Apache ShardingSphere实战与核心源码剖析
1.数据库架构演变与分库分表介绍
1.1 海量数据存储问题及解决方案
如今随着互联网的发展,数据的量级也是成指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。
阿里数据中心内景( 阿里、百度、腾讯这样的互联网巨头,数据量据说已经接近EB级)

使用NoSQL数据库, 通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
NoSQL并不是万能的,就比如有些使用场景是绝对要有事务与安全指标的, 所以还是要用关系型数据库, 这时候就需要搭建MySQL数据库集群,为了提高查询性能, 将一个数据库的数据分散到不同的数据库中存储, 通过这种数据库拆分的方法来解决数据库的性能问题。
遇到的问题
-
用户请求量太大
单服务器TPS、内存、IO都是有上限的,需要将请求打散分布到多个服务器
-
单库数据量太大
单个数据库处理能力有限;单库所在服务器的磁盘空间有限;单库上的操作IO有瓶颈
-
单表数据量太大
查询、插入、更新操作都会变慢,在加字段、加索引、机器迁移都会产生高负载,影响服务
解决方案
- 刚开始我们的系统只用了单机数据库
- 随着用户的不断增多,考虑到系统的高可用和越来越多的用户请求,我们开始使用数据库主从架构
- 当用户量级和业务进一步提升后,写请求越来越多,这时我们开始使用了分库分表
1.2 数据库架构的演进
1.2.1 理财平台 - V1.0
此时项目是一个单体应用架构 (一个归档包(可以是JAR、WAR、EAR或其它归档格式)包含所有功能的应用程序,通常称为单体应用)

这个阶段是公司发展的早期阶段,系统架构如上图所示。我们经常会在单台服务器上运行我们所有的程序和软件。
在项目运行初期,User表、Order表、等等各种表都在同一个数据库中,每个表都包含了大量的字段。在用户量比较少,访问量也比较少的时候,单库单表不存在问题。
把所有软件和应用都部署在一台机器上,这样就完成一个简单系统的搭建,这个阶段一般是属于业务规模不是很大的公司使用,因为机器都是单台的话,随着我们业务规模的增长,慢慢的我们的网站就会出现一些瓶颈和隐患问题
公司可能发展的比较好,用户量开始大量增加,业务也越来越繁杂。一张表的字段可能有几十个甚至上百个,而且一张表存储的数据还很多,高达几千万数据,更难受的是这样的表还挺多。于是一个数据库的压力就太大了,一张表的压力也比较大。试想一下,我们在一张几千万数据的表中查询数据,压力本来就大,如果这张表还需要关联查询,那时间等等各个方面的压力就更大了。
1.2.2 理财平台 - V1.x
随着访问量的继续不断增加,单台应用服务器已经无法满足我们的需求。所以我们通过增 加应用服务器的方式来将服务器集群化。
存在的问题
采用了应用服务器高可用集群的架构之后,应用层的性能被我们拉上来了,但是数据库的负载也在增加,随着访问量的提高,所有的压力都将集中在数据库这一层.
1.2.3 理财平台-V2.0 版本
应用层的性能被我们拉上来了,但数据库的负载也在逐渐增大,那如何去提高数据库层面的性能呢?
在实际的生产环境中, 数据的读写操作如果都在同一个数据库服务器中进行, 当遇到大量的并发读或者写操作的时候,是没有办法满足实际需求的,数据库的吞吐量将面临巨大的瓶颈压力.
- 数据库主从复制、读写分离
-
主从复制
通过搭建主从架构, 将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
-
读写分离
读写分离就是让主库处理事务性操作,从库处理select查询。数据库复制被用来把事务性查询导致的数据变更同步到从库,同时主库也可以select查询.
读写分离的数据节点中的数据内容是一致。
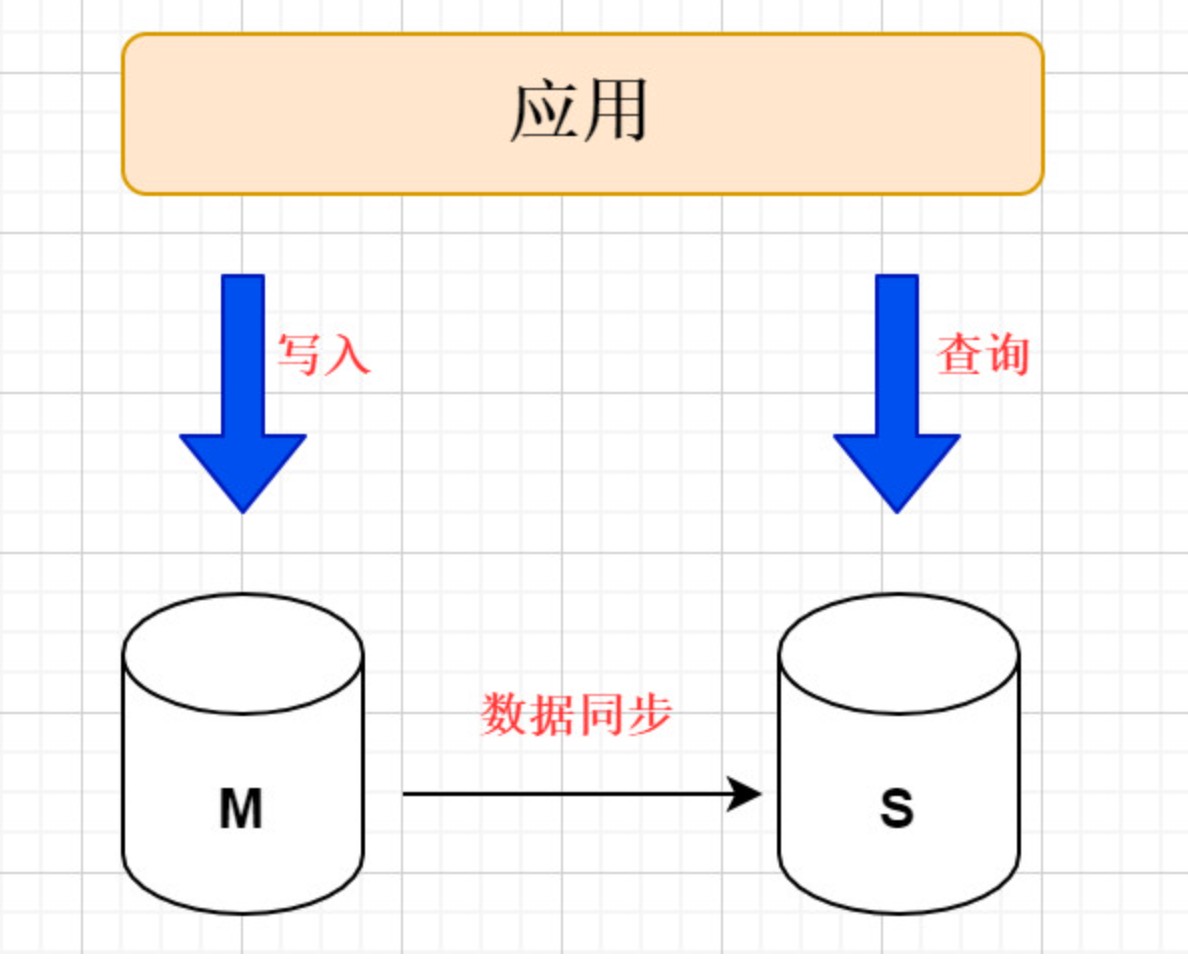
使用主从复制+读写分离一定程度上可以解决问题,但是用户超级多的时候,比如几个亿用户,此时写操作会越来越多,一个主库(Master)不能满足要求了,那就把主库拆分,这时候为了保证数据的一致性就要开始进行同步,此时会带来一系列问题:
(1)写操作拓展起来比较困难,因为要保证多个主库的数据一致性。
(2)复制延时:意思是同步带来的时间消耗。
(3)锁表率上升:读写分离,命中率少,锁表的概率提升。
(4)表变大,缓存率下降:此时缓存率一旦下降,带来的就是时间上的消耗。
主从复制架构随着用户量的增加、访问量的增加、数据量的增加依然会带来大量的问题.
