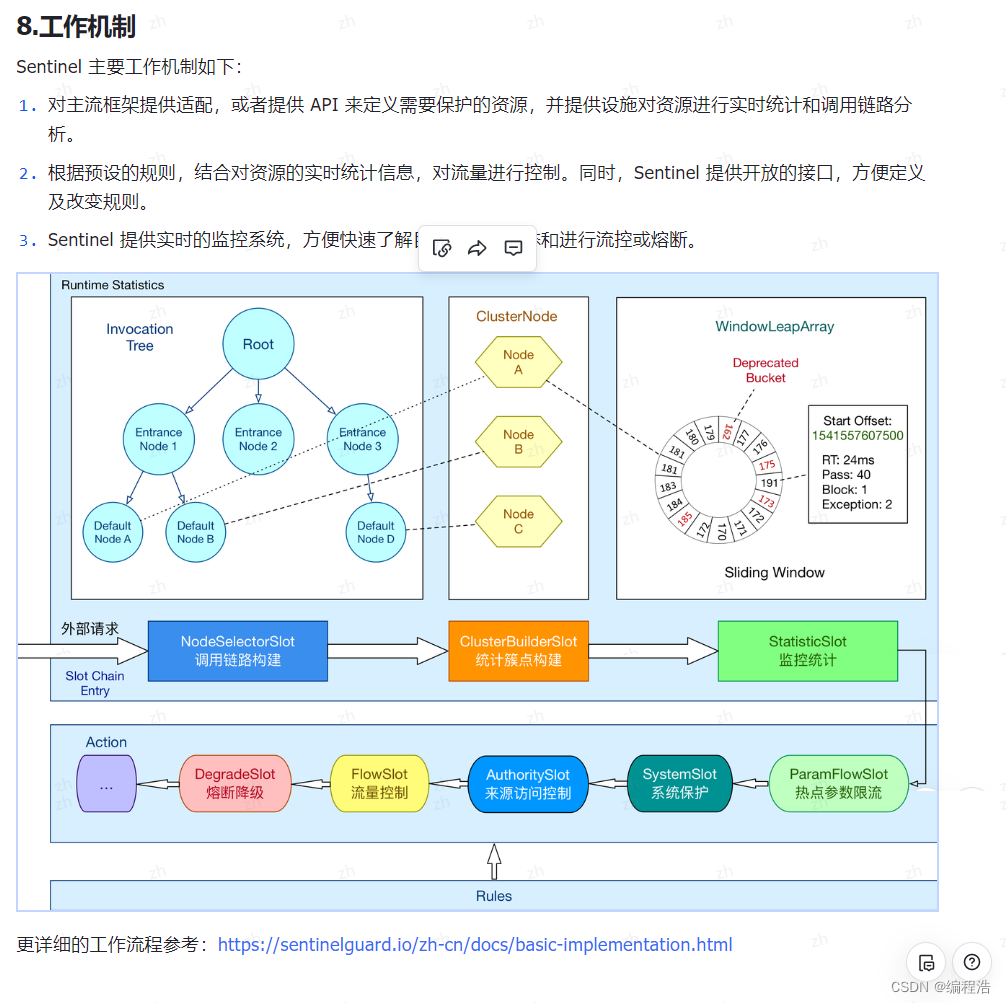
【云岚到家】-day03-1-门户-缓存方案选择
- 1 门户
- 1.1 门户简介
- 1.2 常见的技术方案
- 1.2.1 需求
- 1.2.2 常见门户
- 1.2.2.1 Web门户
- 1.2.2.2 移动应用门户
- 1.2.2.3 总结
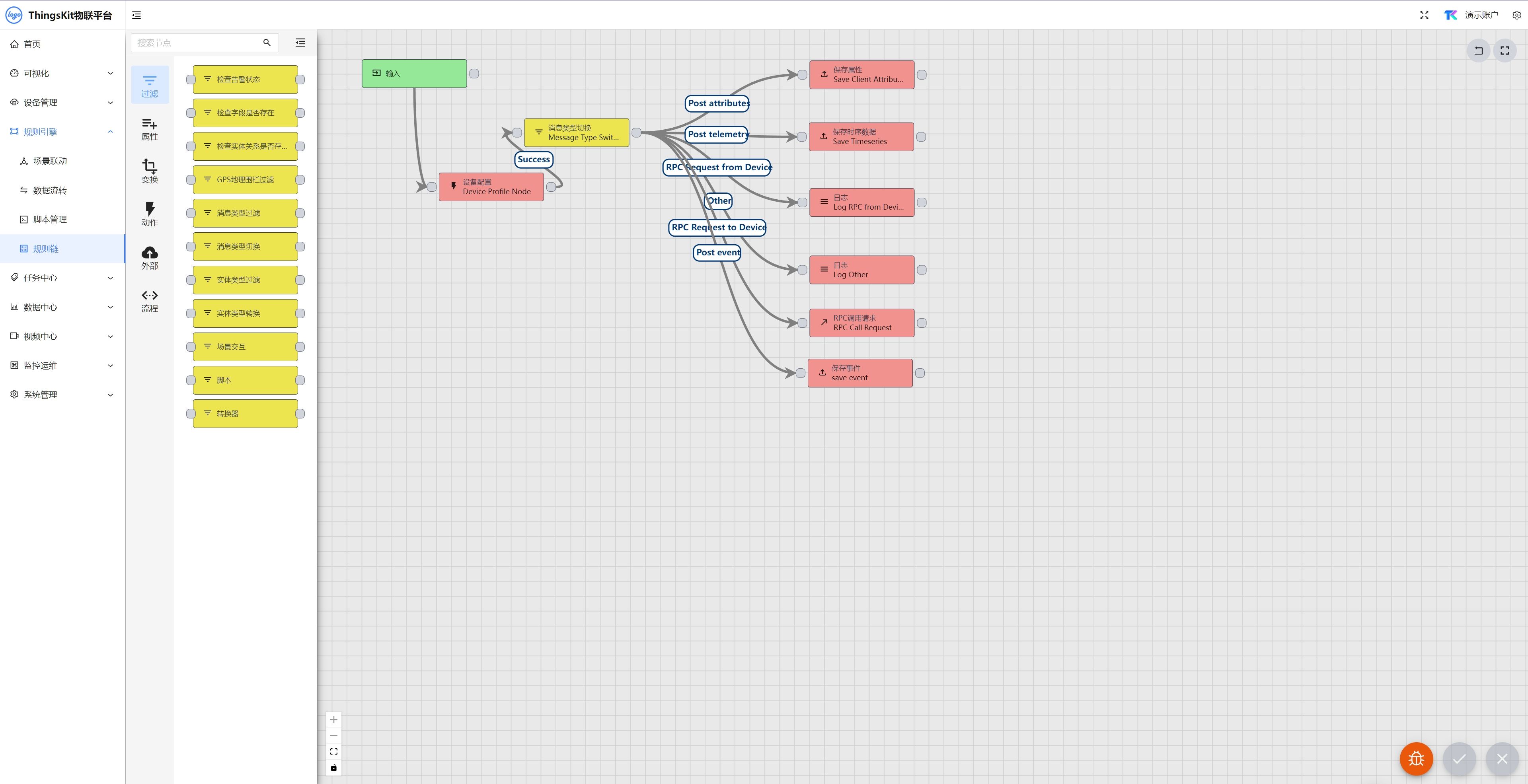
- 2 缓存技术方案
- 2.1 需求分析
- 2.1.1 界面原型
- 2.2.2 缓存需求
- 3 SpringCache入门
- 3.1 基础概念
- 3.1.1 Redis客户端
- 3.1.2 Spring data和Spring data redis是什么关系?
- 3.1.3 RedisTemplate和Lettuce是什么关系?
- 3.1.4 Spring Cache和Spring data redis是什么关系?
- 3.2 入门程序
- 3.2.1 Spring Cache基本介绍
- 3.2.2 搭建环境
- 3.2.3 查询数据时缓存-Cacheable
- 3.2.4 测试
- 3.2.5 工作原理
- 3.3 测试Spring Cache-@CachePut-@CacheEvict
- 3.3.1 测试@CachePut
- 3.3.2 测试@CacheEvict
- 3.3.3 总结
- 4 缓存常见问题
- 4.1 缓存穿透问题
- 4.1.1 什么是缓存穿透问题
- 4.1.2 解决方案
- 4.1.2.1 对请求增加校验机制
- 4.1.2.2 缓存空值或特殊值
- 4.1.2.3 使用布隆过滤器
- 1) 什么是布隆过滤器?
- 2) 如何使用布隆过滤器?
- 3) 如何代码实现布隆过滤器?
- 4.1.3 小结
- 4.2 缓存击穿问题
- 4.2.1 什么是缓存击穿
- 4.2.2 解决方案
- 4.2.2.1 使用锁
- 4.2.2.2 热点数据不过期
- 4.2.2.3 缓存预热
- 4.2.2.4 热点数据查询降级处理
- 4.2.3 小结
- 4.3 缓存雪崩问题
- 4.3.1 什么是缓存雪崩
- 4.3.2 解决方案
- 4.3.2.1 使用锁进行控制
- 4.3.2.2 对同一类型信息的key设置不同的过期时间
- 4.3.2.3 缓存定时预热
- 4.3.3 小结
- 4.4 缓存不一致问题
- 4.4.1 什么是缓存不一致问题
- 4.4.2 解决方案
- 4.4.2.1 使用分布式式锁
- 4.4.2.2 延迟双删
- 4.4.2.3 异步同步
- 4.4.3 小结
- 5 缓存实现
- 5.1 开通区域列表缓存实现
- 5.1.1 缓存方案分析
- 5.1.2 查询缓存实现
- 5.1.3 启用区域
- 5.1.4 禁用区域
- 5.1.5 测试
1 门户
1.1 门户简介
说到门户马上会想到门户网站,中国比较早的门户网站有新浪、网易、搜狐、腾讯等,门户网站为用户提供一个集中的、易于访问的平台,使他们能够方便地获取各种信息和服务。
这里我们说的门户是指一个网站或应用程序的主页,它是用户进入这个网站或系统的入口,主页上通常聚合很多的信息,包括内容导航、热点信息等,比如:门户网站的首页、新闻网站的首页、小程序的首页等。
小程序首页:
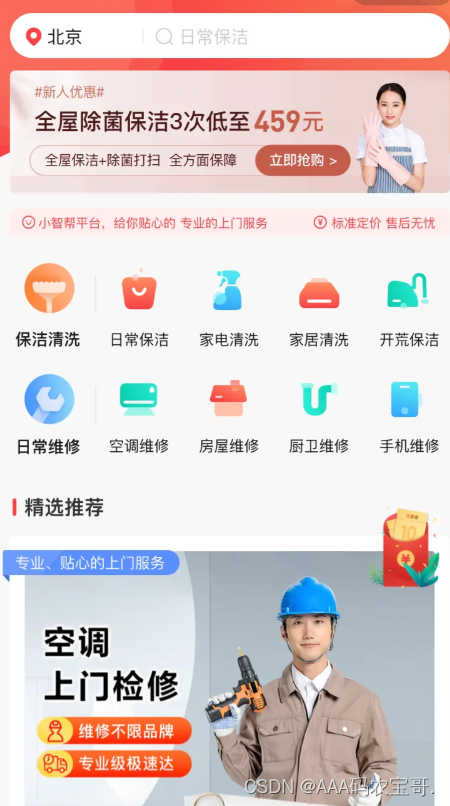
1.2 常见的技术方案
1.2.1 需求
1.门户上的信息是动态的
门户上的信息会按照一定的时间周期去更新,比如一个新闻网站不可能一直显示一样的新闻。
2.门户作为入口其访问频率非常高
对于访问频率高的界面其加载速度是至关重要的,因为它直接影响用户的体验和留存率。一般来说门户网站的首页应该在2至3秒内加载完成,这被认为是一个合理的加载时间目标。
1.2.2 常见门户
常见的两类门户是:web门户和移动应用门户。
我们针对这两类门户分析技术方案。
1.2.2.1 Web门户
web门户是最常见的门户类型,比如:新浪、百度新闻等,它们通过PC浏览器访问,用户可以通过桌面电脑、笔记本电脑、平板电脑和智能手机等设备访问。Web门户通常运行在Web浏览器上,用户可以通过输入网址或通过搜索引擎访问。
web门户是通过浏览器访问html网页,虽然html网页上的内容是动态的但是考虑门户作为入口其访问频率非常高所以就需要提高它的加载速度,如果网页上的数据是通过实时查询数据库得到是无法满足要求的,所以针对web门户提高性能的关键是如何提高html文件的访问性能,如何提高查询数据的性能。
1.将门户页面生成静态网页发布到CDN服务器。
纯静态网页通过Nginx加载要比去Tomcat加载快很多。
我们可以使用模板引擎技术将动态数据静态化生成html文件,并通过CDN分发到边缘服务器,可以提高访问效率。
Java模板引擎技术有很多,比如:freemarker、velocity等。
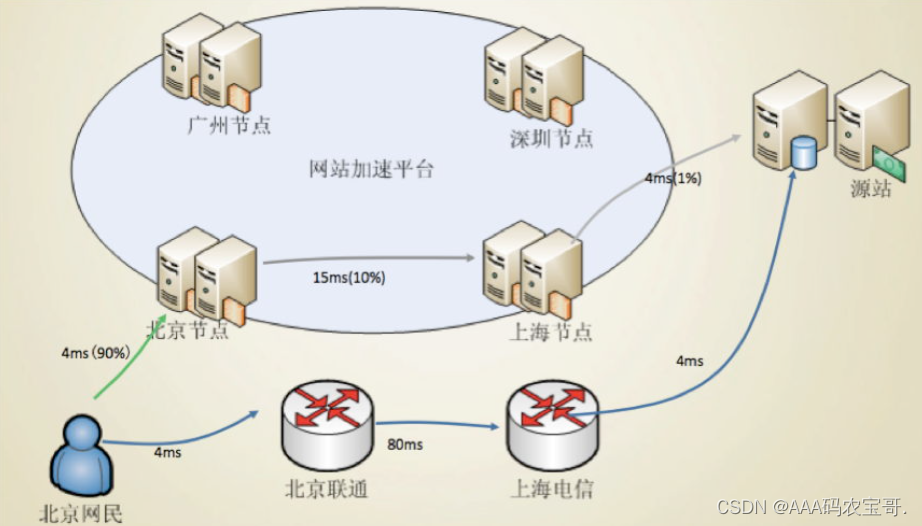
什么是CDN?
CDN 是构建在数据网络上的一种分布式的内容分发网,旨在提高用户访问网站或应用时的性能。
下图中,通过CDN将内容分发到各个城市的CDN节点上,北京的网民请求北京的服务即可拿到资源,提高访问速度。
CDN就可以把诸如freemarker制作好的静态页面以模块的方式分发到各个边缘节点。
2、html文件上的静态资源比如:图片、视频、CSS、Js等也全部放到CDN服务。
3、html上的动态数据通过异步请求后端缓存服务器加载,不要直接查询数据库,通过Redis缓存提高查询速度。
4、使用负载均衡,通过部署多个Nginx服务器共同提供服务,不仅保证系统的可用性,还可以提高系统的访问性能。
5、在前端也做一部分缓存。
不仅服务端可以做缓存,前端也可以做缓存,前端可以把缓存信息存储到
LocalStorage: 提供了持久化存储,可以存储大量数据
SessionStorage: 与 LocalStorage 类似,但数据只在当前会话中有效,当用户关闭标签页或浏览器时清空。
Cookie: 存储在用户计算机上的小型文本文件,可以在客户端和服务器之间传递数据
浏览器缓存:通过 HTTP 头部控制,比如:Cache-Control头部提供了更灵活的缓存控制选项,可以定义缓存的最大有效时间。
1.2.2.2 移动应用门户
移动应用门户是专为移动设备(如智能手机和平板电脑)设计的应用程序,比如:小程序、APP等,用户可以通过应用商店下载并安装。这些应用程序提供了更好的用户体验,通常具有更高的性能和交互性,可以直接从设备主屏幕启动。
对于移动应用提高访问效率方法通常有:
静态资源要走CDN服务器
对所有请求进行负载均衡
在前端及服务端缓存门户上显示的动态数据。
1.2.2.3 总结
根据上边的分析,对于Java程序员需要关注的是缓存服务的开发,主流的缓存服务器是Redis,所以我们接下来的工作重点是使用Redis为门户开发缓存服务接口。
选用的技术方案一句话来说就是:静态资源放cdn服务器,走nginx负载均衡,动态数据使用redis缓存,异步加载。
2 缓存技术方案
2.1 需求分析
目标:明确本项目门户有哪些信息需要缓存
2.1.1 界面原型
了解了门户的技术方案,下边通过门户界面原型分析本项目门户包括哪些部分。
本项目小程序门户首页如下图:
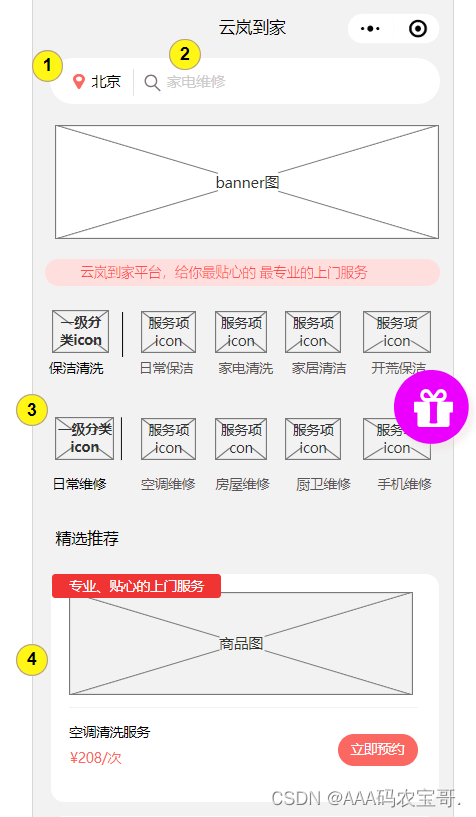
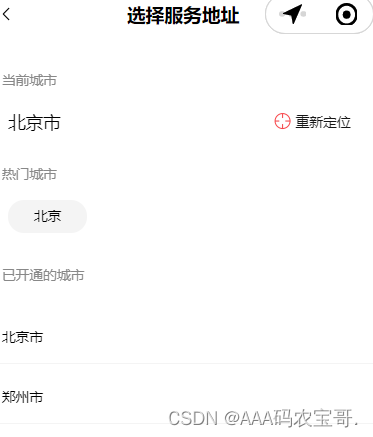
第1部分:用户允许微信授权后,自动获取当前定位,点击地址进入城市选择页面,如下图:
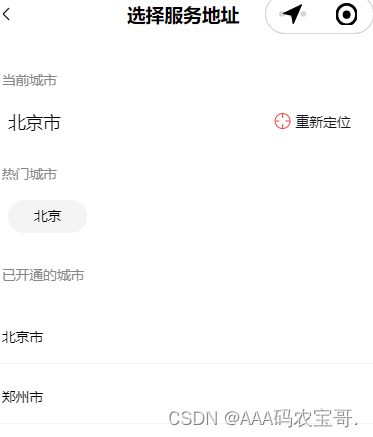
已开通城市是指在区域管理中所有启用的区域信息。
第2部分:触发搜索框进入搜索主页面,如下图:
输入关键字搜索服务信息。这个我们后面要走es,索引库过来的数据也要缓存。

第3部分:首页服务列表
默认展示前两个服务分类,每个服务分类下取前4个服务项(根据后台排序规则显示,如排序相同则按照更新时间倒序排列)
点击一级分类进入【全部服务】页;点击服务项进入【服务项目详情页】
第4部分:热门服务列表
这里显示在区域服务界面设置热门服务的服务项。
第5部分:全部服务
点击首页服务列表的服务分类或直接点击“全部服务”进入全部服务界面,
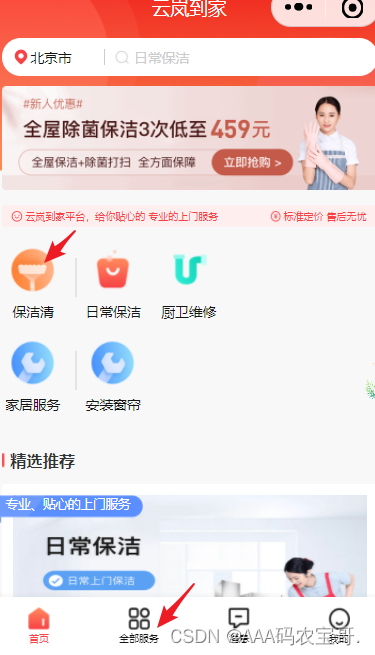
全部服务界面,如下图:
在全部服务界面需要展示当前区域下的服务分类,点击服务分类查询分类下的服务。
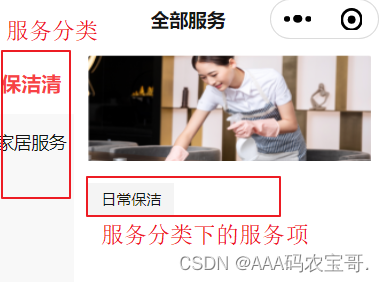
点击服务名称进入服务详情页面:
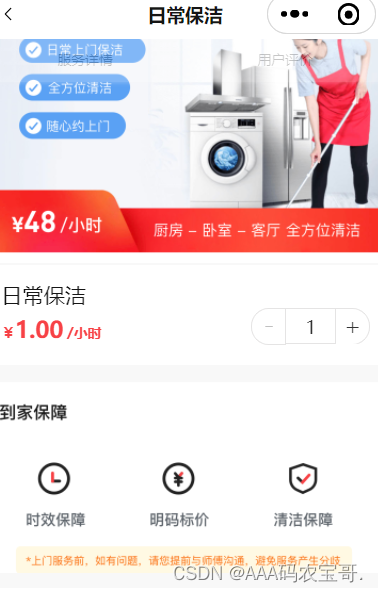
价格数据等等也要进行缓存。一句话,从数据库查出来的都要缓存!
2.2.2 缓存需求
1、首页服务列表,包括两个服务分类及每个分类下的四个服务项。
2、热门服务列表
3、服务类型列表
4、开通城市列表
5、服务详细信息,内容包括服务项信息、服务信息。
3 SpringCache入门
3.1 基础概念
3.1.1 Redis客户端
常用的有Jedis和Lettuce两个访问redis的客户端库,其中Lettuce的性能和并发性要好一些,Spring Boot 默认使用的是 Lettuce 作为 Redis 的客户端。
3.1.2 Spring data和Spring data redis是什么关系?
Spring data是Spring对全部的数据来源进行抽取的一个框架,可以访问mysql、redis、mongodb等等的数据库的一个框架。而Spring data redis是仅访问redis的一个数据库框架。
3.1.3 RedisTemplate和Lettuce是什么关系?
RedisTemplate是Spring data redis的东西,而Lettuce 是redis官方给的一个客户端的类库。
RedisTemplate 进行 Redis 操作时,实际上是通过 Lettuce 客户端与 Redis 服务器进行通信。
3.1.4 Spring Cache和Spring data redis是什么关系?
Spring data redis和Spring Cache是两个不同的框架。
Spring Cache是用来访问缓存的一个缓存框架。Spring Cache是Spring的缓存框架,可以集成各种缓存中间件,比如:EhCache、Caffeine、redis。当你使用redis的时候Spring Cache他就会借助redis官方给到的客户端类库,如Jedis和Lettuce去访问redis,Spring Cache最终也是通过Lettuce 去访问redis 。
使用Spring Cache的方法很简单,只需要在方法上添加注解即可实现将方法返回数据存入缓存,以及清理缓存等注解的使用。
Spring data redis通过RedisTemplate适用于灵活操作redis的场景,通过RedisTemplate的API灵活访问Redis。Spring Cache添加注解即可实现将方法返回数据存入缓存,这两种访问 redis的方法在本项目都有使用。
3.2 入门程序
目标:学会使用SpringCache查询缓存注解并理解它的原理
3.2.1 Spring Cache基本介绍
Spring Cache是Spring提供的一个缓存框架,基于AOP原理,实现了基于注解的缓存功能,只需要简单地加一个注解就能实现缓存功能,对业务代码的侵入性很小。
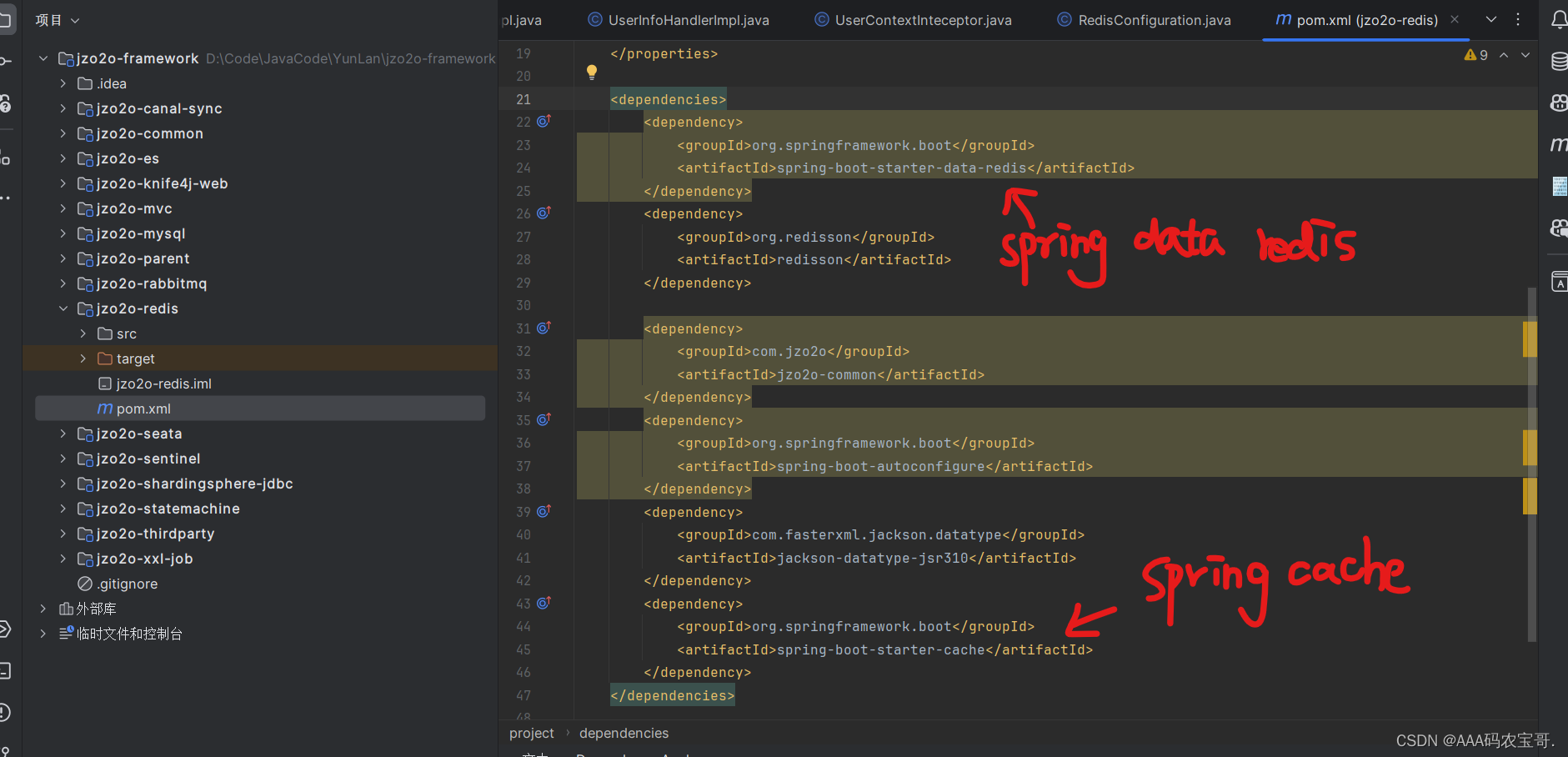
基于SpringBoot使用Spring Cache非常简单,首先加入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId><version>2.7.10</version>
</dependency>
本项目在jzo2o-framework下的jzo2o-redis工程引入此依赖,其它服务只需要引入jzo2o-redis的依赖即可。
简单认识它的常用注解:
@EnableCaching:开启缓存注解功能
@Cacheable:查询数据时缓存,将方法的返回值进行缓存。
@CacheEvict:用于删除缓存,将一条或多条数据从缓存中删除。
@CachePut:用于更新缓存,将方法的返回值放到缓存中。
@Caching:组合多个缓存注解;
@CacheConfig:统一配置@Cacheable中的value值
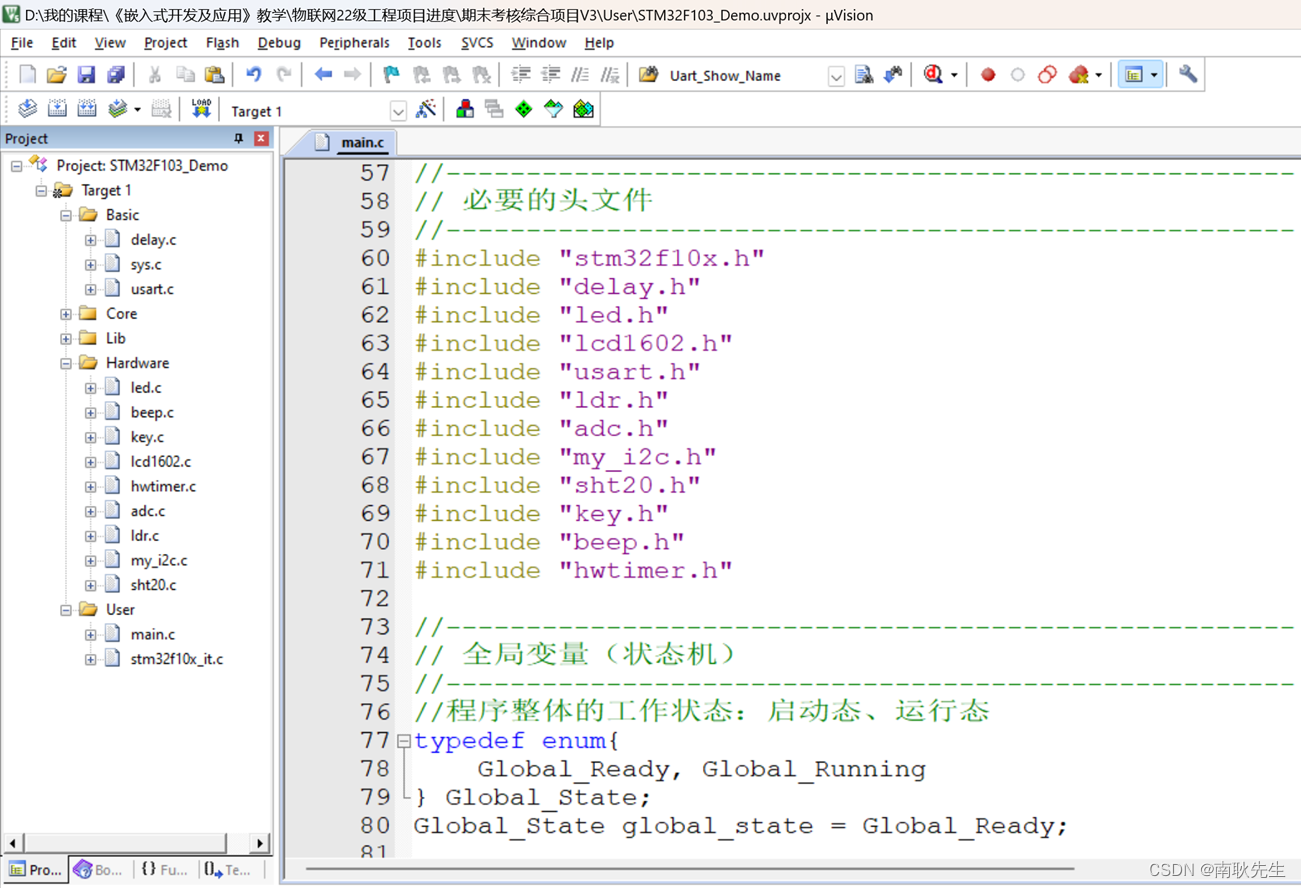
3.2.2 搭建环境
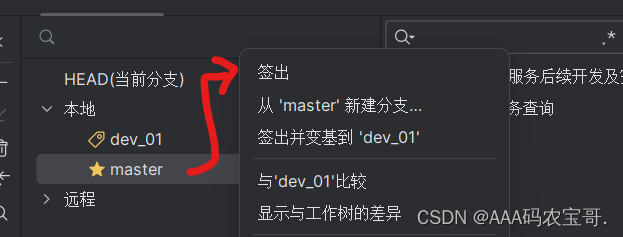
首先搭建jzo2o-foundations工程.
在jzo2o-foundations工程,在master分支的基础上创建新分支dev_02并切换到该分支,并且把dev_02分支推送到远程服务器。
从课程资料的源码目录解压jzo2o-foundations-02-0.zip下的代码,拷贝其中的src和pom.xml覆盖jzo2o-foundations目录的代码,全部覆盖。
然后提交推送
在jzo2o-foundations工程引入jzo2o-redis依赖
<dependency><groupId>com.jzo2o</groupId><artifactId>jzo2o-redis</artifactId>
</dependency>
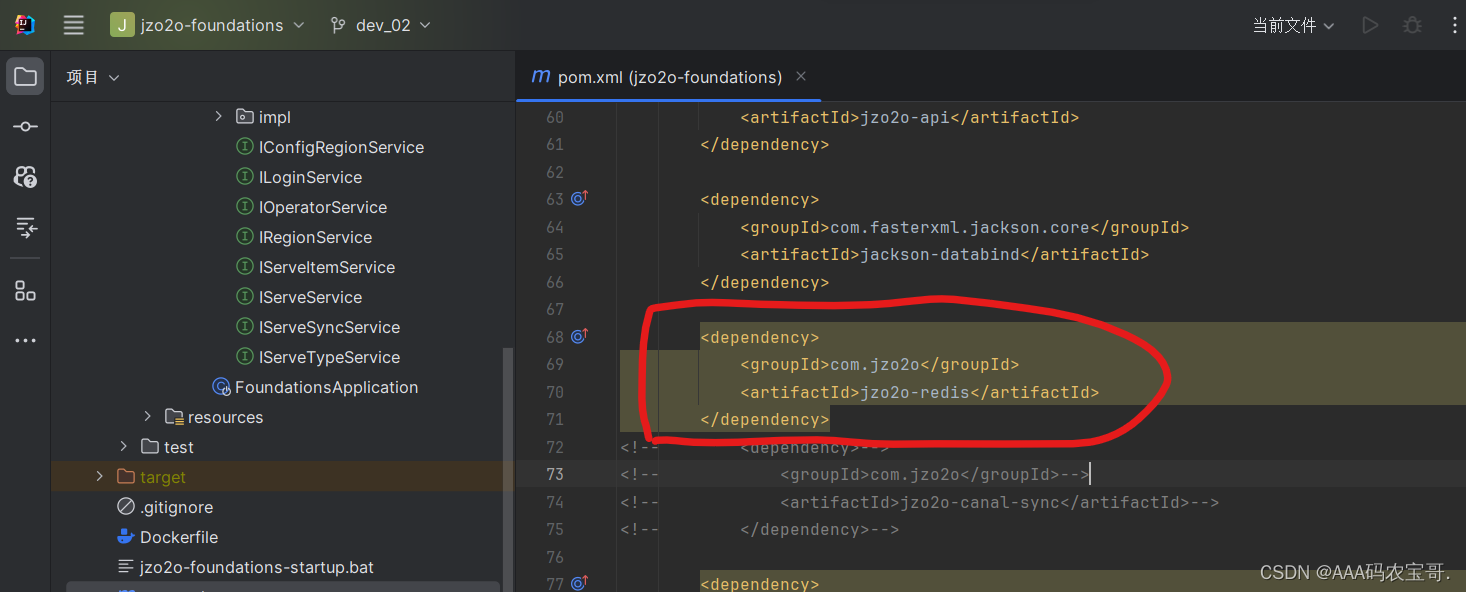
在jzo2o-foundations工程的bootstrap.yml中引入redis的配置文件,如下图:
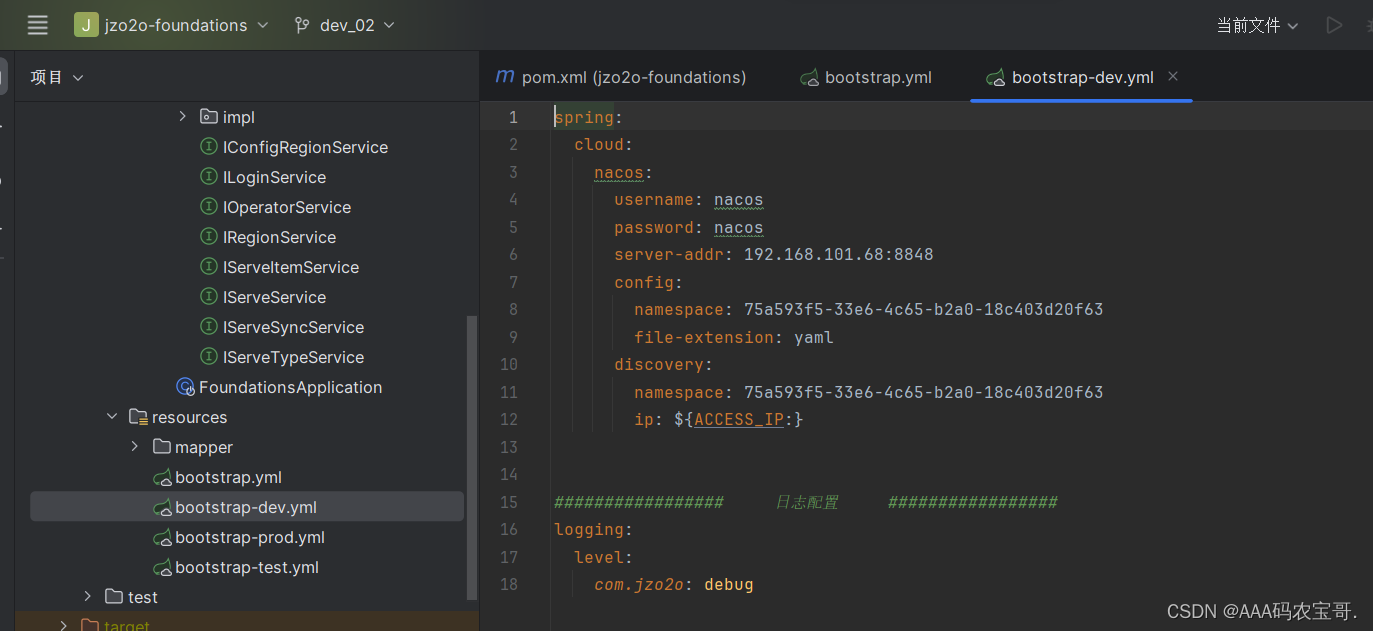
打开总的bootstrap.yaml
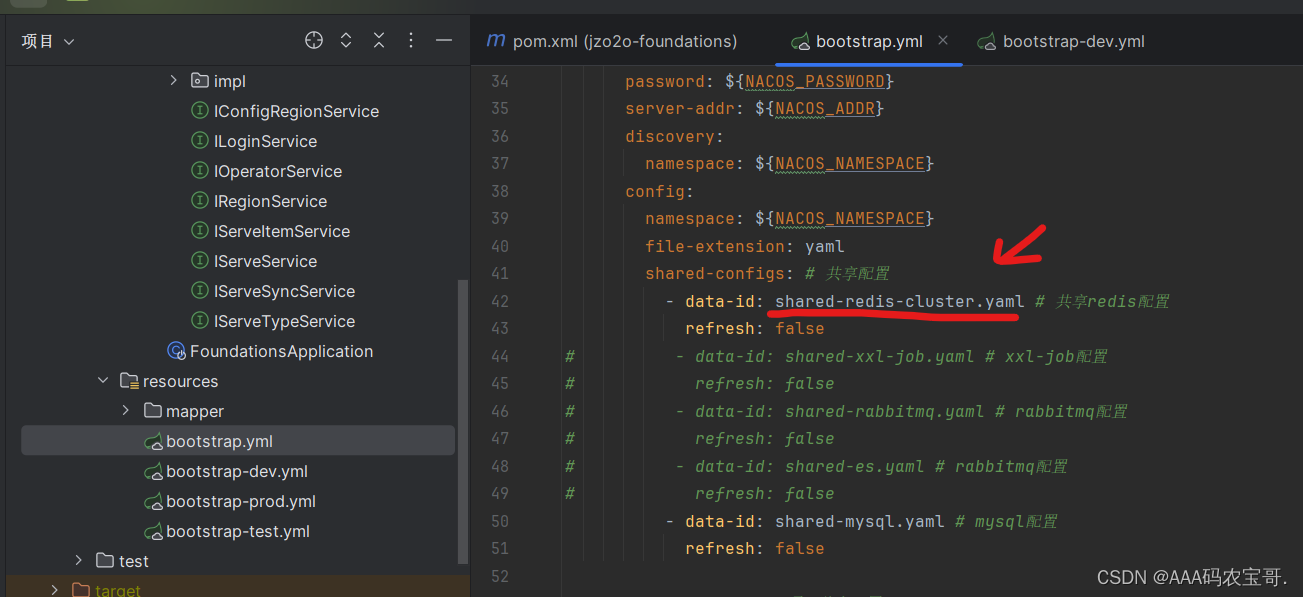
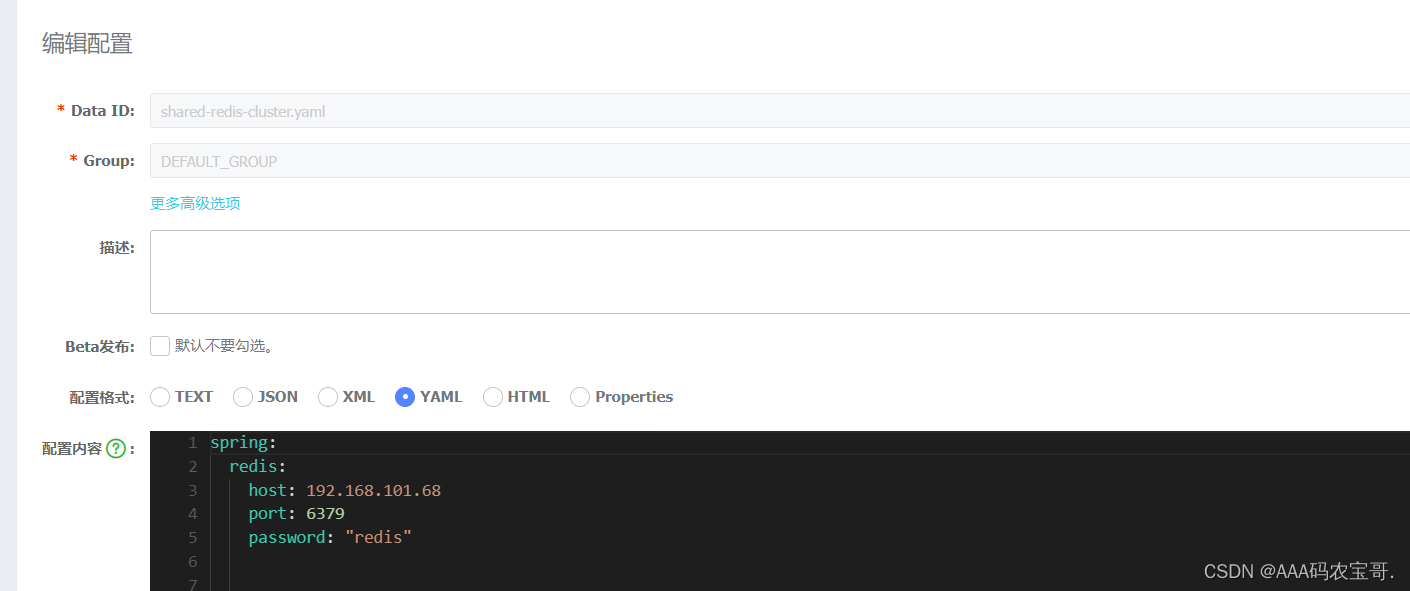
在nacos配置shared-redis-cluster.yaml,开发环境使用redis单机,配置文件如下:
注意配置redis的IP地址、端口和密码。
3.2.3 查询数据时缓存-Cacheable
下边使用Cacheable注解实现查询服务信息时对服务信息进行缓存,它的执行流程是:第一次查询服务信息缓存中没有该服务的信息此时去查询数据库,查询数据库拿到服务信息并进行缓存,第二次再去查询该服务信息发现缓存中有该服务的信息则直接查询缓存不再去数据库查询。
流程如下:
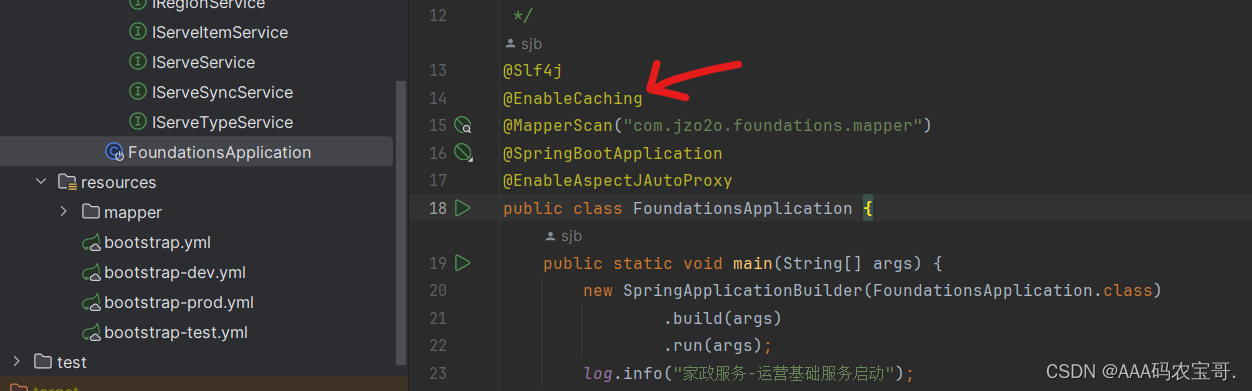
首先在工程启动类中添加@EnableCaching注解,它表示开启Spring cache缓存组件。
@EnableCaching:开启缓存注解功能(在启动类上注释,表示开启缓存注释)
下边实现对区域服务信息查询时进行缓存。
首先找到区域服务信息的service,为了不和原来的getById(Serializable id)查询方法混淆,单独定义查询区域服务信息缓存的方法,如下:
在com.jzo2o.foundations.service.IServeService中,IServeService接口中定义如下接口:
/*** 查询区域服务信息并进行缓存* @param id 对应serve表的主键* @return 区域服务信息*/
Serve queryServeByIdCache(Long id);
在接口实现类中定义如下方法:
@Override
public Serve queryServeByIdCache(Long id) {Serve serve = baseMapper.selectById(id);return serve;
}
此时该方法还是查询数据库。
下边在方法中添加Cacheable注解:
//@Cacheable(value = "JZ_CACHE:SERVE_RECORD",key = "#id")
@Cacheable(value = RedisConstants.CacheName.SERVE,key = "#id")
@Override
public Serve queryServeByIdCache(Long id) {Serve serve = baseMapper.selectById(id);return serve;
}
