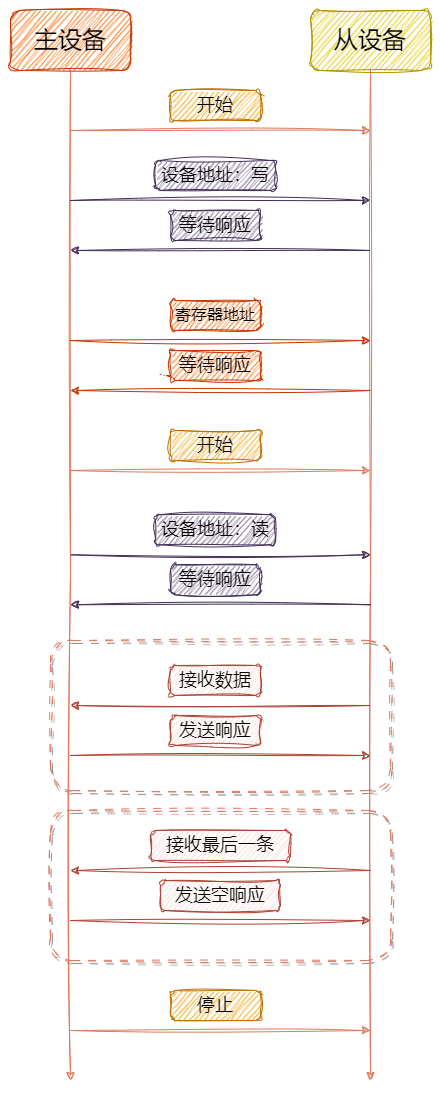
先来看一段bs4的应用实例:


结果输出如下:

代码逐行解释如下:
1. 首先,我们导入了`re`模块和`BeautifulSoup`类。
2. 然后,我们定义了一个包含多个链接的HTML文档字符串`html_doc`。
3. 接着,我们创建了一个BeautifulSoup对象`soup`,并将HTML文档传递给它进行解析。
4. 在`soup.find_all()`方法中,我们使用了正则表达式`re.compile(r'^https?://')`来匹配以"http://"或"https://"开头的链接。其中,`^`表示字符串的开头,`https?`表示"http"或"https",`://`表示冒号和两个斜杠。
5. `find_all()`方法返回一个包含所有符合条件的标签的列表。
6. 最后,我们遍历这个列表,并打印出每个链接的`href`属性值。
可以看到,只有以"http://"或"https://"开头的链接被成功提取出来。
对于bs4介绍:
Beautiful Soup 4是网络爬虫中常用的HTML/XML解析库,它能够帮助开发者从复杂的网页结构中提取有价值的数据。以下是具体介绍:
1. 初始化与文档解析:
- 使用BeautifulSoup类将HTML或XML文档转换成一个Beautiful Soup对象,从而便于后续操作。
- 在初始化Beautiful Soup对象时,需选择合适的解析器,如'html.parser'、'lxml'等,以优化解析过程并提高容错能力。
2. 标签查询与选择器:
- 通过标签名直接查询单个标签或查询所有符合条件的标签。
- 根据属性和属性值来查询单个或多个具有特定属性的标签。
- 使用CSS选择器进行高级查询,能够更精确地定位到特定的标签集合。
3. 数据提取与异常处理:
- 提取标签的文本内容,并对提取的文本进行处理,如去除空白字符、提取数字等。
- 在进行标签查询和内容提取时,添加适当的异常处理机制,避免出现None引发的异常,确保代码的稳定性。
4. 编码选择与文件处理:
- 在处理本地文件时注意指定正确的文件编码格式,如UTF-8,以避免乱码问题。
- 使用prettify()等方法优化输出内容的可读性,便于调试和分析。
5. 属性操作与链接处理:
- 获取和设置标签的属性,如获取链接标签的href属性来提取URL。
- 利用Beautiful Soup的导航功能,如parent、next_sibling等,遍历文档树并定位到特定标签的上下文环境。
6. 自定义函数与模块化设计:
- 针对常见的数据提取任务,编写自定义函数封装Beautiful Soup操作,提高代码复用性和可维护性。
- 结合其他Python库,如Requests、Pandas等,实现数据的采集、清洗、分析一体化流程。
7. 性能优化与最佳实践:
- 评估不同解析器的性能,根据应用场景选择最合适的解析器平衡解析速度和容错需求。
- 遵循Beautiful Soup的官方文档和社区推荐的最佳实践,编写高效且可维护的爬虫代码。
8. 示例应用与实战演练:
- 通过实际案例,如抓取网站标题、链接、图片等,加深对Beautiful Soup在爬虫中应用的理解。