1.2.4 理财平台-V2.x 版本
然后又随着访问量的持续不断增加,慢慢的我们的系统项目会出现许多用户访问同一内容的情况,比如秒杀活动,抢购活动等。
那么对于这些热点数据的访问,没必要每次都从数据库重读取,这时我们可以使用到缓存技术,比如 redis、memcache 来作为我们应用层的缓存。
- 数据库主从复制、读写分离 +缓存技术
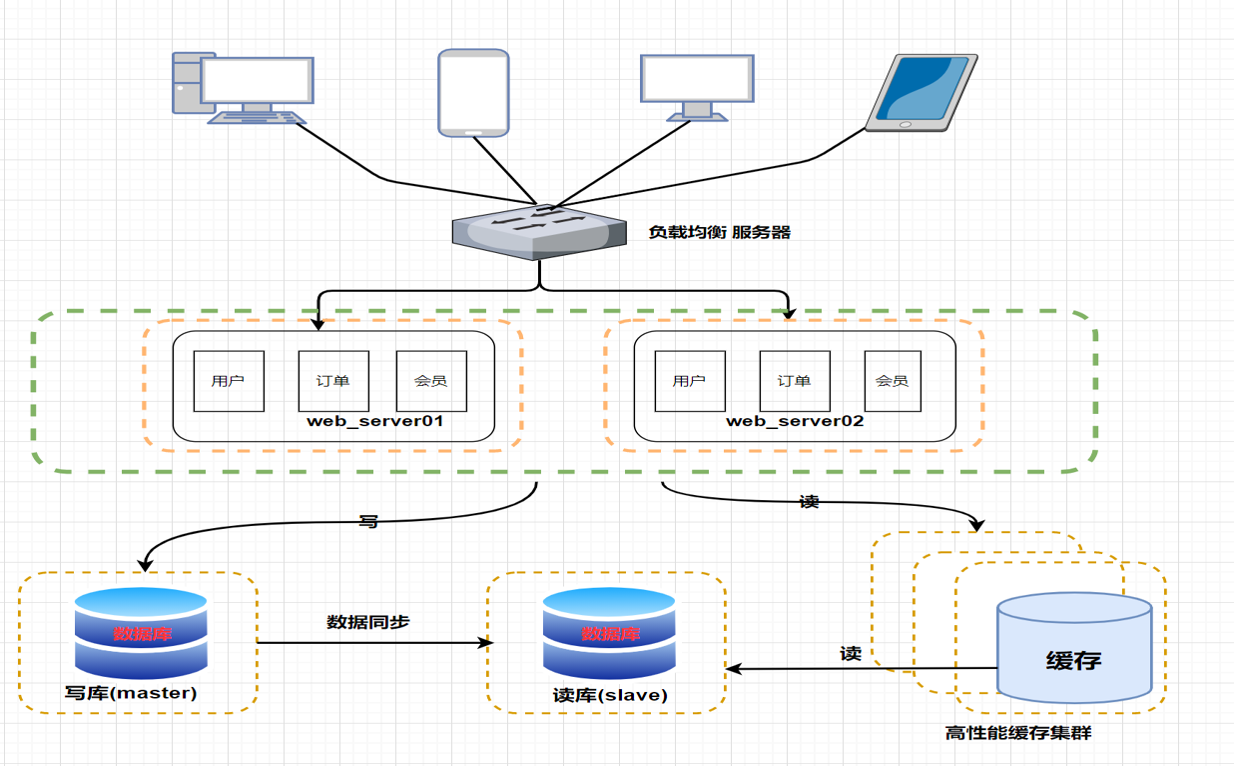
存在的问题
-
缓存只能缓解读取压力,数据库的写入压力还是很大
-
且随着数据量的继续增大,性能还是很缓慢
我们的系统架构从单机演变到这个阶,所有的数据都还在同一个数据库中,尽管采取了增加缓存,主从、读写分离的方式,但是随着数据库的压力持续增加,数据库的瓶颈仍然是个最大的问题。因此我们可以考虑对数据的垂直拆分和水平拆分。就是今天所讲的主题,分库分表。
1.5 分库分表
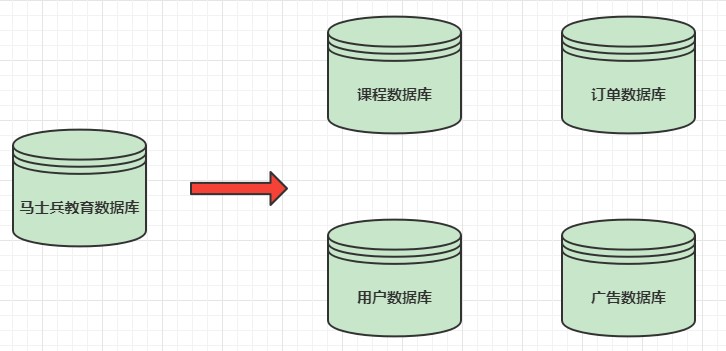
1.5.1 什么是分库分表
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
-
分库分表解决的问题
分库分表的目的是为了解决由于数据量过大而导致数据库性能降低的问题,将原来单体服务的数据库进行拆分.将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
-
什么情况下需要分库分表
- 单机存储容量遇到瓶颈.
- 连接数,处理能力达到上限.
注意:
分库分表之前,要根据项目的实际情况 确定我们的数据量是不是够大,并发量是不是够大,来决定是否分库分表.
