目录
环境概述:
http模块中的全局模块
1. root配置主要是对主web页面的路径访问。
2.server虚拟主机
2.1基于IP:
2.2基于域名:
3.alias别名
4.location匹配
5.access模块:
6.验证模块
7.自定义错误页面
8.日志存放位置
9.检测文件是否存在
10.作为下载服务器配置
在nginx服务中,主要作用就是提供web服务,而提供web服务最重要的是核心配置文件中的http模块。我编译安装在/apps/nginx下,有conf,html,logs,html等文件夹。
环境概述:
wget下载在/data/下,编译安装在/apps/nginx/下
有两台机器,Node1(192.168.114.10)和Node2(192.168.114.20),Node1做为nginx服务端,Node2作为客户端访问Node1测试使用。
http模块中的全局模块
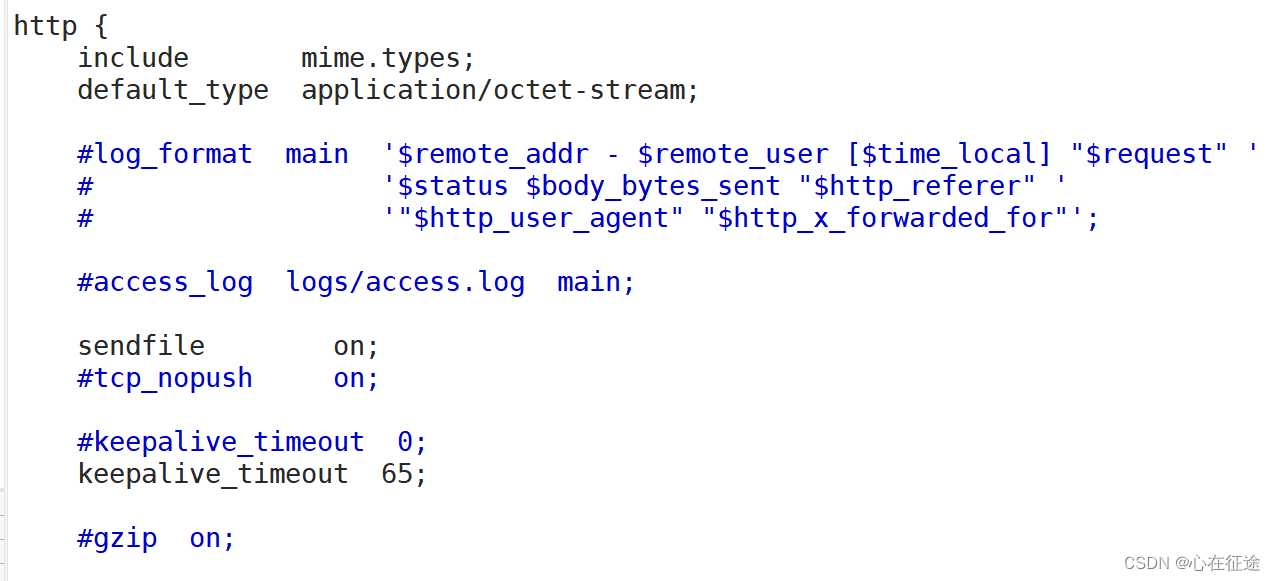
include mime.types; 是导入支持的文件类型,由于是编译安装,默认在指定的路径/apps/nginx/下的conf/mime.types。只要是在该路径下,那么访问链接就是下载。
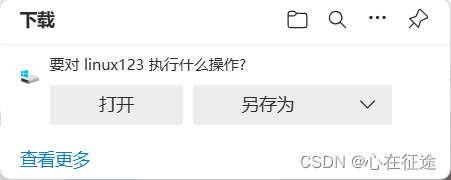
我们在/apps/nginx/html下写一个文件交linux123,echo "linux123" > linux123
使用浏览器访问系统下的该文件,192.68.114.10/linux123(系统IP/文件名)就会出现下载操作。如图:
default_type application/octet-stream; 如果include文件类型不明确,那么默认就是这个类型。
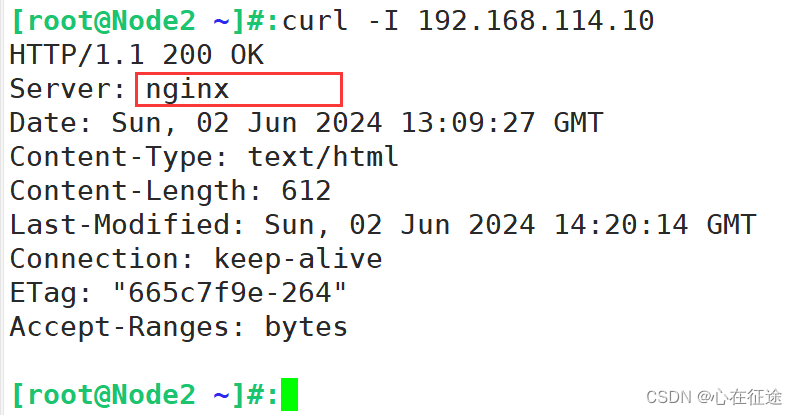
server_tokens off; 该配置项是隐藏nginx版本。添加该行,重启(nginx -s reload)。使用测试系统查看,隐藏了版本号。
keepalive_timeout 65 65; 是设置会话保持的时间,可以有两个值,后者值是响应首部,keepAlived:timeout=65;
gzip on; 是开启压缩文件的功能,但不压缩图片。
http模块中,还有server模块且可以有多个server模块,每个server模块相当于一个虚拟主机,可以对端口号、IP地址、域名、主站点、日志等设置,第一个server默认为虚拟服务器。
