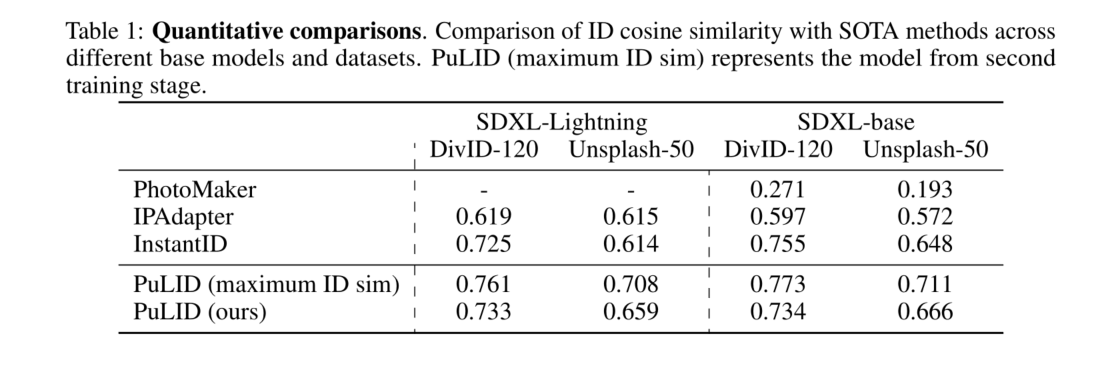
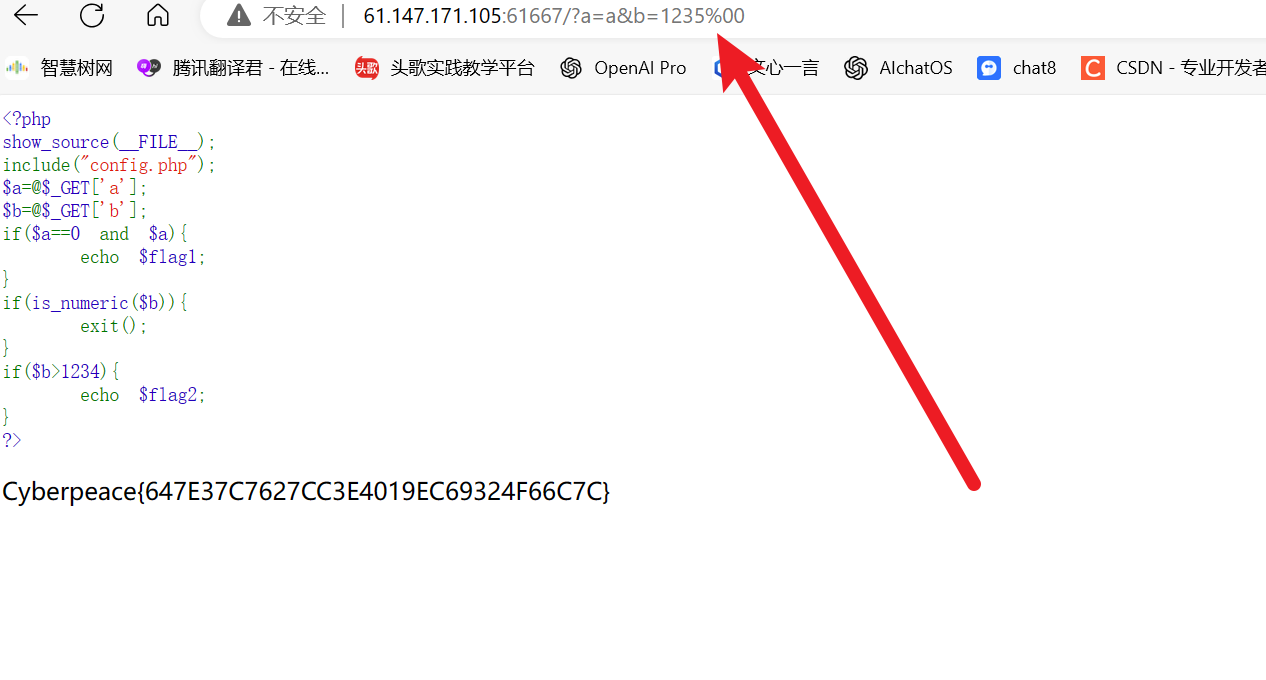
论文:https://arxiv.org/abs/2404.16022
代码:https://github.com/ToTheBeginning/PuLID
文章目录
- Abstract
- Introduction
- Related Work
- Methods
Abstract
我们提出了一种新颖的、无需调整的文本生成图像ID定制方法——Pure and Lightning ID customization(PuLID)。通过将Lightning T2I分支与标准扩散分支结合,PuLID引入了对比对齐损失和准确ID损失,最大程度地减少了对原始模型的干扰,确保了高ID保真度。实验表明,PuLID在ID保真度和可编辑性方面都表现出色。PuLID的另一个吸引人的特性是,在插入ID前后,图像的元素(例如背景、光照、构图和风格)尽可能保持一致。代码和模型将会发布在https://github.com/ToTheBeginning/PuLID。
Introduction
作为一种特定类别的定制化文本生成图像(T2I)方法【5, 30, 12, 17, 40, 42】,身份(ID)定制允许用户适配预训练的T2I扩散模型,以符合他们的个性化ID。一类方法【5, 30, 12, 17】通过在用户提供的同一ID的若干图像上微调某些参数,从而将ID嵌入到生成模型中。这些方法催生了许多流行的AI肖像应用程序,如PhotoAI和EPIK。
尽管基于微调的解决方案取得了可观的成果,但每个ID的定制需要耗费数十分钟的微调时间,因此使个性化过程经济成本较高。另一类方法【41, 42, 2, 36, 20, 19, 38】则放弃了每个ID微调的必要性,转而在一个庞大的肖像数据集上预训练一个ID适配器【11, 24】。这些方法通常利用编码器(例如CLIP图像编码器【27】)提取ID特征。然后,将提取的特征以特定方式(例如嵌入到交叉注意力层中)整合到基础扩散模型中。尽管这些无需微调的方法效率极高,但面临两个显著挑战。
- ID插入会破坏原始模型的行为。一个纯粹的ID信息嵌入应具有两个特征。首先,理想的ID插入应仅改变与ID相关的方面,如面部、发型和肤色,而与特定身份不直接相关的图像元素,如背景、光照、构图和风格,应该与原始模型的行为保持一致。据我们所知,以前的工作并未关注这一点。尽管一些研究【42, 38, 20】展示了生成风格化ID的能力,但与ID插入前的图像相比,风格明显退化(如图1所示)。具有较高ID保真度的方法往往会导致更严重的风格退化。
