一、背景
团队在升级大数据架构
前端使用trino查询,对trino也进行了很多优化,目前测试来看,运行还算稳定,但是不可避免的trino的任务总会出现失败的情况。原来的架构是trino失败后去跑hive,而hive是跑mapreduce依赖于hadoop,新架构摒弃了hadoop,当然也没法用hive跑了,因此目前看较好的办法是使用spark sql来替代。
在初次研究了spark sql,发现没有能实时返回数据的方式,spark更着重于执行任务处理,而对于客户端交互没有很好的支持。在搜索了大量资料及chatgpt的帮助下,找到了用kyuubi驱动sparksql来与客户端交互的方法。网上关于kyuubi集成spark的文章大多只讲了spark和kyuubi的配置,配置完成执行一个spark demo就算完了,没有精准的实际案例,导致对这个集成没有一个整体的概念,有些无从下手,下面我会先讲清楚kyuubi jdbc获取数据的流程。当然过程中也遇到大量的问题,在研究了大概一周左右的时间,终于将kyuubi驱动spark到k8s跑spark sql,并访问rest catalog的iceberg的数据走通了,在此记录并分享给大家!
二、目前架构
略。参考我另一篇文章
【大数据架构】基于流式数据的大数据架构升级-CSDN博客
三、版本介绍
| 组件名称 | 版本 |
| Iceberg | 1.5.0 |
| Spark | 3.5.0 |
| Kyuubi | 1.9.0 |
四、数据流介绍
Trino执行失败 >>> 访问Kyuubi Jdbc >>> Spark engine 提交spark任务到k8s >>> Spark读取iceberg元数据 >>> spark访问Minio读取数据并计算 >>> 返回数据到Kyuubi
这里讲一下kyuubi集成spark后是怎么通过kyuubi jdbc返回sql数据的。
1)首先kyuubi基于thrfit协议i创建了thrift jdbc server,同时kyuubi集成了spark的引擎,可以调用spark submit提交任务。那么从客户端到kyuubi再到spark执行sql就通了。
2)kyuubi使用spark引擎调用spark需要spark环境,因此在kyuubi中需要有一个spark环境,因此在本地需要装一个spark
3)kyuubi调用spark后执行任务,spark会使用spark submit将任务发送到本地,k8s,或yarn上面执行,这就用到了spark的动态调度特性
4)本例需要将spark发布到k8s执行,因此需要一个在k8s上能执行spark sql的镜像
5)其他环境:本例中存在一个基于iceberg的Rest catalog,数据和metadata存储在minio上,spark执行sql需要访问Rest Catalog,再去Minio取数据。访问Minio需要相应的access_key,secret_key,还有证书。以上这些都是已经存在了,需要在环境中或者配置中配好的。
下面正式开始集成。
五、spark安装及配置
1.首先下载spark程序,可以去官网下载,最新版是3.5.1,我下载的是3.5.0
https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
2.上传到服务器解压
查看conf文件夹是这样的,其中是没有spark-env.sh和spark-defaults.conf
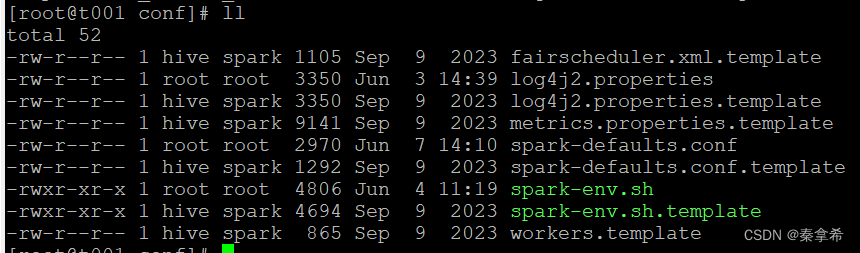
copy这两个配置文件
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf3.如果有环境变量,可以设置到spark-env.sh中,spark-env.sh的内容是这样的,我是暂时没有配置
#!/usr/bin/env bash#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos# Options read in any mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)# Options read in any cluster manager using HDFS
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files# Options read in YARN client/cluster mode
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers# Options for launcher
# - SPARK_LAUNCHER_OPTS, to set config properties and Java options for the launcher (e.g. "-Dx=y")# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_LOG_MAX_FILES Max log files of Spark daemons can rotate to. Default is 5.
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS# Options for beeline
# - SPARK_BEELINE_OPTS, to set config properties only for the beeline cli (e.g. "-Dx=y")
# - SPARK_BEELINE_MEMORY, Memory for beeline (e.g. 1000M, 2G) (Default: 1G)4. 配置spark-defaults.conf,我的完整配置如下。
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.# Example:#k8s地址spark.master k8s://https://10.38.199.201:443/k8s/clusters/c-m-l7gflsx7spark.eventLog.enabled true#minio地址spark.eventLog.dir s3a://wux-hoo-dev-01/ice_warehousespark.hadoop.fs.s3a.impl org.apache.hadoop.fs.s3a.S3AFileSystemspark.hadoop.fs.s3a.access.key ******r5KpXkzEW2jNKWspark.hadoop.fs.s3a.secret.key ******hDYtuzsDnKGLGg9EJSbJ083ekuW7PejM#minio的endpointspark.hadoop.fs.s3a.endpoint http://XXX.com:30009spark.hadoop.fs.s3a.path.style.access truespark.hadoop.fs.s3a.aws.region=us-east-1spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystemspark.sql.catalog.default spark_catalogspark.sql.catalog.spark_catalog org.apache.iceberg.spark.SparkCatalogspark.sql.catalog.spark_catalog.type rest#spark.sql.catalog.spark_catalog.catalog-impl org.apache.iceberg.rest.RESTCatalogspark.sql.catalog.spark_catalog.uri http://10.40.8.42:31000spark.sql.extensions org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensionsspark.sql.catalog.spark_catalog.io-impl org.apache.iceberg.aws.s3.S3FileIOspark.sql.catalog.spark_catalog.warehouse s3a://wux-hoo-dev-01/ice_warehousespark.sql.catalog.spark_catalog.s3.endpoint http://XXXXX.com:30009spark.sql.catalog.spark_catalog.s3.path-style-access truespark.sql.catalog.spark_catalog.s3.access-key-id ******5KpXkzEW2jNKWspark.sql.catalog.spark_catalog.s3.secret-access-key ******hDYtuzsDnKGLGg9EJSbJ083ekuW7PejMspark.sql.catalog.spark_catalog.region us-east-1#spark镜像harbor地址spark.kubernetes.container.image 10.38.199.203:1443/fhc/spark350:v1.0spark.kubernetes.namespace defaultspark.kubernetes.authenticate.driver.serviceAccountName sparkspark.kubernetes.container.image.pullPolicy Alwaysspark.submit.deployMode clusterspark.kubernetes.file.upload.path s3a://wux-hoo-dev-01/ice_warehouse
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"a)因为我是需要将spark sql提交到k8s上的,所以spark sql提交模式是cluster,然后配置k8s的路径。
b)其次我需要访问minio,需要配置minio访问的参数,spark.hadoop.fs.s3a的这一段
c)然后我访问mino是通过iceberg的,我创建了一个iceberg的rest catalog,地址是http://10.40.8.42:31000,所以要定义一个spark catalog,这些参数也需要加上
d)然后因为需要将spark sql提交到k8s上,需要一个spark环境的image,在创建pod的时候加载spark环境,所以要打一个spark运行环境的镜像 10.38.199.203:1443/fhc/spark350:v1.0
六、kyuubi部署配置
1.下载kyuubi,我下载的是1.9.0
2.上传到服务器,解压
查看conf文件夹是这样的,其中是没有kyuubi-env.sh和kyuubi-defaults.conf

copy这两个文件
cp kyuubi-env.sh.template kyuubi-env.sh
cp kyuubi-defaults.conf.template kyuubi-defaults.conf3.配置kyuubi-env.sh,我的完整配置如下,主要配置java home,spark home,还有kyuuni启动参数
