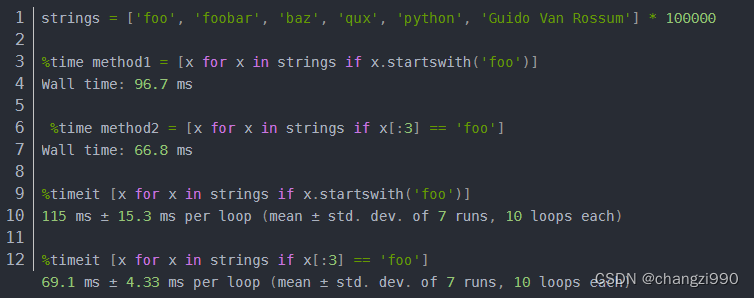
PyTorch 简介
PyTorch 是一个开源的深度学习框架,由 Facebook 的人工智能研究团队(FAIR)开发。它提供了灵活且高效的张量计算功能,并支持动态计算图。PyTorch 的易用性和灵活性使其成为深度学习研究和生产应用中广泛使用的工具。
主要特点
-
动态计算图:
- PyTorch 使用动态计算图(Dynamic Computation Graph),也称为定义即运行(Define-by-Run)模式。这种方式允许在模型运行时改变计算图结构,提供了很大的灵活性,尤其适用于调试和开发复杂模型。
-
强大的张量计算:
- PyTorch 提供类似于 NumPy 的张量操作,但可以在 GPU 上高效运行,极大地提高了计算速度。
-
自动求导:
- PyTorch 内置的自动求导(Autograd)机制,可以自动计算张量的梯度,方便进行反向传播。
-
模块化和可扩展性:
- PyTorch 提供了丰富的模块和类库,如
torch.nn、torch.optim、torch.utils.data等,便于构建和训练神经网络模型。
- PyTorch 提供了丰富的模块和类库,如
-
社区和生态系统:
- PyTorch 拥有活跃的开发者社区和丰富的第三方库支持,如 torchvision(用于计算机视觉)、torchaudio(用于音频处理)等。
PyTorch 的基本概念和组件
-
张量(Tensor):
- PyTorch 的核心数据结构是张量,与 NumPy 数组类似,但可以在 GPU 上进行计算。
import torch# 创建一个张量 x = torch.tensor([[1, 2], [3, 4]]) print(x)# 在 GPU 上创建张量 if torch.cuda.is_available():x = x.to('cuda')print(x) -
自动求导(Autograd):
- PyTorch 的自动求导引擎可以轻松实现反向传播。
# 创建一个需要求导的张量 x = torch.tensor(2.0, requires_grad=True) y = x**2 + 3*x + 5# 计算梯度 y.backward() print(x.grad) # 输出 dy/dx -
神经网络模块(torch.nn):
- PyTorch 提供了构建神经网络的基础模块。
import torch.nn as nn# 定义一个简单的神经网络 class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)model = SimpleNN() -
优化器(torch.optim):
- PyTorch 提供了多种优化算法,如 SGD、Adam 等。
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 在训练循环中使用优化器 for epoch in range(100):optimizer.zero_grad() # 清零梯度output = model(input) # 前向传播loss = loss_fn(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数 -
数据加载(torch.utils.data):
- PyTorch 提供了灵活的数据加载和预处理工具。
from torch.utils.data import DataLoader, Datasetclass CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.labels[idx]dataset = CustomDataset(data, labels) dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
示例代码
以下是一个简单的完整示例,包括数据准备、模型定义、训练和评估:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 生成一些随机数据
x_data = torch.randn(100, 10)
y_data = torch.randn(100, 1)# 创建数据集和数据加载器
dataset = TensorDataset(x_data, y_data)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义一个简单的神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)model = SimpleNN()# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(100):for x_batch, y_batch in dataloader:optimizer.zero_grad()output = model(x_batch)loss = loss_fn(output, y_batch)loss.backward()optimizer.step()# 评估模型
with torch.no_grad():output = model(x_data)loss = loss_fn(output, y_data)print(f'Final loss: {loss.item()}')
总结
PyTorch 是一个强大且灵活的深度学习框架,特别适合研究和快速原型设计。它的动态计算图、自动求导和丰富的工具库使其成为深度学习领域的重要工具。通过学习和使用 PyTorch,你可以更高效地构建、训练和部署复杂的深度学习模型。
![[CUDA 学习笔记] 稀疏矩阵向量乘法(SpMV) CUDA 实现与优化](https://img-blog.csdnimg.cn/direct/49e9c610c3d04ee8b27608db0a68f680.png)