在工业自动化的领域中,数据的采集、存储和分析是实现高效决策和操作的基石。AVEVA Historian (原 Wonderware Historian) 作为领先的工业实时数据库,专注于收集和存储高保真度的历史工艺数据。与此同时,TDengine 作为一款专为时序数据打造的高性能数据库,在处理和分析大量实时、历史时序数据方面展现出无与伦比的优越性。
在最新发布的 TDengine 3.2.3.0 版本中,我们进一步更新了 TDengine 的数据接入功能,推出了一款新的连接器,旨在实现 AVEVA Historian 与 TDengine 的集成。基于此,本文将阐述把 AVEVA Historian 的历史数据和实时数据整合进入 TDengine 的创新方法,以及这种结合如何能够极大地提升数据利用率,打造一个工业创新底座,推动工业自动化高效发展。
从时序数据的关键应用场景分析优化方案
我们先来回顾下当下工业场景几种典型时序数据处理方案:
-
关系型数据库(例如 Oracle/MySQL、达梦、南大通用):关系型数据库在处理海量时序数据时,读写性能较低,分布式支持差。随着数据的增加,查询的速度也会变慢。典型的应用场景包括低频监控场景和电力 SCADA 历史库。
-
传统工业实时库(例如 PI、AVEVA Historian、亚控、海迅):尽管传统工业实时库在工业数据存储中有着长期的功效,但它们的架构已经过时,缺乏分布式解决方案,不能水平扩展。而且,它们依赖于 Windows 等环境,在数据分析能力上较弱,且往往是封闭系统。这类数据库主要用于 SCADA 系统和生产监控系统。
-
NoSQL 数据库(例如 MongoDB、Cassandra):这类数据库的问题在于计算实时性较差,查询速度慢,对内存和 CPU 的计算开销大,没有针对时序数据的优化。它们主要用于处理非结构化数据存储和爬虫数据。
-
Hadoop 大数据平台(例如 HBase、Zookeeper、Redis、Flink/Spark):虽然这类平台支持分布式,但其采用非结构化方式处理时序数据,组件众多,架构臃肿,单节点效率低,硬件和人力维护成本非常高。它们主要用于通用大数据平台和舆情电商大数据。
在当前的工业企业中,创新应用需求旺盛,时序数据处理关键的应用场景包括智能决策支持、设备故障预警、产品质量分析与预测、智能制造与数字孪生、能耗管理与节能减排。这些关键场景突出了工业时序大数据在创新应用中的核心价值,工业企业只有采用先进的解决方案,才能够加快创新步伐并在竞争激烈的市场中实现差异化。
在工业场景中,多个工厂或车间通常会部署独立的 SCADA/Historian 系统,如 AVEVA Wonderware 和 PI 系统,以管理实时和历史数据。这是目前工业自动化的常态,数据分布在各个现场的数据库中。
时序数据向中心侧集中的优势在于,它可以增强对数据的整体控制力,使得企业更好地利用它们的数据资产。数据的集中处理为全局数据可视化带来了可能,为业务创新提供灵感和快速验证的手段,帮助企业更好地管理和分析数据,快速响应而提取有价值的洞见,并依此及时做出商业决策。