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
#
# - JAVA_HOME Java runtime to use. By default use "java" from PATH.
#
#
# - KYUUBI_CONF_DIR Directory containing the Kyuubi configurations to use.
# (Default: $KYUUBI_HOME/conf)
# - KYUUBI_LOG_DIR Directory for Kyuubi server-side logs.
# (Default: $KYUUBI_HOME/logs)
# - KYUUBI_PID_DIR Directory stores the Kyuubi instance pid file.
# (Default: $KYUUBI_HOME/pid)
# - KYUUBI_MAX_LOG_FILES Maximum number of Kyuubi server logs can rotate to.
# (Default: 5)
# - KYUUBI_JAVA_OPTS JVM options for the Kyuubi server itself in the form "-Dx=y".
# (Default: none).
# - KYUUBI_CTL_JAVA_OPTS JVM options for the Kyuubi ctl itself in the form "-Dx=y".
# (Default: none).
# - KYUUBI_BEELINE_OPTS JVM options for the Kyuubi BeeLine in the form "-Dx=Y".
# (Default: none)
# - KYUUBI_NICENESS The scheduling priority for Kyuubi server.
# (Default: 0)
# - KYUUBI_WORK_DIR_ROOT Root directory for launching sql engine applications.
# (Default: $KYUUBI_HOME/work)
# - HADOOP_CONF_DIR Directory containing the Hadoop / YARN configuration to use.
# - YARN_CONF_DIR Directory containing the YARN configuration to use.
#
# - SPARK_HOME Spark distribution which you would like to use in Kyuubi.
# - SPARK_CONF_DIR Optional directory where the Spark configuration lives.
# (Default: $SPARK_HOME/conf)
# - FLINK_HOME Flink distribution which you would like to use in Kyuubi.
# - FLINK_CONF_DIR Optional directory where the Flink configuration lives.
# (Default: $FLINK_HOME/conf)
# - FLINK_HADOOP_CLASSPATH Required Hadoop jars when you use the Kyuubi Flink engine.
# - HIVE_HOME Hive distribution which you would like to use in Kyuubi.
# - HIVE_CONF_DIR Optional directory where the Hive configuration lives.
# (Default: $HIVE_HOME/conf)
# - HIVE_HADOOP_CLASSPATH Required Hadoop jars when you use the Kyuubi Hive engine.
### Examples ##export JAVA_HOME=/root/zulu11.52.13-ca-jdk11.0.13-linux_x64export SPARK_HOME=/root/spark-3.5.0-bin-hadoop3
# export FLINK_HOME=/opt/flink
# export HIVE_HOME=/opt/hive
# export FLINK_HADOOP_CLASSPATH=/path/to/hadoop-client-runtime-3.3.2.jar:/path/to/hadoop-client-api-3.3.2.jar
# export HIVE_HADOOP_CLASSPATH=${HADOOP_HOME}/share/hadoop/common/lib/commons-collections-3.2.2.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-runtime-3.1.0.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-api-3.1.0.jar:${HADOOP_HOME}/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar
# export HADOOP_CONF_DIR=/usr/ndp/current/mapreduce_client/conf
# export YARN_CONF_DIR=/usr/ndp/current/yarn/confexport KYUUBI_JAVA_OPTS="-Xmx10g -XX:MaxMetaspaceSize=512m -XX:MaxDirectMemorySize=1024m -XX:+UseG1GC -XX:+UseStringDeduplication -XX:+UnlockDiagnosticVMOptions -XX:+UseCondCardMark -XX:+UseGCOverheadLimit -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -verbose:gc -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=20M"export KYUUBI_BEELINE_OPTS="-Xmx2g -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+UseCondCardMark"4.配置kyuubi-defaults.conf,我的配置如下,基本上把spark-defaults.conf搬一份过来
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
### Kyuubi Configurations#
# kyuubi.authentication NONE
#kyuubi.frontend.bind.host 10.38.199.201
# kyuubi.frontend.protocols THRIFT_BINARY,REST
# kyuubi.frontend.thrift.binary.bind.port 10009kyuubi.frontend.rest.bind.port 10099
#kyuubi.engine.type SPARK_SQL
# kyuubi.engine.share.level USER
# kyuubi.session.engine.initialize.timeout PT3M
#
# kyuubi.ha.addresses zk1:2181,zk2:2181,zk3:2181
# kyuubi.ha.namespace kyuubi
#spark.master=k8s://https://10.38.199.201:443/k8s/clusters/c-m-l7gflsx7
spark.home=/root/spark-3.5.0-bin-hadoop3spark.hadoop.fs.s3a.access.key=******5KpXkzEW2jNKW
spark.hadoop.fs.s3a.secret.key=******hDYtuzsDnKGLGg9EJSbJ083ekuW7PejM
spark.hadoop.fs.s3a.endpoint=http://XXXXX.com:30009
spark.hadoop.fs.s3a.path.style.access=true
spark.hadoop.fs.s3a.aws.region=us-east-1
spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystemspark.sql.catalog.default=spark_catalog
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.spark_catalog.type=rest
#spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.rest.RESTCatalog
