MySQL(Ⅱ)
- 7、 进阶篇 —— 存储引擎
- 7.1、MySQL 体系结构
- 7.2、存储引擎
- 7.2.1 InnoDB
- 7.2.2 MyISAM
- 7.2.3 Memory
- 7.2.4 InnoDB、MyISAM、Memory 的比较
- 8、 拓展篇 —— 在 Linux 上安装数据库
- 9、进阶篇 —— 索引
- 9.1、概述
- 9.2、语法
- 9.3、性能分析
- 9.4、联合索引中索引失效的情况
- 9.5、索引使用的 SQL 提示
- 9.6、覆盖索引
- 9.7、前缀索引
- 9.8、索引设计原则
- 10、进阶篇 —— SQL 优化
- 10.1、插入数据
- 10.2、主键优化
- 10.3、ORDER BY 优化
- 10.4、GROUP BY 优化
- 10.5、LIMIT 优化
- 10.6、COUNT 优化
- 10.7、UPDATE 优化
7、 进阶篇 —— 存储引擎
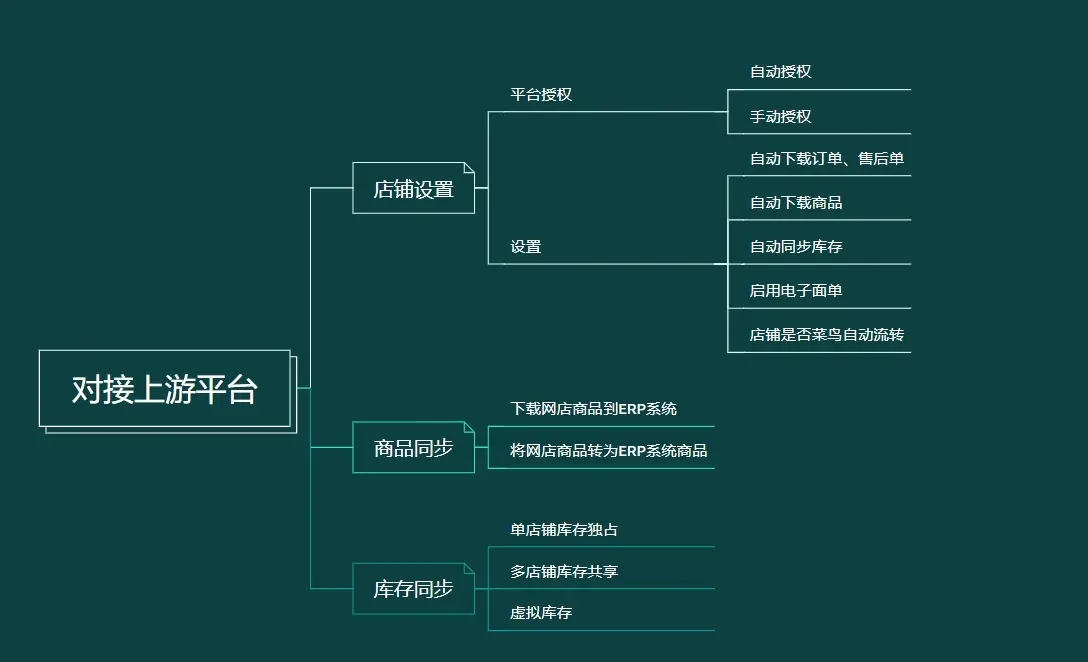
7.1、MySQL 体系结构
常见的客户端连接器,例如 Native C API、JDBC、ODBC、.NET、PHP、Perl、Python、Ruby 和 Cobol 会 使相应的语言和应用程序与 MySQL 进行数据交互
而 MySQL 的体系结构如下图所示,由 Client Connectors (客户端链接)层、MySQL Server (MySQL 服务)层及 Storage Engines (存储引擎)层组成
| 客户端链接层 | 描述 |
|---|---|
| Connection Pool | 处理数据库连接的管理,包括认证、线程重用、连接限制、内存检查和缓存管理。通过连接池,MySQL 可以有效地管理和复用连接,提升性能 |
| MySQL Server | 描述 |
|---|---|
| Management Services & Utilities | 包括备份与恢复、安全性、复制、集群、管理、配置、迁移和元数据管理等。这些工具和服务帮助管理员更好地管理和维护 MySQL 服务器 |
| SQL Interface | 处理 DML(数据操作语言,如 SELECT、INSERT)、DDL(数据定义语言,如 CREATE、ALTER)、存储过程、视图和触发器等。SQL 接口是用户与数据库交互的主要途径 |
| Parser | 将 SQL 查询解析成可执行的指令,负责查询翻译和对象权限检查。解析器确保查询的正确性并进行语法分析 |
| Optimizer | 确定执行查询的最佳路径,基于统计数据选择最优的访问路径。优化器对于提升查询性能至关重要 |
| Caches & Buffers | 包含全局和引擎特定的缓存与缓冲区,用于提升数据访问的速度。缓存机制在提高 MySQL 性能方面起着重要作用 |
| Storage Engines | 描述 |
|---|---|
| Pluggable Storage Engines | 存储引擎包括MyISAM、InnoDB、Archive和Memory。MySQL是一个插件存储引擎。只要正确定义了与MySQL Server的接口,任何引擎都可以访问MySQL,这也是MySQL受欢迎的原因之一 |
| File system | MySQL 支持多种文件系统,包括 NTFS、ufs、ext2/3、NFS、SAN 和 NAS。文件系统是数据最终存储的位置 |
| Files & Logs | 包含重做日志、撤销日志、数据文件、索引文件、二进制日志、错误日志、查询日志和慢查询日志等。这些日志文件帮助 MySQL 进行数据恢复、审计和性能优化 |

7.2、存储引擎