数据量不够就不要分表,单表数据量超过1000万或100G的时候, 速度就会变慢(官方测试),
1.5.2 分库分表的方式
分库分表包括: 垂直分库、垂直分表、水平分库、水平分表 四种方式。
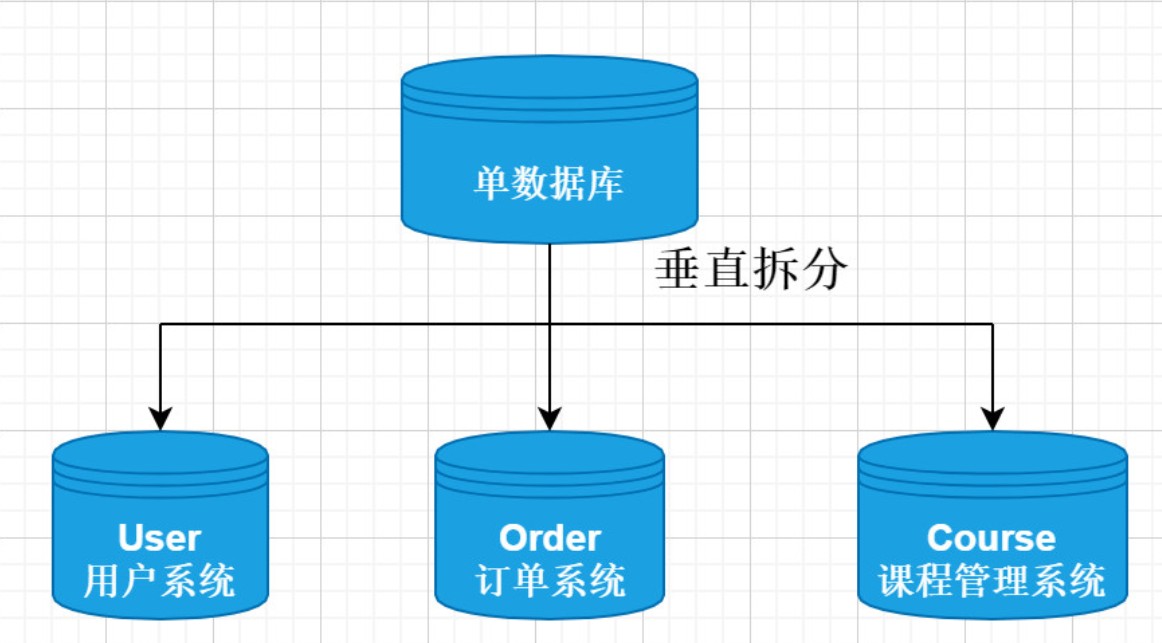
1.5.2.1 垂直分库
- 数据库中不同的表对应着不同的业务,垂直切分是指按照业务的不同将表进行分类,分布到不同的数据库上面
- 将数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果
1.5.2.2 垂直分表
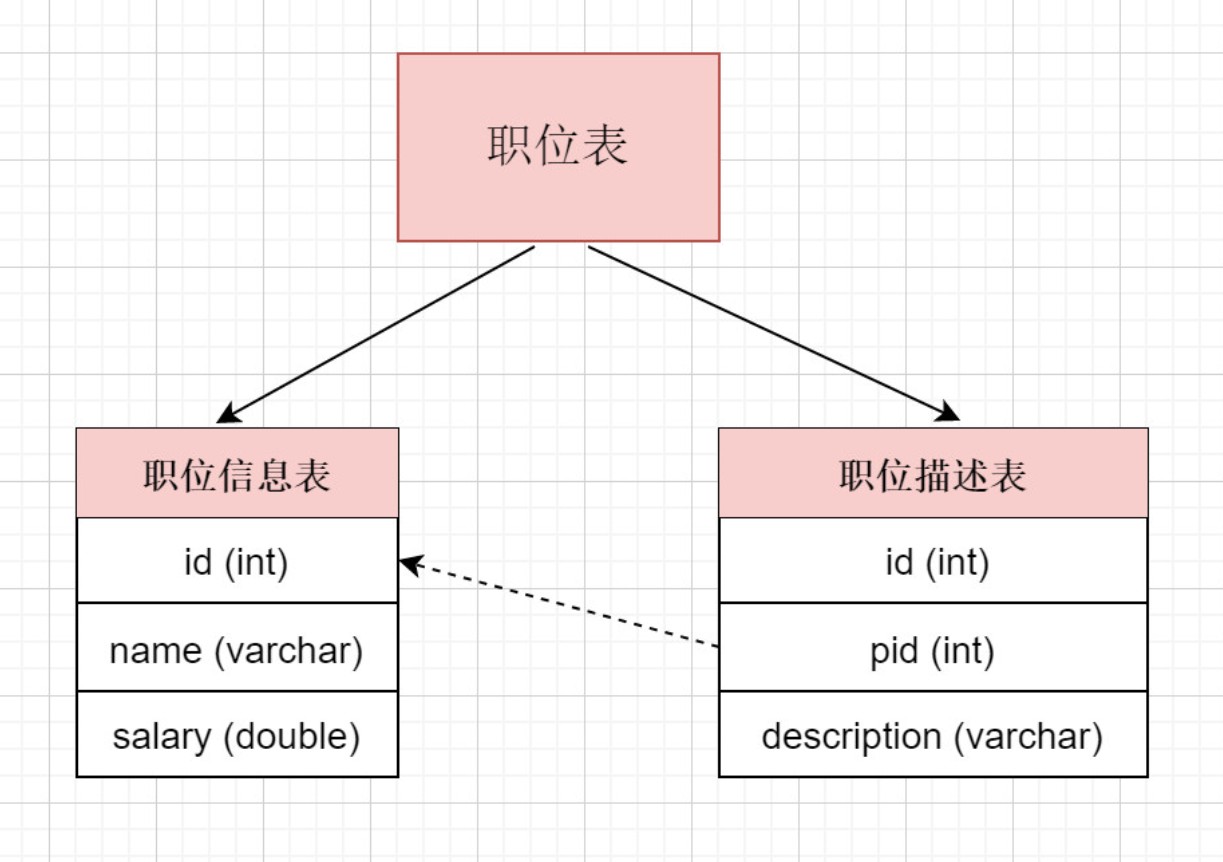
表中字段太多且包含大字段的时候,在查询时对数据库的IO、内存会受到影响,同时更新数据时,产生的binlog文件会很大,MySQL在主从同步时也会有延迟的风险
- 将一个表按照字段分成多表,每个表存储其中一部分字段。
- 对职位表进行垂直拆分, 将职位基本信息放在一张表, 将职位描述信息存放在另一张表
- 垂直拆分带来的一些提升
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提高访问性能