server模块中又有若干个location模块,主要作用是匹配URL。
server下的root配置
1. root配置主要是对主web页面的路径访问。
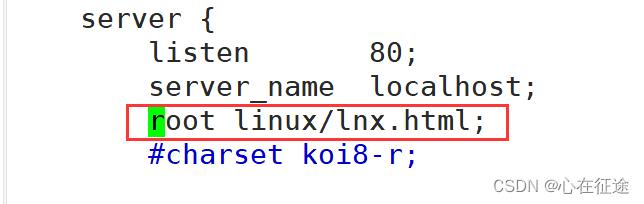
在配置文件nginx.conf中添加一行web访问路径。root linux/lnx.html
在html下创建文件夹mkdir linux。再写入内容。 echo "Linux html" > linux/lnx.html
[root@Node1 html]#:mkdir linux
[root@Node1 html]#:echo "Linux html" > linux/lnx.html
再测试机访问curl 192.168.114.10/linux/lnx.html。跟上路径
[root@Node2 ~]#:curl 192.168.114.10/linux/lnx.html
Linux html
2.server虚拟主机
在配置文件中,http模块中的每一个server就是一个虚拟主机,第一个server为默认虚拟服务器。
我们在主站点创建一个文件夹,但需要再主配置文件nginx.conf中包含该子配置文件的路径。
写在子配置文件中方便管理维护。
2.1基于IP:
基于IP,先添加两个虚拟ip地址:
ifconfig ens33:0 192.168.114.11/24
ifconfig ens33:1 192.168.114.12/24
ifconfig 查看:

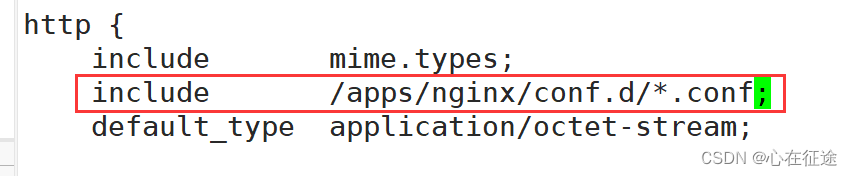
写两个server文件:分别代表两台主机(实际是一台):
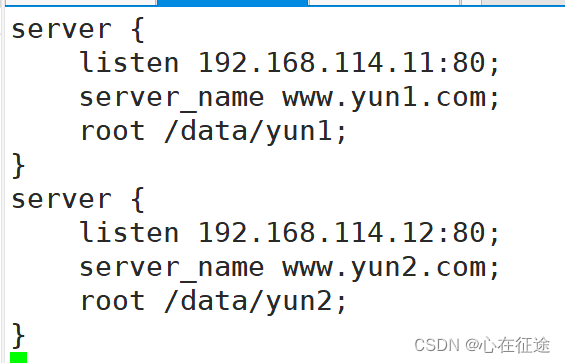
重新加载配置文件:nginx -s reload 。在站点写入html文件:
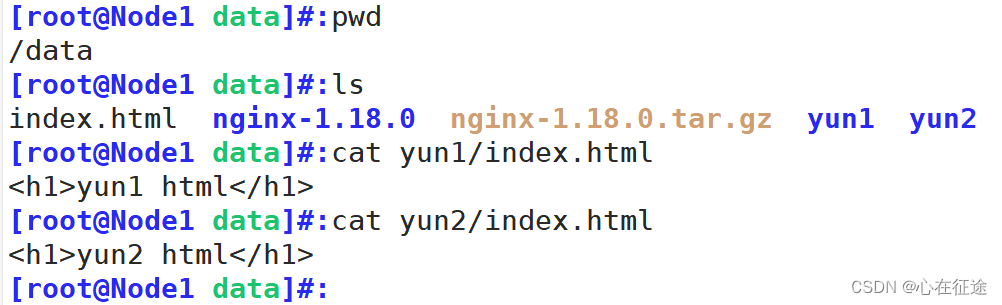
在真机浏览器中分别访问192.168.114.11和192.168.114.12:
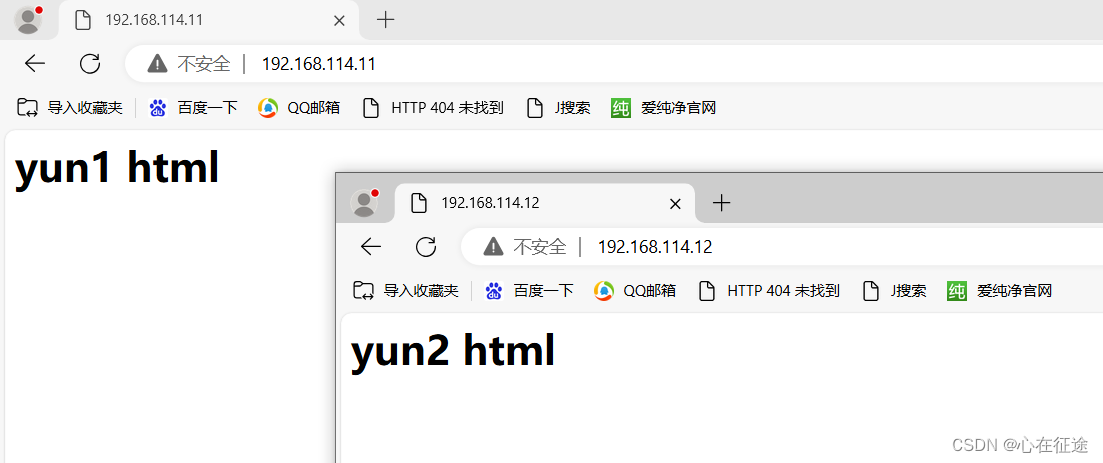
2.2基于域名:
在该文件下创建一个文件作为子配置文件sver.conf。
[root@Node1 nginx]#:pwd
/apps/nginx[root@Node1 nginx]#:mkdir conf.d