在生活中,引擎是一种将燃料或其他能量转化为机械能的装置,用于驱动车辆、机器等。例如汽车引擎用于将燃油燃烧产生的能量转化为机械能,驱动汽车行驶;飞机引擎用于利用燃料燃烧提供推力,使飞机飞行;电动机用于将电能转化为机械能,驱动各种电器和机械设备
而在数据库管理系统(DBMS)中,存储引擎是用来管理和操作数据(存储数据、建立索引、更新/查询数据等)的核心组件。且存储引擎是基于表的而不是基于库的,每张表可以有自己的存储引擎,因此存储引擎也可以被称为表的类型,每种存储引擎都有其特定的特性和优化目标
两者虽然应用领域不同,但都是为实现特定功能和优化性能而设计的关键部分
建表时指定存储引擎:
CREATE TABLE 表名 ( ... ) ENGINE=xxx [ COMMENT 表注释 ];
查询当前数据库支持的存储引擎:SHOW ENGINES;
现在默认的存储引擎是:InnoDB
接下来讲述几种常见的存储引擎
7.2.1 InnoDB
| 概述 | 描述 |
|---|---|
| 介绍 | InnoDB 是 MySQL 的默认存储引擎,支持事务(Transaction),行级锁(Row-level Locking)以及外键约束(Foreign Key Constraint) |
| 特点 | 高可靠、高性能 |
| 用途 | 适用于需要高并发和数据完整性保障的应用场景,如金融系统、电子商务网站等 |
| 文件 | 使用 InnoDB 引擎构建的表会对应一个 xxx.ibd 表空间文件,用于存储表的表结构(frm,sdi)、数据、索引 查看其存放的表结构:在存放目录下打开cmd执行 ibd2sdi xxx.ibd(sdi为表结构) |
| 相关参数 | 查看:SHOW VARIABLES LIKE 'innodb_file_per_table';如果 innodb_file_per_table 参数为 ON 则说明每张表会对应一个 ibd 文件而非共享 |
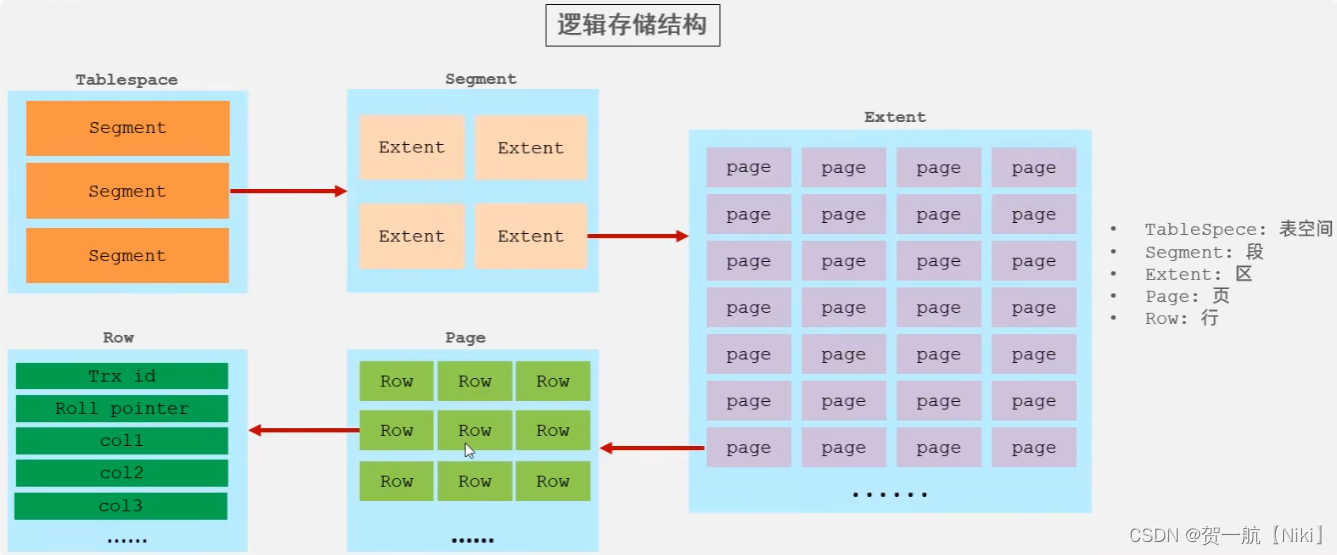
| 逻辑存储结构 | 描述 |
|---|---|
| 表空间(Tablespace) | InnoDB 将所有的数据存储在一个或多个表空间中。表空间是数据库的逻辑存储单位,可以包含多个数据文件,默认情况下,所有 InnoDB 表拥有属于自己的独立表空间 |
| 段(Segment) | 每个表空间由多个段组成。段是表和索引的数据存储单位 ① 数据段: 存储表的行数据 ② 索引段: 存储表的索引数据 ③ 回滚段: 存储事务回滚信息 |
| 区(Extent) | 段由区组成,每个区的大小为 1 MB(64 个页,每个页 16 KB) ① 数据区: 包含表的行数据页 ② 索引区: 包含索引页 |
| 页(Page) | 页是 InnoDB 的最小存储单位,每个页的大小为 16 KB,这里的页就是磁盘的块,是磁盘处理的最小单元 ① 数据页: 存储表的行数据 ② 索引页: 存储 B+ 树索引 ③ 撤销日志页: 存储撤销日志,用于事务回滚 ④ 系统页: 存储系统信息 |
| 行(Row) | 页中存储具体的行数据,每行代表表中的一条记录 |
7.2.2 MyISAM
| 概述 | 描述 |
|---|---|
| 介绍 | MyISAM 是 MySQL 早期的默认存储引擎,它不支持事务、外键,但支持表级锁(Table-level Locking) |
| 特点 | 存储结构简单,占用空间小,查询性能高,访问速度快 |
| 用途 | 适用于只读和低更新频率(读多于写)的应用场景,如数据仓库和数据分析 |
| 文件 | 使用 MyISAM 引擎构建的表会对应有 xxx.sdi 文件(存储表结构)、xxx.MYD 文件(存储表数据)、xxx.MYI 文件(存储索引) Tip:ibd 文件是二进制文件,而 sdi 文件是一个 JSON 类型的文本文件,可以直接打开 |