- 垂直拆分没有彻底解决单表数据量过大的问题
1.5.2.3 水平分库
-
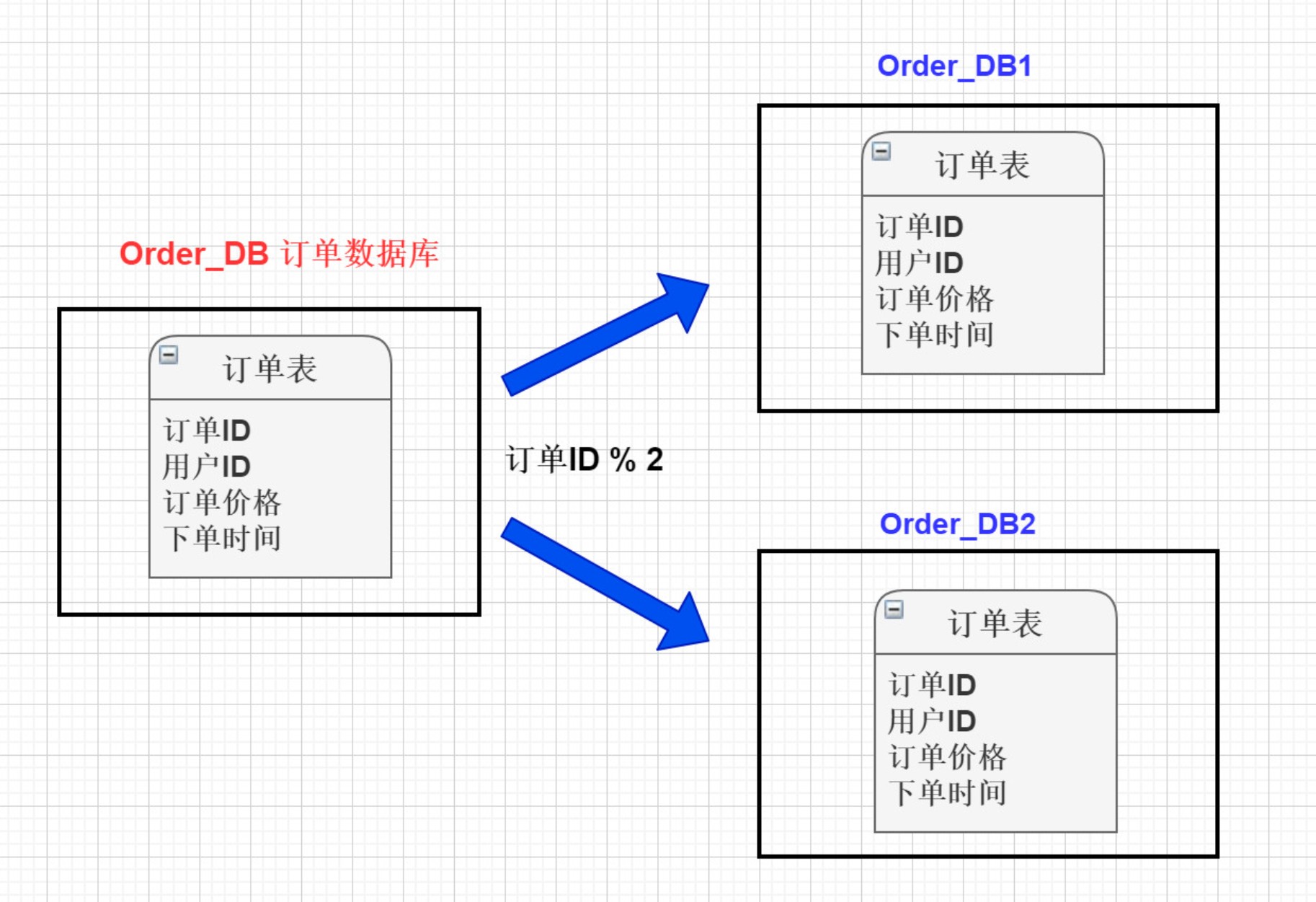
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈.
-
简单讲就是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面, 例如将订单表 按照id是奇数还是偶数, 分别存储在不同的库中。
1.5.2.4 水平分表
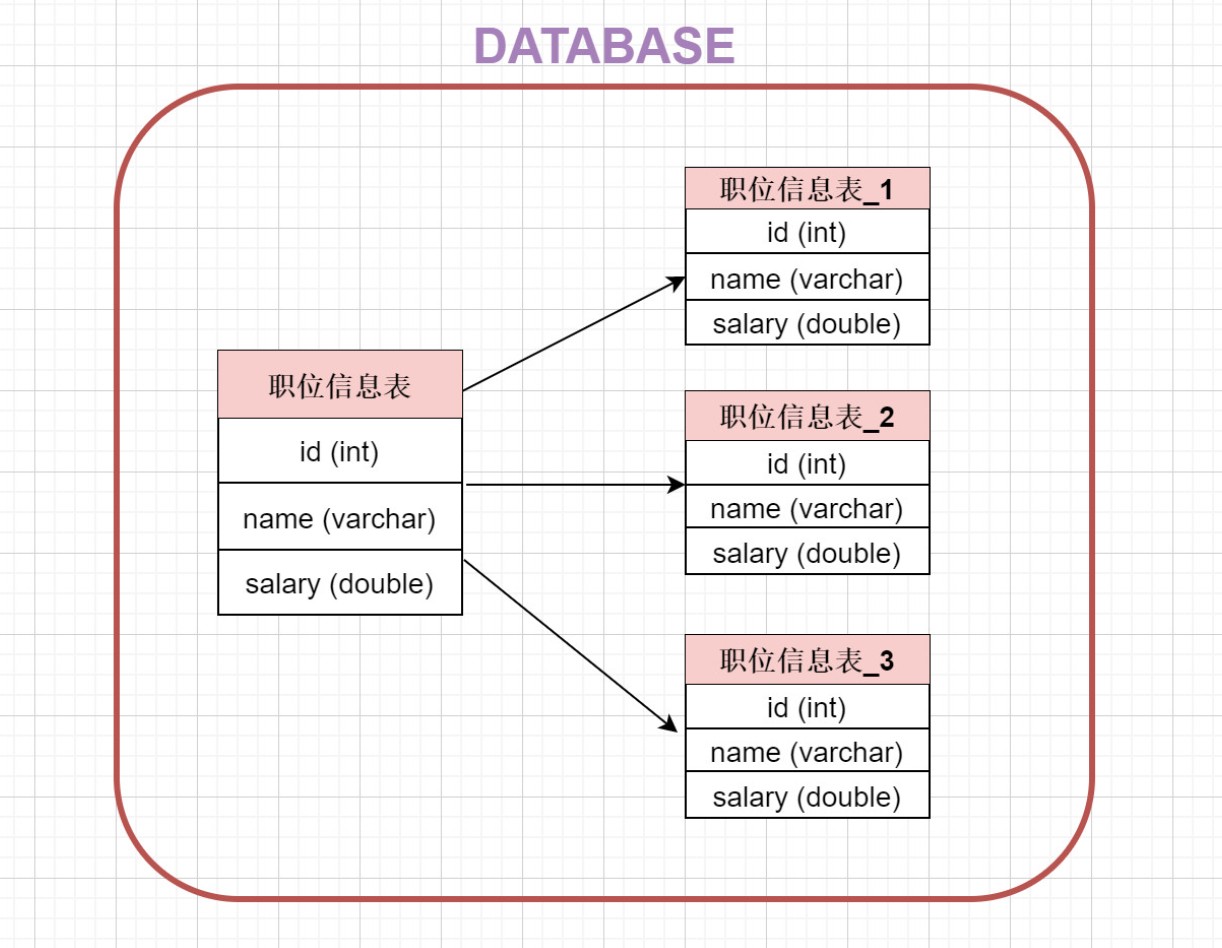
- 针对数据量巨大的单张表(比如订单表),按照规则把一张表的数据切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。
- 总结
- 垂直分表: 将一个表按照字段分成多表,每个表存储其中一部分字段。
- 垂直分库: 根据表的业务不同,分别存放在不同的库中,这些库分别部署在不同的服务器.
- 水平分库: 把一张表的数据按照一定规则,分配到不同的数据库,每一个库只有这张表的部分数据.
- 水平分表: 把一张表的数据按照一定规则,分配到同一个数据库的多张表中,每个表只有这个表的部分数据.
