对于在数据库行业中摸爬滚打多年的老鸟 DBA 来说,TiDB 可是一点也不陌生,作为 PingCAP 公司自主研发的真开源分布式数据库,其先进的设计理念以及丰富的生态工具,可算得上是业界自主创新和性能领先的代名词。
TiDB 是谁?
显然这个章节在这里有点多余,但我们也想为不了解 TiDB 的小伙伴们做一个科普,TiDB 是一款开源的分布式关系型数据库管理系统,由PingCAP开发,旨在解决传统关系型数据库在扩展性和灵活性上的局限。它有很多的优点:
- TiDB 是开源产品:TiDB 具有一个相当成熟的社区,并且具有相当数量并持续增长的代码贡献者,这使 TiDB 的成熟度越来越高。
- 强大的可扩展性:TiDB 是一个分布式数据库,有着非常好的读、写扩展性,尤其是写扩展性,可以存储海量的数据,数百 TB 数据轻松存储。
- 存算分离架构:使用户可以单独为计算资源或存储资源进行扩容,避免其中一方资源的浪费。
- HTAP 能力:OLTP 和 OLAP 能力相融合,提供 HTAP 的混合负载能力,赋予 TiDB 强大的业务处理能力和数据查询能力。
- 在线扩缩容与升级:在 TiDB 的存算分离架构下,数据库的扩缩容和升级再也不用停机了,对于长期在线的业务系统来说尤为重要。