7.2.3 Memory
| 概述 | 描述 |
|---|---|
| 介绍 | Memory 存储引擎将数据存储在内存中,由于受到硬件问题、断电问题的影响,只能将这些表作为临时表或缓存使用 |
| 特点 | 由于存放在内存因此访问速度快,支持 Hash 索引,但数据在服务器关闭时会丢失(数据不持久化) |
| 用途 | 适用于需要快速访问的数据,如缓存表和临时数据 |
| 文件 | 使用 Memory 引擎构建的表会对应有一个 xxx.sdi 文件(存储表结构),而的数据、索引存放在内存中,因此没有相关的存储文件 |
7.2.4 InnoDB、MyISAM、Memory 的比较
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 256TB (可调整) | 受可用内存限制 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持 | 支持 | - |
| 空间使用 | 较高(包括事务日志等) | 较低 | 高(数据在内存中) |
| 内存使用 | 较高 | 较低 | 高 |
| 批量插入速度 | 低 | 高 | 高 |
| 外键 | 支持 | - | - |
8、 拓展篇 —— 在 Linux 上安装数据库
① 下载 Linux 版的 MySQL 安装包:
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.3.0-1.el7.x86_64.rpm-bundle.tar
② 解压 :mkdir mysql→tar -xvf mysql-8.3.0-1.el7.x86_64.rpm-bundle.tar -C mysql
③ 安装:cd mysql
Ⅰrpm -ivh mysql-community-common-8.3.0-1.el7.x86_64.rpm
Ⅱrpm -ivh mysql-community-client-plugins-8.3.0-1.el7.x86_64.rpm
Ⅲrpm -ivh mysql-community-libs-8.3.0-1.el7.x86_64.rpm(报错的话就先执行yum -y remove mariadb-libs.x86_64)
Ⅳrpm -ivh mysql-community-libs-compat-8.3.0-1.el7.x86_64.rpm
Ⅴrpm -ivh mysql-community-devel-8.3.0-1.el7.x86_64.rpm(报错的话就先执行yum -y install openssl-devel)
Ⅶrpm -ivh mysql-community-client-8.3.0-1.el7.x86_64.rpm
Ⅷrpm -ivh mysql-community-server-8.3.0-1.el7.x86_64.rpm
③ 现在就启动:systemctl start mysqld(设置以后开机自启动:systemctl enable mysqld)→systemctl status mysqld查看启动成功没有
④ 查看初始密码:grep 'temporary password' /var/log/mysqld.log | tail -n 1 | awk '{print "初始密码是:"$NF}'
