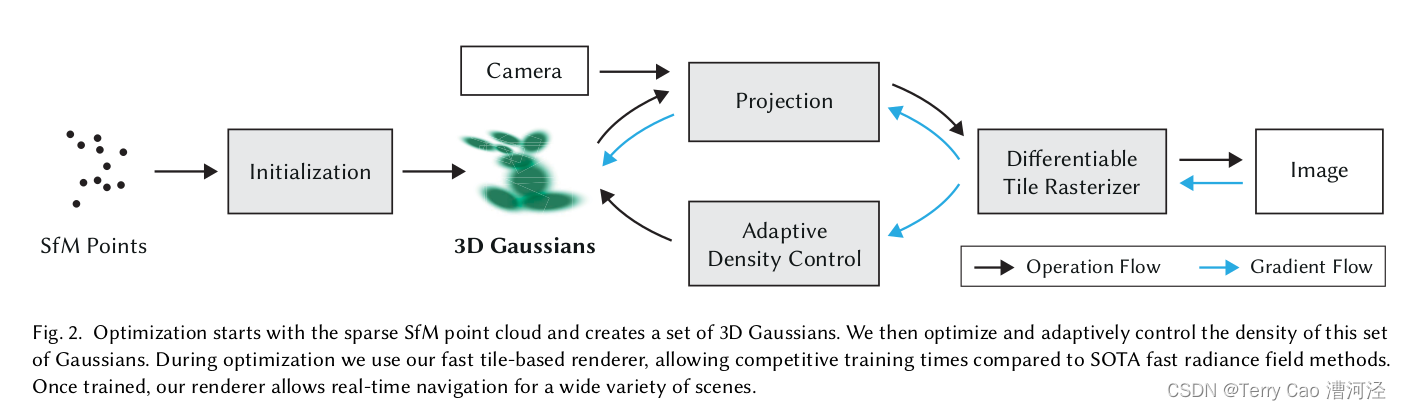
我们的方法的输入是一组静态场景的图像,以及由SfM【Schönberger 和 Frahm 2016】校准的对应摄像机,SfM会产生稀疏点云作为副产品。我们从这些点创建了一组3D高斯分布(见第4节),定义了位置(均值)、协方差矩阵和不透明度α,这允许非常灵活的优化机制。这结果在于对3D场景的合理紧凑表示,部分原因是高度各向异性的体积喷溅可以紧凑地表示精细结构。辐射场的方向外观分量(颜色)通过球谐函数(SH)表示,遵循标准做法【Fridovich-Keil 和 Yu 等人 2022;Müller 等人 2022】。我们的算法通过一系列3D高斯参数(即位置、协方差、α和SH系数)的优化步骤交错进行高斯密度的自适应控制操作来创建辐射场表示(见第5节)。我们方法的效率关键在于我们的基于瓦片的光栅化器(见第6节),它允许各向异性喷溅的α混合,并通过快速排序来尊重可见性顺序。我们的快速光栅化器还包括通过跟踪累积的α值进行快速反向传递,而无需限制可以接收梯度的高斯数量。我们方法的概述如图2所示。
4. 可微分3D高斯喷溅
我们的目标是优化一种场景表示,允许从稀疏的(SfM)点集(没有法线)开始进行高质量的新视图合成。为此,我们需要一种继承可微分体积表示属性的原语,同时这种原语要非结构化且显式表示以允许非常快速的渲染。我们选择3D高斯分布,这些分布是可微分的,并且可以轻松投影到允许快速α混合进行渲染的2D喷溅。
我们的表示方法与先前使用2D点的方法相似【Kopanas 等人 2021;Yifan 等人 2019】,并假设每个点是具有法线的小平面圆。鉴于SfM点的极端稀疏性,很难估计法线。同样,从这样的估计中优化非常嘈杂的法线也是非常具有挑战性的。相反,我们将几何体建模为一组不需要法线的3D高斯分布。我们的高斯分布由位于点(均值)μ处的世界空间中定义的完整3D协方差矩阵Σ定义【Zwicker 等人 2001a】:
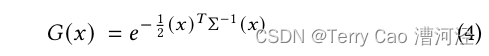
这个高斯分布在我们的混合过程中乘以α。然而,我们需要将我们的3D高斯分布投影到2D进行渲染。Zwicker等人【2001a】展示了如何将这种投影到图像空间。给定视图变换W,摄像机坐标中的协方差矩阵Σ′如下:

其中J是投影变换的仿射近似的雅可比矩阵。Zwicker等人【2001a】还表明,如果跳过Σ′的第三行和第三列,我们将得到一个具有相同结构和性质的2×2方差矩阵,就像从平面点与法线开始一样,如之前的工作【Kopanas 等人 2021】。
一个显而易见的方法是直接优化协方差矩阵Σ以获得表示辐射场的3D高斯分布。然而,协方差矩阵只有在它们是半正定的情况下才具有物理意义。对于我们所有参数的优化,我们使用梯度下降,这不能轻易约束产生有效的矩阵,并且更新步骤和梯度很容易创建无效的协方差矩阵。
因此,我们选择了更直观但同样有表现力的优化表示。3D高斯分布的协方差矩阵Σ类似于描述椭球体的配置。给定缩放矩阵S和旋转矩阵R,我们可以找到相应的Σ:

为了允许独立优化这两个因子,我们将它们分别存储:一个3D向量s用于缩放,一个四元数q用于表示旋转。这些可以轻松转换为各自的矩阵并组合,确保q归一化以获得有效的单位四元数。
为了避免在训练期间由于自动微分引起的显著开销,我们显式地推导了所有参数的梯度。具体的导数计算细节在附录A中。
