awk 前言
AWK是一种优良的文本处理工具。它不仅是 Linux中也是任何环境中现有的功能最强大的数据处理引擎之一。
Linux中最常用的文本处理工具有grep,sed,awk。行内将之称为文本三剑客,就功能量和效率来看,awk是当之无愧的文本三剑客之首。
grep主要用于过滤文本,sed用于修改文本,而awk则擅长处理和格式化文本
awk与vim的区别:
- awk为加载一行处理一行,可以接受比较大的文件处理
- vim为先加载整个文件到内存中处理,若内存不够大,无法打开大文件
一、awk的工作原理
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。即 读取一行处理一行,可以接受比较大的文件处理。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
二、awk的语法
awk 选项 '模式或条件 {操作}' 文件 1 文件 2 …
awk -f 脚本文件 文件 1 文件 2 …
- 一定要用单引号。
- { }外指定条件,{ }内指定操作。
- 内建变量,不能用双引号括起来,不然系统会把它当成字符串
三、基本打印用法
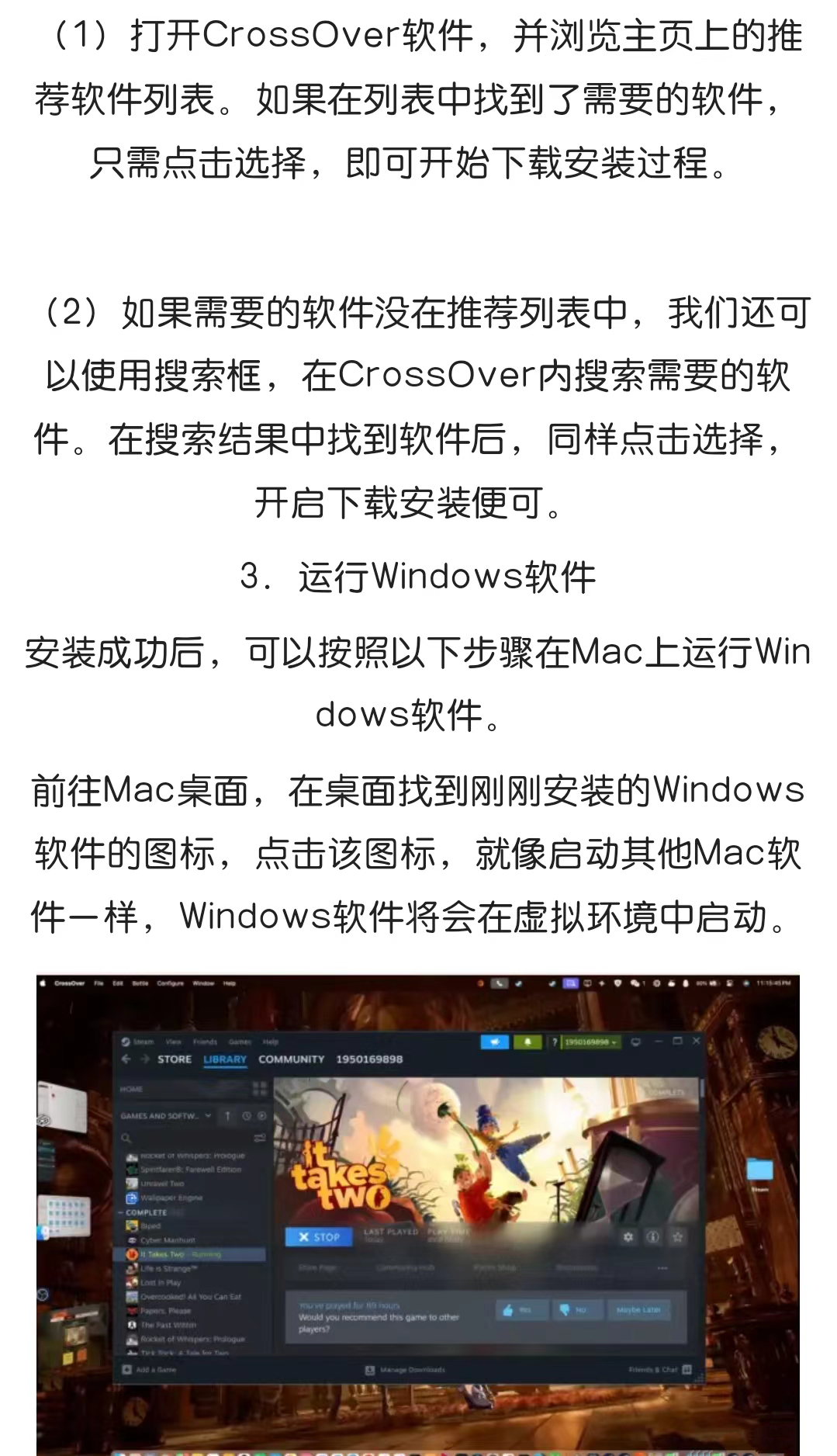
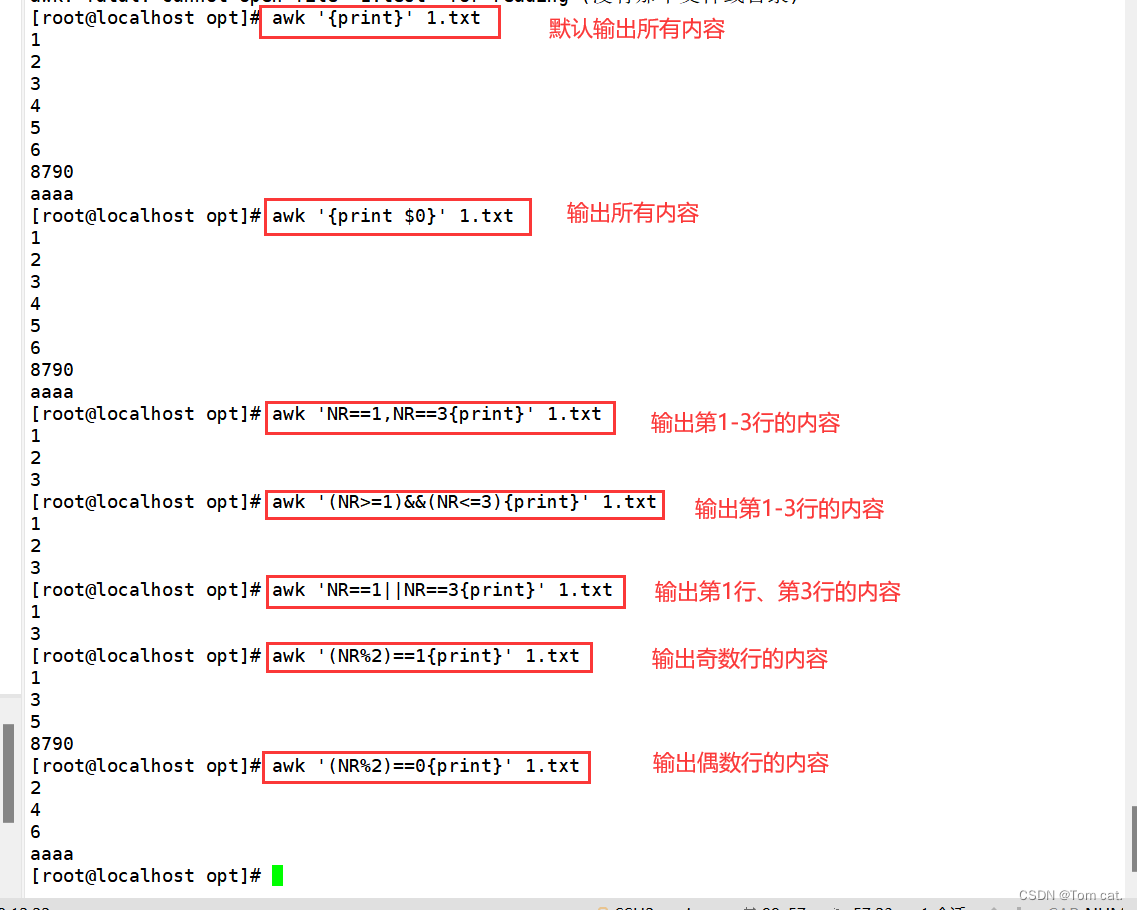
按行输出文本:
| awk '{print}' 1.txt | #输出所有内容 |
| awk '{print $0}' 1.txt | #输出所有内容 |
| awk 'NR==1,NR==3{print}' 1.txt | #输出第 1~3 行内容 |
| awk '(NR>=1)&&(NR<=3){print}' 1.txt | #输出第 1~3 行内容 |
| awk 'NR==1||NR==3{print}' 1.txt | #输出第1行、第3行内容 |
| awk '(NR%2)==1{print}' 1.txt | #输出所有奇数行的内容 |
| awk '(NR%2)==0{print}' 1.txt | #输出所有偶数行的内容 |
| awk '/^p/{print}' /opt/2.txt | #输出以 p 开头的行 |
| awk '/q$/{print}' /opt/2.txt | #输出以 q 结尾的行 |
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd #统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句


打印行内容及其行号:

awk '{getlinegetlinegetline;print$0}' 1.txt #打印偶数行
awk '{print$0;getline}' 1.txt #打印奇数行getline 意思是滑倒下一行
一开始print$0是在1 上面 遇到getline 就滑倒下一行 就是2
反之

BEGIN:
awk 'BEGIN {...}; 条件{...}; END {...}' 文件
##BEGIN {...} #表示处理文件前执行的操作
##条件{...} #表示对匹配满足指定条件的文件行内容要执行的操作
##END {...} #表示处理完文件所有行内容后要执行的操作
例:
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd
#统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd
- BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作
- awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句.
字段输出:
awk -F: '/q$/{print $1}' /opt/2.txt #打印以bash结尾行的第一个字段
awk '/q$/{print $1,$3}' /opt/2.txt #输出多个列时,默认空格进行分隔

四、常见的内置变量
| 内置变量 | 作用 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数。$NF代表最后一个字段 |
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| OFS | 输出内容的列分隔符 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是"\n" |
NR: 表示行号
关于NF的使用 :表示最后一列
[root@localhost ~]#df |awk '{print $NF}' ##挂载点[root@localhost ~]#df |awk '{print $(NF-1)}' ##使用百分比


关于FS的使用:指定每行文本的字段分隔符,默认为空格或制表位
[root@localhost /ceshi]#awk -v "FS=:" '{print $1FS$3}' /etc/passwd
##与 -F":" [root@localhost /ceshi]#awk -F: '{print $1":"$3}' /etc/passwd
##-F和-FS一起使用时-F 的优先级高

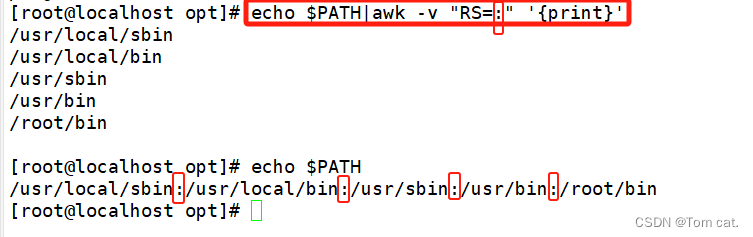
关于RS的使用 :为换行符
将冒号作为换行的分隔符 把内容打印出来
五、实际运用
1、提取磁盘的分区利用率
df|awk '{print $5}'

2、提取用户名和uid号
cat /etc/passwd|awk -F: '{print $1,$3}'
##默认用空格分开
[root@localhost ~]#cat /etc/passwd|awk -F: '{print $1":"$3}'
##用冒号分隔开
[root@localhost ~]#cat /etc/passwd|awk -F: '{print $1"\t"$3}'
##用制表符分隔开


3、提取ip地址
[root@localhost /ceshi]#hostname -I
192.168.20.6 192.168.122.1
[root@localhost /ceshi]#hostname -I|awk '{print $1}'
192.168.20.6
[root@localhost /ceshi]#ifconfig ens33|sed -n '2p' |awk '{print $2}'
192.168.20.64、awk的统计用法
[root@localhost /ceshi]#grep -c "/bin/bash$" /etc/passwd
4
[root@localhost /ceshi]#cat /etc/passwd|awk '{x++}END{print x}'
44
[root@localhost /ceshi]#cat /etc/passwd|wc -l
44
[root@localhost /ceshi]#cat /etc/passwd|awk '/bash$/{x++}END{print x}'
45、计算磁盘使用率及空闲率
df | grep -w "/" | awk '{print $5}' #磁盘使用率
df | grep -w "/" | awk '{print 100-$5"%"}' #磁盘空闲率6、检测本机cpu 15分钟内的平均负载
[root@localhost awk]#uptime|awk '{print $NF}'
一般超过百七十,就要注意了
grep前言
grep 命令是一个在 Linux/Unix 操作系统中用于查找文本的工具,grep 命令能够对指定的文件或标准输入进行搜索,并输出包含匹配文本的行。
grep 命令是一个非常强大的文本搜索工具,支持基本正则表达式、扩展正则表达式和固定字符串的匹配模式,可以帮助用户快速地定位文件中的关键信息,提高工作效率。
一、 基本用法
grep 命令的基本语法格式为:
grep [参数] 搜索模式 [路径]
例在文件 2.txt中搜索字符串 2q,可以使用以下命令:
grep 2q 2.txt
如果要搜索多个文件,可以指定多个文件名或使用通配符。
例搜索所有以 q结尾的字符串,可以使用以下命令:
grep q* 2.txt
二、常用选项
grep 命令常用的选项:
- -i:忽略大小写;
- -r:递归搜索子目录;
- -n:显示匹配行的行号;
- -c:只显示匹配行的数量;
- -v:反转匹配,即只显示不匹配的行;
- -w:只匹配整个单词,不匹配子串;
- -o :表示只输出匹配部分,而不是整行;
- -E:使用扩展正则表达式;
- -F:将模式视为固定字符串而非正则表达式。
- -h:表示不显示文件名
例 忽略大小写和显示匹配行的行号,可以使用以下命令:
grep -in "P" 2.txt
三. 正则表达式
grep 命令支持基本正则表达式(BRE)、扩展正则表达式(ERE)和固定字符串三种匹配模式。
基本正则表达式
- . :匹配任意一个字符;
- [] :匹配括号中的任意一个字符;
- [^] :匹配不在括号中的任意一个字符;
- [:class:] :匹配指定字符类中的任意一个字符,例如 [:digit:] 表示数字字符。
常用的特殊序列包括:
- ^ :匹配行首;
- $ :匹配行尾;
- \< :匹配单词首;
- \> :匹配单词尾;
- \n :匹配换行符。
如要在文件 2.txt 中搜索以 q 开头的行,可以使用以下命令:
grep '^q' 2.txt #要在文件2 .txt 中搜索以 q开头的行

- + :匹配一个或多个前导字符;
- * :匹配零个或多个前导字符;
- ? :匹配零个或一个前导字符;
- {n} :匹配恰好 n 个前导字符;
- {n,} :匹配至少 n 个前导字符;
- {n,m} :匹配至少 n 个且不超过 m 个前导字符;
- () :分组匹配;
- | :或运算符。
如要在文件 2.txt 中搜索以 hello 开头且后面跟着一个或多个空格的行,可以使用以下命令
grep '^hello[[:space:]]+' 2.txt^与$的运用
# 搜索以数字开头的行
grep '^[0-9]' file.txt# 搜索以数字结尾的行
grep '[0-9]$' file.txt# 搜索包含数字的行
grep '[0-9]' file.txt
匹配整个单词
grep 默认会匹配到包含搜索词的所有行,包括单词的一部分。如果需要只匹配完整单词,可以使用 ‘-w’ 选项。
# 搜索包含单词 'hello' 的行
grep 'hello' file.txt# 只搜索包含完整单词 'hello' 的行
grep -w 'hello' file.txt
搜索多个文件
如果需要在多个文件中搜索,可以使用通配符或者正则表达式。
# 搜索多个文件
grep 'hello' file1.txt file2.txt file3.txt# 搜索文件夹下的所有 txt 文件
grep 'hello' *.txt# 搜索文件夹下的所有文件
grep 'hello' *
显示匹配行的上下文
使用 ‘-A’ 和 ‘-B’ 选项可以显示匹配行的上下文。
# 显示匹配行的前 3 行和后 3 行
grep -A 3 -B 3 'hello' file.txt
反向搜索
使用 ‘-v’ 选项可以反向搜索,即只显示不匹配的行。
# 只显示不包含单词 'hello' 的行
grep -v 'hello' file.txt
统计匹配次数
使用 ‘-c’ 选项可以统计匹配次数。
# 统计包含单词 'hello' 的行数
grep -c 'hello' file.txt
总结
' ' 单引号内的内容被视为字面字符串
" " 双引号允许变量扩展和命令替换 (如双引号号内有变量可引用变量)
( ) 分组匹配
[ ] 匹配括号中的任意一个字符
{n} 匹配恰好 n 个前导字符