其次,在ID插入后,仍应保持原始T2I模型遵循提示的能力。在ID定制的背景下,这通常意味着能够通过提示改变ID属性(例如年龄、性别、表情和发型)、方向和配件(例如眼镜)。为了实现这些特性,目前的解决方案通常分为两类。第一类涉及增强编码器。IPAdapter【42, 1】从早期版本的CLIP提取网格特征转向利用面部识别骨干【4】提取更抽象和相关的ID信息。尽管编辑性有所改善,但ID保真度还不够高。InstantID【38】通过包括一个额外的ID和标志控制网【43】来进行更有效的调节。尽管ID相似性显著提高,但却牺牲了一定程度的编辑性和灵活性。第二类方法【20】通过构建按ID分组的数据集支持非重建训练以增强编辑性;每个ID包含若干图像。然而,创建这样的数据集需要付出巨大的努力。而且,大多数ID对应于有限数量的名人,这可能会限制其对非名人的效果。
- 缺乏ID保真度。考虑到我们对面部的高度敏感性,在ID定制任务中保持高度的ID保真度至关重要。受GAN时代【7】面部生成任务【29, 39】成功经验的启发,提高ID保真度的一个直接想法是在扩散训练中引入ID损失。然而,由于扩散模型的迭代去噪特性【10】,实现准确的x0需要多个步骤。以这种方式训练所消耗的资源可能高得令人望而却步。因此,一些方法【2】直接从当前时间步预测x0,然后计算ID损失。然而,当当前时间步较大时,预测的x0往往嘈杂且有缺陷。在这种条件下计算ID损失显然不准确,因为面部识别骨干【4】是在照片级真实感图像上训练的。尽管提出了一些变通方法,如仅在噪声较小的时间步计算ID损失【25】或通过额外的推理步骤预测x0【45】,但仍有改进空间。
在这项工作中,为了在减少对原始模型行为影响的同时保持高ID保真度,我们提出了PuLID,一种通过对比对齐实现的纯粹和快速的ID定制方法。具体而言,我们引入了一个Lightning T2I分支以及标准扩散去噪训练分支。利用最近的快速采样方法【23, 32, 21】,Lightning T2I分支可以在有限且可控的步骤内从纯噪声生成高质量图像。通过这个额外的分支,我们可以同时解决上述两个挑战。首先,为了最小化对原始模型行为的影响,我们构建了一个对比对,其中包括相同提示和初始潜在变量,有和没有ID插入。在Lightning T2I过程中,我们在语义上对齐对比对的UNet特征,指导ID适配器如何插入ID信息而不影响原始模型的行为。其次,由于我们现在在ID插入后有了精确和高质量的生成x0,我们可以自然地提取其面部嵌入并与真实面部嵌入计算准确的ID损失。值得一提的是,这种x0生成过程与实际测试环境一致。我们的实验表明,在这种情况下优化ID损失可以显著提高ID相似性。