SCADA/Historian 也提供了数据集中方案,确实在某些方面能够满足需求,但面临的挑战是它们难以支持海量测点(传感器、设备等)的数据量,难以满足创新应用的对大量获取时序数据的需求。当数据量非常大时,SCADA/Historian 数据消费接口的能力较弱,可能会经历高延时,甚至无法获取需要的数据集。
要有效应对这些挑战,需要从以下几个方面优化方案:
-
利用好已有的投资:很多情况下,企业已经采购、部署了多套 SCADA/Historian,投资已经形成,方案必须考虑如何充分利用已建成系统的能力,避免重复投资。
-
提高数据消费接口的能力:增强数据接口的能力,以确保即使在数据量很大时也能快速、高效地消费数据。
-
降低延时:提升系统的性能以减少处理和提取数据时的延时,确保可以及时地获取数据。
-
实现实时和历史数据的整合:数据的整合可以提高存储空间利用率,并为分析和决策提供更完整的数据视图。实时和历史数据的结合还能支持更复杂的创新应用,如预测维护、能耗管理和优化操作。
-
支撑海量测点:提高系统能够处理的测点数量,以适应越来越多传感器数据的需求。
-
推动创新应用的发展:构建支持创新的基础架构,应对创新应用需求、新兴的工业应用,如预测性维护、资产性能管理、能效优化等,需要对数据进行更深层次的消费、分析和更快速的处理。
TDengine 作为一款极简的时序大数据平台,具有高效的数据写入和查询性能,适合处理海量、时序性的工业数据。除了实时与历史合一的时序库核心功能外,还提供了消息队列、事件驱动流计算、读写缓存,以及多数据源接入的能力。如何实现融合上述六点的方案优化,TDengine 也给出了答案。
整合 AVEVA Historian 数据到 TDengine
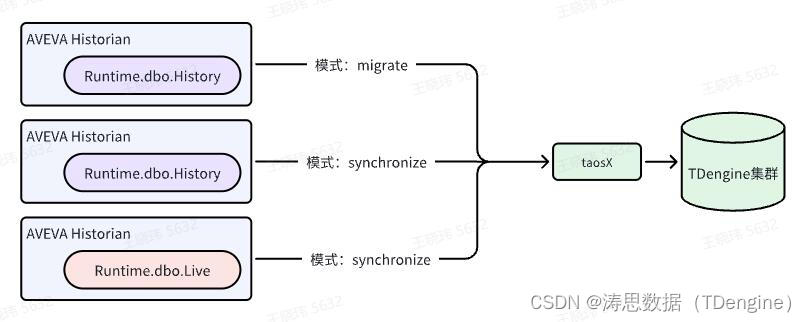
本文方案中,将利用 TDengine 企业版 taosX 的多数据源接入能力汇集多路 AVEVA Historian 现场数据,持久化至中心侧 TDengine 集群。
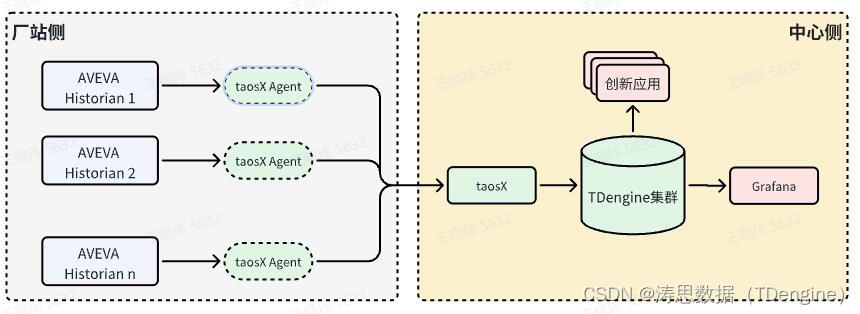
其特点如下:
-
数据迁移:从 AVEVA Historian 系统迁移现有的历史数据到 TDengine。
-
数据同步:支持实时和历史数据的同步,实现 AVEVA Historian 实时(Runtime.dbo.Live)和历史数据(Runtime.dbo.History)至 TDengine 之间的数据同步。
-
支持海量测点:TDengine 支持 10 亿时间线,轻松应对目前工业大数据场景。
-
充分利用已有投资:已有的 AVEVA Historian 将继续发挥作用,同时在 TDengine 平台上支持创新业务的开发。
-
时序数据优化存储:利用 TDengine 的高效数据压缩和存储机制,优化数据在新平台上的存储。
-
查询性能显著提升:与 Historian 的查询性能比较,TDengine 无论在投影查询还是聚合查询,均提升几个数量级的性能。
-
支持数据订阅:TDengine 提供了结构化的消息队列,当数据入库的同时,可根据业务需要创建主题,支持实时消费以驱动创新应用落地。
-
支持多种部署环境:LInux & Windows
-
支持完整 ETL 特性:taosX 组件支持完整的解析、提取拆分、过滤以及数据映射,零代码即可完成外部数据源接入 TDengine。
本方案的基本环境要求有:
-