⑤ 修改密码:mysql -u root -p输入初始密码进行登录 →ALTER USER 'root'@'localhost' IDENTIFIED BY 'Ab@123456';先设置一个复杂点的密码以符合当前的密码检验等级(不改密码不让执行其他的 sql 语句) →SET GLOBAL validate_password.policy = 0;将密码检验等级改为低(现在要求长度符合八位即可) →SET GLOBAL validate_password.length = 4;设置密码长度符合四位即可(SHOW VARIABLES LIKE 'validate_password%';查看现在的密码检验规则) →ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';现在就可以设置一个简单的密码了
⑥ 重新登录:exit退出 mysql →mysql -u root -p使用新密码进行登录
⑦ 创建一个新的 root 用户让其它主机能够用来访问数据库:CREATE USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';→GRANT ALL ON *.* TO 'root'@'%';授予所有权限
⑧ 现在就关闭 Linux 防火墙:systemctl stop firewalld(设置以后开机不要自启动:systemctl disable firewalld)
配置完成 ~ ~ ~
TIP:在 mysql 终端中清屏指令是:\! CLEAR;
链接测试

链接成功,下面将采用 linux 系统中的 mysql 进行测试,先创建数据库
-- 创建数据库
CREATE DATABASE mysql_study DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
-- 查看
SHOW DATABASES;
-- 使用
USE mysql_study;
9、进阶篇 —— 索引
9.1、概述
索引(Index)是数据库管理系统(DBMS)中的一种数据结构,它用于提高数据库表的查询速度。索引类似于书本的目录,通过建立索引,可以在不必扫描整个表的情况下快速定位到所需的数据行,MySQL 中的索引主要用于优化查询性能
| 索引的类型 | 描述 | 索引结构 ( InnoDB ) | 创建使用关键字 |
|---|---|---|---|
| 主键索引 | 针对主键创建的索引,默认会自动创建,且只能有一个 | B+树 | PRIMARY |
| 唯一索引 | 索引列的值必须要唯一,唯一索引可以有多个 | B+树 | UNIQUE |
| 常规索引 | 索引列的值可以不唯一,常规索引可以有多个 | B+ 树 | |
| 全文索引 | 用于全文搜索,适用于大文本数据的查询 | Full-text | FULLTEXT |
TIP
1、对于主键来说,会默认地自动为其创建主键索引,而对于唯一索引来说,不是一个字段声明了唯一约束(unique)它就有相应的唯一索引了,唯一约束只是为了在插入数据时防止有相同的值,而唯一索引是执行相应的 sql 语句去将值都唯一的列创建出的一个数据结构,例如CREATE UNIQUE INDEX idx_name ON students_info(name);
2、唯一索引和常规索引的区别在于允不允许出现相同的键值
3、Full-text 基于倒排索引:倒排索引是一种映射,记录每个词条出现在哪些文档或行中,类似于书的索引部分,告诉你哪个词出现在书的哪些页。当创建全文索引时,数据库会解析文本字段,将其拆分成单词或词条(通常,数据库会忽略停用词如 “the”, “is”, “at” 等以及标点符号,只保留有意义的单词),例如,如果我们有两个文档:
文档1: “MySQL is a popular database.”
文档2: “MySQL supports full-text indexing.”
倒排索引会类似这样:
MySQL -> 文档1, 文档2
is -> 文档1
a -> 文档1
