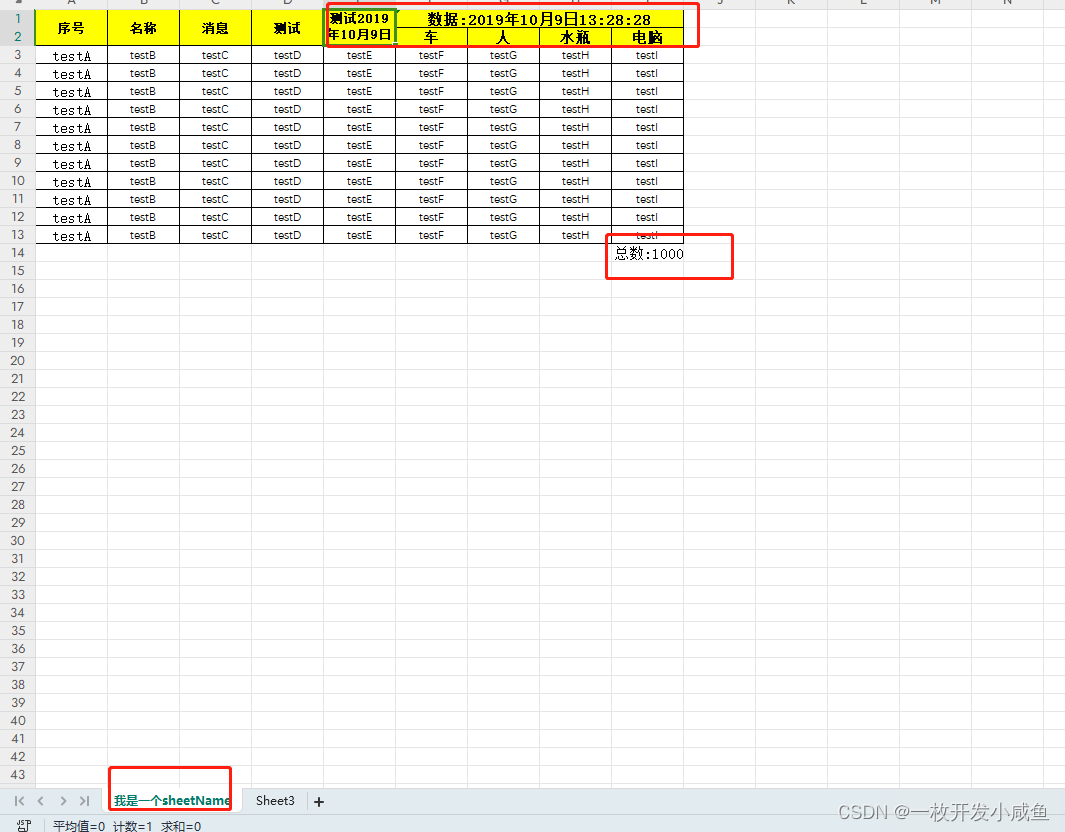
1.默认方式,其中加入文本过长,需要换行,因此做
content=html_output.replace('</style>','table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>'),添加换行操作
ps:当前text1输入是列表格式,返回是按照行形式(如果text1输入的是字符串,返回是按照列形式)
#coding:utf-8
import difflibtext1 = '''尊敬的韦尔总理、尊敬的汉恩党委书记、王省长、总领事、
女士们和先生们,
今天我非常高兴与你们共同庆祝40年的伙伴关系。'''.splitlines(keepends=True)
#
text2 = '''尊敬的韦尔总理,汉恩党委书记,王省长,总领事,
女士们,先生们,
今天我很高兴与你们一起庆祝四十年的伙伴关系。'''.splitlines(keepends=True)
html_diff = difflib.HtmlDiff()
html_output = html_diff.make_file(text1, text2)content=html_output.replace('</style>','table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>')
with open('diff_output_huanhang.html', 'w',encoding="utf-8") as fw:fw.write(content)案例展示:

2.方式1直接调用difflib.HtmlDiff()存在一个问题,在复杂场景下不能针对文本很好的比对(小伙伴们有好的方案可以推荐,当前输入字符串按列展示没有问题,但看着不舒服),因此使用diff_match_patch或者difflib.SequenceMatcher,进行修改,当前以diff_match_patch演示
#coding:utf-8
import diff_match_patch
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return contenthtml_cont = read("diff_baseline.html")text1 = '''尊敬的韦尔总理、汉恩党委书记、王省长、总领事、女士们和先生们,今天我非常高兴与你们共同庆祝40年的伙伴关系。我们作为AHK只做了三十年。我认为这是一个感谢前任的机会,他们为这种伙伴关系付出了很多努力。这种伙伴关系不仅存在于纸面上,还存在于实践中。我认为目前是我们塑造未来40年的关键时期,这可能比过去40年更加困难。因为中国在不断变化,所以我们设法找到并利用共同的潜力。今天政治领导人在这里向我们发出明确信号,即伙伴关系符合双方利益。我还要指出,总理。创新的公司表示愿意参与这个地区的发展,寻找并实施市场潜力。作为AHK,我们已经帮助了30年,同时我们在德国的组织和工商会也在尽我们所能支持德国公司。说话人E:我很高兴你今天发起了这个会议,我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,我相信我们都同意,未来40年只有我们继续好好交谈、合作、做生意才会越来越好。我祝愿所有与会者和会议取得圆满成功。谢谢。
'''
text2 = '''尊敬的韦尔总理,尊敬的汉恩党委书记,王省长,总领事,女士们,先生们,今天我很高兴与你们一起庆祝四十年的伙伴关系。我们作为ahk只做了三十年。尽管如此,我认为这也是一个很好的机会来感谢我们的前任,他们为这一伙伴关系付出了如此多的努力。这种伙伴关系不仅存在于纸面上,而且存在于实践中。我认为现在是我们塑造未来四十年的时候了,我认为这可能比过去四十年要困难一些。因为我们变了。中国变了。我们会不断地改变。然而,我们一次又一次地设法找到并利用共同的潜力。由于政治领导人今天在这里向我们发出了明确的信号,即伙伴关系符合我们双方的利益,我还要指出,你,总理,带来了创新的公司,他们表现出愿意参与这个地区,这个地区,寻找市场潜力,不仅谈论潜力,而且实施潜力。作为ahk,我们已经帮助了三十年,当然还有我们在德国的组织,工商会,尽我们所能支持德国公司。eben-partner to find。我很高兴你今天发起了这个会议,在那里我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,因为我相信我们都同意,未来四十年,只有我们继续好好交谈,好好合作,好好做生意,才会好起来。我祝愿所有与会者今天取得圆满成功,并祝愿会议取得圆满成功。谢谢,谢谢
'''
dmp = diff_match_patch.diff_match_patch()
diffs = dmp.diff_main(text1, text2)
print(diffs)
a="<td>"
b="<td>"
for i in diffs:if i[0]==0:a+=i[1]b+=i[1]if i[0]==-1:a+='<span class="diff_chg">{}</span>'.format(i[1])if i[0]==1:b+='<span class="diff_chg">{}</span>'.format(i[1])
a+="</td>"
b+="</td>"one='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)样例展示:

构建html格式
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><meta http-equiv="Content-Type"content="text/html; charset=utf-8" /><title></title><style type="text/css">table.diff {font-family:Courier; border:medium;}.diff_header {background-color:#e0e0e0}td.diff_header {text-align:right}.diff_next {background-color:#c0c0c0}.diff_add {background-color:#aaffaa}.diff_chg {background-color:#ffff77}.diff_sub {background-color:#ffaaaa}table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>
</head><body><table class="diff" id="difflib_chg_to0__top"cellspacing="0" cellpadding="0" rules="groups" ><colgroup></colgroup> <colgroup></colgroup> <colgroup></colgroup><colgroup></colgroup> <colgroup></colgroup> <colgroup></colgroup><tbody></tbody></table><table class="diff" summary="Legends"><tr> <th colspan="2"> Legends </th> </tr><tr> <td> <table border="" summary="Colors"><tr><th> Colors </th> </tr><tr><td class="diff_add"> Added </td></tr><tr><td class="diff_chg">Changed</td> </tr><tr><td class="diff_sub">Deleted</td> </tr></table></td><td> <table border="" summary="Links"><tr><th colspan="2"> Links </th> </tr><tr><td>(f)irst change</td> </tr><tr><td>(n)ext change</td> </tr><tr><td>(t)op</td> </tr></table></td> </tr></table>
</body></html>3.当前以difflib.SequenceMatcher演示
#coding:utf-8
import difflib, re
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return content
html_cont = read("diff_baseline.html")
# 比较两个文本差异点
def compare_text_index(text1, text2):# 创建SequenceMatcher对象matcher = difflib.SequenceMatcher(a=text1, b=text2)# 获取差异报告diff_report = matcher.get_opcodes()index_info=[]# 检查差异报告中是否存在关键词错误for tag, i1, i2, j1, j2 in diff_report:index_info.append([tag, i1, i2, j1, j2])return index_infotext1 = '''尊敬的韦尔总理、汉恩党委书记、王省长、总领事、女士们和先生们,今天我非常高兴与你们共同庆祝40年的伙伴关系。我们作为AHK只做了三十年。我认为这是一个感谢前任的机会,他们为这种伙伴关系付出了很多努力。这种伙伴关系不仅存在于纸面上,还存在于实践中。我认为目前是我们塑造未来40年的关键时期,这可能比过去40年更加困难。因为中国在不断变化,所以我们设法找到并利用共同的潜力。今天政治领导人在这里向我们发出明确信号,即伙伴关系符合双方利益。我还要指出,总理。创新的公司表示愿意参与这个地区的发展,寻找并实施市场潜力。作为AHK,我们已经帮助了30年,同时我们在德国的组织和工商会也在尽我们所能支持德国公司。说话人E:我很高兴你今天发起了这个会议,我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,我相信我们都同意,未来40年只有我们继续好好交谈、合作、做生意才会越来越好。我祝愿所有与会者和会议取得圆满成功。谢谢。
'''text2 = '''尊敬的韦尔总理,尊敬的汉恩党委书记,王省长,总领事,女士们,先生们,今天我很高兴与你们一起庆祝四十年的伙伴关系。我们作为ahk只做了三十年。尽管如此,我认为这也是一个很好的机会来感谢我们的前任,他们为这一伙伴关系付出了如此多的努力。这种伙伴关系不仅存在于纸面上,而且存在于实践中。我认为现在是我们塑造未来四十年的时候了,我认为这可能比过去四十年要困难一些。因为我们变了。中国变了。我们会不断地改变。然而,我们一次又一次地设法找到并利用共同的潜力。由于政治领导人今天在这里向我们发出了明确的信号,即伙伴关系符合我们双方的利益,我还要指出,你,总理,带来了创新的公司,他们表现出愿意参与这个地区,这个地区,寻找市场潜力,不仅谈论潜力,而且实施潜力。作为ahk,我们已经帮助了三十年,当然还有我们在德国的组织,工商会,尽我们所能支持德国公司。eben-partner to find。我很高兴你今天发起了这个会议,在那里我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,因为我相信我们都同意,未来四十年,只有我们继续好好交谈,好好合作,好好做生意,才会好起来。我祝愿所有与会者今天取得圆满成功,并祝愿会议取得圆满成功。谢谢,谢谢
'''
a="<td>"
b="<td>"
chayi=compare_text_index(text1, text2)
for effect in chayi:print(effect)if effect[0]=="equal":a+=text1[effect[1]:effect[2]]b+=text2[effect[3]:effect[4]]if effect[0]=="replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a+='<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0]=="insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0]=="delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a+="</td>"
b+="</td>"one='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('difflib_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)
案例展示:

4.同理将多个文本按行比对:
#coding:utf-8
import diff_match_patch
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return contenthtml_cont = read("diff_baseline.html")text11 = read("text1.txt").splitlines(keepends=True)text22 = read("text2.txt").splitlines(keepends=True)one=""
for id,text1 in enumerate(text11):text2=text22[id]dmp = diff_match_patch.diff_match_patch()diffs = dmp.diff_main(text1, text2)if id==0:a="<td>"b="<td>"for i in diffs:if i[0]==0:a+=i[1]b+=i[1]if i[0]==-1:a+='<span class="diff_chg">{}</span>'.format(i[1])if i[0]==1:b+='<span class="diff_chg">{}</span>'.format(i[1])a+="</td>"b+="</td>"print(a)print(b)one+='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)if id>0:a = "<td>"b = "<td>"for i in diffs:if i[0] == 0:a += i[1]b += i[1]if i[0] == -1:a += '<span class="diff_chg">{}</span>'.format(i[1])if i[0] == 1:b += '<span class="diff_chg">{}</span>'.format(i[1])a += "</td>"b += "</td>"print(a)print(b)one += '<tr><td class="diff_next"></td><td class="diff_header" id="from0_{}">{}</td>{}<td class="diff_next"></td><td class="diff_header" id="to0_{}">{}</td>{}</tr>'.format(id+1,id+1,a,id+1,id+1, b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output1.html', 'w', encoding='utf-8') as f:f.write(html_cont)#coding:utf-8
import diff_match_patch,difflib
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return content
# 比较两个文本差异点
def compare_text_index(text1, text2):# 创建SequenceMatcher对象matcher = difflib.SequenceMatcher(a=text1, b=text2)# 获取差异报告diff_report = matcher.get_opcodes()index_info=[]# 检查差异报告中是否存在关键词错误for tag, i1, i2, j1, j2 in diff_report:index_info.append([tag, i1, i2, j1, j2])return index_infohtml_cont = read("diff_baseline.html")text11 = read("text1.txt").splitlines(keepends=True)text22 = read("text2.txt").splitlines(keepends=True)one=""
for id,text1 in enumerate(text11):text2=text22[id]chayi=compare_text_index(text1, text2)if id==0:a="<td>"b="<td>"for effect in chayi:print(effect)if effect[0] == "equal":a += text1[effect[1]:effect[2]]b += text2[effect[3]:effect[4]]if effect[0] == "replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a+="</td>"b+="</td>"print(a)print(b)one+='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)if id>0:a = "<td>"b = "<td>"for effect in chayi:print(effect)if effect[0] == "equal":a += text1[effect[1]:effect[2]]b += text2[effect[3]:effect[4]]if effect[0] == "replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a += "</td>"b += "</td>"print(a)print(b)one += '<tr><td class="diff_next"></td><td class="diff_header" id="from0_{}">{}</td>{}<td class="diff_next"></td><td class="diff_header" id="to0_{}">{}</td>{}</tr>'.format(id+1,id+1,a,id+1,id+1, b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)