AVEVA Historian 接入需 TDengine 企业版支持
-
远端采集需通过代理模式接入,采集现场须部署 taosX Agent
-
支持 AVEVA Historian 2017 以后的版本
下面以数据迁移为例,介绍 AVEVA Historian 的历史视图数据如何迁移至 TDengine。
-
先完成准备工作:在 TDengine 中建库、建超级表
-
登入 taosExplorer,创建数据写入任务,类型:AVEVA Historian
-
填写任务基本信息:任务名称、目标数据库、Historian 服务器地址、端口、认证信息
-
填写采集配置:migrate 模式、选择标签点位范围(默认所有点位)、设置源数据起始终止时间、查询时间窗口跨度
-
数据解析与过滤:因 Historian 发送过来的数据是结构化的,无需额外配置解析器和过滤器
-
数据映射:选择目标超级表后,系统会自动匹配部分字段,没有匹配的字段,手工指定映射关系即可
-
启动任务
数据同步 synchronize 与数据迁移 migrate 类似,不同之处在于:
-
支持两个来源:Runtime.dbo.History & Runtime.dbo.Live
-
任务结束时间可以不设定,意味着可以一直同步下去,直至人工终止
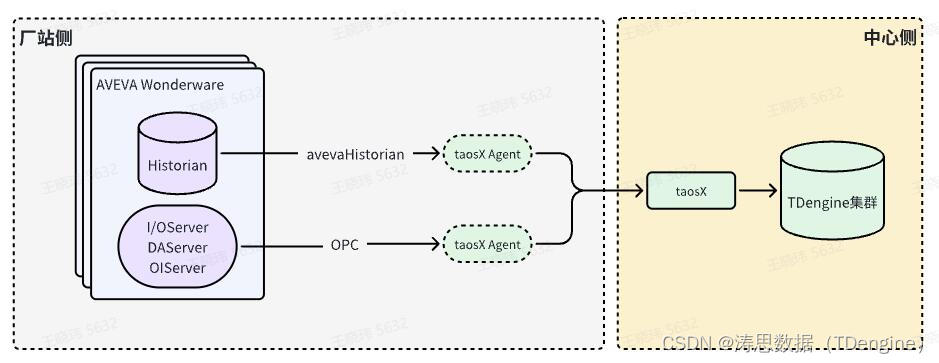
本方案还可以与 OPC 方案融合:历史数据通过 Historian 导入 TDengine,实时数据通过 OPC 汇集至 TDengine。新方案的优点是,通过 OPC 支持的订阅特性实现实时数据即时采集,一旦变化就立刻采集至 TDengine。
新方案同样是基于 taosX 组件,维护方便。
结语
对于曾投资 AVEVA Wonderware 的工业企业,在面临数字化转型的挑战时,Historian Connector 结合 TDengine 的解决方案便能成为他们的强大后盾。此方案不仅能快速打通数字化转型的难关,还能携业务创新之力,开拓数字化潜能。
此外,本方案具有优秀的融合能力,可与各类数据采集解决方案无缝结合。例如,通过与 OPC Connector 数据采集方案的整合,历史数据得以从 Historian 顺畅导入至 TDengine,同时实时数据亦可通过 OPC 即时汇集至 TDengine,实现现场时序数据的高效集中处理。
本方案所依托的是 TDengine Enterprise 企业版的强大功能(且未来我们将推出 TDengine Cloud 版本)。如若贵企业正寻求这方面的解决方案,欢迎主动接洽北京涛思的专业商务团队,一起探索先进的数据处理之道。
关于 AVEVA Wonderware
Wonderware 公司成立于 1987 年,总部位于美国洛杉矶,是全球工业自动化领域的知名品牌。其先被施耐德电气收购,后并入 AVEVA。AVEVA Wonderware 应用行业广泛,在连续生产过程控制和离散制造领域优势明显。主要应用于烟草生产、水处理、电力、石油天然气、化工、钢铁冶金、食品饮料、制药、汽车制造、物流仓储等行业。其产品包括但不限于 In Touch HMI(人机界面)、System Platform(系统平台)、Historian(历史数据记录与分析)。