1.5.3 分库分表的规则
1) 水平分库规则
-
不跨库、不跨表,保证同一类的数据都在同一个服务器上面。
-
数据在切分之前,需要考虑如何高效的进行数据获取,如果每次查询都要跨越多个节点,就需要谨慎使用。
2) 水平分表规则
-
RANGE
- 时间:按照年、月、日去切分。例如order_2020、order_202005、order_20200501
- 地域:按照省或市去切分。例如order_beijing、order_shanghai、order_chengdu
- 大小:从0到1000000一个表。例如1000001-2000000放一个表,每100万放一个表
-
HASH
- 用户ID取模
3) 不同的业务使用的切分规则是不一样,就上面提到的切分规则,举例如下:
-
用户表
-
范围法:以用户ID为划分依据,将数据水平切分到两个数据库实例,如:1到1000W在一张表,1000W到2000W在一张表,这种情况会出现单表的负载较高
-
按照用户ID HASH尽量保证用户数据均衡分到数据库中
如果在登录场景下,用户输入手机号和验证码进行登录,这种情况下,登录时是不是需要扫描所有分库的信息?
最终方案:用户信息采用ID做切分处理,同时存储用户ID和手机号的映射的关系表(新增一个关系表),关系表采用手机号进行切分。可以通过关系表根据手机号查询到对应的ID,再定位用户信息。
-
-
流水表
- 时间维度:可以根据每天新增的流水来判断,选择按照年份分库,还是按照月份分库,甚至也可以按照日期分库
1.5.4 分库分表带来的问题及解决方案
关系型数据库在单机单库的情况下,比较容易出现性能瓶颈问题,分库分表可以有效的解决这方面的问题,但是同时也会产生一些 比较棘手的问题.
1) 事务一致性问题
- 当我们需要更新的内容同时分布在不同的库时, 不可避免的会产生跨库的事务问题. 原来在一个数据库操作, 本地事务就可以进行控制, 分库之后 一个请求可能要访问多个数据库,如何保证事务的一致性,目前还没有简单的解决方案.
2) 跨节点关联的问题
- 在分库之后, 原来在一个库中的一些表,被分散到多个库,并且这些数据库可能还不在一台服务器,无法关联查询.解决这种关联查询,需要我们在代码层面进行控制,将关联查询拆开执行,然后再将获取到的结果进行拼装.
3) 分页排序查询的问题
- 分库并行查询时,如果用到了分页 每个库返回的结果集本身是无序的, 只有将多个库中的数据先查出来,然后再根据排序字段在内存中进行排序,如果查询结果过大也是十分消耗资源的.
4) 主键避重问题
- 在分库分表的环境中,表中的数据存储在不同的数据库, 主键自增无法保证ID不重复, 需要单独设计全局主键.
5) 公共表的问题
- 不同的数据库,都需要从公共表中获取数据. 某一个数据库更新看公共表其他数据库的公共表数据需要进行同步.
上面我们说了分库分表后可能会遇到的一些问题, 接下来带着这些问题,我们就来一起来学习一下Apache ShardingSphere !
2.ShardingSphere实战
2.1 什么是ShardingSphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
官网: https://shardingsphere.apache.org/document/current/cn/overview/

Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。

Apache ShardingSphere它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
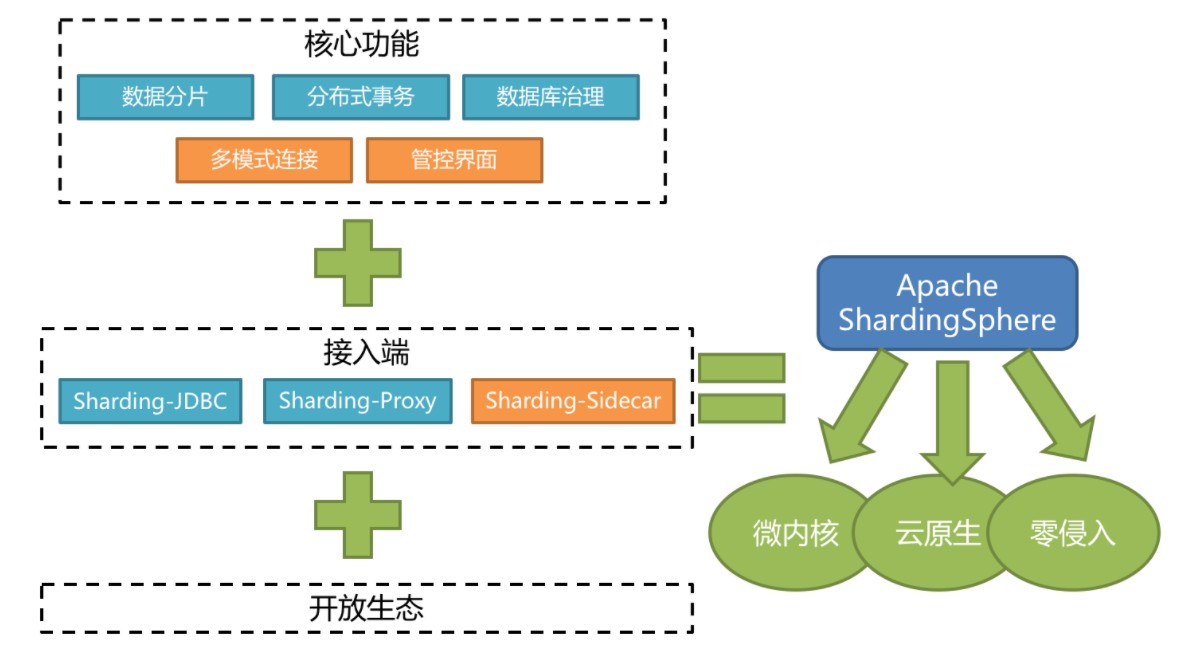
-
Sharding-JDBC:被定位为轻量级Java框架,在Java的JDBC层提供的额外服务,以jar包形式使用。
-
Sharding-Proxy:被定位为透明化的数据库代理端,向应用程序完全透明,可直接当做 MySQL 使用;
-
Sharding-Sidecar:被定位为Kubernetes(K8S)的云原生数据库代理,以守护进程的形式代理所有对数据库的访问(只是计划在未来做)。
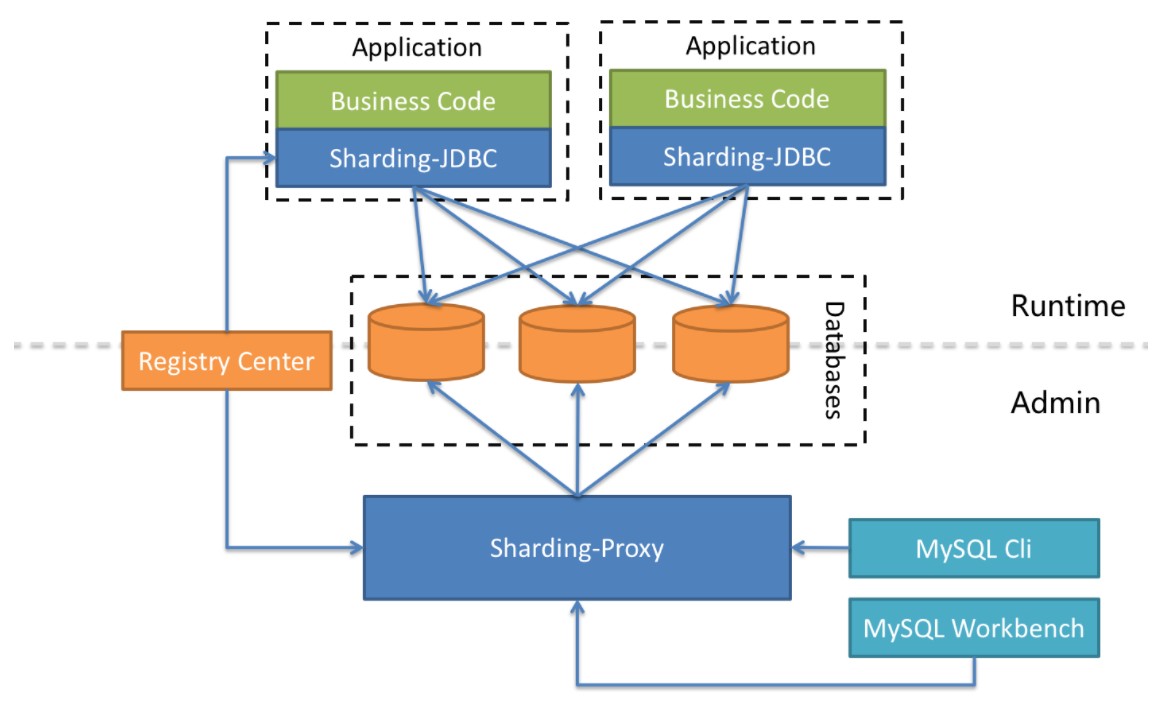
Sharding-JDBC、Sharding-Proxy之间的区别如下:
| Sharding-JDBC | Sharding-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
异构是继面向对象编程思想又一种较新的编程思想,面向服务编程,不用顾虑语言的差别,提供规范的服务接口,我们无论使用什么语言,就都可以访问使用了,大大提高了程序的复用率。
Sharding-Proxy的优势在于对异构语言的支持,以及为DBA提供可操作入口。它可以屏蔽底层分库分表的复杂度,运维及开发人员仅面向proxy操作,像操作单个数据库一样操作复杂的底层MySQL实例
很显然ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均有业务方自己控制,所以他的功能相对灵活,支持的 数据库也非常多,但是对业务侵入大,需要业务方自己定义所有的分库分表逻辑.
而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少,两者各有优劣.
ShardingSphere项目状态如下:
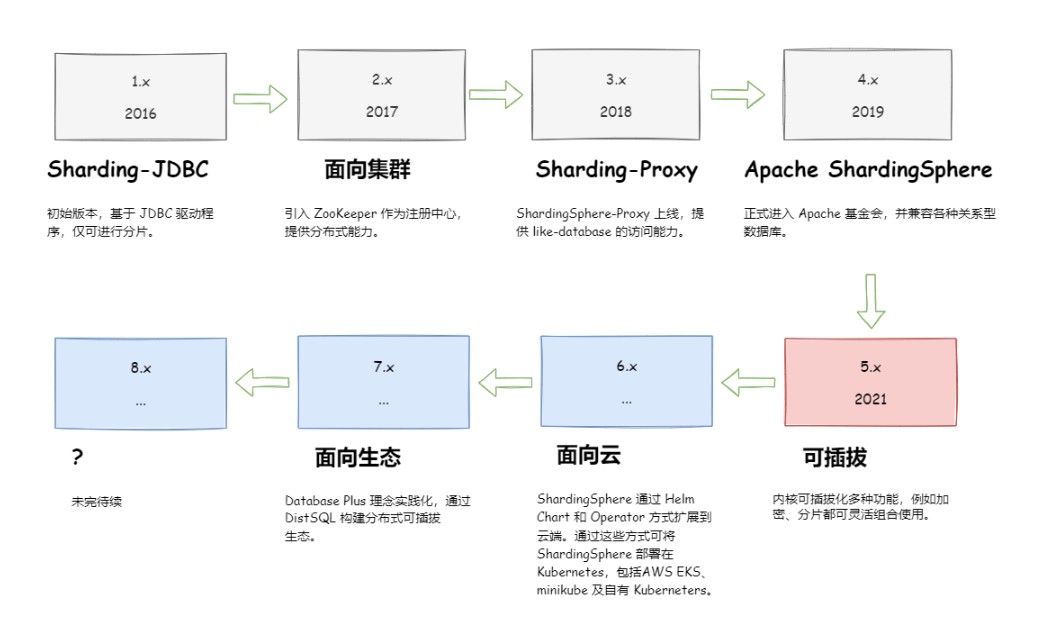
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
2.2 Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架的使用。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-JDBC主要功能:
- 数据分片
- 分库、分表
- 读写分离
- 分片策略
- 分布式主键
- 分布式事务
- 标准化的事务接口
- XA强一致性事务
- 柔性事务
- 数据库治理
- 配置动态化
- 编排和治理
- 数据脱敏
- 可视化链路追踪
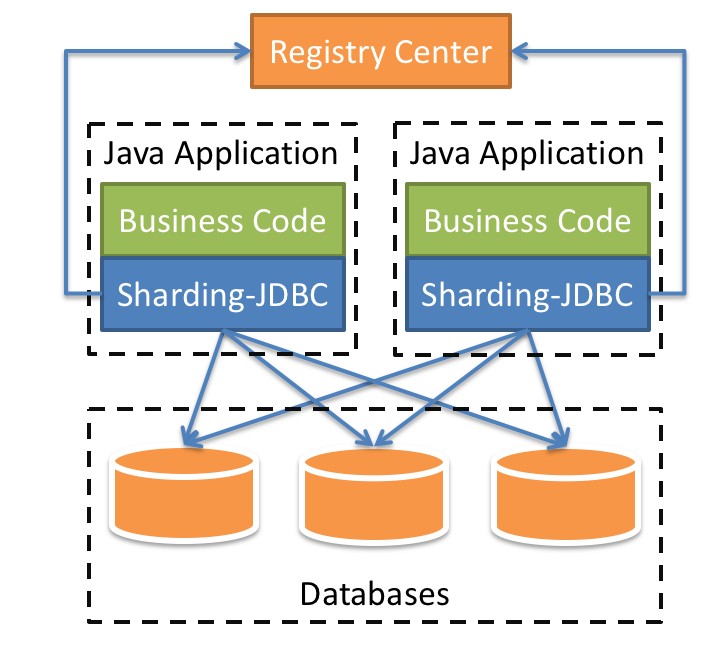
Sharding-JDBC 内部结构:

- 图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有ShardingDataSourceFactory和MasterSlaveDataSourceFactory两个工厂类。
- ShardingDataSourceFactory支持分库分表、读写分离操作
- MasterSlaveDataSourceFactory支持读写分离操作
- 图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多变的配置方式。 ShardingRuleConfiguration是分库分表配置的核心和入口,它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。
- TableRuleConfiguration封装的是表的分片配置信息,有5种配置形式对应不同的Configuration类型。
- MasterSlaveRuleConfiguration封装的是读写分离配置信息。
- 图中红色部分表示的是内部对象,由Sharding-JDBC内部使用,应用开发者无需关注。Sharding-JDBC通过ShardingRuleConfiguration和MasterSlaveRuleConfiguration生成真正供ShardingDataSource和MasterSlaveDataSource使用的规则对象。ShardingDataSource和MasterSlaveDataSource实现了DataSource接口,是JDBC的完整实现方案。
2.3 数据分片详解与实战
2.3.1 核心概念

对于数据库的垂直拆分一般都是在数据库设计初期就会完成,因为垂直拆分与业务直接相关,而我们提到的分库分表一般是指的水平拆分,数据分片就是将原本一张数据量较大的表t_order拆分生成数个表结构完全一致的小数据量表t_order_0、t_order_1…,每张表只保存原表的部分数据.
2.3.1.1 表概念
-
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
-
真实表
数据库中真实存在的物理表。例如: t_order0、t_order1
-
数据节点
在分片之后,由数据源和数据表组成。例如:t_order_db1.t_order_0
-
绑定表
指的是分片规则一致的关系表(主表、子表),例如t_order和t_order_item,均按照order_id分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,可以提升关联查询效率。
# t_order:t_order0、t_order1 # t_order_item:t_order_item0、t_order_item1select * from t_order o join t_order_item i on(o.order_id=i.order_id) where o.order_id in (10,11);由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
select * from t_order0 o join t_order_item0 i on o.order_id=i.order_id where o.order_id in (10,11);select * from t_order0 o join t_order_item1 i on o.order_id=i.order_id where o.order_id in (10,11);select * from t_order1 o join t_order_item0 i on o.order_id=i.order_id where o.order_id in (10,11);select * from t_order1 o join t_order_item1 i on o.order_id=i.order_id where o.order_id in (10,11);

如果配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0和 t_order_item_0 表关联即可。
select * from b_order0 o join b_order_item0 i on(o.order_id=i.order_id)
where o.order_id in (10,11);select * from b_order1 o join b_order_item1 i on(o.order_id=i.order_id)
where o.order_id in (10,11);

注意:在关联查询时 t_order 它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item 表的分片相关的计算也会使用 t_order 的条件,所以要保证绑定表之间的分片键要完全相同,当保证这些一样之后,根据sql去查询时会统一的路由到0表或者1表,自然就没有笛卡尔积问题了。
-
广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数据完全相同。
-
单表
指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。
2.3.1.2 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。
例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由(去查询所有的真实表),性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
2.3.1.3 分片算法
由于分片算法(ShardingAlgorithm) 和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。目前提供4种分片算法。
-
精确分片算法
用于处理使用单一键作为分片键的=与IN进行分片的场景。
-
范围分片算法
用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。
-
复合分片算法
用于处理使用多键作为分片键进行分片的场景,多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
Hint分片算法
用于处理使用Hint行分片的场景。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释两种方式使用。
2.3.1.4 分片策略
分片策略(ShardingStrategy) 包含分片键和分片算法,真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
-
标准分片策略 StandardShardingStrategy
只支持单分片键,提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
PreciseShardingAlgorithm是必选的,RangeShardingAlgorithm是可选的。但是SQL中使用了范围操作,如果不配置RangeShardingAlgorithm会采用全库路由扫描,效率低。
-
复合分片策略 ComplexShardingStrategy
支持多分片键。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
-
行表达式分片策略 InlineShardingStrategy
只支持单分片键。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发。如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
-
Hint分片策略HintShardingStrategy
通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
-
不分片策略NoneShardingStrategy
不分片的策略。
分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度,两种策略的API完全相同。
-
数据源分片策略
用于配置数据被分配的目标数据源。
-
表分片策略
用于配置数据被分配的目标表,由于表存在与数据源内,所以表分片策略是依赖数据源分片策略结果的。
2.3.1.5 分布式主键
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题,同一个逻辑表(t_order)内的不同真实表(t_order_n)之间的自增键由于无法互相感知而产生重复主键。
尽管可通过设置自增主键初始值和步长的方式避免ID碰撞,但这样会使维护成本加大,缺乏完整性和可扩展性。如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
内置主键生成器:
-
UUID
采用UUID.randomUUID()的方式产生分布式主键。
-
SNOWFLAKE
在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法,生成64bit的长整型数据。
自定义主键生成器:
-
自定义主键类,实现ShardingKeyGenerator接口
-
按SPI规范配置自定义主键类
在Apache ShardingSphere中,很多功能实现类的加载方式是通过SPI注入的方式完成的。 注意:在resources目录下新建META-INF文件夹,再新建services文件夹,然后新建文件的名字为org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,打开文件,复制自定义主键类全路径到文件中保存。 -
自定义主键类应用配置
#对应主键字段名 spring.shardingsphere.sharding.tables.t_book.key-generator.column=id #对应主键类getType返回内容 spring.shardingsphere.sharding.tables.t_book.key-generator.type=LAGOUKEY
2.3.2 搭建基础环境
2.3.2.1 安装环境
-
jdk: 要求jdk必须是1.8版本及以上
-
MySQL: 推荐mysql5.7版本
-
搭建两台MySQL服务器
mysql-server1 192.168.52.10 mysql-server2 192.168.52.11
2.3.2.2 创建数据库和表

- 在mysql01服务器上, 创建数据库 msb_payorder_db,并创建表pay_order
CREATE DATABASE msb_payorder_db CHARACTER SET 'utf8';CREATE TABLE `pay_order` (`order_id` bigint(20) NOT NULL AUTO_INCREMENT,`user_id` int(11) DEFAULT NULL,`product_name` varchar(128) DEFAULT NULL,`COUNT` int(11) DEFAULT NULL,PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=12345679 DEFAULT CHARSET=utf8
- 在mysql02服务器上, 创建数据库 msb_user_db,并创建表users
CREATE DATABASE msb_user_db CHARACTER SET 'utf8';CREATE TABLE `users` (`id` int(11) NOT NULL,`username` varchar(255) NOT NULL COMMENT '用户昵称',`phone` varchar(255) NOT NULL COMMENT '注册手机',`PASSWORD` varchar(255) DEFAULT NULL COMMENT '用户密码',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表'2.3.2.3 创建SpringBoot程序
环境说明:
SpringBoot2.3.7+MyBatisPlus+ShardingSphere-JDBC 5.1+Hikari+MySQL 5.7
1) 创建项目
项目名称: shardingjdbc-table
Spring脚手架: http://start.aliyun.com
2) 引入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.1.1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies>
3) 创建实体类
@TableName("pay_order") //逻辑表名
@Data
@ToString
public class PayOrder {@TableIdprivate long order_id;private long user_id;private String product_name;private int count;}@TableName("users")
@Data
@ToString
public class User {@TableIdprivate long id;private String username;private String phone;private String password;}
4) 创建Mapper
@Mapper
public interface PayOrderMapper extends BaseMapper<PayOrder> {
}@Mapper
public interface UserMapper extends BaseMapper<User> {
}
2.3.3 实现垂直分库
2.3.3.1 配置文件
使用sharding-jdbc 对数据库中水平拆分的表进行操作,通过sharding-jdbc对分库分表的规则进行配置,配置内容包括:数据源、主键生成策略、分片策略等。
application.properties
-
基础配置
# 应用名称 spring.application.name=sharding-jdbc -
数据源
# 定义多个数据源 spring.shardingsphere.datasource.names = db1,db2#数据源1 spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.52.10:3306/msb_payorder_db?characterEncoding=UTF-8&useSSL=false spring.shardingsphere.datasource.db1.username = root spring.shardingsphere.datasource.db1.password = QiDian@666#数据源2 spring.shardingsphere.datasource.db2.type = com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db2.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.db2.url = jdbc:mysql://192.168.52.11:3306/msb_user_db?characterEncoding=UTF-8&useSSL=false spring.shardingsphere.datasource.db2.username = root spring.shardingsphere.datasource.db2.password = QiDian@666 -
配置数据节点