cd conf.d
[root@Node1 conf.d]#:vim sver.conf
server {
listen 80;
server_name www.pc.com;
root html/pc/;
}
server {
listen 8080;
server_name www.jd.com;
root html/linux/;
}修改完子配置文件后,重新加载配置文件:
[root@Node1 conf.d]#:nginx -s reload
listen监听端口,server_name域名,root主页文件的路径。
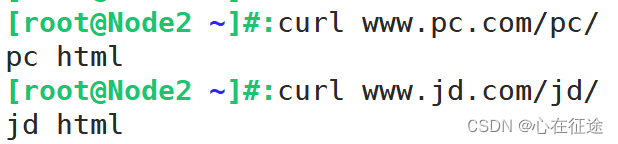
要在html文件夹下创建两个文件夹pc和jd分别写入index.html文件。
[root@Node1 html]#:mkdir pc jd
[root@Node1 html]#:echo "jd html" > jd/index.html
[root@Node1 html]#:echo "pc html" > pc/index.html#查看web文件
[root@Node1 html]#:cat jd/index.html
jd html
[root@Node1 html]#:cat pc/index.html
pc html
此外,还需要在测试机上修改/etc/hosts文件,添加一行

测试:
还可以基于端口号,IP,主站点,日志等。
3.alias别名
访问location中的uri相当于访问alias中的uri。
在/data/下写一个网页,

自配置文件conf.d/sver.conf
server {
listen 80;
server_name www.pc.com;
location /cxk {
alias /data/;}
}
curl 192.168.114.10/cxk 相当于置换访问192.168.114.10/data/。-L跟着跳

4.location匹配
location匹配规则:location [ = | ^~ | ~ | ~* | 不带符号 ] uri { ...... }
示例:
location = / {
......
}
=是精确匹配,只能匹配/,大小写敏感,优先级最高。
^~ 支持正则表达式,以什么什么开头,不区分大小写。
~ 支持正则表达式,区分大小写。
~* 支持正则表达式,不区分大小写。
不带符号,匹配起始于uri的所有uri
