- 获取nvidia_docker压缩包nvidia_docker.tgz
- 将压缩包上传至服务器指定目录
- 解压nvidia_docker.tgz压缩包
tar -zxvf 压缩包
- 执行rpm安装命令:
#查看指定rpm包安装情况
rpm -qa | grep libstdc++
#查看指定rpm包下的依赖包的版本情况
strings /lib64/libstdc++ |grep GLIBCXX
#安装rpm包
rpm -ivh rpm包路径
#升级rpm包
rpm -Uvh rpm包路径
#卸载rpm包
rpm -e rpm包路径
#yum命令安装--配置好yum网络源或者本地源url的情况
yum install container-selinux-2.205.0-2.al8.noarch
#yum卸载命令
yum remove container-selinux-2.205.0-2.al8.noarch
rpm -ivh libnvidia-container1-1.2.0-1.x86_64.rpm libnvidia-container-tools-1.2.0-1.x86_64.rpm nvidia-container-toolkit-1.2.1-2.x86_64.rpm nvidia-container-runtime-3.3.0-1.x86_64.rpm libcgroup-0.41-21.el7.x86_64.rpm containerd.io-1.2.13-3.2.el7.x86_64.rpm docker-ce-cli-19.03.12-3.el7.x86_64.rpm docker-ce-19.03.12-3.el7.x86_64.rpm nvidia-docker2-2.4.0-1.noarch.rpm
- 如果报错:
error: Failed dependencies:container-selinux >= 2:2.74 is needed by containerd.io-1.2.13-3.2.el7.x86_64container-selinux >= 2:2.74 is needed by docker-ce-3:19.03.12-3.el7.x86_64
需要先安装版本不冲突的rpm包:
yum install container-selinux-2.205.0-2.al8.noarch
,然后再执行第四步
- 拉取nvidia的GPU镜像文件:
docker pull pai-light-registry.cn-beijing.cr.aliyuncs.com/prod/pytorch-training:23.08-gpu-py310-cu122-ubuntu22.04
7.如果报错如下:
write /var/lib/docker/tmp/GetImageBlob139943065: no space left on device
原因:磁盘空间不够,大概率是因为docker数据所在目录的分区空间不够
定位:
- 查看docker的数据目录分区的空间使用情况,一般docker目录在/var/lib/docker下
df -h /var/lib/docker
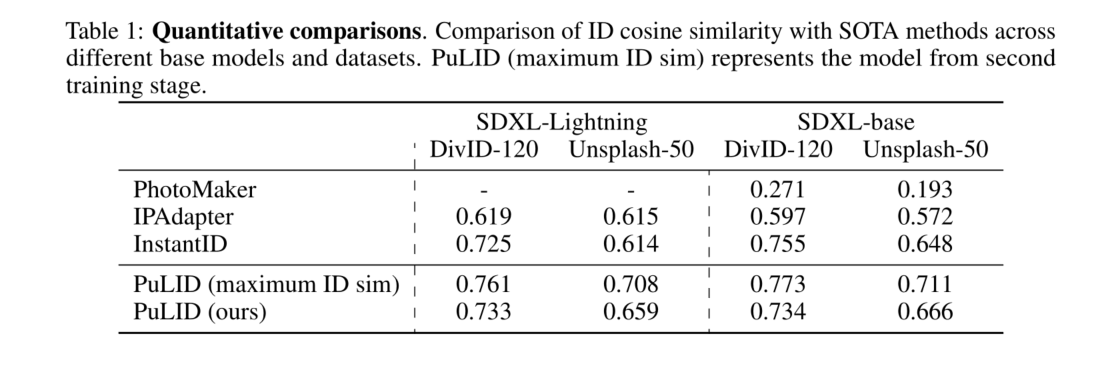
可以看到显示结果如下,已使用99%,不够镜像存储空间:

解决办法:更改docker的数据目录到更大空间的目录下
- 查看磁盘分区的分布情况,寻找一个空间比较充足的分区
lsblk
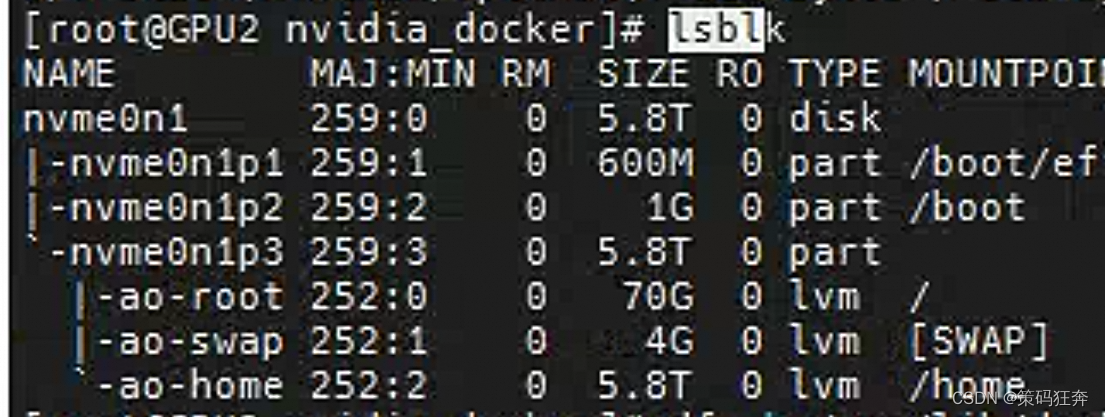
2.将原有的docker数据目录迁移到新的docker数据目录
2.1 先停止docker服务
sudo systemctl stop docker
2.2 使用 rsync 命令同步旧的数据目录到新的位置。务必保留原始文件属性和权限
sudo rsync -aP /var/lib/docker/ /new/path/docker/
2.3 配置 Docker 使用新的数据目录:1. 首先修改/etc/docker/daemon.json 配置文件,新增配置项:
{"data-root": "/new/path/docker"}
实际的nvidia_docker的配置形式不同:
{"runtimes": {"nvidia": {"path": "nvidia-container-runtime","data-root":"/home/docker","runtimeArgs": []}}
} 2. 修改 docker.service 文件,一般路径:
/usr/lib/systemd/system/docker.service
ExecStart属性增加参数指定docker数据目录: --data-root: /home/docker
ExecStart=/usr/bin/dockerd -H fd:// --data-root /home/docker --containerd=/run/containerd/containerd.sock
3. 重新加载系统守护进程并重启 Docker 服务:
sudo systemctl daemon-reload
4. 重新启动docker的服务
sudo systemctl start docker
5. 检查 Docker 是否使用了新的数据目录,并确保一切正常运行
docker info | grep 'Docker Root Dir'
- 启动nvidia_docker的容器,关键参数 --gpus all:
#可用宿主机的所有GPU网卡
--gpus all
#容器采用host网络模式,共享主机网卡
--network host
#容器内有足够权限执行宿主机命令或访问文件
--privileged
#直接共用宿主机内存,容器内拉起MPI进程时,报错,例如不存在的物理地址等错误
--ipc=host
#容器内设置shmsize内存资源大小
--ulimit=stack=67108864 --ulimit=memlock=-1
#映射宿主机目录到容器内目录(酌情设置,建议直接拷贝到容器内,不要映射)
-v /home:/homedocker run -itd --gpus all --network host --privileged --ipc=host -v /home:/home --ulimit=stack=67108864 --ulimit=memlock=-1 --name 容器名称 镜像:镜像版本 /bin/bash