这种适合优化的各向异性协方差表示允许我们优化3D高斯分布以适应捕获场景中不同形状的几何体,从而得到相当紧凑的表示。图3展示了这样的情况。
5. 带有自适应密度控制的3D高斯优化
我们方法的核心是优化步骤,该步骤创建了一组密集的3D高斯分布,以准确表示场景进行自由视角合成。除了位置 ppp、不透明度 α\alphaα 和协方差矩阵 Σ\SigmaΣ,我们还优化了表示每个高斯分布颜色 ccc 的球谐函数(SH)系数,以正确捕捉场景的视角依赖外观。这些参数的优化与控制高斯分布密度的步骤交替进行,以更好地表示场景。

5.1 优化
优化基于连续的渲染和将结果图像与捕获数据集中训练视图进行比较的迭代。由于3D到2D投影的模糊性,几何体可能会被错误地放置。因此,我们的优化需要能够创建几何体,同时也能销毁或移动错误放置的几何体。3D高斯分布协方差参数的质量对于表示的紧凑性至关重要,因为大面积的同质区域可以用少量的大各向异性高斯分布来捕捉。
我们使用随机梯度下降(SGD)技术进行优化,充分利用标准的GPU加速框架,并为一些操作添加自定义CUDA内核,遵循最近的最佳实践【Fridovich-Keil 和 Yu 等人 2022;Sun 等人 2022】。特别是,我们的快速光栅化(见第6节)对于优化的效率至关重要,因为它是优化的主要计算瓶颈。
为了约束 α\alphaα 在 [0, 1) 范围内并获得平滑的梯度,我们使用Sigmoid激活函数;对于协方差的尺度,我们使用指数激活函数,原因类似。我们将初始协方差矩阵估计为各向同性高斯分布,其轴等于与最近三个点距离的均值。我们采用类似于Plenoxels【Fridovich-Keil 和 Yu 等人 2022】的标准指数衰减调度技术,但仅用于位置。损失函数是 L1 结合 D-SSIM 项:在所有测试中,我们使用 λ=0.2\lambda = 0.2λ=0.2。我们在第7.1节提供了学习调度和其他元素的详细信息。
5.2 高斯分布的自适应控制
我们从SfM的初始稀疏点集开始,然后应用我们的方法自适应地控制单位体积上的高斯分布数量和密度,使我们从初始稀疏的高斯分布集转变为更密集、更能代表场景且参数正确的高斯分布集。在优化预热(见第7.1节)之后,我们每100次迭代进行一次密集化,并移除任何基本透明的高斯分布,即 α\alphaα 小于阈值 ϵα\epsilon_{\alpha}ϵα 的高斯分布。
我们的高斯分布自适应控制需要填充空白区域。它关注几何特征缺失的区域(“重建不足”),但也关注高斯分布覆盖场景大面积区域的区域(通常对应于“重建过度”)。我们观察到这两种情况都有较大的视图空间位置梯度。从直觉上讲,这是因为它们可能对应于尚未很好地重建的区域,优化试图移动高斯分布以纠正这一点。
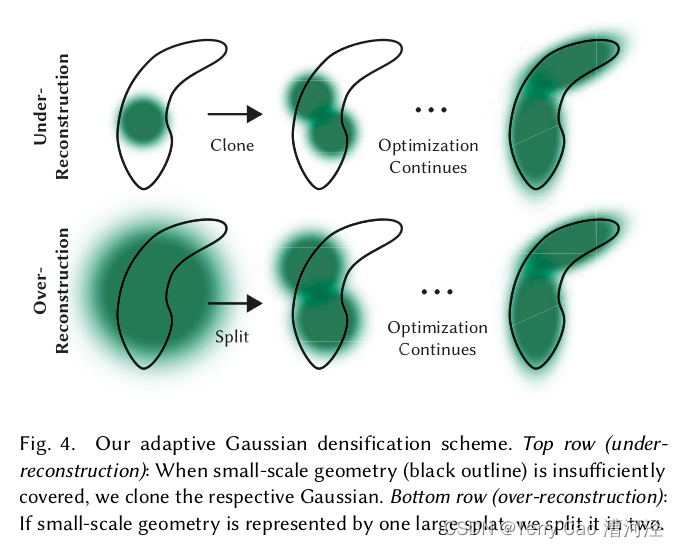
由于这两种情况都是密集化的良好候选者,我们对视图空间位置梯度平均幅值超过阈值 τpos\tau_{\text{pos}}τpos 的高斯分布进行密集化,我们在测试中将其设置为0.0002。我们接下来展示此过程的详细信息,如图4所示。