有以下location:
location ~ /Test1/$ {
return 200 'A位置最前的正则表达式匹配';
}
location ~* /Test1/(\w+)$ {
return 200 'B长正则表达式匹配';
}
location ^~ /Test1/ {
return 200 'C 停止正则表达式匹配';
}
location /Test1/Test2 {
return 200 'D 无符号最长的前缀匹配';
}
location /Test1 {
return 200 'E 无符号短前缀匹配';
}
location = /Test1 {
return 200 'F =精确匹配!';
}
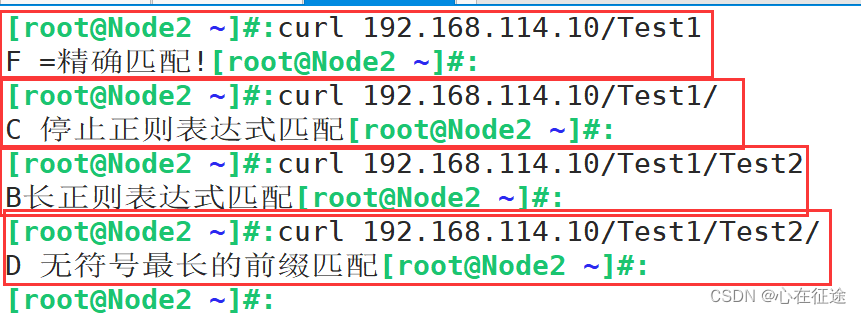
在客户端curl时:
curl 192.168.114.10/Test1
curl 192.168.114.10/Test1/
curl 192.168.114.10/Test1/Test2
curl 192.168.114.10/Test1/Test2/
这四种情况的不同:
第一种情况,会优先匹配F,因为是=/Test1精确匹配。
第二种情况,F排除,E能匹配上,D排除,C能匹配上,如果C匹配到,出现^~就不匹配正则表达式。故A,B都不看。由于C匹配最长,且是/Test1/开头,故匹配到C。
第三种情况/Test1/Test2。显然^~匹配不到,正则表达式中B匹配到了,(~* /Test1/(\w+)$代表以数字字母出现一个或多个)。匹配到正则后,优先级比其他高。故匹配B。
第四种情况:/Test1/Test2/。A,B,F排除,A是以/Test/结尾,B是以数字字母结尾 第四种情况是/结尾,F精确匹配排除。只有C,D,E能够匹配上,但由于D是最长匹配原则,只能匹配D。
如下:
[root@Node2 ~]#:curl 192.168.114.10/Test1
F =精确匹配![root@Node2 ~]#:[root@Node2 ~]#:curl 192.168.114.10/Test1/
C 停止正则表达式匹配[root@Node2 ~]#:[root@Node2 ~]#:curl 192.168.114.10/Test1/Test2
B长正则表达式匹配[root@Node2 ~]#:[root@Node2 ~]#:curl 192.168.114.10/Test1/Test2/