popular -> 文档1
database -> 文档1
supports -> 文档2
full-text -> 文档2
indexing -> 文档2
4、如果在一个字段上没有创建索引,数据库在执行基于该字段的查询时,通常会进行全表扫描
根据索引的存储形式,可以划分为两类
| 类别 | 描述 | |
|---|---|---|
| 聚集索引 | 将数据存储与索引放到一块,索引结构的叶子节点保存了行数据 | 必须有且只有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以有多个 |
TIP
1、对于主键索引,B+ 树的叶子节点存储的是数据行 —— 聚集索引
2、对于唯一索引和常规索引,B+ 树的叶子节点存储的是指向实际数据行的指针(即主键值)—— 二级索引
3、如果一个表不存在主键(主键索引),将使用第一个唯一索引(不是唯一约束)作为聚集索引
4、如果一个表既没有主键(主键索引),又没有唯一索引,则 InnoDB 会自动地生成一个 rowid 作为隐藏地聚集索引,可见这样就起不到什么检索上地帮助了
根据索引关联的字段数量,又可以划分为两类
| 类别 | 描述 |
|---|---|
| 单列索引 | 索引关联一个字段 |
| 联合索引 | 索引关联多个字段 |
| 索引结构 | 描述 | InnoDB | MyISAM | Memory |
|---|---|---|---|---|
| B+树索引 | 最常见的索引类型,大部分的存储引擎都支持 B+ 树索引 | √ | √ | √ |
| Hash 索引 | 基于哈希表的索引,只有精确匹配索引列的查询才能生效,不支持范围查询 | √ | ||
| R-Tree(空间索引) | 是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 | √ | ||
| Full-text(全文索引) | 基于倒排索引,能够快速地匹配文档进行全文搜索,类似于 Lucene,Solr,ES | 5.6v+ 支持 | √ |
TIP
1、查看存储引擎的版本(以InnoDB为例):SHOW VARIABLES LIKE 'innodb_version';
2、由于树的特性,加之B树、B+树是有序的,因此B树、B+树支持范围查询,而索引存放在哈希表中是无序的,不能知道自己(例如4)附近有哪些具体的索引值(是2呢还是3呢还是4.0001呢,是猜不完的,而树是连在一起的有关系的,因此数据库中存没存2、3、4.0001一看便知),因此Hash不支持范围查询
| InnoDB 采用 B+ 树的原因 | 描述 |
|---|---|
| 更高的存储效率 | 与二叉树(红黑树)每个节点只包含一个索引不同,B+ 树节点包含多个索引,相对于 B 树来说也是(因为 B 树的节点中包含了数据,占据了索引的存放空间),使树的高度较低,利用了页式存储的优势,减少了查询时的磁盘 I/O 操作 |
| 稳定的搜索时间 | B+ 树所有的实际数据都存储在叶子节点中,内部节点只存储索引信息,这使得搜索操作的时间复杂度更加稳定 |
| 支持顺序访问 | 由于 B+ 树的所有叶子节点通过链表连接(InnoDB还将其升级为双向循环链表),因此支持高效的顺序访问,且使得范围查询(如 BETWEEN、> 、< 等)和排序操作非常高效 |
| 存储引擎 | 索引存储方式 | 具体 |
|---|---|---|
| InnoDB | 将表数据和索引数据存储在同一个表空间文件中 | 每个 InnoDB 表都有一个表空间文件(.ibd 文件),存储该表的表数据和辅助索引数据,主索引(即主键索引)存储在聚簇索引中,聚簇索引是表数据的一部分 |