对于在重建不足区域的小高斯分布,我们需要覆盖必须创建的新几何体。为此,最好克隆这些高斯分布,通过简单地创建相同大小的副本,并沿位置梯度方向移动它。另一方面,在具有高方差的区域内的大高斯分布需要分割为较小的高斯分布。我们将这些高斯分布替换为两个新高斯分布,并将其尺度缩小一个实验确定的系数 ϕ=1.6\phi = 1.6ϕ=1.6。我们还使用原始3D高斯分布作为PDF进行采样来初始化它们的位置。
在第一种情况下,我们检测并处理增加系统总量和高斯分布数量的需求,而在第二种情况下,我们保持总量不变但增加高斯分布的数量。类似于其他体积表示,我们的优化可能会在靠近输入摄像机的位置出现浮动情况;在我们的案例中,这可能导致高斯分布密度的不合理增加。控制高斯分布数量的有效方法是每3000次迭代将 α\alphaα 值设为接近零。优化然后增加所需高斯分布的 α\alphaα 值,同时允许我们的剔除方法移除 α\alphaα 小于 ϵα\epsilon_{\alpha}ϵα 的高斯分布,如上所述。高斯分布可能会缩小或增大并与其他高斯分布显著重叠,但我们定期移除在世界空间中非常大且在视图空间中占据大面积的高斯分布。这一策略总体上很好地控制了高斯分布的总数量。我们的模型中的高斯分布始终是欧几里得空间中的原语;与其他方法不同【Barron 等人 2022;Fridovich-Keil 和 Yu 等人 2022】,我们不需要远距离或大型高斯分布的空间压缩、变形或投影策略。
6. 快速可微光栅化器用于高斯分布
我们的目标是实现快速的整体渲染和排序,以允许近似的 α\alphaα-混合(包括各向异性的斑点),并避免以往工作中对接收梯度的斑点数量的硬性限制【Lassner 和 Zollhofer 2021】。
为了实现这些目标,我们设计了一种基于瓦片的高斯斑点光栅化器,灵感来自最近的软件光栅化方法【Lassner 和 Zollhofer 2021】,预先为整个图像排序原语,避免了每像素排序的开销,这是以前 α\alphaα-混合解决方案的瓶颈【Kopanas 等人 2022,2021】。我们的快速光栅化器允许在任意数量的混合高斯分布上进行有效的反向传播,且附加的内存消耗低,每像素只需恒定的开销。我们的光栅化管道是完全可微的,并且在投影到2D后(见第4节),可以类似于之前的2D斑点方法进行光栅化【Kopanas 等人 2021】。
我们的方法首先将屏幕分成16×16的瓦片,然后将3D高斯分布与视锥和每个瓦片进行剔除。具体来说,我们只保留99%置信区间与视锥相交的高斯分布。此外,我们使用保护带来简单地拒绝极端位置的高斯分布(即那些均值接近近平面且远在视锥之外的高斯分布),因为计算其投影的2D协方差会不稳定。然后,我们根据高斯分布重叠的瓦片数量实例化每个高斯分布,并为每个实例分配一个结合视图空间深度和瓦片ID的键。然后,我们使用一个快速的GPU基数排序【Merrill 和 Grimshaw 2010】对高斯分布进行排序。注意,没有额外的每像素排序,混合是基于这个初始排序进行的。因此,我们的 α\alphaα-混合在某些配置中可能是近似的。然而,当斑点接近单个像素的大小时,这些近似变得可以忽略不计。我们发现这种选择大大提高了训练和渲染性能,而不会在收敛的场景中产生可见的伪影。
在对高斯分布排序之后,我们通过识别斑点到给定瓦片的第一个和最后一个深度排序条目,为每个瓦片生成一个列表。对于光栅化,我们为每个瓦片启动一个线程块。每个块首先协作地将高斯分布包加载到共享内存中,然后对于给定像素,通过从前到后遍历列表累积颜色和 α\alphaα 值,从而最大化数据加载/共享和处理的并行性。当我们在一个像素中达到目标 α\alphaα 饱和度时,相应的线程停止。在定期间隔内,查询瓦片中的线程,当所有像素都饱和(即 α\alphaα 达到1)时,整个瓦片的处理终止。排序和整体光栅化方法的高级概述在附录C中给出。
在光栅化期间,α\alphaα 的饱和是唯一的停止标准。与之前的工作相比,我们不限制接收梯度更新的混合原语的数量。我们强制执行这一属性,使我们的方法能够处理具有任意变化深度复杂性的场景并准确地学习它们,而无需进行场景特定的超参数调整。在反向传播过程中,我们必须恢复前向过程中每个像素混合点的完整序列。一种解决方案是将每个像素中混合点的任意长列表存储在全局内存中【Kopanas 等人 2021】。为了避免隐含的动态内存管理开销,我们选择再次遍历每瓦片的列表;我们可以重用前向过程中排序的高斯分布数组和瓦片范围。为了方便梯度计算,我们现在从后向前遍历它们。
遍历从影响瓦片中任何像素的最后一个点开始,点的加载再次协作地进行。此外,每个像素只有在深度低于或等于前向过程中对其颜色有贡献的最后一个点的深度时,才会开始(昂贵的)重叠测试和点处理。第4节中描述的梯度计算需要在原始混合过程中每一步的累积不透明度值。与其在反向传播过程中遍历逐渐减小的不透明度显式列表,我们可以通过在前向过程中仅存储总累积不透明度来恢复这些中间不透明度。具体来说,每个点在前向过程中存储最终累积的不透明度 α\alphaα;我们通过在从后向前遍历中将其除以每个点的 α\alphaα 来获得所需的梯度计算系数。
7. 实现、结果与评估
我们接下来讨论实现的细节,展示算法的结果,并与之前的工作进行比较和消融研究的评估。
7.1 实现
我们使用Python和PyTorch框架实现了我们的方法,并编写了定制的CUDA内核进行光栅化,这些内核是以前方法的扩展版本【Kopanas等人 2021】,并使用NVIDIA CUB排序程序进行快速基数排序【Merrill和Grimshaw 2010】。我们还使用开源的SIBR【Bonopera等人 2020】构建了一个交互式查看器,用于交互式查看。我们使用这个实现来测量我们实现的帧率。源代码和所有数据可在以下网址获得:
3D Gaussian Splatting for Real-Time Radiance Field Rendering
优化细节。为了稳定性,我们在较低分辨率下“预热”计算。具体来说,我们以4倍较小的图像分辨率开始优化,并在250和500次迭代后进行两次上采样。
SH系数优化对角度信息的缺乏敏感。对于典型的“类似NeRF”捕获,其中一个中央对象被整个半球周围的照片观察到,优化效果良好。然而,如果捕获具有缺少的角度区域(例如,捕获场景的角落,或执行“内外”捕获【Hedman等人 2016】),优化可能会生成完全错误的零阶SH分量(即基色或漫反射色)。为了解决这个问题,我们首先只优化零阶分量,然后在每1000次迭代后引入一个SH带,直到表示所有4个SH带。
7.2 结果与评估
结果。我们在从之前发表的数据集中获得的13个真实场景和合成Blender数据集【Mildenhall等人 2020】上测试了我们的算法。特别是,我们在Mip-Nerf360【Barron等人 2022】中展示的全套场景上测试了我们的方法,该方法是当前NeRF渲染质量的最新技术,两场景来自Tanks&Temples数据集【2017】和Hedman等人提供的两场景【Hedman等人 2018】。我们选择的场景具有非常不同的捕获风格,涵盖了有界的室内场景和大范围的室外环境。我们在所有实验中使用相同的超参数配置。除Mip-NeRF360方法外,所有结果均在A6000 GPU上运行。
在补充材料中,我们展示了包含远离输入照片视图的场景的渲染视频路径。
真实世界场景。在质量方面,当前的最新技术是Mip-Nerf360【Barron等人 2021】。我们将此方法作为质量基准进行比较。我们还与最近的两个快速NeRF方法:InstantNGP【Müller等人 2022】和Plenoxels【Fridovich-Keil和Yu等人 2022】进行了比较。
我们使用Mip-NeRF360建议的方法进行数据集的训练/测试划分,每8张照片进行一次测试,以生成误差指标的对比,并使用文献中最常用的标准PSNR、L-PIPS和SSIM指标;请参见表1。表中的所有数字都是我们运行作者代码的结果,除了Mip-NeRF360在其数据集上的结果,我们从原始出版物中复制了这些数字,以避免关于当前最新技术的混淆。对于我们的图像,我们使用了Mip-NeRF360的运行结果:这些运行的数字在附录D中。我们还展示了训练时间、渲染速度和存储优化参数所需内存的平均值。我们报告了InstantNGP的基本配置(Base),运行35K次迭代,以及作者建议的稍大网络(Big),以及我们的两种配置,分别运行7K和30K次迭代。我们展示了两种配置在视觉质量上的差异(见图6)。在许多情况下,7K次迭代的质量已经相当不错。
训练时间因数据集而异,我们分别报告它们。请注意,图像分辨率也因数据集而异。在项目网站上,我们提供了用于计算所有方法(包括我们的方法和以前的方法)在所有场景上统计数据的测试视图的渲染。请注意,我们保持所有渲染的输入分辨率。
表中显示,我们完全收敛的模型在质量上与最新的Mip-NeRF360方法相当,有时略好;注意,在相同硬件上,他们的平均训练时间为48小时2,而我们的训练时间为35-45分钟,他们的渲染时间为每帧10秒。我们在5-10分钟的训练后达到与InstantNGP和Plenoxels相当的质量,但额外的训练时间使我们达到最新技术的质量,而其他快速方法则无法做到这一点。对于Tanks&Temples,我们在相似的训练时间(我们的情况为约7分钟)内达到了与InstantNGP基本配置相当的质量。
我们还展示了图5中我们和选择进行比较的以前渲染方法的测试视图的视觉结果;我们的结果是经过30K次训练的。我们看到,在某些情况下,即使是Mip-NeRF360也有剩余的伪影,而我们的方法避免了这些伪影(例如,在自行车和树桩中的植被模糊,或房间中的墙壁)。在补充视频和网页中,我们提供了远距离路径的比较。我们的方法倾向于在远距离视角中保留覆盖良好区域的视觉细节,而以前的方法并非总是如此。
合成有界场景。除了现实场景,我们还在合成Blender数据集【Mildenhall等人 2020】上评估了我们的方法。所涉及的场景提供了详尽的视图集,尺寸有限,并提供精确的摄像机参数。在这种情况下,即使从随机初始化开始,我们也能达到最新的结果:我们从一个包含场景边界的体积内的100K均匀随机高斯分布开始训练。我们的方法迅速且自动地将它们修剪到约6-10K有意义的高斯分布。经过30K次迭代后,训练模型的最终大小达到每个场景约200-500K高斯分布。我们报告并比较了我们在白色背景下实现的PSNR分数以便兼容性。示例可以参见图10(从左数第二张图片)和补充材料。训练好的合成场景以180-300 FPS渲染。