贡献总结如下:(1) 我们提出了一种无需调整的方法,即PuLID,在减轻对原始模型行为影响的同时保持高ID相似性。(2) 我们引入了一个Lightning T2I分支和常规扩散分支。在这个分支中,我们结合了对比对齐损失和ID损失,以最小化ID信息对原始模型的污染,同时确保保真度。与当前主流方法提高ID编码器或数据集相比,我们提供了新的视角和训练范式。(3) 实验表明,我们的方法在ID保真度和可编辑性方面实现了SOTA性能。此外,与现有方法相比,我们的方法对模型的ID信息侵扰较少,使得我们的方法在实际应用中更加灵活。
Related Work
基于微调的文本生成图像ID定制。文本生成图像模型的ID定制旨在使预训练模型能够生成特定身份的图像,同时遵循文本描述。两个开创性的基于微调的工作【5, 30】努力实现这一目标。Textual Inversion【5】为用户提供的ID优化了一个新的词嵌入,而Dreambooth【30】则通过微调整个生成器进一步增强了保真度。随后,各种方法【12, 17, 8, 35】在生成器和嵌入空间探索了不同的微调范式,以实现更高的ID保真度和文本对齐。尽管这些进展显著,但每个ID的耗时优化过程(至少需要几分钟)限制了其更广泛的应用。
无需微调的文本生成图像ID定制。为了减少在线微调所需的资源,一系列无需微调的方法【36, 38, 25, 42, 20, 41, 3】应运而生,这些方法直接将ID信息编码到生成过程中。这些方法面临的主要挑战是,在保持高ID保真度的同时,尽量减少对T2I模型原始行为的干扰。为了最小化干扰,一个可行的方法是使用面部识别模型【4】提取更抽象和相关的面部领域特定表示,就像IP-Adapter-FaceID【1】和InstantID【38】所做的那样。包含同一ID的多张图像的数据集可以促进共同表示的学习【20】。尽管这些方法取得了一定的进展,但它们还没有从根本上解决干扰问题。值得注意的是,ID保真度较高的模型往往会对原始模型的行为造成更大的干扰。在本研究中,我们提出了一种新的视角和训练方法来解决这一问题。有趣的是,该方法不需要按ID分组的数据集,也不局限于特定的ID编码器。