D 无符号最长的前缀匹配[root@Node2 ~]#:[root@Node2 ~]#:
5.access模块:
access模块作为访问控制模块,能够对来自客户端的某个IP阻止阻止访问。在编译安装时要加入access模块,查看是否安装该模块:
[root@Node1 nginx-1.18.0]#:./configure --help | grep access
--without-http_access_module disable ngx_http_access_module
--http-log-path=PATH set http access log pathname
--without-stream_access_module disable ngx_stream_access_module
该模块可以支持IPv6地址。
例子如下:
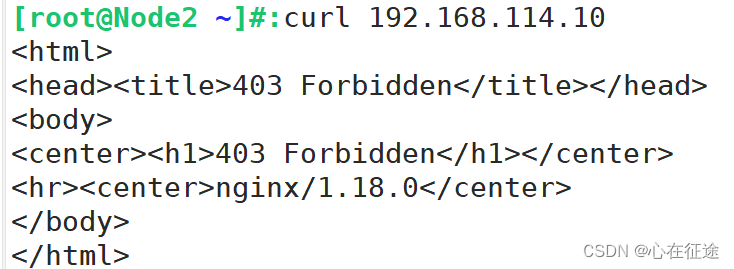
我有三台主机Node1:192.168.114.10,Node2:192.168.114.20,Node:192.168.114.30
只拒绝Node2主机
server {
listen 80;
server_name www.kgc.com;
deny 192.168.114.20;
allow 192.168.114.0/24;
location / {
root /data/html/;
}
}
在/data/html/下写一个网页index.html内容为:
[root@Node1 html]#:ls
index.html
[root@Node1 html]#:cat index.html
<h1>/data/html</h1>
当在Node2上访问和在Node3上访问测试:

达到访问控制的目的,文件中应该把小范围写在前面,大范围写在后面,如果是
deny 192.168.114.20;
allow 192.168.114.0/24;
两个调换,则会允许192.168.114.0/24这个网段的地址访问而导致192.168.114.20也能访问,就会达不到禁止某一个IP访问的目的,故范围小的写前面。
6.验证模块
验证模块,是用户访问我的地址的时候,向用户发起一个信息验证。需要下载httpd-tools工具包。
yum install httpd-tools -y。需要用到htpasswd命令。
添加一个loction:

auth_basic是提示信息,下面指的是密码文件存放位置。
