3、Job工作机制源码解读
用之前wordcount案例进行源码阅读,debug断点打在Job任务提交时
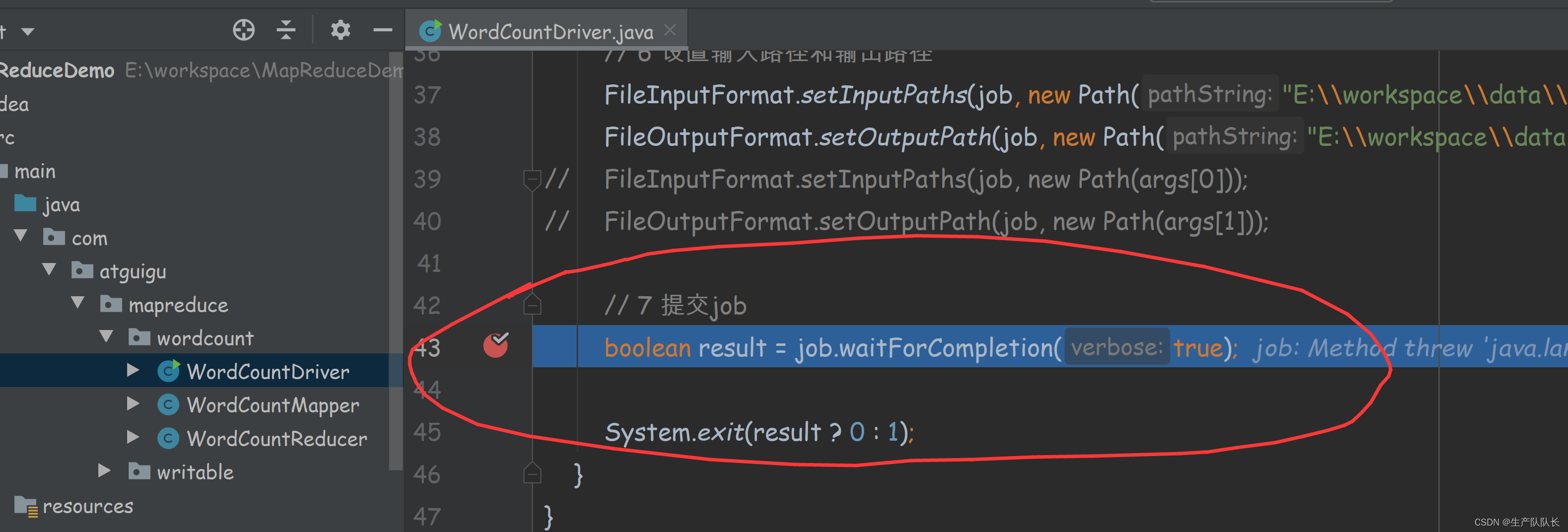
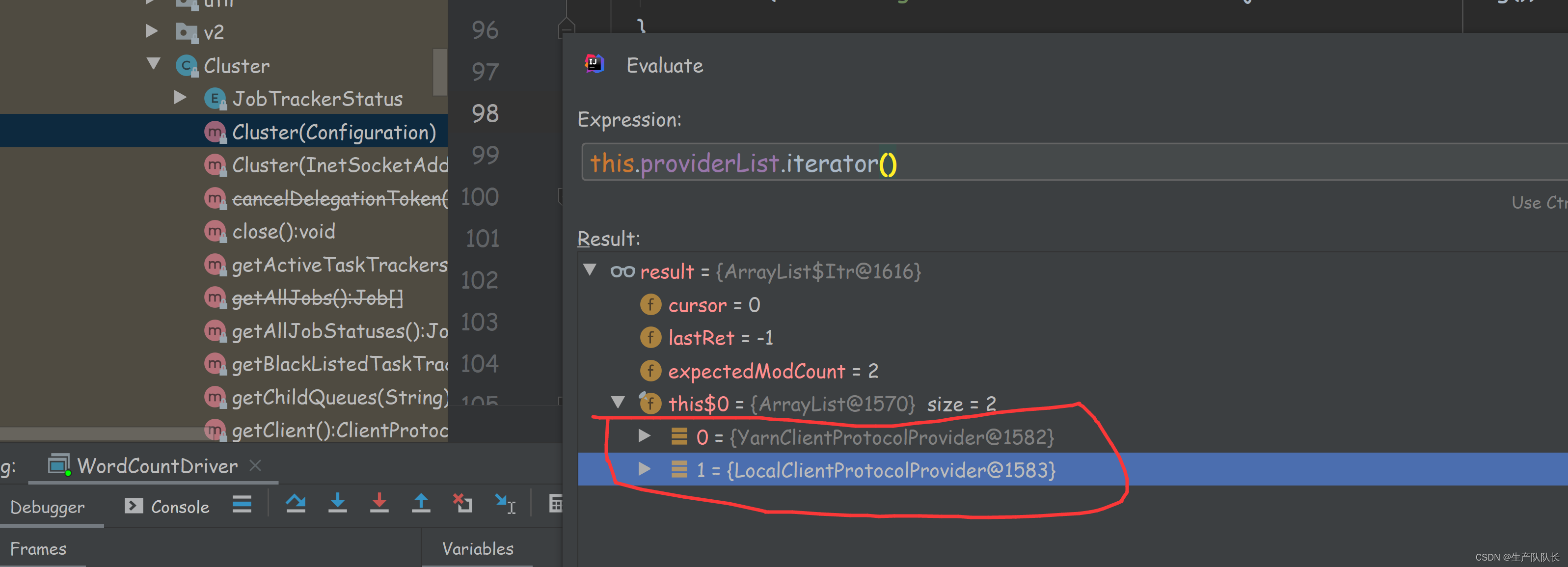
提交任务前,建立客户单连接
如下图,可以看出,只有两个客户端提供者,一个是YarnClient,一个是LocalClient。
显然,我这里是LocalClient模式
