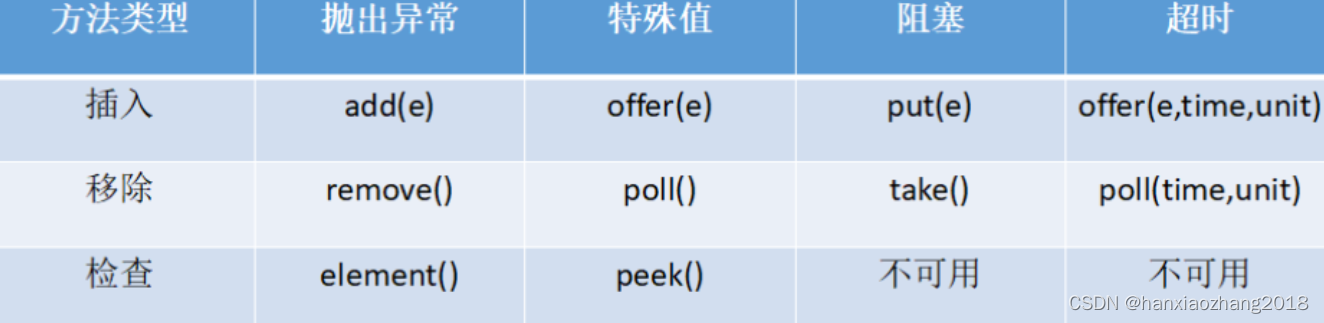
1. NMF算法
NMF算法,即非负矩阵分解,是一种无监督学习算法,主要用于数据降维和特征提取,特别是在数据元素具有非负性约束的情况下。
NMF是一种数据降维模型,它的基本模型是通过矩阵分解将非负数据转换到新的空间,这个新空间的坐标轴(基础矩阵)按照数据的活跃度排序,活跃度越高的基础矩阵能保留更多的数据信息。学习的基本想法是求解能够保留数据集中主要特征并且降低数据维度的分解矩阵。
NMF算法的原理是找到一个分解矩阵,将原始非负数据投影到新的空间中,新空间的每个维度(基础矩阵)都与原始数据的维度正交,并且第一个基础矩阵具有最大的活跃度(即能解释数据中最多的信息),第二个基础矩阵具有第二大的活跃度,且与第一个基础矩阵正交,依此类推。
具体来说,NMF通过以下步骤来实现数据的降维和特征提取:
数据预处理:确保数据矩阵中的所有元素都是非负的,以满足NMF的非负性要求。
分解矩阵初始化:随机初始化分解矩阵 W 和 H,它们将用于重构原始数据。
迭代优化:通过迭代优化过程,交替更新 W 和 H,以最小化重构误差。常用的优化方法包括乘法更新规则、梯度下降法等。
收敛判断:在每次迭代后,检查 W 和 H 的变化是否小于预设的阈值,如果满足则停止迭代。
重构数据:使用得到的分解矩阵 W 和 H 重构原始数据,实现数据的降维。
通过NMF算法,我们可以在保留数据集中主要特征的同时,降低数据的维度,简化模型的复杂度,提高计算效率,并且有助于去除噪声和冗余信息,从而提高后续分析和建模的性能。同时,由于NMF生成的特征向量具有稀疏性和局部性,它在某些应用场景下比PCA具有更好的解释性。
2. NMF的基本原理
非负数据空间:在非负矩阵分解中,数据点存在于一个所有元素均为非负数的空间中。NMF的目标是找到一个变换,将数据投影到一个新的非负空间中,这个新空间的每个维度(基础矩阵)都与原始数据的维度正交。
信息保留最大化:NMF试图找到一个分解,使得在新空间中的基础矩阵能够最好地重构原始数据,同时捕捉数据中的主要信息。基础矩阵的元素乘积能够重构原始数据的非负性。
分解矩阵:在处理数据降维时,NMF通过分解矩阵 W 和 H 来确定数据投影的方向和新空间的维度。分解矩阵 W 决定了基础矩阵的方向,而分解矩阵 H 决定了每个基础矩阵的权重。
数据重构:在确定了分解矩阵后,NMF将原始数据通过 W 和 H 的乘积重构出来。这个过程可以看作是在寻找数据的内在结构,通过降低数据的维度来简化问题。
数据预处理:在训练过程中,NMF对数据进行非负性检查,确保所有元素均为非负数,这有助于避免负数元素对NMF结果产生不利影响。
NMF的原理涉及到矩阵分解、迭代优化以及非负性约束等概念,这使得NMF能够在实践中有效地进行非负数据的降维和特征提取。总的来说,NMF以信息保留最大化为目标,通过求解相应的矩阵分解问题来找到最佳的分解矩阵,实现数据的有效降维。
通过NMF算法,我们能够从非负数据中提取出最重要的特征,降低数据的复杂性,同时保留数据的主要信息,这对于数据可视化、模式识别和机器学习等应用领域具有重要意义。
3. NMF算法的作用与优点
NMF算法,即非负矩阵分解,是一种数据降维和特征提取的无监督学习算法,特别适用于处理具有非负属性的数据集。
具体来说,NMF算法的作用包括:
数据降维:NMF能够减少数据的维度,去除冗余信息,帮助我们从高维非负数据中提取出最重要的特征。这在处理大规模数据集时尤其有用,可以显著降低计算复杂度。
特征提取:通过NMF,我们可以将原始数据转换到一个新的特征空间中,新空间中的特征(基础矩阵)是原始特征的非负线性组合,并且按照活跃度的大小排序。这有助于我们理解数据中的结构和模式。
数据压缩:NMF可以用于数据压缩,通过保留几个主要的成分来近似原始数据,从而减少存储和传输数据所需的资源。
主题发现:特别是在文本数据中,NMF可以用于发现文档集合中的潜在主题,帮助我们理解文本数据的内在结构。
其中,NMF算法的优点包括:
适用性广泛:NMF可以应用于各种类型的非负数据集,无论是图像数据、文本数据还是生物信息学数据,都可以通过NMF进行降维和特征提取。
自动化特征构造:NMF通过元素乘积最大化自动构造最重要的特征,这减少了手动特征构造的工作量,并有助于避免人为的偏差。
稀疏性:NMF倾向于生成稀疏的分解矩阵,这有助于突出数据中的关键特征,并且使得结果更易于解释。
局部性:NMF生成的特征向量通常具有局部性,即它们在原始数据的某些部分上具有较高的权重,有助于发现数据的局部模式。
稳定性:NMF是一种迭代优化方法,通过适当的初始化和优化策略,可以在一定程度上抵抗异常值的影响。
易于实现:NMF算法的实现相对简单,大多数数值计算和机器学习库都提供了NMF的实现,易于集成到现有的数据分析流程中。
NMF作为一种有效的数据降维技术,在图像处理、文本挖掘、生物信息学等领域有着广泛的应用。通过NMF,我们可以有效地处理非负数据,提取出有价值的信息,为后续的数据分析和建模打下坚实的基础。
4. 代码案例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import NMF
from sklearn.preprocessing import MinMaxScaler# 设置随机种子以获得可重现的结果
np.random.seed(0)# 生成随机时序数据
n_samples, n_features, n_components = 1000, 4, 2 # 1000个样本,4个特征,2个组件
X = np.abs(np.random.randn(n_samples, n_features))# 归一化数据
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)# 应用NMF
nmf = NMF(n_components=n_components, init='random', random_state=0)
W = nmf.fit_transform(X_scaled)
H = nmf.components_# 重构数据
X_reconstructed = np.dot(W, H)# 可视化原始数据和重构后的数据
plt.figure(figsize=(12, 8))for i in range(n_features):plt.subplot(n_features, 1, i+1)plt.plot(X[:, i], label='Original')plt.plot(X_reconstructed[:, i], label='Reconstructed', linestyle='--')plt.legend()plt.title(f'Feature {i+1}')plt.tight_layout()
plt.show()

![[CAN] 创建解析CAN报文DBC文件教程](https://img-blog.csdnimg.cn/direct/4e79b98c4b3d4a92a123b481a4a6d698.png#pic_center)