spark.sql.catalog.spark_catalog.uri=http://10.40.8.42:31000
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO
spark.sql.catalog.spark_catalog.warehouse=s3a://wux-hoo-dev-01/ice_warehouse
spark.sql.catalog.spark_catalog.s3.endpoint=http://XXXXX.com:30009
spark.sql.catalog.spark_catalog.s3.path-style-access=true
spark.sql.catalog.spark_catalog.s3.access-key-id=******r5KpXkzEW2jNKW
spark.sql.catalog.spark_catalog.s3.secret-access-key=******AhDYtuzsDnKGLGg9EJSbJ083ekuW7PejM
spark.sql.catalog.spark_catalog.region=us-east-1spark.kubernetes.container.image=10.38.199.203:1443/fhc/spark350:v1.0
spark.kubernetes.namespace=default
spark.kubernetes.authenticate.driver.serviceAccountName=spark
# Details in https://kyuubi.readthedocs.io/en/master/configuration/settings.html七、spark运行环境镜像打包
这一步是最花时间的,因为打镜像后联调测试的时候,在kyuubi控制台执行spark sql,各种no class found,就是在spark镜像的环境中缺少各种jar包,其中最主要的包是amzon的jar。我是有一个错解决一个,把需要的jar下载下来打进去,一共打了大概31个jar吧。
Dockfile如下
from apache/spark:3.5.0RUN setUSER root#这个是minio访问的证书,如果是hdfs或者其他存储或没有证书的,不需要打进去
ADD SeagateCA02.cer /tmpCOPY awsicelib/ /opt/spark/jars#将minio证书导入到java环境
RUN keytool -import -keystore /opt/java/openjdk/lib/security/cacerts -storepass changeit -noprompt -alias seagateca -file /tmp/SeagateCA02.cerRUN ls /opt/spark/jarsENV SPARK_HOME=/opt/sparkENV AWS_REGION=us-east-1awsicelib/ 下面存储了所有调试报错后下载的jar
大概如下,我会把它打个zip包供下载,当然下载遇到困难的,可可以单独去maven仓库下,我都是到maven仓库下载的
资源包在这 https://download.csdn.net/download/w8998036/89410068

jar名称
-rw-r--r-- 1 root root 74757 Jun 7 10:34 apache-client-2.25.65.jar
-rw-r--r-- 1 root root 232047 Jun 7 09:26 auth-2.25.65.jar
-rw-r--r-- 1 root root 165024 Jun 6 16:47 aws-core-2.25.65.jar
-rw-r--r-- 1 root root 280645251 Jun 6 10:56 aws-java-sdk-bundle-1.12.262.jar
-rw-r--r-- 1 root root 115052 Jun 7 11:50 aws-json-protocol-2.25.65.jar
-rw-r--r-- 1 root root 68117 Jun 7 15:12 aws-query-protocol-2.25.65.jar
-rw-r--r-- 1 root root 101435 Jun 7 15:03 aws-xml-protocol-2.25.65.jar
-rw-r--r-- 1 root root 9341 Jun 7 15:16 checksums-2.25.65.jar
-rw-r--r-- 1 root root 8047 Jun 7 15:27 checksums-spi-2.25.65.jar
-rw-r--r-- 1 root root 2819073 Jun 7 14:50 dynamodb-2.25.65.jar
-rw-r--r-- 1 root root 13170 Jun 7 10:49 endpoints-spi-2.25.65.jar
-rw-r--r-- 1 root root 6786696 Jun 7 10:15 glue-2.25.65.jar
-rw-r--r-- 1 root root 962685 Jun 6 10:55 hadoop-aws-3.3.4.jar
-rw-r--r-- 1 root root 17476 Jun 7 11:02 http-auth-2.25.65.jar
-rw-r--r-- 1 root root 211391 Jun 7 10:58 http-auth-aws-2.25.65.jar
-rw-r--r-- 1 root root 44434 Jun 7 10:54 http-auth-spi-2.25.65.jar
-rw-r--r-- 1 root root 84134 Jun 7 09:51 http-client-spi-2.25.65.jar
-rw-r--r-- 1 root root 41601849 Jun 6 16:14 iceberg-spark-runtime-3.5_2.12-1.5.0.jar
-rw-r--r-- 1 root root 30965 Jun 7 09:34 identity-spi-2.25.65.jar
-rw-r--r-- 1 root root 30943 Jun 7 11:50 json-utils-2.25.65.jar
-rw-r--r-- 1 root root 1502321 Jun 7 14:32 kms-2.25.65.jar
-rw-r--r-- 1 root root 27267 Jun 7 14:58 metrics-spi-2.25.65.jar
-rw-r--r-- 1 root root 49524 Jun 7 10:38 profiles-2.25.65.jar
-rw-r--r-- 1 root root 35145 Jun 7 11:50 protocol-core-2.25.65.jar
-rw-r--r-- 1 root root 11640 Jun 7 11:31 reactive-streams-1.0.4.jar
-rw-r--r-- 1 root root 860193 Jun 7 10:23 regions-2.25.65.jar
-rw-r--r-- 1 root root 3578525 Jun 6 16:41 s3-2.25.65.jar
-rw-r--r-- 1 root root 900547 Jun 7 09:10 sdk-core-2.25.65.jar
-rw-r--r-- 1 root root 506301 Jun 7 09:56 sts-2.25.65.jar
-rw-r--r-- 1 root root 535001 Jun 7 13:26 third-party-jackson-core-2.25.65.jar
-rw-r--r-- 1 root root 218521 Jun 7 09:39 utils-2.25.65.jar
这一步的错误贴几个,就是在kyuubi控制台执行sql的时候出现的


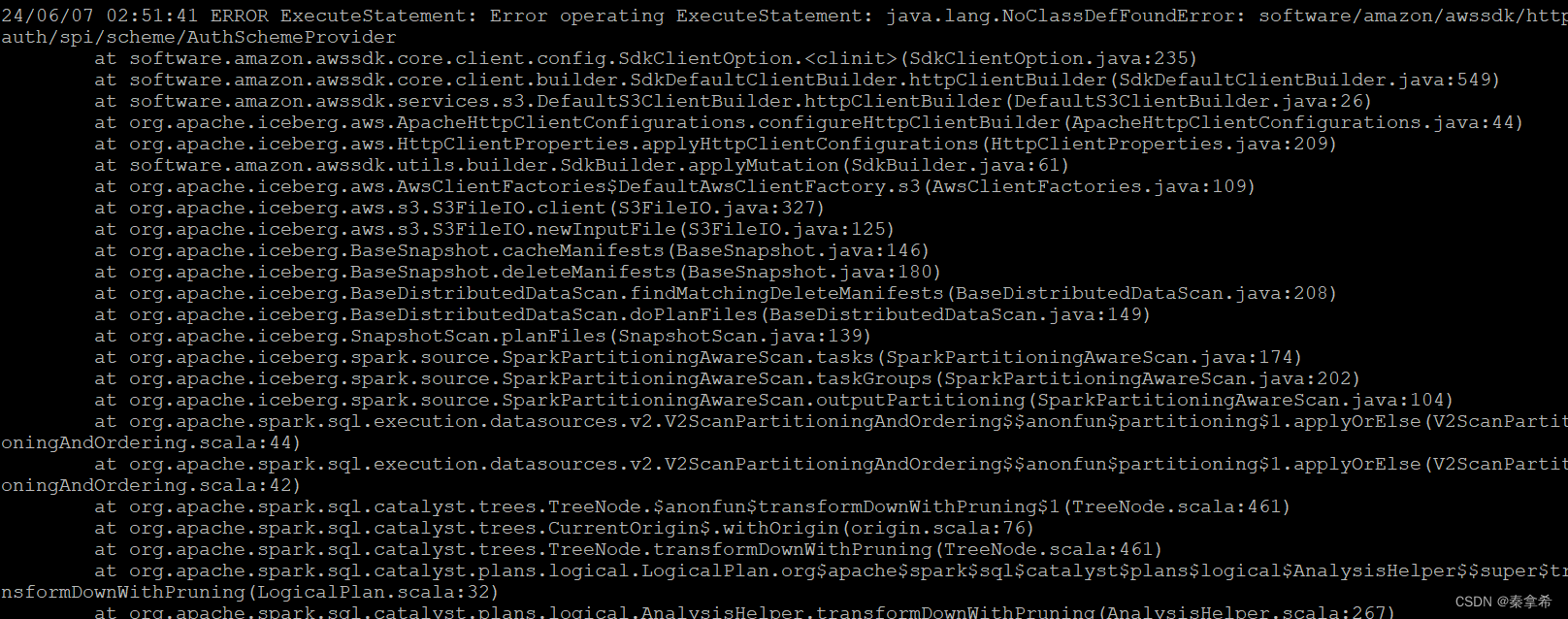
其次还要注意下载的包的版本,spark3.5.0镜像里面用的scale版本是2.12,下载包的时候如果有版本的问题要注意一下。
镜像打包完成 10.38.199.203:1443/fhc/spark350:v1.0,在spark配置文件中引用它
八、测试kyuubi执行spark sql
cd到kyuubi home目录,执行命令jdbc:hive2://10.38.199.201:10009。
bin/beeline -u 'jdbc:hive2://10.38.199.201:10009'第一次执行会比较慢,控制台会打印出spark pod(driver和executor)构建过程,打印出的log如下
[root@t001 apache-kyuubi-1.9.0-bin]# bin/beeline -u 'jdbc:hive2://10.38.199.201:10009'
Connecting to jdbc:hive2://10.38.199.201:10009