紧凑性。与以前的显式场景表示法相比,我们优化中使用的各向异性高斯能够以较少的参数建模复杂形状。我们通过将我们的方法与【Zhang等人 2022】获得的高度紧凑的基于点的模型进行比较来展示这一点。我们从他们通过前景掩膜进行空间雕刻获得的初始点云开始优化,直到我们达到他们报告的PSNR分数。通常在2-4分钟内实现这一点。我们使用约四分之一的点数超越了他们报告的指标,平均模型大小为3.8 MB,而他们的为9 MB。我们注意到,对于这个实验,我们仅使用了两个阶数的球谐函数,类似于他们的设置。
7.3 消融实验
我们将不同的贡献和算法选择进行了隔离,并构建了一组实验来衡量它们的效果。具体来说,我们测试了以下方面:
- 从SfM初始化
- 我们的增密策略
- 各向异性协方差
- 我们允许无限数量的splats具有梯度
- 使用球谐函数
每个选择的定量效果总结在表3中。
从SfM初始化。我们还评估了从SfM点云初始化3D高斯的重要性。对于这个消融实验,我们均匀地从一个大小为输入摄像机边界框三倍的立方体中采样。我们观察到,即使没有SfM点,我们的方法也表现相对较好,避免了完全失败。相反,主要是在背景中退化,见图7。同样,在训练视图未充分覆盖的区域,随机初始化方法似乎有更多无法通过优化去除的浮动点。另一方面,合成NeRF数据集没有这种行为,因为它没有背景,并且输入摄像机很好地约束了场景(见上文讨论)。
增密。我们接下来评估了我们的两种增密方法,具体是第5节描述的克隆和分裂策略。我们分别禁用每种方法,并使用其他方法不变进行优化。结果表明,分裂大的高斯对于良好地重建背景很重要,如图8所示,而克隆小的高斯而不是分裂它们可以使场景中出现.
8 讨论与结论
我们提出了第一个真正实现实时、高质量辐射场渲染的方法,适用于各种场景和捕获风格,同时需要的训练时间与之前最快的方法相竞争。
我们选择了3D高斯原语,保留了体积渲染的优化属性,同时直接允许基于快速splat的光栅化。我们的工作表明,与广泛接受的观点相反,连续表示并不严格需要以实现快速高质量的辐射场训练。
我们大部分(约80%)的训练时间都花费在Python代码上,因为我们使用PyTorch构建了我们的解决方案,以便让其他人可以轻松使用我们的方法。只有光栅化例程是作为优化的CUDA内核实现的。我们期望将其余的优化完全转移到CUDA上,例如,就像InstantNGP【Müller等人 2022】中所做的那样,这可以在性能至关重要的应用程序中实现显著的进一步加速。
我们还展示了建立在实时渲染原理之上的重要性,利用GPU的强大性能和软件光栅化管线架构的速度。这些设计选择是训练和实时渲染性能的关键,提供了与以前的体积光线追踪相比的竞争优势。
有趣的是,我们想知道我们的高斯能否用于对捕获的场景进行网格重建。除了实际应用的影响,考虑到网格的广泛应用,这将使我们更好地理解我们的方法在体积和表面表示之间的确切位置。
总之,我们提出了第一个辐射场的实时渲染解决方案,渲染质量与最好的昂贵的以前方法相匹配,同时训练时间与现有最快的解决方案相竞争。