需要在子配置文件conf.d中新建一个隐藏文件:
[root@Node1 conf.d]#:mkdir .httpuser
#再向其中添加一个验证信息,用户名和密码:第一次添加:
[root@Node1 conf.d]#:htpasswd -bc /apps/nginx/conf.d/.httpuser kgc 123456
-c是新建用户名和密码对应的文件
-b将密码跟在用户名后面
如果不是第一次添加,要添加其他用户:
[root@Node1 conf.d]#:htpasswd /apps/nginx/conf.d/.httpuser xiaoming
New password:
Re-type new password:
Adding password for user xiaoming
重新加载配置文件:nginx -s reload
在浏览器中输入192.168.114.10/admin,会弹出一个验证模块,输入正确的信息
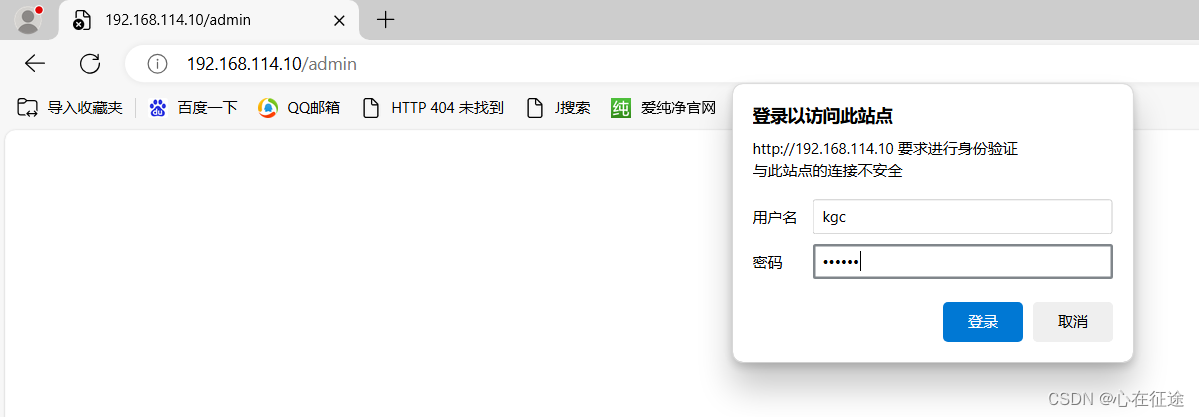
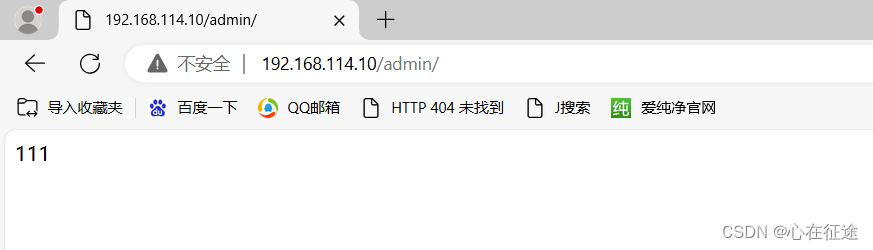
如果验证其他用户,可能有缓存,清楚历史浏览记录(包括缓存信息)即可。否则不会出现验证模块。
7.自定义错误页面
自定义错误页面是客户端输入了错误的域名,比如www.baidu.com/xxxxxxxxxxxxxx就会报404错误,那么就让客户自动跳转到我们规定的页面。
在server中加入error_page配置项:
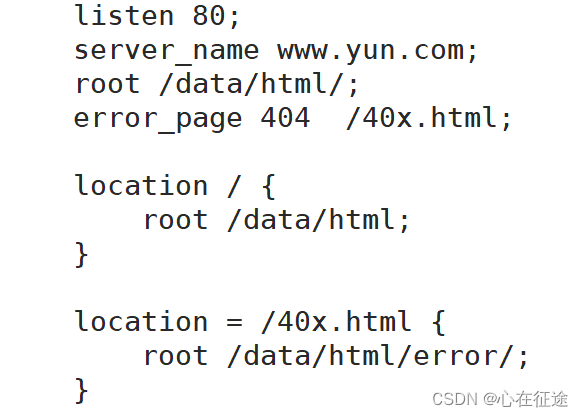
错误页面的位置,自定义的,这里放在/data/html/error/下的40x.html文件中
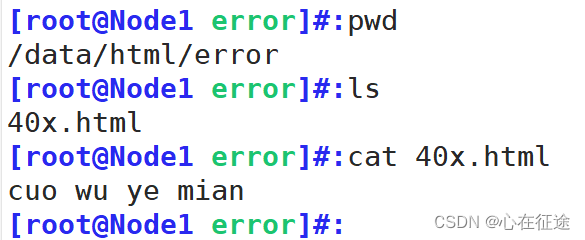
在客户端/etc/hosts中添加一行192.168.114.10 www.yun.com。使用curl www.yun.com/adfafddfs

8.日志存放位置
通常将生成的日志文件指定到某个位置,默认的位置是/apps/nginx/logs/下,有三个文件,一个是正确日志文件,一个是错误日志文件,一个是主进程pid号

当我们设置两台主机时,两台主机的日志文件都会放入该路径下,我们设置访问不同主机时生成的日志存放在不同的位置,即两个网站的日志分离。
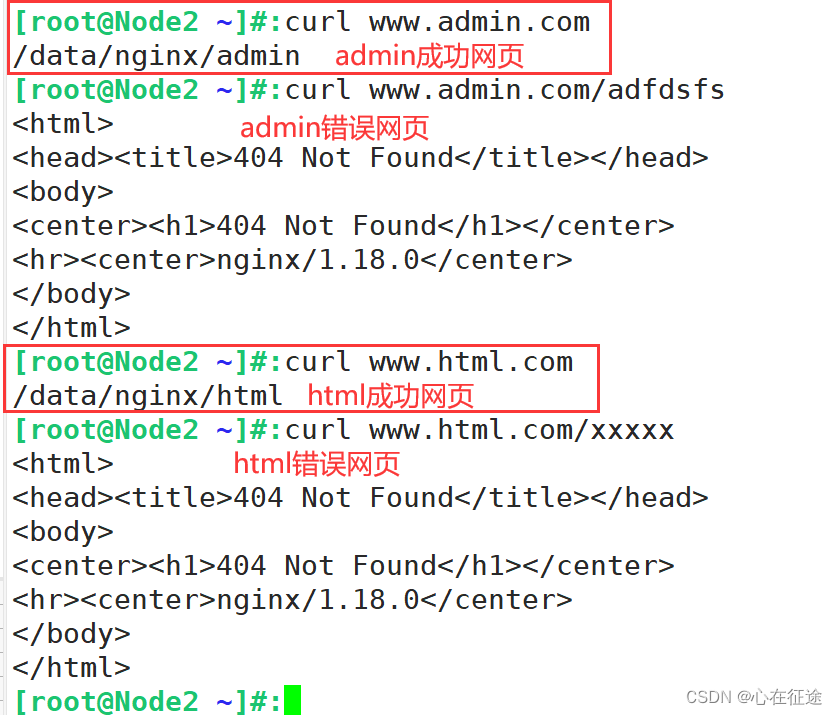