TiDB 配套工具的弊病?
TiDB 很强,在配套工具方面,TiDB 也提供了各式各样的功能,例如 Dumpling、Lightning、Data Migration(DM)、Backup & Restore、TiCDC 等等,这些工具各自都有不同的使用场景和限制,想要熟练运用这些工具,那就需要花大量的时间去学习。
然而,即使你可以很熟练地去运用这些工具,也可能会碰到一些问题,就拿 TiDB 的数据导入和数据导出方面举例,Dumpling 工具用于 TiDB 数据库导出数据,而 Lightning 用于 TiDB 的数据导入,这两个工具就存在如下一些限制:
-
通过 Dumpling 工具导出较大的单表(超过 1 TB)时,可能会因为数据过大导致 TiDB 内存溢出(OOM)。
-
Lightning 工具需要 tikv-importer 等工具配合使用,操作复杂难以上手,并且该工具运行后,TiDB 集群无法正常对外提供服务。
-
最重要的一个点,使用数据导入导出工具(包含上述两个工具)会对数据库本身的业务读写造成负面影响,降低数据库的性能。
整体来讲,使用这些工具多多少少需要数据库来配合,这样会对业务的可用性带来很大的影响,这就有点和企业所注重的点背道而驰,对于企业来说,我最关注的是数据库的稳定性,你不能对我的业务造成任何影响,然后我还要高效,还要操作简单,有办法吗?
NineData 的 TiDB 导入导出解决方案
在 NineData 最新发布的版本中,提供了对 TiDB 数据导入导出的支持,得益于 NineData 天然的独立性,在对 TiDB 进行数据导入导出时,再也无需 TiDB 数据库进行各种各样的妥协了,让 TiDB 该干什么干什么去,剩下的交给 NineData 就行。
在功能方面,导入功能支持 SQL、CSV、EXCEL 等文件格式,同时支持多种自定义配置,例如可以自定义指定导入到哪个表的哪个列、遇到重名冲突时的执行策略等;导出功能支持通过 SQL 语句或直接选择目标库表进行导出,还支持数据、结构、结构+数据三种形式,支持导出到 SQL、CSV、EXCEL 三种文件类型,除此之外,还有多种高级设置(大字段导出、SQL 脚本扩展、触发器|函数|视图|存储过程|事件导出等)可供选择。
在操作方面,页面全程傻瓜式流程引导,只要没有语言障碍,就能轻松玩转。