- 定期回顾和更新爬虫代码,适应目标网站可能的结构调整,确保爬虫程序的长期有效运行。
Beautiful Soup 4因其易用性和强大的文档处理能力,成为Python爬虫领域的重要工具。掌握Beautiful Soup 4的使用对于设计和开发高效稳定的网络爬虫至关重要。通过以上详细的介绍和实践指南,开发者可以更好地利用Beautiful Soup 4进行网页数据的爬取和处理,从而在数据分析和网络信息采集的任务中取得更好的成果。
正则表达式与bs4强强联手
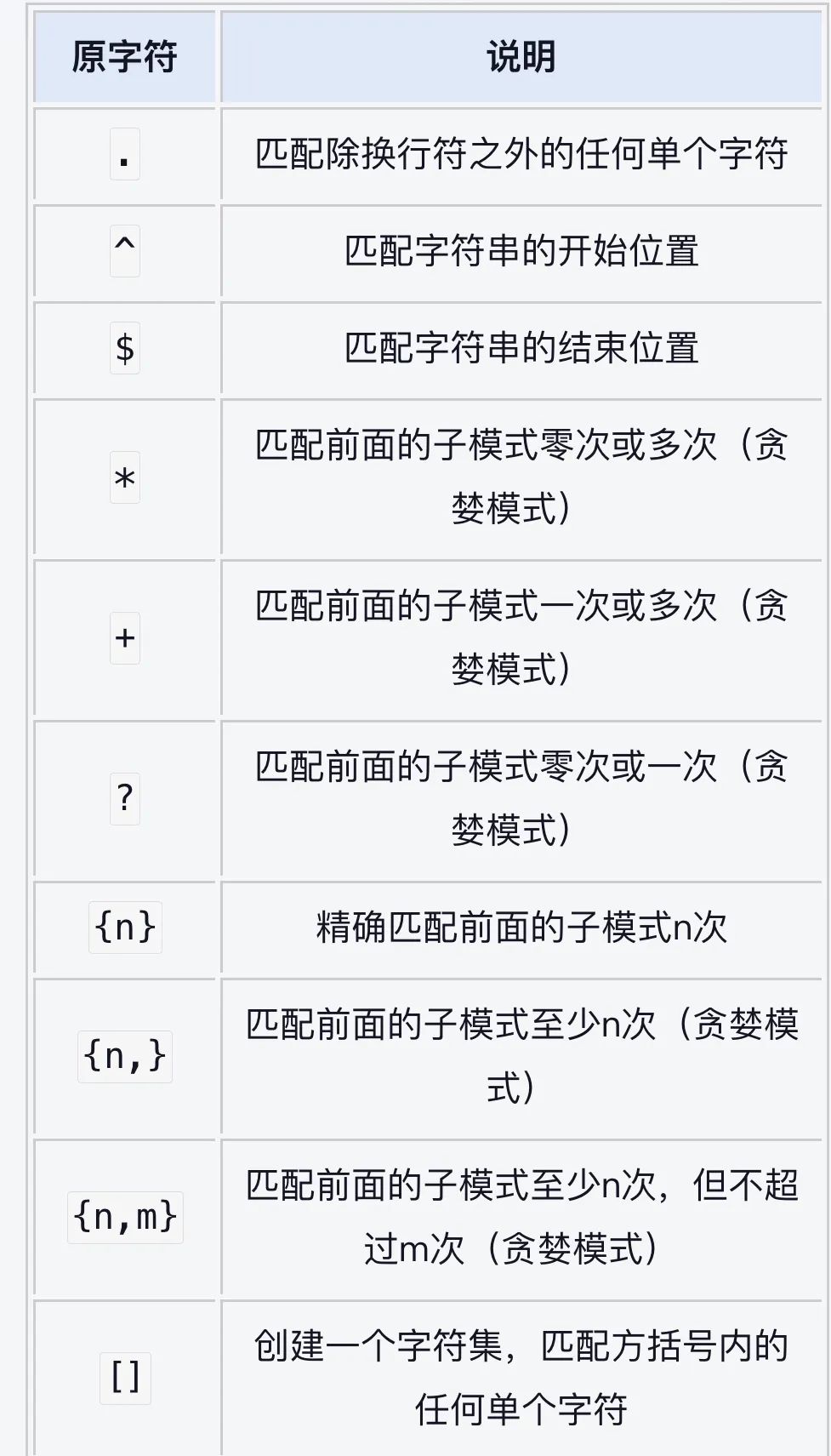
正则表达式(原字符)
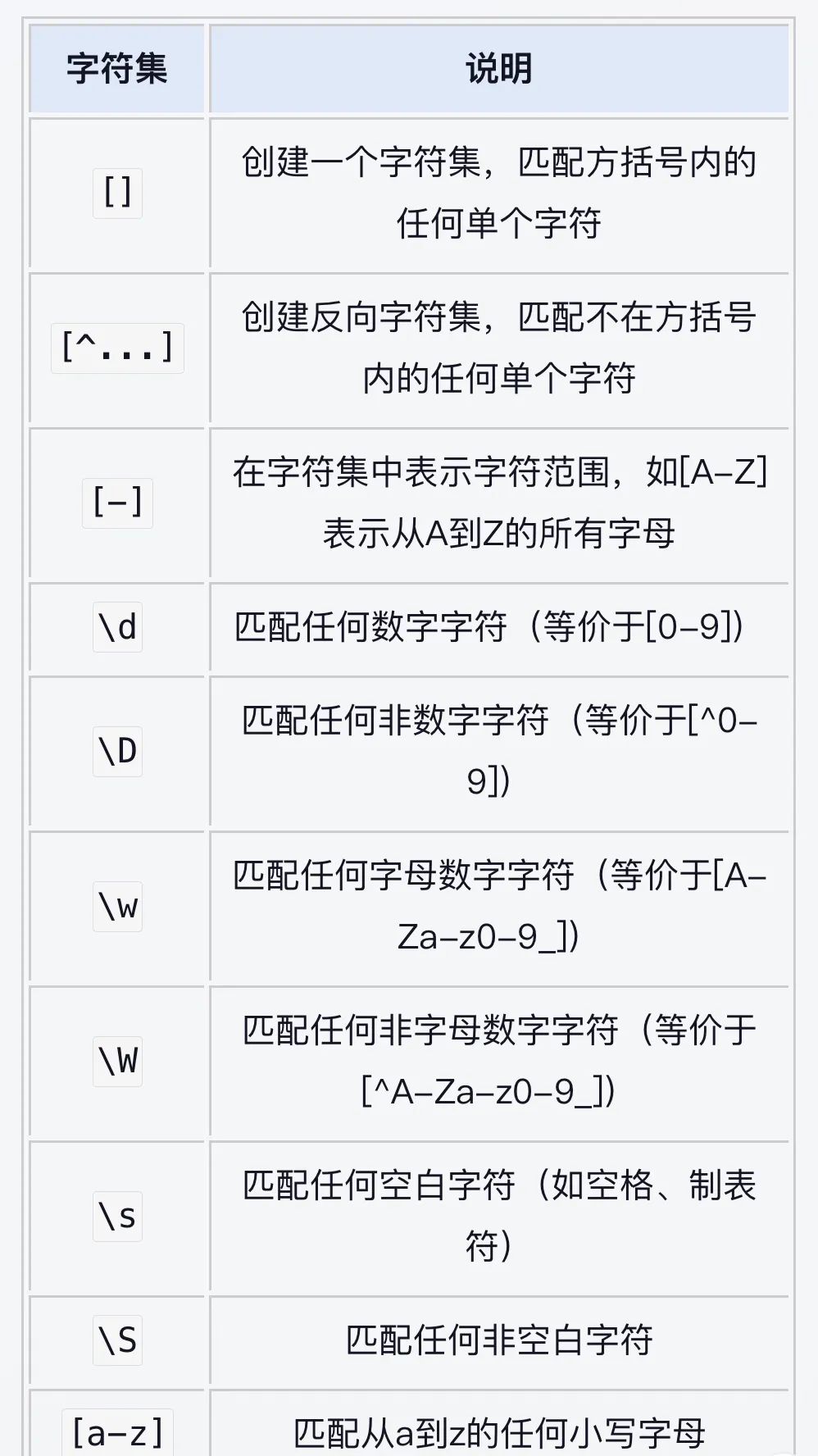
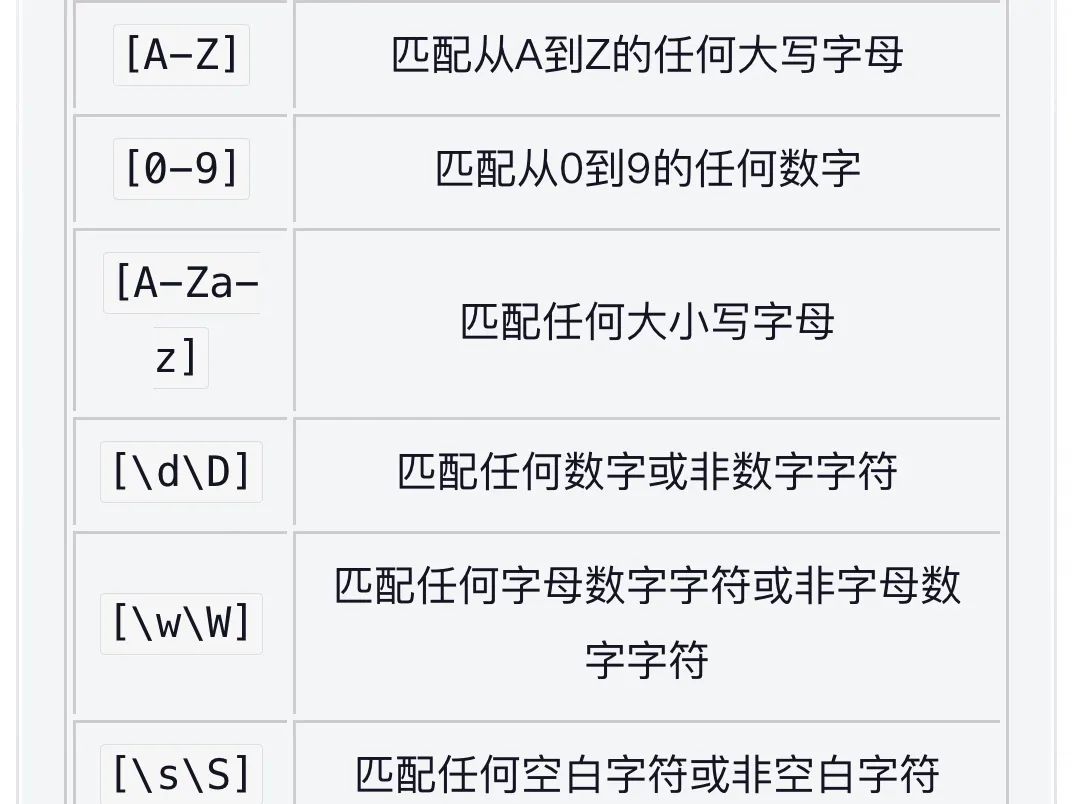
正则表达式(字符集)
以上的相关应用可以通过小蜜蜂AI的GPT问答获取更多的示例。网址:https://zglg.work。
(文章对你有用的话。记得点赞➕在看哦😯😯😯😯分享知识也是一种美德)
如有学习上的困惑或问题欢迎评论区留言告诉我们,让我们一起解决共同进步: