接前面加入钩子函数处理token复用的问题,只保证了用例的串联执行,我的部分测试用例中接入了通义千问的部分接口生成测试数据,七八个场景跑完差不多快要10分钟。考虑使用并发执行。
http://t.csdnimg.cn/ACexL

使用多线程和不使用耗时差距很大,建议还是开启
前置条件:
下载pytest-xdist 这个包 ,直接在终端pip install pytest-xdist即可
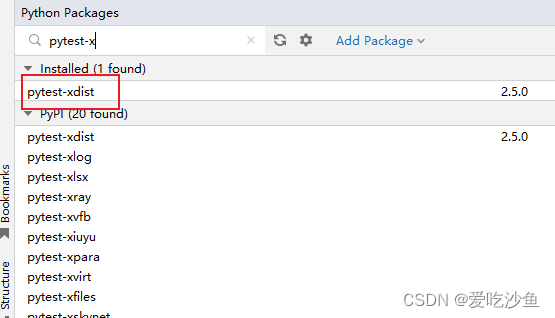
更改pytest.ini 命令行配置
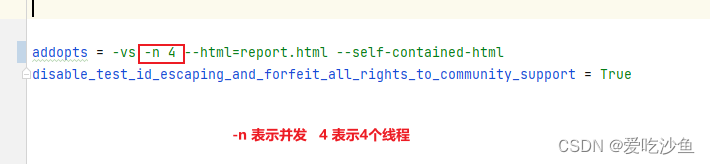
更改token处理方式,加入锁机制
代码是由之前的代码使用gpt生成的 ,针对token.json文件的锁好像无用,还是会导致登录频繁报错。这里改为对username的锁,保证同一时间同一账号只登录一次。另外,避免出现其他不稳定的情况,建议加上重试 --reruns 2。
# 全局文件锁
token_file_lock = threading.Lock()# 用户级别的锁字典,用于控制对每个用户名的并发访问
user_token_locks = {}def load_tokens_from_file(file_path):with token_file_lock:with open(file_path, 'r') as file:return json.load(file)def save_tokens_to_file(tokens, file_path):with token_file_lock:with open(file_path, 'w') as file:json.dump(tokens, file)def get_user_lock(username):"""获取或创建针对特定username的锁。"""if username not in user_token_locks:user_token_locks[username] = threading.Lock()return user_token_locks[username]def synchronized_per_user(func):"""装饰器,用于同步函数,确保对每个username的操作是线程安全的"""@wraps(func)def wrapper(username, *args, **kwargs):user_lock = get_user_lock(username)with user_lock:return func(username, *args, **kwargs)return wrapper@pytest.fixture(scope="module")
def auth_tokens(refresh_threshold=600, file_path='tokens.json'):tokens = load_tokens_from_file(file_path)@synchronized_per_userdef get_or_refresh_token(username):nonlocal tokenstoken_info = tokens.get(username)if not token_info or (time.time() - token_info['timestamp']) > refresh_threshold:logger.info(f"没有获取到该账号{username}的token,或者token已过期,重新获取token中 当前时间为{time.time()} 时间间隔为{time.time() - token_info['timestamp']}")# 假设login_user是一个模拟的函数,实际应用中需要替换为真实的认证逻辑token = login_user(username, '222222').response.json()['data']['accessToken']tokens[username] = {'token': token, 'timestamp': time.time()}save_tokens_to_file(tokens, file_path)logger.info(f"{username}的token为{tokens[username]['token']}")return tokens[username]['token']return get_or_refresh_token这里还有个疑问,加上并发执行后,控制台打印的中文日志全变成了乱码,不明所以,后续有时间再看看怎么解决