分析:两个网站分别为www.admin.com和www.html.com。在/data/下创建nginx文件夹,nginx下分别有admin和html和logs文件夹。admin和html存放正常的网页,logs存放两个网站生成的错误日志,日志文件分别是admin_access.log和admin_error.log和html_access.log和html_error.log四个日志文件(这四个日志文件不需要创建,重启配置文件后能够自动生成)。分为代表admin正确日志,错误日志,html正确日志,错误日志。使用客户端访问curl www.admin.com(正确网站)和curl www.html.com/xxxxx(错误网站)。查看对应日志中是否有记录。
那么在子配置文件中有两个配置文件admin.conf和html.conf。两个不同域名网站。
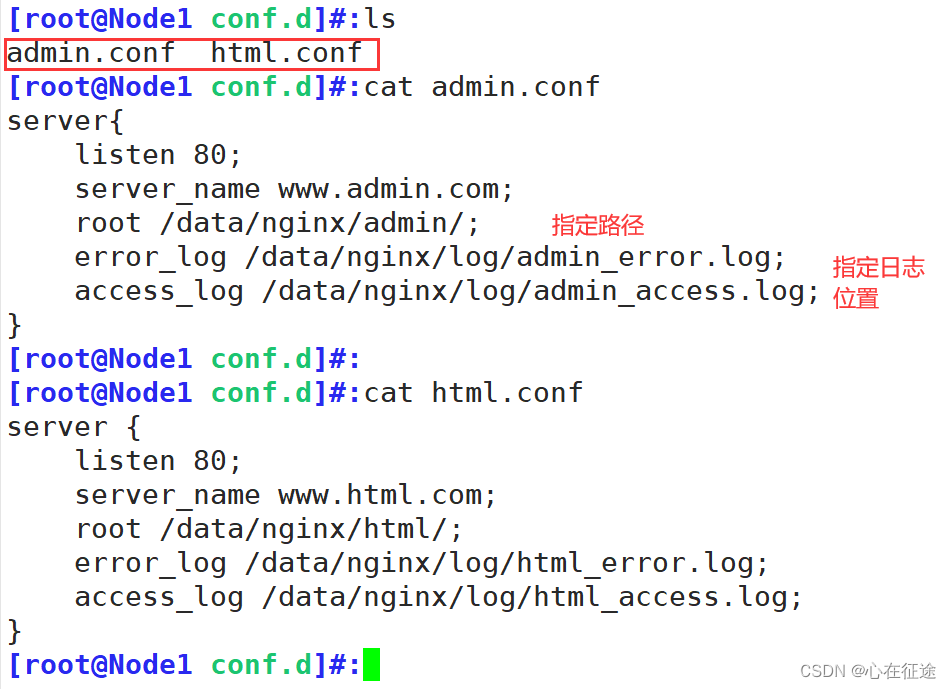
创建存放日志的路径。并重新加载配置文件。
[root@Node1 conf.d]#:mkdir -p /data/nginx/logs/
[root@Node1 conf.d]#:nginx -s reload
就会发现在路径下自动成了四个日志文件。

在nginx下创建两个主页文件夹,并写入网页内容:
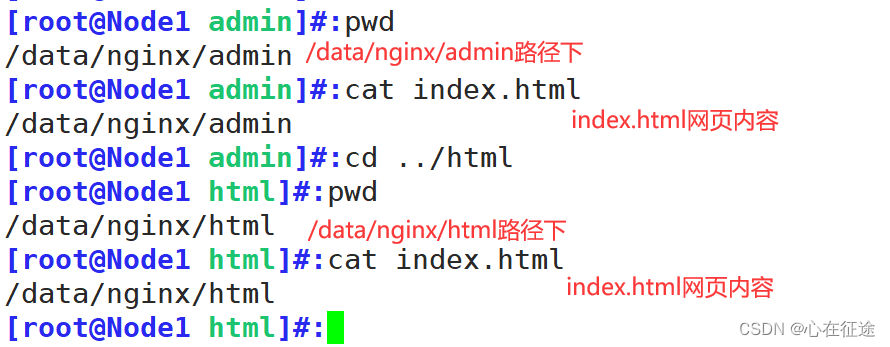
在客户端:vim /etc/hosts添加一行。域名解析
192.168.114.10 www.admin.com www.html.com
使用客户端访问:
查看日志是否生成:
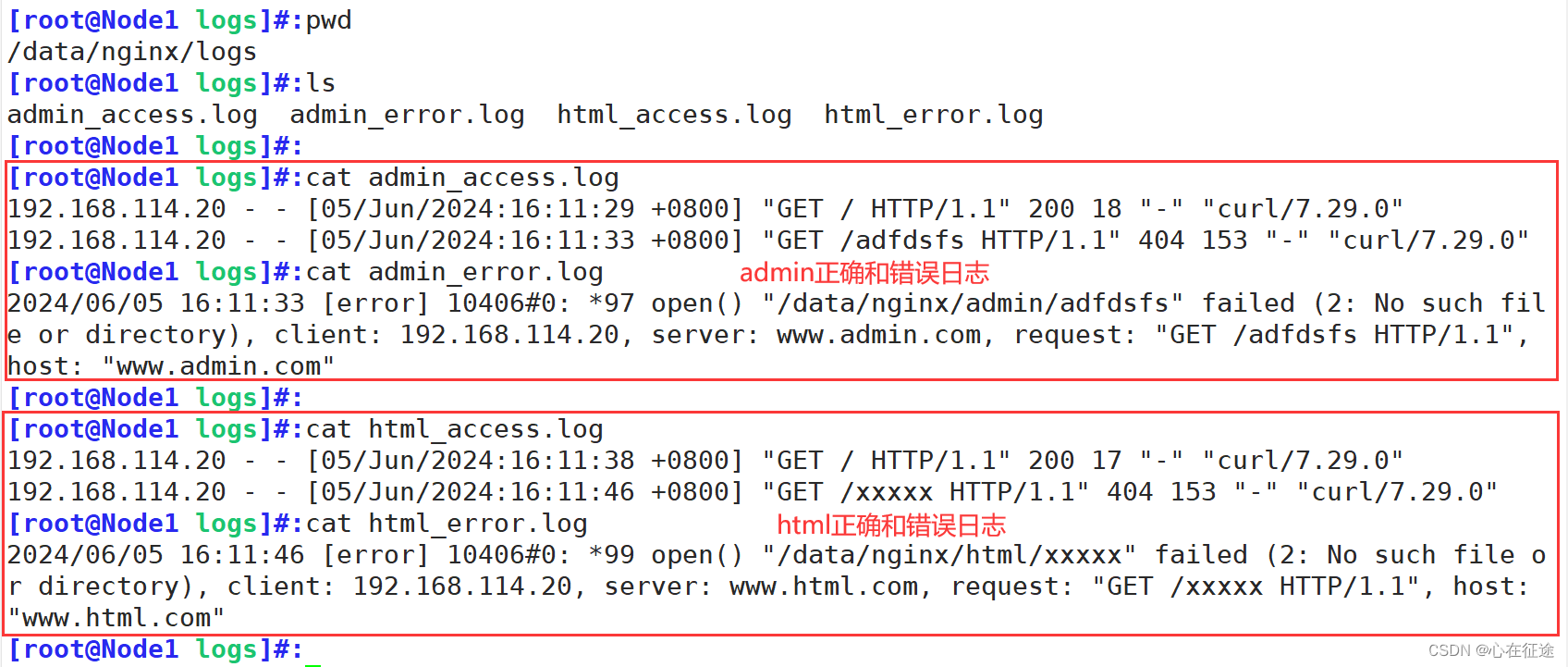
实现了不同网站的日志分离!
9.检测文件是否存在
当输入了正确的网站如curl www.html.com/zs。
检测规则:$uri $uri.html $uri/index.html /about/default.html(如果都没有就会有个最终匹配到的,如果没有就报错了)
先看在root指定的目录下是否存在zs,按规则顺序匹配,如果有就就不在匹配,没有的话就匹配zs.html,再没有就匹配zs/index.html,再没有就匹配最后默认的/about/default.html。
实验:先都不设置,匹配默认的,然后依次从后往前匹配。
配置文件中:
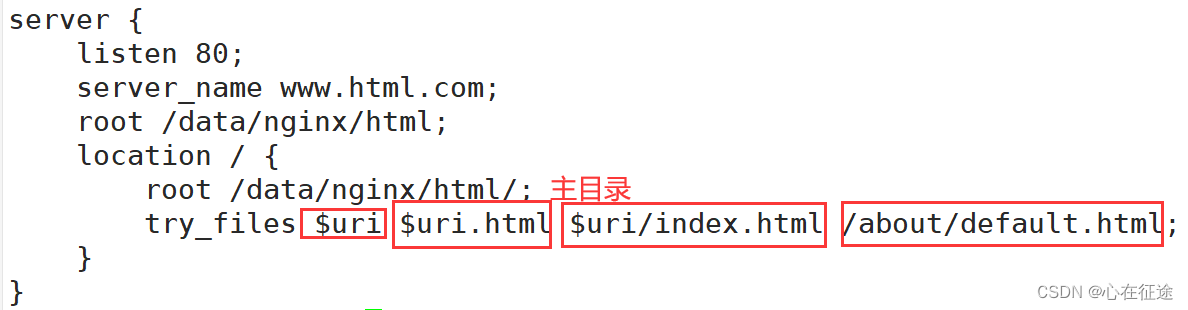