| MyISAM | 将表数据和索引数据存储在不同的文件中 | xxx.sdi 文件用于存储表结构、xxx.MYD 文件用于存储表数据、xxx.MYI 文件用于存储索引 |
| 优点 | 描述 |
|---|---|
| 提高查询效率、减少磁盘 I/O | 由于索引较小,可以在内存中加载更多的索引,而不是整个表数据,因此可以在更少的磁盘 I/O 操作中获知所需的数据信息 |
| 排序优化 | 索引可以按指定的顺序存储数据,这样在执行带有 ORDER BY 子句的查询时,数据库不需要额外的排序步骤,降低 CPU 的消耗 |
| 缺点 | 描述 |
|---|---|
| 占用空间 | 索引需要额外的存储空间 |
| 插入和更新性能下降 | 每次插入、删除或更新数据时,索引也需要相应地更新,从而增加了额外的开销 |
9.2、语法
创建常规索引:
CREATE INDEX 索引名 ON 表(字段1,字段2...);
创建唯一索引:CREATE UNIQUE INDEX 索引名 ON 表(字段1,字段2...);
创建全文索引:CREATE FULLTEXT INDEX 索引名 ON 表(字段1,字段2...);
查看索引:SHOW INDEX FROM 表;(由于一行的内容很多,因此在 cmd / vim 中使用SHOW INDEX FROM tb_user\G;可以将一行呈现为一个单子的样子)
删除索引:DROP INDEX 索引名 ON 表;
-- 创建表
CREATE TABLE tb_user
(id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50),phone VARCHAR(20),email VARCHAR(50),profession VARCHAR(50),age INT,gender INT,status INT,createtime DATETIME
);-- 插入数据
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('吕布', '17799990000', 'lvbu666@163.com', '软件工程', 23, 1, 6, '2001-02-02 00:00:00'),('曹操', '17799990001', 'caocao666@qq.com', '通讯工程', 33, 1, 0, '2001-03-05 00:00:00'),('赵云', '17799990002', '17799990002@139.com', '英语', 34, 1, 2, '2002-03-02 00:00:00'),('孙悟空', '17799990003', '17799990003@163.com', '工程造价', 35, 1, 4, '2001-07-02 00:00:00'),('花木兰', '17799990004', '1998072@sina.com', '软件工程', 23, 2, 1, '2001-04-22 00:00:00'),('大乔', '17799990005', 'daqiao666@sina.com', '舞蹈', 22, 2, 0, '2001-02-07 00:00:00'),('露娜', '17799990006', 'luna_love@sina.com', '应用数学', 24, 2, 0, '2001-02-08 00:00:00'),('程咬金', '17799990007', 'chengyaojin@163.com', '化工', 38, 1, 5, '2001-05-23 00:00:00'),('项羽', '17799990008', 'xiaoyu666@qq.com', '金属材料', 43, 1, 0, '2001-09-18 00:00:00'),(