检查输出路径是否存在,存在则报错

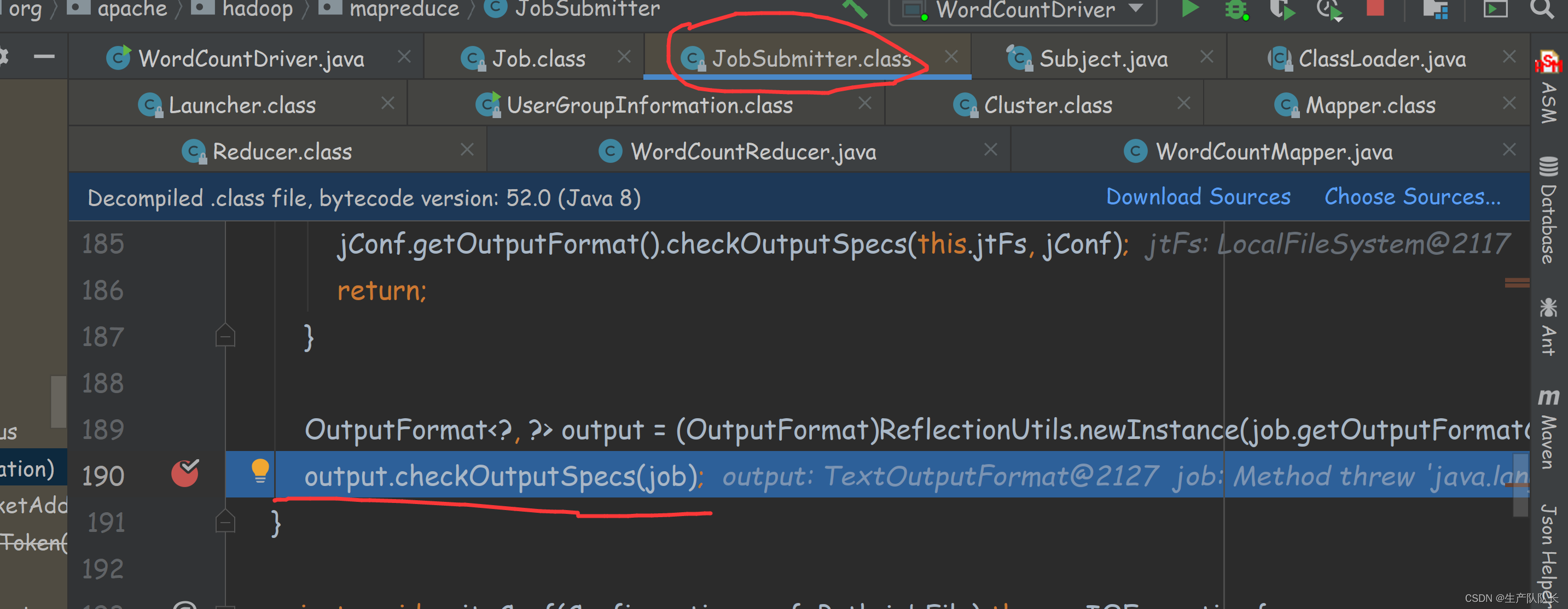
这里的两串提示就很熟悉了,如果输出路径存在,则报错。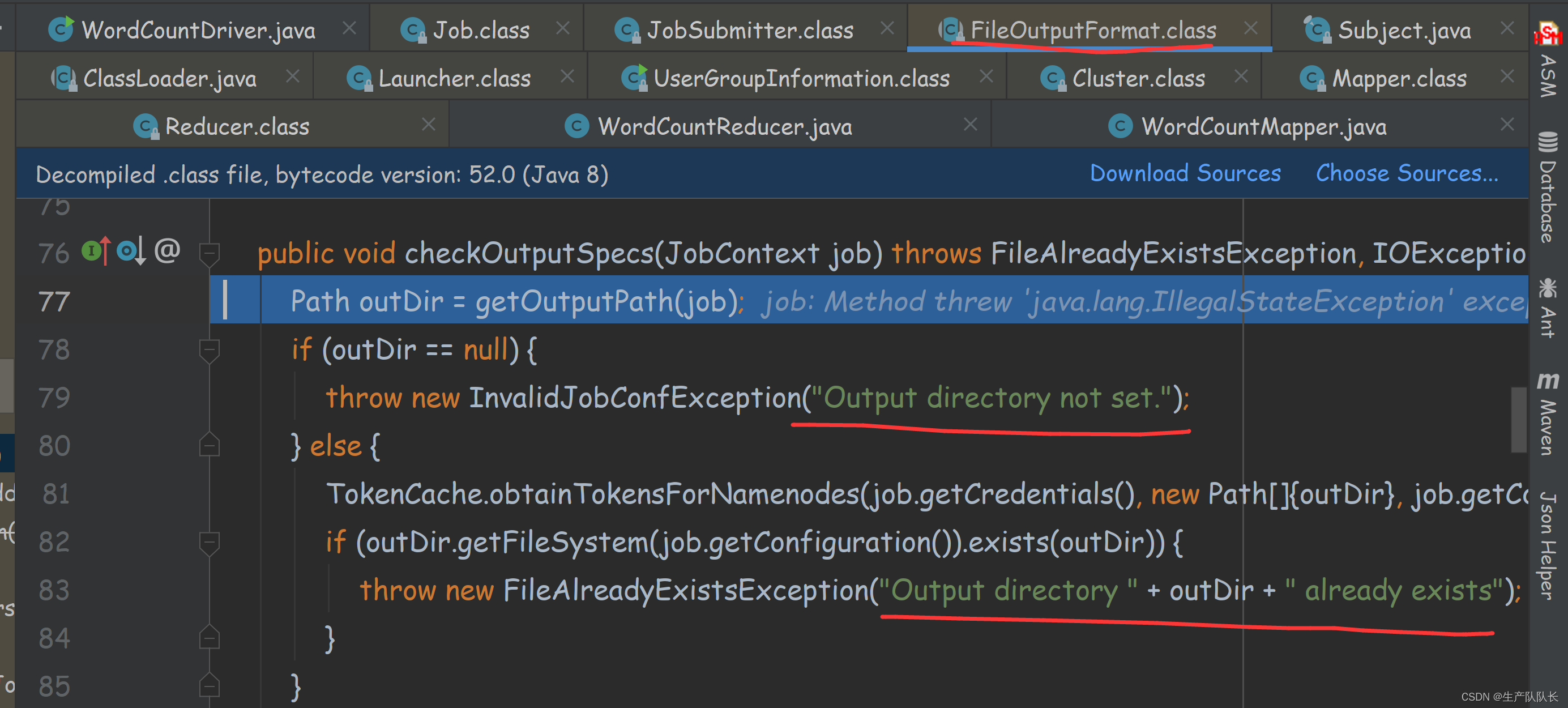
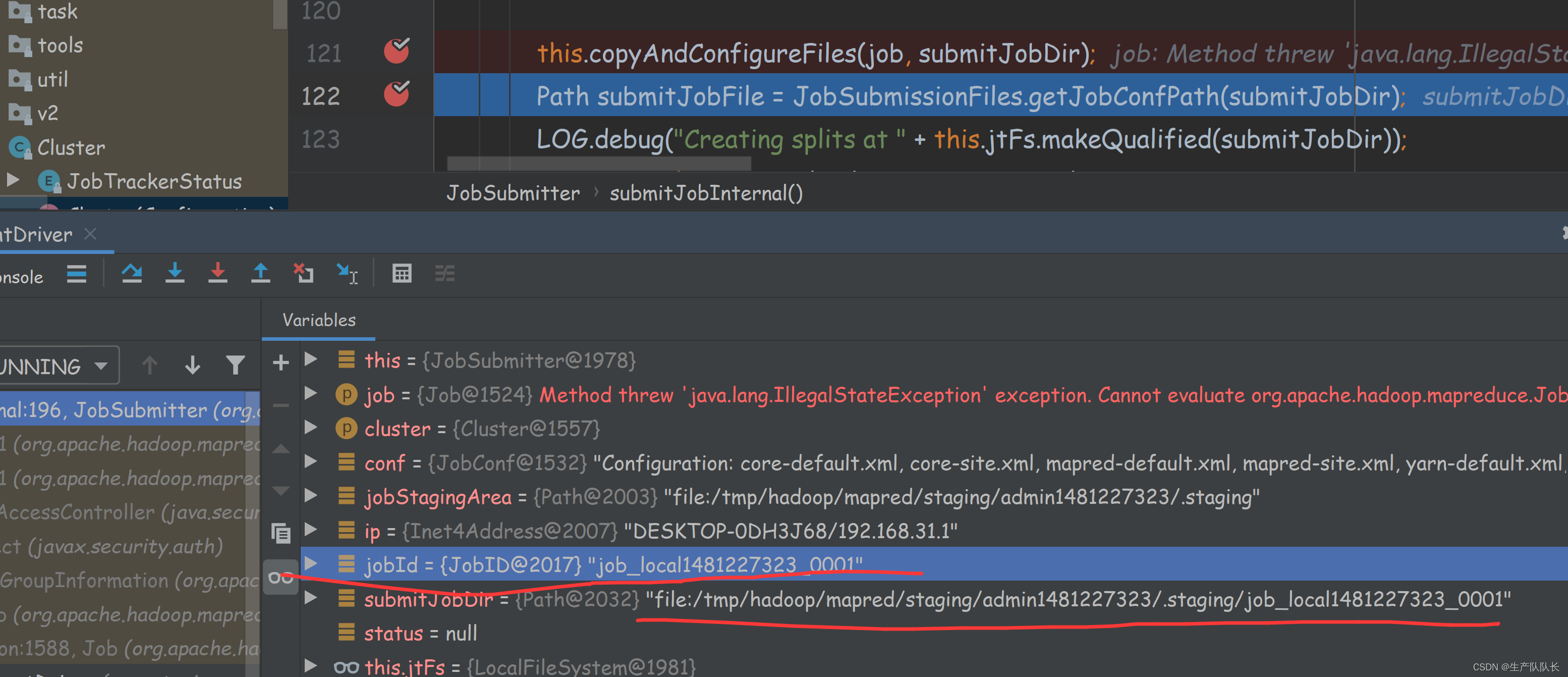
提交任务前会创建一个jobID,并创建相关文件夹,文件夹里存放临时的文件数据,job完成后会删除
切片和MapTask的关系:切片数决定MapTask线程数量
关键日志:number of splits
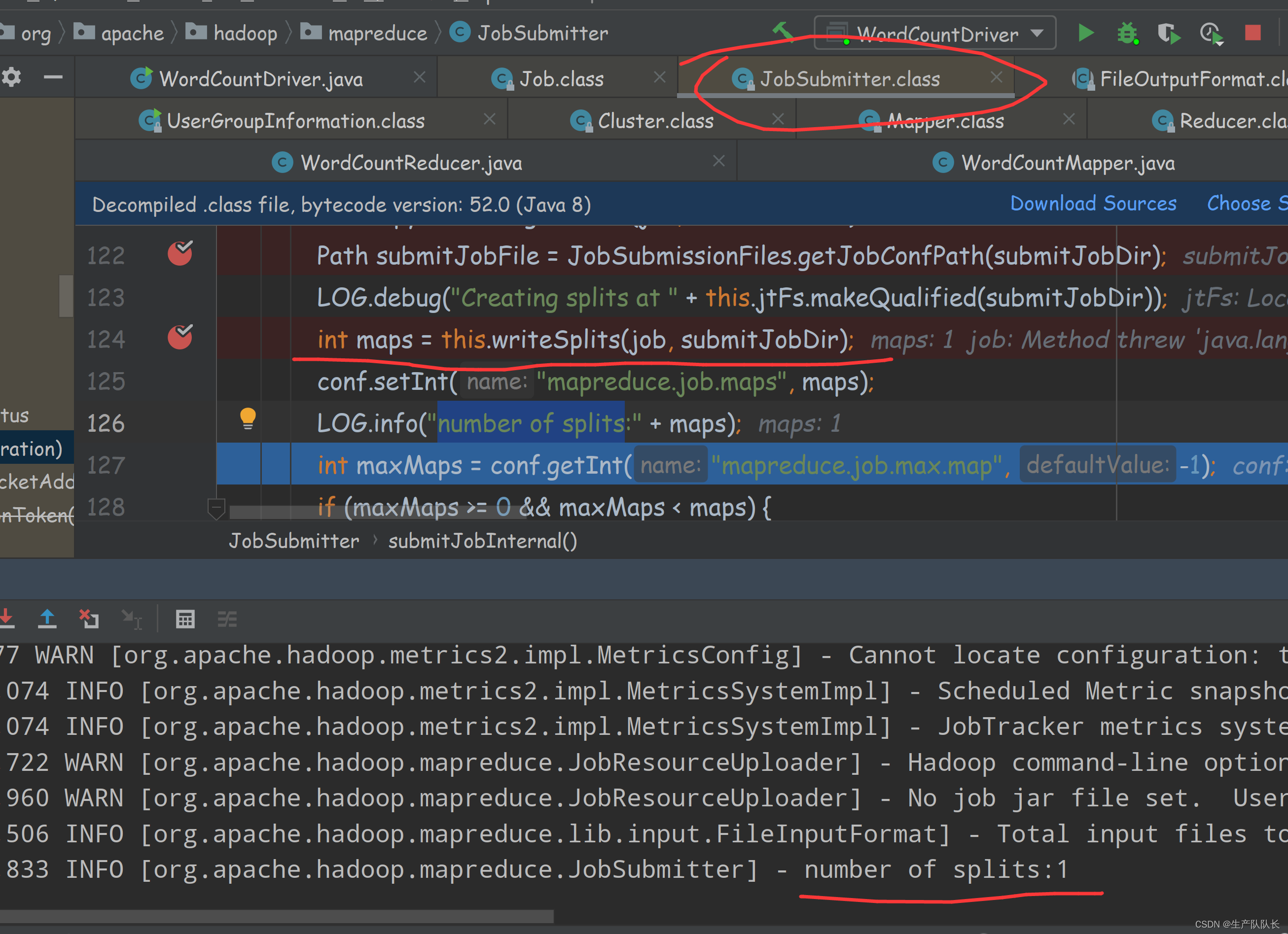
流程总结:
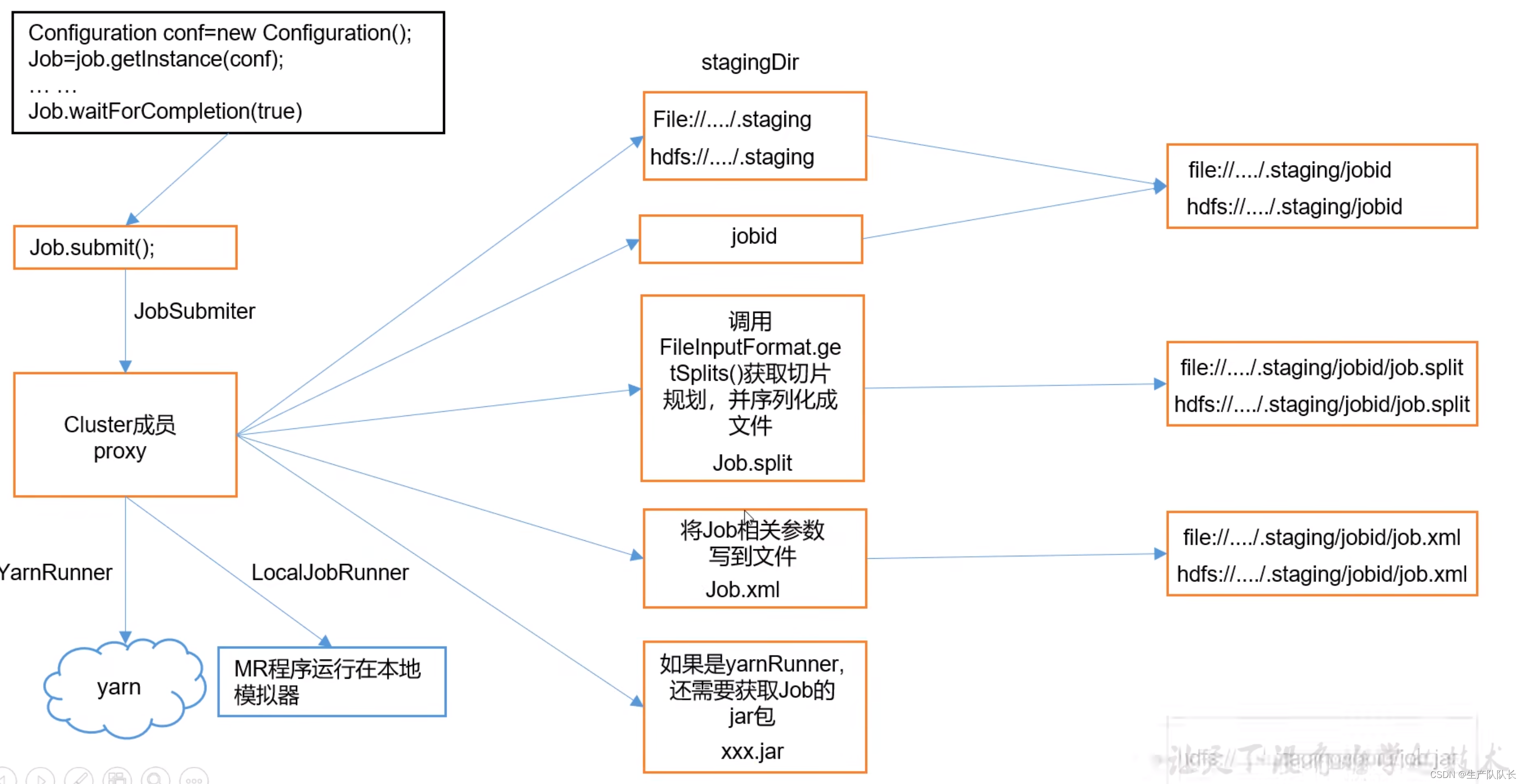
waitForCompletion()
submit();
// 1建立连接connect(); // 1)创建提交Job的代理new Cluster(getConfiguration());// (1)判断是本地运行环境还是yarn集群运行环境initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)// 1)创建给集群提交数据的Stag路径Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);// 2)获取jobid ,并创建Job路径JobID jobId = submitClient.getNewJobID();// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir);// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);maps = writeNewSplits(job, jobSubmitDir);input.getSplits(job);// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);conf.writeXml(out);// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
流程图




![[ue5]建模场景学习笔记(5)——必修内容可交互的地形,交互沙(2)](https://img-blog.csdnimg.cn/direct/fb477df0bdae48f48100a38f630431b9.png)