先实验匹配最后的。要在主目录下/data/nginx/html/下创建一个about文件夹,再创建一个最后的页面default.html:
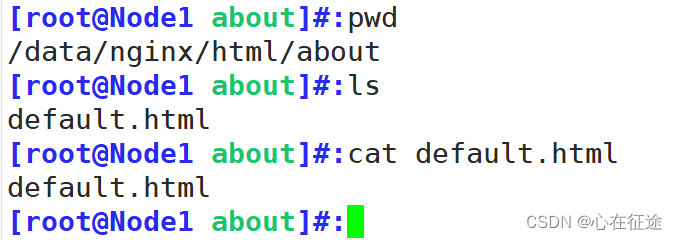
在客户端curl 192.168.114.10/zs一个没有zs的uri,验证是否能访问到default.hmtl文件。依次匹配,都没中,就会匹配到最后这个打底的。

依次往前$uri/index.html
在主目录下创建zs文件夹,[root@Node1 html]#:mkdir zs,写入index.html文件。
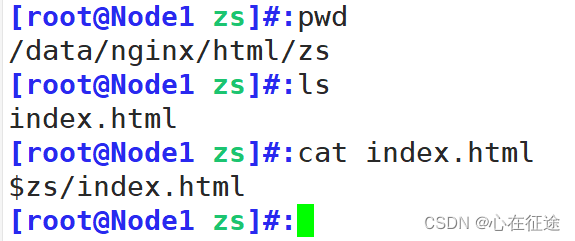
再次访问:curl 192.168.114.10/zs

发现匹配到了$uri/index.html,就不再往下匹配。
再往前匹配,直接在主目录html下创建zs.html文件。
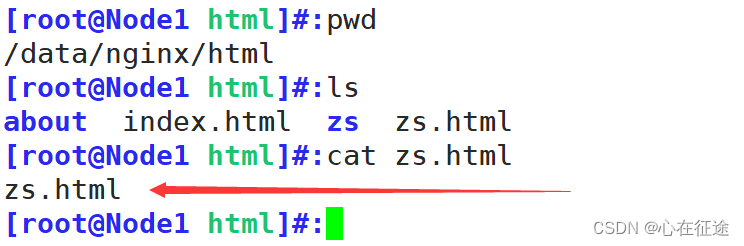
再次访问curl 192.168.114.10/zs

再次往前匹配到$uri,即$zs
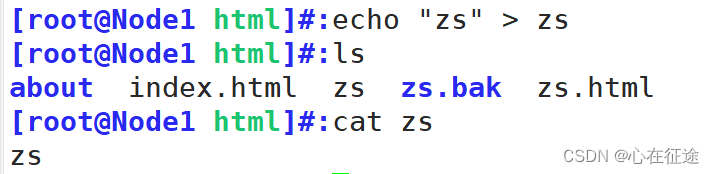
再次curl 192.168.114.10/zs:
总结,匹配次序为$uri $uri.html $uri/index.html /about/default.html。如果前面找不到就依次往后匹配,最终有个打底的,否则报错。实验依次从后(/about/default.html)往前($uri)做实验。
10.作为下载服务器配置
先指定主目录:root /data/nginx/html
在location做以下配置:
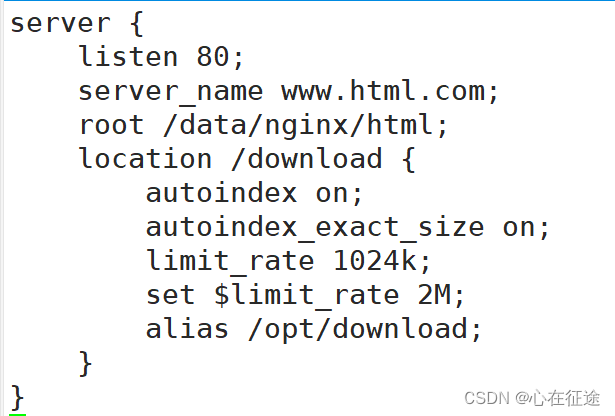
autoindex on; #开启下载服务器
autoindex_exact_size on; #开启确切大小
limit_rate 1024k; #给下载限速1024k,默认是字节数
set $limit_rate 2M; #谁先生效
alias /opt/download; #别名
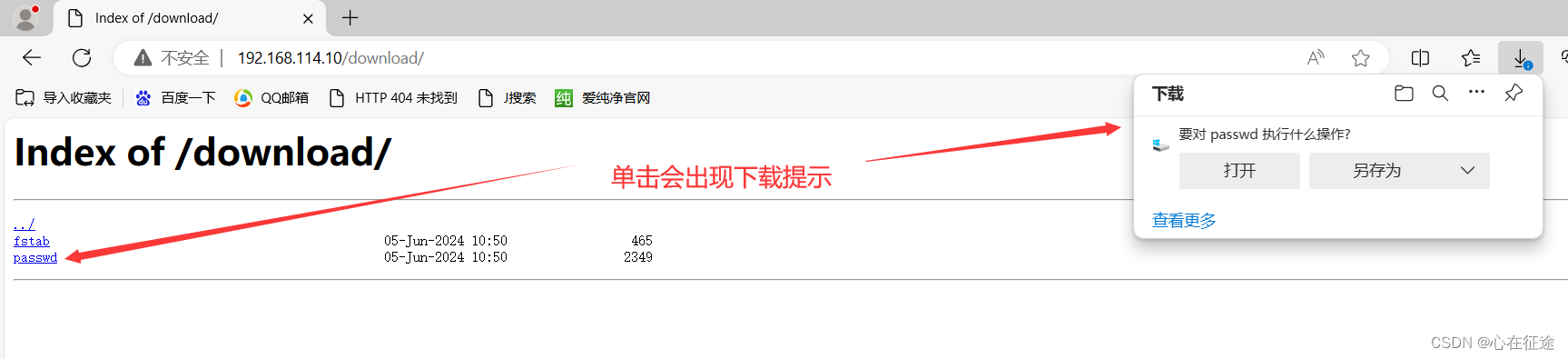
在/opt/下创建一个文件夹download,里面复制几个文件过来
重新加载配置文件:nginx -s relaod
使用浏览器访问192.168.114.10/download
-------end-------