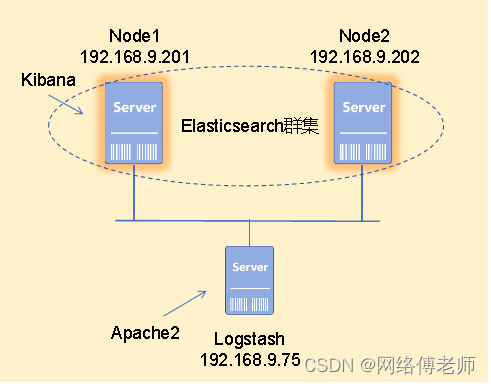
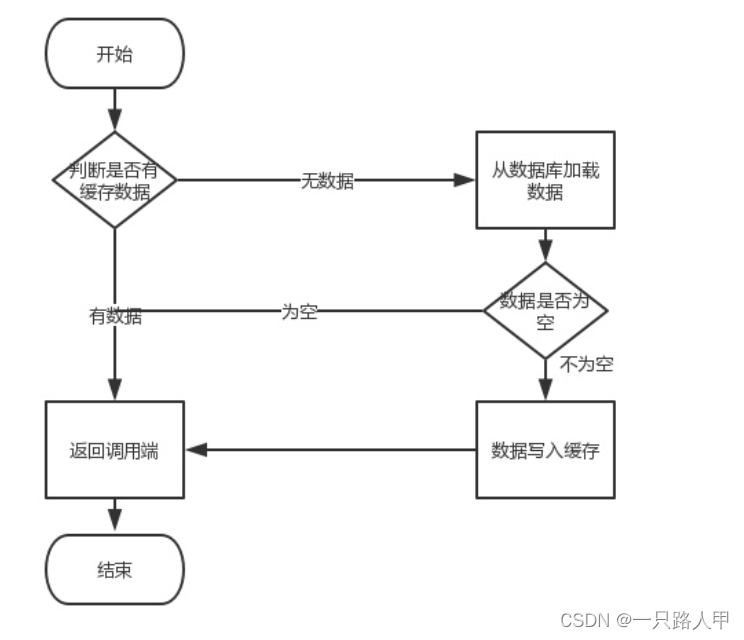
一,使用方案
在使用redis作为缓存的场景下,我们一般使用流程如下
二,更新数据场景
我们此时修改个某条数据,如何保证mysql数据库和redis缓存中的数据一致呢?
按照常规思路有四种办法,1.先更新mysql数据,再更新缓存数据 2.先更新缓存数据,再更新mysql数据
3.先删除缓存,再更新mysql数据 4.先更新mysql数据,再删除缓存 。
这四种方法各有各的弊端,并不能完全保证数据一致性,采用“先写 MySQL,再删除 Redis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。对于不是强一致性要求的业务,可以容忍。(什么情况下不能容忍呢,比如秒杀业务、库存服务等。)
为什么采用删除缓存而不是更新缓存,是因为高并发下产生脏数据的要求要比更新缓存的要求更多,也就是删除缓存产生脏数据的概率更小一些。
那么问题又来了,在高并发的情况下
采用先删除缓存,再更新数据库
- 请求A来了,删除缓存
- 请求A更新数据库,发生卡顿,同时来了请求B
- 请求B发现没有缓存,就从数据库查询了数据,并生成了缓存
- 此时请求A卡顿结束,更新了数据库
这个情况下,缓存中的就是脏数据。我们采用延时双删来解决
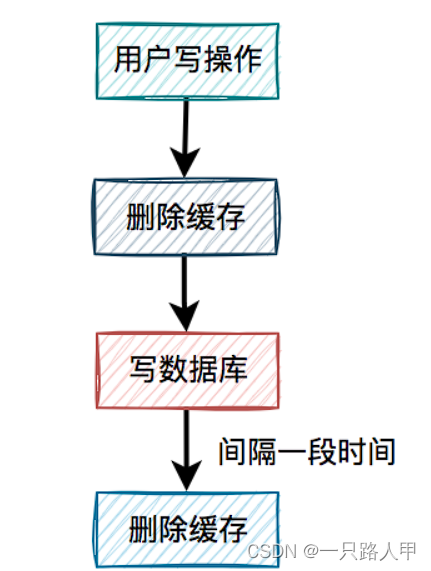
那么问题又来了,第二次删除缓存失败了怎么办?看下面 - 先更新数据库,再删除缓存
如果删除缓存失败,怎么保证数据一致性?
1.使用重试机制,可以直接在接口中重试,但是比较耗费性能
2.使用异步队列重试
3.使用rabbitmq消息中间件来处理
当用户操作写完数据库,但删除缓存失败了,产生一条mq消息,发送给mq服务器。
mq消费者读取mq消息,重试5次删除缓存。如果其中有任意一次成功了,则返回成功。如果重试了5次,还是失败,则写入死信队列中。
当然在该方案中,删除缓存可以完全走异步。即用户的写操作,在写完数据库之后,不用立刻删除一次缓存。而直接发送mq消息,到mq服务器,然后有mq消费者全权负责删除缓存的任务。
因为mq的实时性还是比较高的,因此改良后的方案也是一种不错的选择。
总结:以上方法只能保证最终一致性,不能保证强一致性