# 标准分片表配置 # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。 spring.shardingsphere.rules.sharding.tables.pay_order.actual-data-nodes=db1.pay_order spring.shardingsphere.rules.sharding.tables.users.actual-data-nodes=db2.users -
打开sql输出日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
2.3.3.2 垂直分库测试
@SpringBootTest
class ShardingJdbcApplicationTests {@Autowiredprivate UserMapper userMapper;@Autowiredprivate PayOrderMapper payOrderMapper;@Testpublic void testInsert(){User user = new User();user.setId(1002);user.setUsername("大远哥");user.setPhone("15612344321");user.setPassword("123456");userMapper.insert(user);PayOrder payOrder = new PayOrder();payOrder.setOrder_id(12345679);payOrder.setProduct_name("猕猴桃");payOrder.setUser_id(user.getId());payOrder.setCount(2);payOrderMapper.insert(payOrder);}@Testpublic void testSelect(){User user = userMapper.selectById(1001);System.out.println(user);PayOrder payOrder = payOrderMapper.selectById(12345678);System.out.println(payOrder);}}
2.3.4 实现水平分表
2.3.4.1 数据准备

需求说明:
- 在mysql-server01服务器上, 创建数据库 msb_course_db
- 创建表 t_course_1 、 t_course_2
- 约定规则:如果添加的课程 id 为偶数添加到 t_course_1 中,奇数添加到 t_course_2 中。
水平分片的id需要在业务层实现,不能依赖数据库的主键自增
CREATE TABLE t_course_1 (`cid` BIGINT(20) NOT NULL,`user_id` BIGINT(20) DEFAULT NULL,`cname` VARCHAR(50) DEFAULT NULL,`brief` VARCHAR(50) DEFAULT NULL,`price` DOUBLE DEFAULT NULL,`status` INT(11) DEFAULT NULL,PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8CREATE TABLE t_course_2 (`cid` BIGINT(20) NOT NULL,`user_id` BIGINT(20) DEFAULT NULL,`cname` VARCHAR(50) DEFAULT NULL,`brief` VARCHAR(50) DEFAULT NULL,`price` DOUBLE DEFAULT NULL,`status` INT(11) DEFAULT NULL,PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
2.3.4.2 配置文件
1) 基础配置
# 应用名称
spring.application.name=sharding-jdbc
# 打印SQl
spring.shardingsphere.props.sql-show=true
2) 数据源配置
#===============数据源配置
#配置真实的数据源
spring.shardingsphere.datasource.names=db1#数据源1
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://192.168.52.10:3306/msb_course_db?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=QiDian@666
3) 数据节点配置
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}
2.3.4.3 测试
- course类
@TableName("t_course")
@Data
@ToString
public class Course implements Serializable {@TableIdprivate Long cid;private Long userId;private String cname;private String brief;private double price;private int status;
}
- CourseMapper
@Mapper
public interface CourseMapper extends BaseMapper<Course> {
}
- 测试:保留上面配置中的一个分片表节点分别进行测试,检查每个分片节点是否可用
# 测试t_course_1表插入
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_1
# 测试t_course_2表插入
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_2
//水平分表测试@Autowiredprivate CourseMapper courseMapper;@Testpublic void testInsertCourse(){for (int i = 0; i < 3; i++) {Course course = new Course();course.setCid(10086+i);course.setUserId(1L+i);course.setCname("Java经典面试题讲解");course.setBrief("课程涵盖目前最容易被问到的10000道Java面试题");course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}
2.3.4.4 行表达式
对上面的配置操作进行修改, 使用inline表达式,灵活配置数据节点
行表达式的使用: https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/inline-expression/)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}
表达式 db1.t_course_$->{1..2}
$ 会被 大括号中的 {1..2} 所替换, ${begin..end} 表示范围区间
会有两种选择: db1.t_course_1 和 db1.t_course_2
2.3.4.5 配置分片算法
分片规则,约定cid值为偶数时,添加到t_course_1表,如果cid是奇数则添加到t_course_2表
- 配置分片算法
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: cid
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_course_$->{cid % 2 + 1}
2.3.4.6 分布式序列算法
雪花算法:
https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/key-generator/
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。
这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
- 基于MyBatisPlus的id策略:将Course类的id设置成如下形式
@TableName("t_course")
@Data
@ToString
public class Course implements Serializable {@TableId(value = "cid",type = IdType.ASSIGN_ID)private Long cid;private Long userId;private String cname;private String brief;private double price;private int status;
}
- 基于ShardingSphere-JDBC的全局序列配置:和前面的MyBatisPlus的策略二选一
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE# 分布式序列算法属性配置,可以先不配置
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=
此时,需要将实体类中的id策略修改成以下形式:
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
@TableId(type = IdType.AUTO)
2.3.5 实现水平分库
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。接下来看一下如何使用Sharding-JDBC实现水平分库
2.3.5.1 数据准备
- 创建数据库
在mysql-server01服务器上, 创建数据库 msb_course_db0, 在mysql-server02服务器上, 创建数据库 msb_course_db1

- 创建表
CREATE TABLE `t_course_0` (`cid` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,`corder_no` bigint(20) DEFAULT NULL,`cname` varchar(50) DEFAULT NULL,`brief` varchar(50) DEFAULT NULL,`price` double DEFAULT NULL,`status` int(11) DEFAULT NULL,PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8CREATE TABLE `t_course_0` (`cid` bigint(20) NOT NULL,`user_id` bigint(20) DEFAULT NULL,`corder_no` bigint(20) DEFAULT NULL,`cname` varchar(50) DEFAULT NULL,`brief` varchar(50) DEFAULT NULL,`price` double DEFAULT NULL,`status` int(11) DEFAULT NULL,PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-
实体类
原有的Course类添加一个
corder_no即可.
@TableName("t_course")
@Data
@ToString
public class Course implements Serializable {// @TableId(value = "cid",type = IdType.ASSIGN_ID)//是否配置sharding-jdbc的分布式序列 ? 是:使用ShardingJDBC的分布式序列,否:自动依赖数据库的主键自增策略@TableId(value = "cid",type = IdType.AUTO)private Long cid;private Long userId;private Long corder_no;private String cname;private String brief;private double price;private int status


![[数据集][目标检测]厨房积水检测数据集VOC+YOLO格式88张2类别](https://img-blog.csdnimg.cn/direct/352bef1e5aea4356a625c493955ade0f.png)


![SpringMVC[从零开始]](https://img-blog.csdnimg.cn/direct/22aa08872ce84232a73fea506c7201b9.png)