2024-06-07 20:16:50.252 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.operaunchEngine: Processing anonymous's query[1b721771-c943-45f5-ab31-384652d151b9]: PENDING_STATENING_STATE, statement:
LaunchEngine
2024-06-07 20:16:50.255 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.shadtor.framework.imps.CuratorFrameworkImpl: Starting
2024-06-07 20:16:50.256 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.shadeeper.ZooKeeper: Initiating client connection, connectString=10.38.199.201:2181 sessionTimeoutwatcher=org.apache.kyuubi.shaded.curator.ConnectionState@62306c2b
2024-06-07 20:16:50.259 INFO KyuubiSessionManager-exec-pool: Thread-407-SendThread(t001:2181) che.kyuubi.shaded.zookeeper.ClientCnxn: Opening socket connection to server t001/10.38.199.201Will not attempt to authenticate using SASL (unknown error)
2024-06-07 20:16:50.262 INFO KyuubiSessionManager-exec-pool: Thread-407-SendThread(t001:2181) che.kyuubi.shaded.zookeeper.ClientCnxn: Socket connection established to t001/10.38.199.201:21tiating session
2024-06-07 20:16:50.269 INFO KyuubiSessionManager-exec-pool: Thread-407-SendThread(t001:2181) che.kyuubi.shaded.zookeeper.ClientCnxn: Session establishment complete on server t001/10.38.19181, sessionid = 0x100dd6b3d350015, negotiated timeout = 60000
2024-06-07 20:16:50.269 INFO KyuubiSessionManager-exec-pool: Thread-407-EventThread org.apache.shaded.curator.framework.state.ConnectionStateManager: State change: CONNECTED
2024-06-07 20:16:50.309 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.engiBuilder: Logging to /root/kyuubi/apache-kyuubi-1.9.0-bin/work/anonymous/kyuubi-spark-sql-engin
2024-06-07 20:16:50.310 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.Utiling Kyuubi properties from /root/spark-3.5.0-bin-hadoop3/conf/spark-defaults.conf
2024-06-07 20:16:50.314 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.engineRef: Launching engine:
/root/spark-3.5.0-bin-hadoop3/bin/spark-submit \--class org.apache.kyuubi.engine.spark.SparkSQLEngine \--conf spark.hive.server2.thrift.resultset.default.fetch.size=1000 \--conf spark.kyuubi.client.ipAddress=10.38.199.201 \--conf spark.kyuubi.client.version=1.9.0 \--conf spark.kyuubi.engine.engineLog.path=/root/kyuubi/apache-kyuubi-1.9.0-bin/work/an/kyuubi-spark-sql-engine.log.9 \--conf spark.kyuubi.engine.submit.time=1717762610303 \--conf spark.kyuubi.engine.type=SPARK_SQL \--conf spark.kyuubi.ha.addresses=10.38.199.201:2181 \--conf spark.kyuubi.ha.engine.ref.id=2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d \--conf spark.kyuubi.ha.namespace=/kyuubi_1.9.0_USER_SPARK_SQL/anonymous/default \--conf spark.kyuubi.ha.zookeeper.auth.type=NONE \--conf spark.kyuubi.server.ipAddress=10.38.199.201 \--conf spark.kyuubi.session.connection.url=10.38.199.201:10009 \--conf spark.kyuubi.session.real.user=anonymous \--conf spark.app.name=kyuubi_USER_SPARK_SQL_anonymous_default_2b3ce304-7f0d-455e-bffd-d3c3d \--conf spark.hadoop.fs.s3a.access.key=apPeWWr5KpXkzEW2jNKW \--conf spark.hadoop.fs.s3a.aws.region=us-east-1 \--conf spark.hadoop.fs.s3a.endpoint=http://wuxdihadl01b.seagate.com:30009 \--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \--conf spark.hadoop.fs.s3a.path.style.access=true \--conf spark.hadoop.fs.s3a.secret.key=cRt3inWAhDYtuzsDnKGLGg9EJSbJ083ekuW7PejM \--conf spark.home=/root/spark-3.5.0-bin-hadoop3 \--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \--conf spark.kubernetes.container.image=10.38.199.203:1443/fhc/spark350:v1.0 \--conf spark.kubernetes.driver.label.kyuubi-unique-tag=2b3ce304-7f0d-455e-bffd-e2e7df1--conf spark.kubernetes.driver.pod.name=kyuubi-user-spark-sql-anonymous-default-2b3ce3-455e-bffd-e2e7df1d3c3d-driver \--conf spark.kubernetes.executor.podNamePrefix=kyuubi-user-spark-sql-anonymous-default04-7f0d-455e-bffd-e2e7df1d3c3d \--conf spark.kubernetes.namespace=default \--conf spark.master=k8s://https://10.38.199.201:443/k8s/clusters/c-m-l7gflsx7 \--conf spark.sql.catalog.default=spark_catalog \--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO \--conf spark.sql.catalog.spark_catalog.region=us-east-1 \--conf spark.sql.catalog.spark_catalog.s3.access-key-id=apPeWWr5KpXkzEW2jNKW \--conf spark.sql.catalog.spark_catalog.s3.endpoint=http://wuxdihadl01b.seagate.com:300--conf spark.sql.catalog.spark_catalog.s3.path-style-access=true \--conf spark.sql.catalog.spark_catalog.s3.secret-access-key=cRt3inWAhDYtuzsDnKGLGg9EJSuW7PejM \--conf spark.sql.catalog.spark_catalog.type=rest \--conf spark.sql.catalog.spark_catalog.uri=http://10.40.8.42:31000 \--conf spark.sql.catalog.spark_catalog.warehouse=s3a://wux-hoo-dev-01/ice_warehouse \--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExt \--conf spark.kubernetes.driverEnv.SPARK_USER_NAME=anonymous \--conf spark.executorEnv.SPARK_USER_NAME=anonymous \--proxy-user anonymous /root/kyuubi/apache-kyuubi-1.9.0-bin/externals/engines/spark/kyark-sql-engine_2.12-1.9.0.jar
24/06/07 20:16:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platforing builtin-java classes where applicable
24/06/07 20:16:54 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using currentt from users K8S config file
24/06/07 20:16:55 WARN DriverServiceFeatureStep: Driver's hostname would preferably be kyuubi-ark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d-25e50e8ff2a16310-driver-svc, buis too long (must be <= 63 characters). Falling back to use spark-b043ef8ff2a1691d-driver-svc driver service's name.
24/06/07 20:16:55 INFO KerberosConfDriverFeatureStep: You have not specified a krb5.conf file or via a ConfigMap. Make sure that you have the krb5.conf locally on the driver image.
24/06/07 20:16:56 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-ftem.properties,hadoop-metrics2.properties
24/06/07 20:16:56 INFO MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
24/06/07 20:16:56 INFO MetricsSystemImpl: s3a-file-system metrics system started
24/06/07 20:16:57 INFO KubernetesUtils: Uploading file: /root/kyuubi/apache-kyuubi-1.9.0-bin/es/engines/spark/kyuubi-spark-sql-engine_2.12-1.9.0.jar to dest: s3a://wux-hoo-dev-01/ice_warehark-upload-e2c1f98d-0612-4ea8-9645-7ddebbae8afc/kyuubi-spark-sql-engine_2.12-1.9.0.jar...
24/06/07 20:16:58 INFO KubernetesClientUtils: Spark configuration files loaded from Some(/root3.5.0-bin-hadoop3/conf) : spark-env.sh,log4j2.properties
24/06/07 20:16:59 INFO LoggingPodStatusWatcherImpl: State changed, new state:pod name: kyuubi-user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd-e2e7df1d3c3rnamespace: defaultlabels: kyuubi-unique-tag -> 2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d, spark-app-name -> user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd, spark-app-selector -> spark-a6876b8c5b87f15a03bc8959a, spark-role -> driver, spark-version -> 3.5.0pod uid: 7826bf25-67a5-4c84-b98e-7239f999a368creation time: 2024-06-07T12:16:59Zservice account name: sparkvolumes: spark-local-dir-1, spark-conf-volume-driver, kube-api-access-rw6gmnode name: t009start time: 2024-06-07T12:16:59Zphase: Pendingcontainer status:container name: spark-kubernetes-drivercontainer image: 10.38.199.203:1443/fhc/spark350:v1.0container state: waitingpending reason: ContainerCreating
24/06/07 20:16:59 INFO LoggingPodStatusWatcherImpl: State changed, new state:pod name: kyuubi-user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd-e2e7df1d3c3rnamespace: defaultlabels: kyuubi-unique-tag -> 2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d, spark-app-name -> user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd, spark-app-selector -> spark-a6876b8c5b87f15a03bc8959a, spark-role -> driver, spark-version -> 3.5.0pod uid: 7826bf25-67a5-4c84-b98e-7239f999a368creation time: 2024-06-07T12:16:59Zservice account name: sparkvolumes: spark-local-dir-1, spark-conf-volume-driver, kube-api-access-rw6gmnode name: t009start time: 2024-06-07T12:16:59Zphase: Pendingcontainer status:container name: spark-kubernetes-drivercontainer image: 10.38.199.203:1443/fhc/spark350:v1.0container state: waitingpending reason: ContainerCreating
24/06/07 20:16:59 INFO LoggingPodStatusWatcherImpl: Waiting for application kyuubi_USER_SPARK_nymous_default_2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d with application ID spark-a6876b8c2ebe48a503bc8959a and submission ID default:kyuubi-user-spark-sql-anonymous-default-2b3ce304-7f0d-455e2e7df1d3c3d-driver to finish...
24/06/07 20:17:00 INFO LoggingPodStatusWatcherImpl: State changed, new state:pod name: kyuubi-user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd-e2e7df1d3c3rnamespace: defaultlabels: kyuubi-unique-tag -> 2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d, spark-app-name -> user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd, spark-app-selector -> spark-a6876b8c5b87f15a03bc8959a, spark-role -> driver, spark-version -> 3.5.0pod uid: 7826bf25-67a5-4c84-b98e-7239f999a368creation time: 2024-06-07T12:16:59Zservice account name: sparkvolumes: spark-local-dir-1, spark-conf-volume-driver, kube-api-access-rw6gmnode name: t009start time: 2024-06-07T12:16:59Zphase: Pendingcontainer status:container name: spark-kubernetes-drivercontainer image: 10.38.199.203:1443/fhc/spark350:v1.0container state: waitingpending reason: ContainerCreating
24/06/07 20:17:00 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Pending)
24/06/07 20:17:01 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Pending)
24/06/07 20:17:02 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Pending)
24/06/07 20:17:03 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Pending)
24/06/07 20:17:04 INFO LoggingPodStatusWatcherImpl: State changed, new state:pod name: kyuubi-user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd-e2e7df1d3c3rnamespace: defaultlabels: kyuubi-unique-tag -> 2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d, spark-app-name -> user-spark-sql-anonymous-default-2b3ce304-7f0d-455e-bffd, spark-app-selector -> spark-a6876b8c5b87f15a03bc8959a, spark-role -> driver, spark-version -> 3.5.0pod uid: 7826bf25-67a5-4c84-b98e-7239f999a368creation time: 2024-06-07T12:16:59Zservice account name: sparkvolumes: spark-local-dir-1, spark-conf-volume-driver, kube-api-access-rw6gmnode name: t009start time: 2024-06-07T12:16:59Zphase: Runningcontainer status:container name: spark-kubernetes-drivercontainer image: 10.38.199.203:1443/fhc/spark350:v1.0container state: runningcontainer started at: 2024-06-07T12:17:03Z
24/06/07 20:17:04 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:05 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:06 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:07 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:08 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:09 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:10 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:11 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:12 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:13 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:14 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:15 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:16 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:17 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:18 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:19 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:20 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:21 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:22 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:23 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:24 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
2024-06-07 20:17:25.372 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.ha.cookeeper.ZookeeperDiscoveryClient: Get service instance:10.42.235.227:36967 engine id:spark-a6ebe48a5b87f15a03bc8959a and version:1.9.0 under /kyuubi_1.9.0_USER_SPARK_SQL/anonymous/default
24/06/07 20:17:25 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:26 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:27 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:28 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:29 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:30 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:31 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:32 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:33 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:34 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:35 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:36 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:37 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:38 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:39 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
2024-06-07 20:17:43.512 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.sessubiSessionImpl: [anonymous:10.38.199.201] SessionHandle [2b3ce304-7f0d-455e-bffd-e2e7df1d3c3d]ected to engine [10.42.235.227:36967]/[spark-a6876b8c2ebe48a5b87f15a03bc8959a] with SessionHan3ce304-7f0d-455e-bffd-e2e7df1d3c3d]]
2024-06-07 20:17:43.513 INFO Curator-Framework-0 org.apache.kyuubi.shaded.curator.framework.imtorFrameworkImpl: backgroundOperationsLoop exiting
2024-06-07 20:17:43.520 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.shadeeper.ZooKeeper: Session: 0x100dd6b3d350015 closed
2024-06-07 20:17:43.520 INFO KyuubiSessionManager-exec-pool: Thread-407-EventThread org.apache.shaded.zookeeper.ClientCnxn: EventThread shut down for session: 0x100dd6b3d350015
2024-06-07 20:17:43.530 INFO KyuubiSessionManager-exec-pool: Thread-407 org.apache.kyuubi.operaunchEngine: Processing anonymous's query[1b721771-c943-45f5-ab31-384652d151b9]: RUNNING_STATEISHED_STATE, time taken: 53.276 seconds
24/06/07 20:17:40 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:41 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
24/06/07 20:17:42 INFO LoggingPodStatusWatcherImpl: Application status for spark-a6876b8c2ebe415a03bc8959a (phase: Running)
Connected to: Spark SQL (version 3.5.0)
Driver: Kyuubi Project Hive JDBC Client (version 1.9.0)
Beeline version 1.9.0 by Apache Kyuubi
0: jdbc:hive2://10.38.199.201:10009>
0: jdbc:hive2://10.38.199.201:10009>
0: jdbc:hive2://10.38.199.201:10009>
此时去k8s的rancher中看到,生成了一个driver和2个executor,其中driver的log就是上面控制台打出的
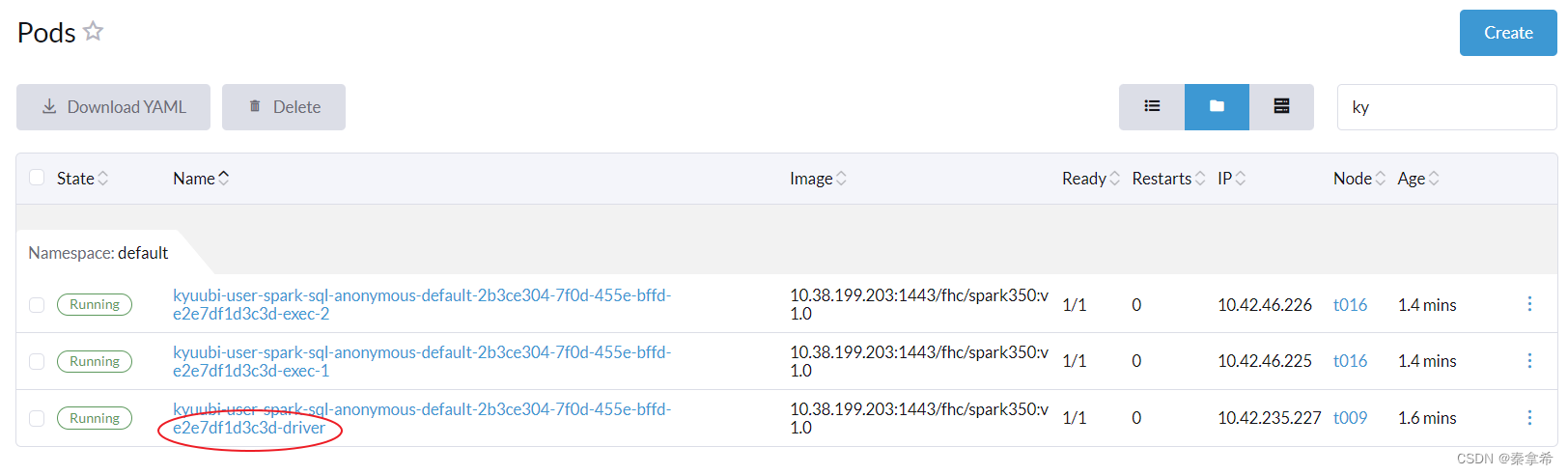
执行sql
show catalogs;show schemas;show tables from p530_cimarronbp;select serial_num,attr_name,pre_attr_value,post_attr_value from p530_cimarronbp.attr_vals limit 10;分别输出



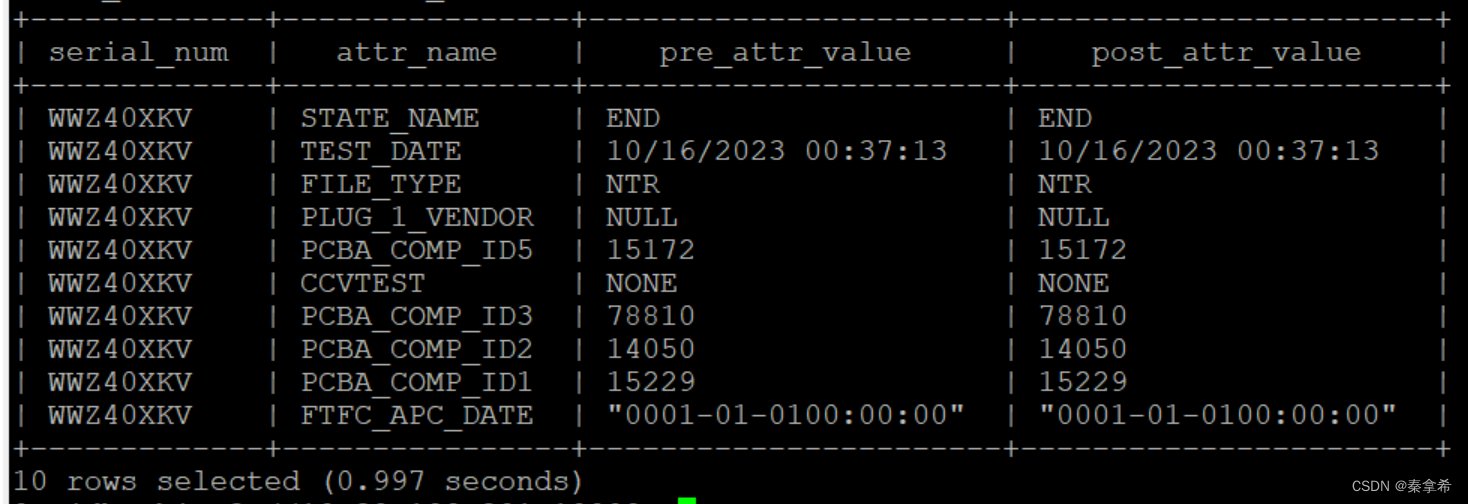
查表过程如下
0: jdbc:hive2://10.38.199.201:10009> select serial_num,attr_name,pre_attr_value,post_attr_value from p530_cimarronbp.attr_vals limit 10;
2024-06-07 21:03:35.706 INFO KyuubiSessionManager-exec-pool: Thread-437 org.apache.kyuubi.operation.ExecuteStatement: Processing anonymous's query[9ca66778-6ada-4e82-a67c-94ff0d1711be]: PENDING_STATE -> RUNNING_STATE, statement:
select serial_num,attr_name,pre_attr_value,post_attr_value from p530_cimarronbp.attr_vals limit 10
24/06/07 13:03:35 INFO ExecuteStatement: Processing anonymous's query[9ca66778-6ada-4e82-a67c-94ff0d1711be]: PENDING_STATE -> RUNNING_STATE, statement:
select serial_num,attr_name,pre_attr_value,post_attr_value from p530_cimarronbp.attr_vals limit 10
24/06/07 13:03:35 INFO ExecuteStatement:Spark application name: kyuubi_USER_SPARK_SQL_anonymous_default_2b3ce304-7f0d-455e-bffd-e2e7df1d3c3dapplication ID: spark-a6876b8c2ebe48a5b87f15a03bc8959aapplication web UI: http://spark-b043ef8ff2a1691d-driver-svc.default.svc:4040master: k8s://https://10.38.199.201:443/k8s/clusters/c-m-l7gflsx7deploy mode: clusterversion: 3.5.0Start time: 2024-06-07T12:17:09.076User: anonymous
24/06/07 13:03:35 INFO ExecuteStatement: Execute in full collect mode
24/06/07 13:03:35 INFO V2ScanRelationPushDown:
Output: serial_num#89, attr_name#91, pre_attr_value#92, post_attr_value#9324/06/07 13:03:35 INFO SnapshotScan: Scanning table spark_catalog.p530_cimarronbp.attr_vals snapshot 7873460573566859549 created at 2024-06-05T07:37:31.200+00:00 with filter true
24/06/07 13:03:35 INFO BaseDistributedDataScan: Planning file tasks locally for table spark_catalog.p530_cimarronbp.attr_vals
24/06/07 13:03:36 INFO LoggingMetricsReporter: Received metrics report: ScanReport{tableName=spark_catalog.p530_cimarronbp.attr_vals, snapshotId=7873460573566859549, filter=true, schemaId=0, projectedFieldIds=[1, 3, 4, 5], projectedFieldNames=[serial_num, attr_name, pre_attr_value, post_attr_value], scanMetrics=ScanMetricsResult{totalPlanningDuration=TimerResult{timeUnit=NANOSECONDS, totalDuration=PT0.171799742S, count=1}, resultDataFiles=CounterResult{unit=COUNT, value=443}, resultDeleteFiles=CounterResult{unit=COUNT, value=0}, totalDataManifests=CounterResult{unit=COUNT, value=40}, totalDeleteManifests=CounterResult{unit=COUNT, value=0}, scannedDataManifests=CounterResult{unit=COUNT, value=39}, skippedDataManifests=CounterResult{unit=COUNT, value=1}, totalFileSizeInBytes=CounterResult{unit=BYTES, value=600752760}, totalDeleteFileSizeInBytes=CounterResult{unit=BYTES, value=0}, skippedDataFiles=CounterResult{unit=COUNT, value=0}, skippedDeleteFiles=CounterResult{unit=COUNT, value=0}, scannedDeleteManifests=CounterResult{unit=COUNT, value=0}, skippedDeleteManifests=CounterResult{unit=COUNT, value=0}, indexedDeleteFiles=CounterResult{unit=COUNT, value=0}, equalityDeleteFiles=CounterResult{unit=COUNT, value=0}, positionalDeleteFiles=CounterResult{unit=COUNT, value=0}}, metadata={engine-version=3.5.0, iceberg-version=Apache Iceberg 1.5.0 (commit 2519ab43d654927802cc02e19c917ce90e8e0265), app-id=spark-a6876b8c2ebe48a5b87f15a03bc8959a, engine-name=spark}}
24/06/07 13:03:36 INFO SparkPartitioningAwareScan: Reporting UnknownPartitioning with 125 partition(s) for table spark_catalog.p530_cimarronbp.attr_vals
24/06/07 13:03:36 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 32.0 KiB, free 413.8 MiB)
24/06/07 13:03:36 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 3.8 KiB, free 413.8 MiB)
24/06/07 13:03:36 INFO SparkContext: Created broadcast 4 from broadcast at SparkBatch.java:79
24/06/07 13:03:36 INFO MemoryStore: Block broadcast_5 stored as values in memory (estimated size 32.0 KiB, free 413.8 MiB)
24/06/07 13:03:36 INFO MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 3.8 KiB, free 413.8 MiB)
24/06/07 13:03:36 INFO SparkContext: Created broadcast 5 from broadcast at SparkBatch.java:79
24/06/07 13:03:36 INFO CodeGenerator: Code generated in 17.286796 ms
24/06/07 13:03:36 INFO SparkContext: Starting job: collect at ExecuteStatement.scala:85
24/06/07 13:03:36 INFO SQLOperationListener: Query [9ca66778-6ada-4e82-a67c-94ff0d1711be]: Job 2 started with 1 stages, 1 active jobs running
24/06/07 13:03:36 INFO SQLOperationListener: Query [9ca66778-6ada-4e82-a67c-94ff0d1711be]: Stage 2.0 started with 1 tasks, 1 active stages running
24/06/07 13:03:36 INFO SQLOperationListener: Finished stage: Stage(2, 0); Name: 'collect at ExecuteStatement.scala:85'; Status: succeeded; numTasks: 1; Took: 506 msec
24/06/07 13:03:36 INFO DAGScheduler: Job 2 finished: collect at ExecuteStatement.scala:85, took 0.513315 s
24/06/07 13:03:36 INFO StatsReportListener: task runtime:(count: 1, mean: 493.000000, stdev: 0.000000, max: 493.000000, min: 493.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 493.0 ms 493.0 ms 493.0 ms 493.0 ms 493.0 ms 493.0 ms 493.0 ms 493.0 ms 493.0 ms
24/06/07 13:03:36 INFO StatsReportListener: shuffle bytes written:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B0.0 B 0.0 B 0.0 B
24/06/07 13:03:36 INFO StatsReportListener: fetch wait time:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms0.0 ms 0.0 ms 0.0 ms
24/06/07 13:03:36 INFO StatsReportListener: remote bytes read:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B0.0 B 0.0 B 0.0 B
24/06/07 13:03:36 INFO StatsReportListener: task result size:(count: 1, mean: 4787.000000, stdev: 0.000000, max: 4787.000000, min: 4787.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB 4.7 KiB
24/06/07 13:03:36 INFO StatsReportListener: executor (non-fetch) time pct: (count: 1, mean: 92.292089, stdev: 0.000000, max: 92.292089, min: 92.292089)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 92 % 92 % 92 % 92 % 92 % 92 % 92 % 92 % 92 %
24/06/07 13:03:36 INFO StatsReportListener: fetch wait time pct: (count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 %
24/06/07 13:03:36 INFO StatsReportListener: other time pct: (count: 1, mean: 7.707911, stdev: 0.000000, max: 7.707911, min: 7.707911)
24/06/07 13:03:36 INFO StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
24/06/07 13:03:36 INFO StatsReportListener: 8 % 8 % 8 % 8 % 8 % 8 % 8 % 8 % 8 %
24/06/07 13:03:36 INFO SQLOperationListener: Query [9ca66778-6ada-4e82-a67c-94ff0d1711be]: Job 2 succeeded, 0 active jobs running
24/06/07 13:03:36 INFO CodeGenerator: Code generated in 19.276515 ms
24/06/07 13:03:36 INFO ExecuteStatement: Processing anonymous's query[9ca66778-6ada-4e82-a67c-94ff0d1711be]: RUNNING_STATE -> FINISHED_STATE, time taken: 0.955 seconds
24/06/07 13:03:36 INFO ExecuteStatement: statementId=9ca66778-6ada-4e82-a67c-94ff0d1711be, operationRunTime=0.5 s, operationCpuTime=0.2 s
2024-06-07 21:03:36.667 INFO KyuubiSessionManager-exec-pool: Thread-437 org.apache.kyuubi.operation.ExecuteStatement: Query[9ca66778-6ada-4e82-a67c-94ff0d1711be] in FINISHED_STATE
2024-06-07 21:03:36.667 INFO KyuubiSessionManager-exec-pool: Thread-437 org.apache.kyuubi.operation.ExecuteStatement: Processing anonymous's query[9ca66778-6ada-4e82-a67c-94ff0d1711be]: RUNNING_STATE -> FINISHED_STATE, time taken: 0.96 seconds
+-------------+----------------+-----------------------+-----------------------+
| serial_num | attr_name | pre_attr_value | post_attr_value |
+-------------+----------------+-----------------------+-----------------------+
| WWZ40XKV | STATE_NAME | END | END |
| WWZ40XKV | TEST_DATE | 10/16/2023 00:37:13 | 10/16/2023 00:37:13 |
| WWZ40XKV | FILE_TYPE | NTR | NTR |
| WWZ40XKV | PLUG_1_VENDOR | NULL | NULL |
| WWZ40XKV | PCBA_COMP_ID5 | 15172 | 15172 |
| WWZ40XKV | CCVTEST | NONE | NONE |
| WWZ40XKV | PCBA_COMP_ID3 | 78810 | 78810 |
| WWZ40XKV | PCBA_COMP_ID2 | 14050 | 14050 |
| WWZ40XKV | PCBA_COMP_ID1 | 15229 | 15229 |
| WWZ40XKV | FTFC_APC_DATE | "0001-01-0100:00:00" | "0001-01-0100:00:00" |
+-------------+----------------+-----------------------+-----------------------+
10 rows selected (0.997 seconds)
0: jdbc:hive2://10.38.199.201:10009>
如有疑问,欢迎评论,或加vx沟通






![[Shell编程学习路线]——探讨Shell中变量的作用范围(export)](https://img-blog.csdnimg.cn/direct/9a35acc2336d468599968e63c736200d.png)