为了提高ID保真度,以前的工作【16, 2】使用了ID损失,这一做法受到了先前基于GAN的工作【29, 39】的启发。然而,在这些方法中,通常在当前时间步使用单一步骤直接预测x0,这往往会导致嘈杂和有缺陷的图像。这些图像对于面部识别模型【4】来说并不理想,因为它们是在真实世界的图像上训练的。PortraitBooth【25】通过仅在噪声较小的阶段应用ID损失来缓解这一问题,但这忽略了早期步骤中的损失,从而限制了其整体有效性。Diffswap【45】通过使用两步而不是一步来获得更好的预测x0,尽管这种估计仍然包含嘈杂的伪影。在我们的工作中,通过引入Lightning T2I训练分支,我们可以在更准确的设置中计算ID损失。
我们注意到一个同时进行的工作LCM-Lookahead【6】,它也使用了快速采样技术(即LCM【23】)来实现更精确的x0预测。然而,该工作与我们的工作有几个不同之处。首先,LCM-Lookahead在传统的扩散去噪过程中对x0进行精确预测,而我们从纯噪声开始,迭代去噪到x0。我们的方法与实际测试设置更一致,使得ID损失的优化更加直接。其次,为了增强提示编辑能力,LCM-Lookahead利用了SDXL-Turbo【32】的模式崩溃现象来合成一致的ID数据集。然而,合成的数据集可能面临多样性和一致性挑战,作者发现,使用该数据集训练可能比其他方法更频繁地产生风格化结果。相比之下,我们的方法不需要按ID分组的数据集。相反,我们通过一种更基础和直观的方法,即对比对齐,来增强提示跟随能力。
扩散模型的快速采样。在实践中,扩散模型通常在1000步内进行训练。在推理过程中,这种冗长的过程可以借助高级采样方法【33, 22, 15】缩短到几十步。最近基于蒸馏的工作【21, 23, 32】进一步将这一生成过程加速到10步以内。其核心动机是指导学生网络对齐与基础教师模型更远的点。在本研究中,我们引入的Lightning T2I训练分支利用了SDXL-Lightning【21】加速技术,从而使我们能够在仅4步内从纯噪声生成高质量图像。
Methods
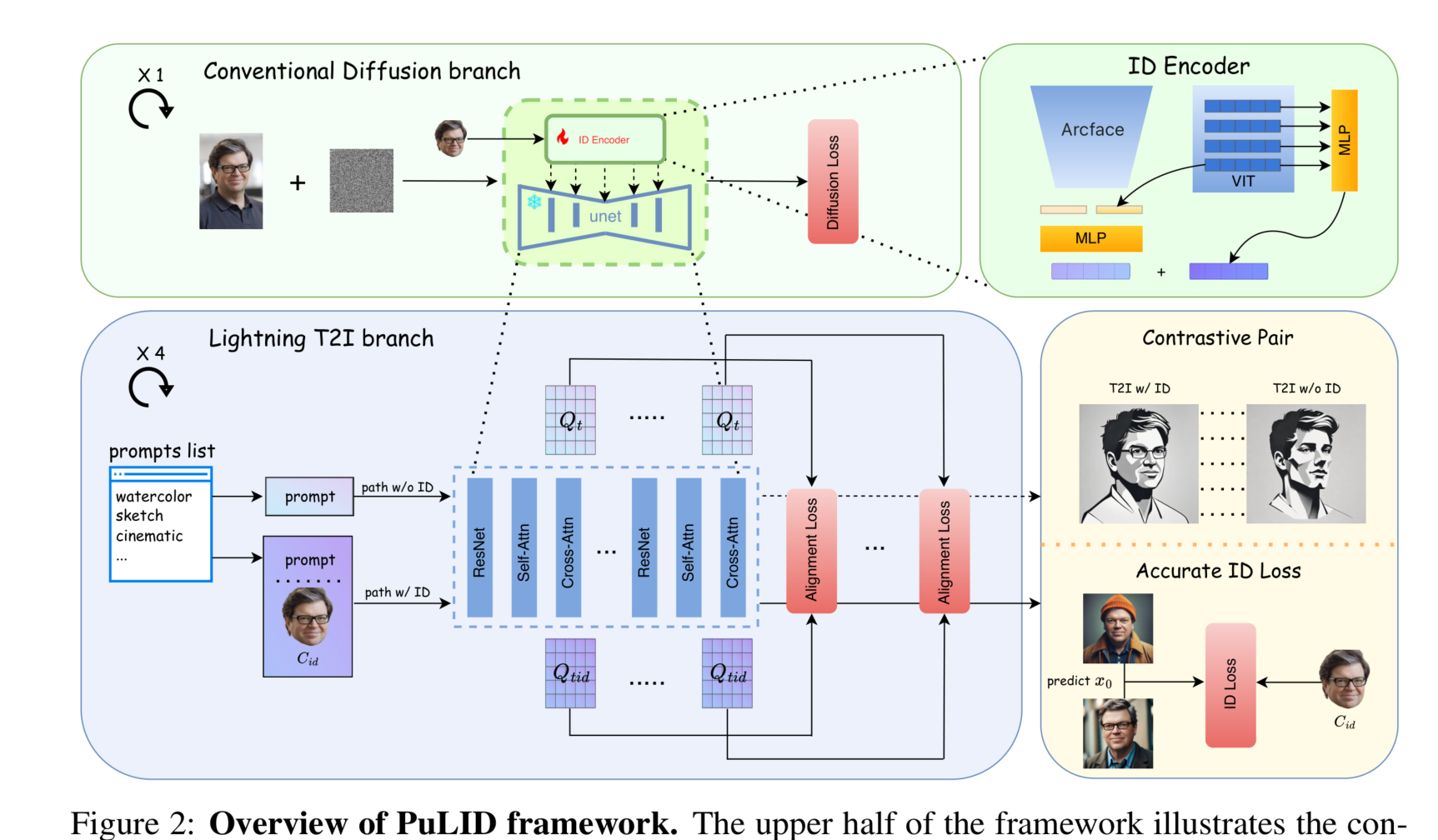
图2:PuLID框架概述。框架的上半部分展示了传统的扩散训练过程。从同一图像中提取的面部用作ID条件 ( C_{\text{id}} )。框架的下半部分展示了本研究中引入的Lightning T2I训练分支。该分支利用了最新的快速采样方法,通过几步迭代去噪从纯噪声生成高质量图像(本文中为4步)。在这个分支中,我们构建了有ID注入和无ID注入的对比路径,并引入了对齐损失,以指导模型如何在不破坏原始模型行为的情况下插入ID条件。由于该分支可以生成照片级真实感图像,这意味着我们可以实现更准确的ID损失优化。