在安全方面,非管理员用户执行导入导出时,系统自动生成审批流程,只有在管理员审批通过后,才能实际执行到 TiDB 数据源。
功能实操演示
数据导出
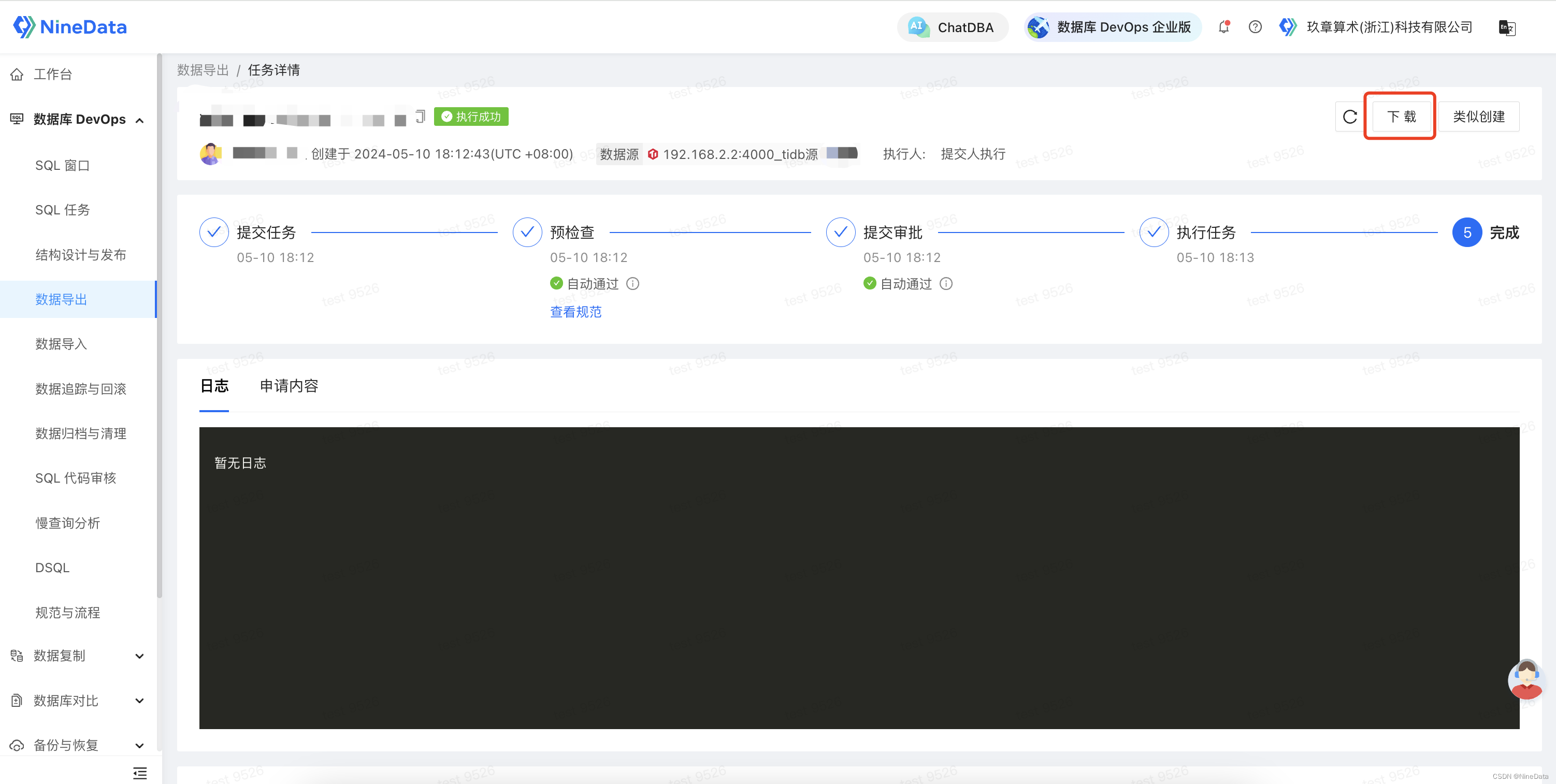
-
登录 NineData 控制台,单击数据库 DevOps>数据导出,然后在页面中单击创建数据导出,在如下页面中根据提示配置导出任务,然后单击创建数据导出。

-
任务跑完后,可以在任务详情页面单击下载,将导出的文件下载到本地,该文件可用于下方的数据导入任务。
数据导入
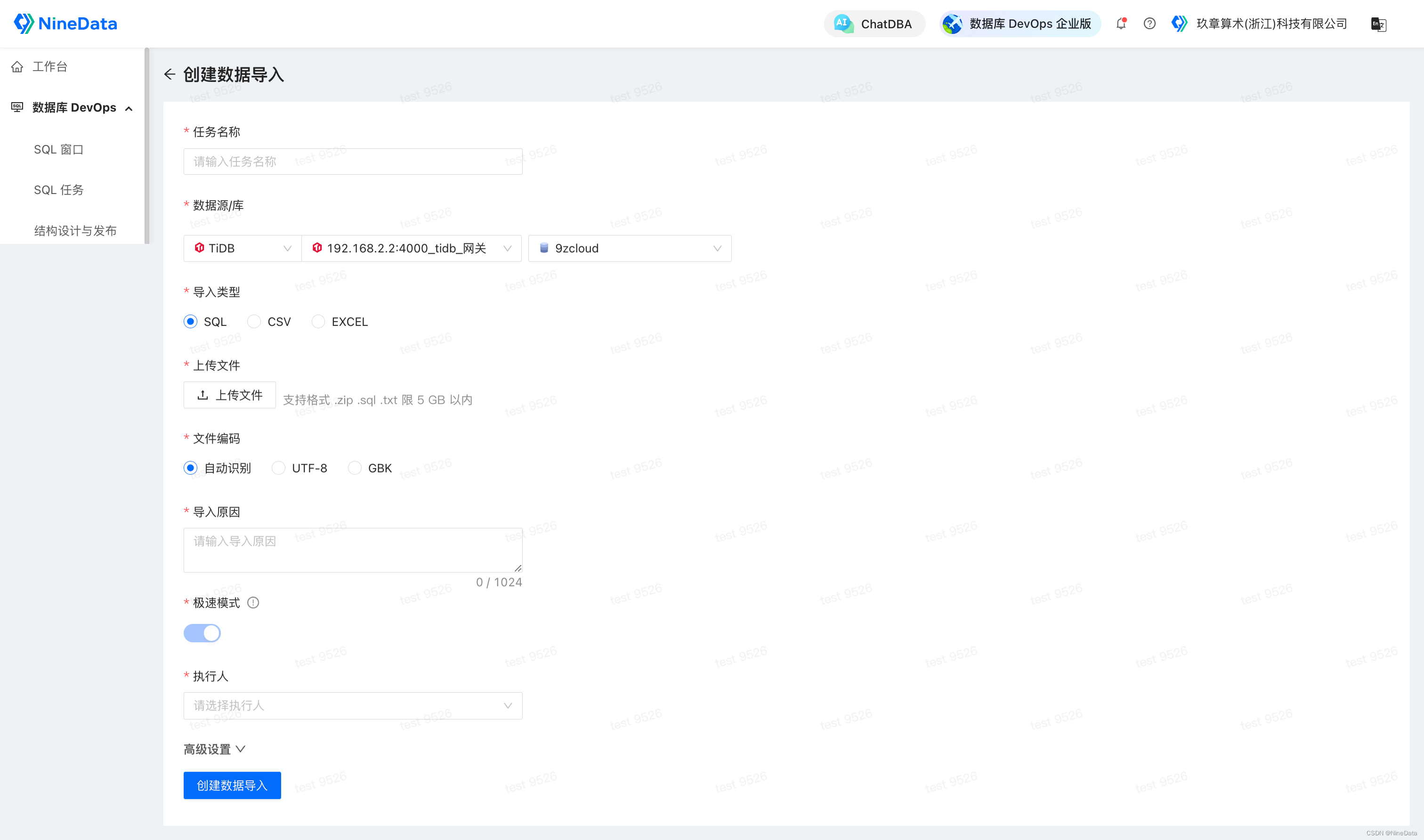
-
登录 NineData 控制台,单击数据库 DevOps>数据导入,然后在页面中单击创建数据导入,在如下页面中根据提示配置导入任务,然后单击创建数据导入。
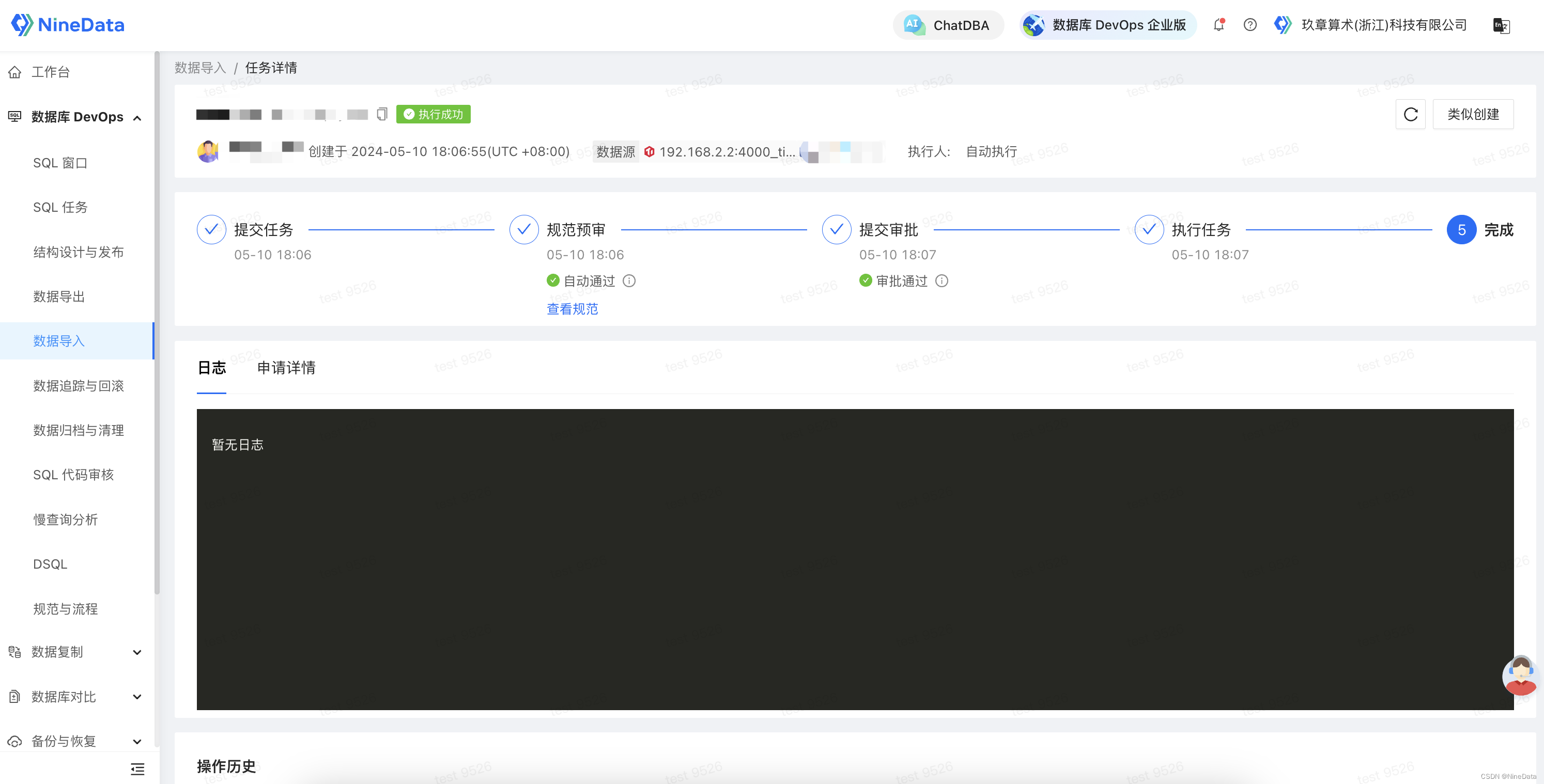
-
等待任务跑完即可。
总结
在本次的功能验证过程中可以发现,NineData 对 TiDB 的数据导入导出功能都提供了良好的支持,并且完美绕开了官方配套工具对业务库带来的性能影响,真正意义上做到了企业所关注的稳定、高效、简单、安全。