Cacheable注解配置的两项参数说明:
value:缓存的名称,缓存名称作为缓存key的前缀。
key: 缓存key,支持SpEL表达式,上述代码表示取参数id的值作为key
最终缓存key为:缓存名称+“::”+key,例如:上述代码id为123,最终的key为:JZ_CACHE:SERVE_RECORD::123
SpEL(Spring Expression Language)是一种在 Spring 框架中用于处理字符串表达式的强大工具,它可以实现获取对象的属性,调用对象的方法操作。
keyGenerator:指定一个自定义的键生成器(实现 org.springframework.cache.interceptor.KeyGenerator 接口的类),用于生成缓存的键。与 key 属性互斥,二者只能选其一。
3.2.4 测试
在com.jzo2o.foundations.service.IServeServiceTest中,对queryServeByIdCache方法进行测试,编写单元测试方法,如下:
@SpringBootTest
@Slf4j
class IServeServiceTest {//区域服务查询
@Test
public void test_queryServeByIdCache(){Serve serve = serveService.queryServeByIdCache(1692475249121038338L);Assert.notNull(serve,"服务为空");
}
...
查看当前缓存,并没有JZ开头的kv键值对
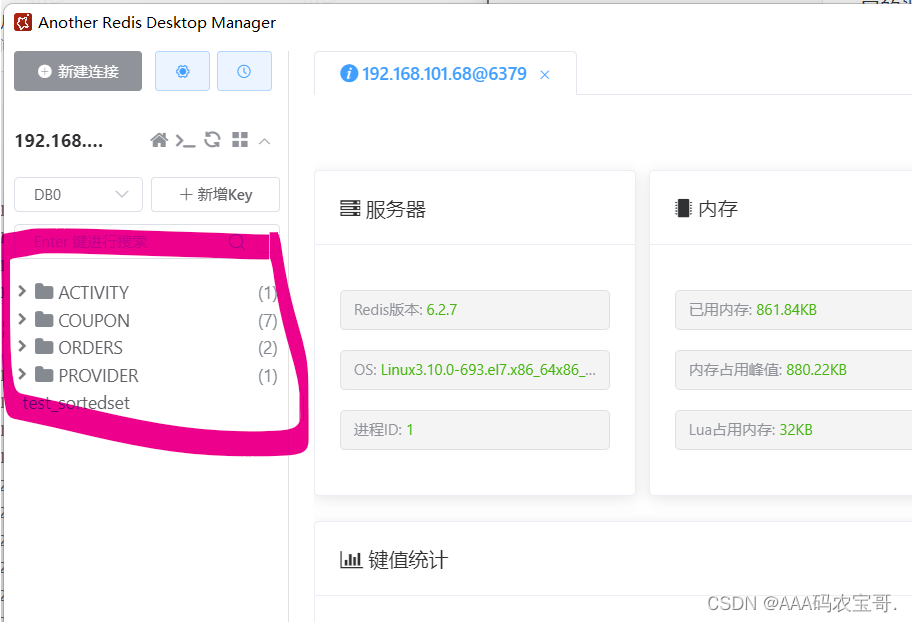
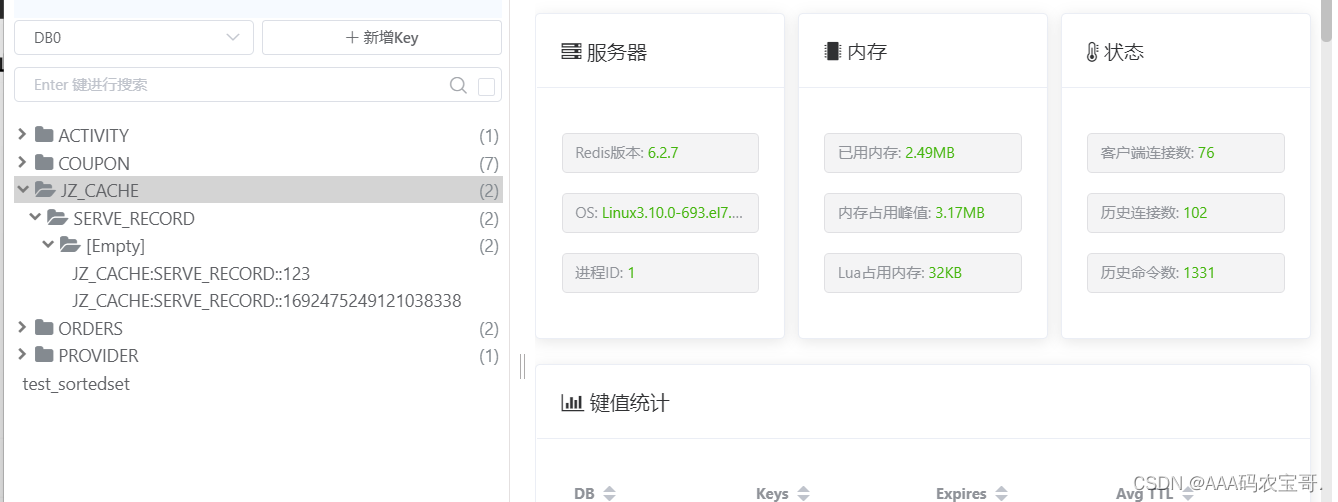
执行测试,查看缓存,成功找到。
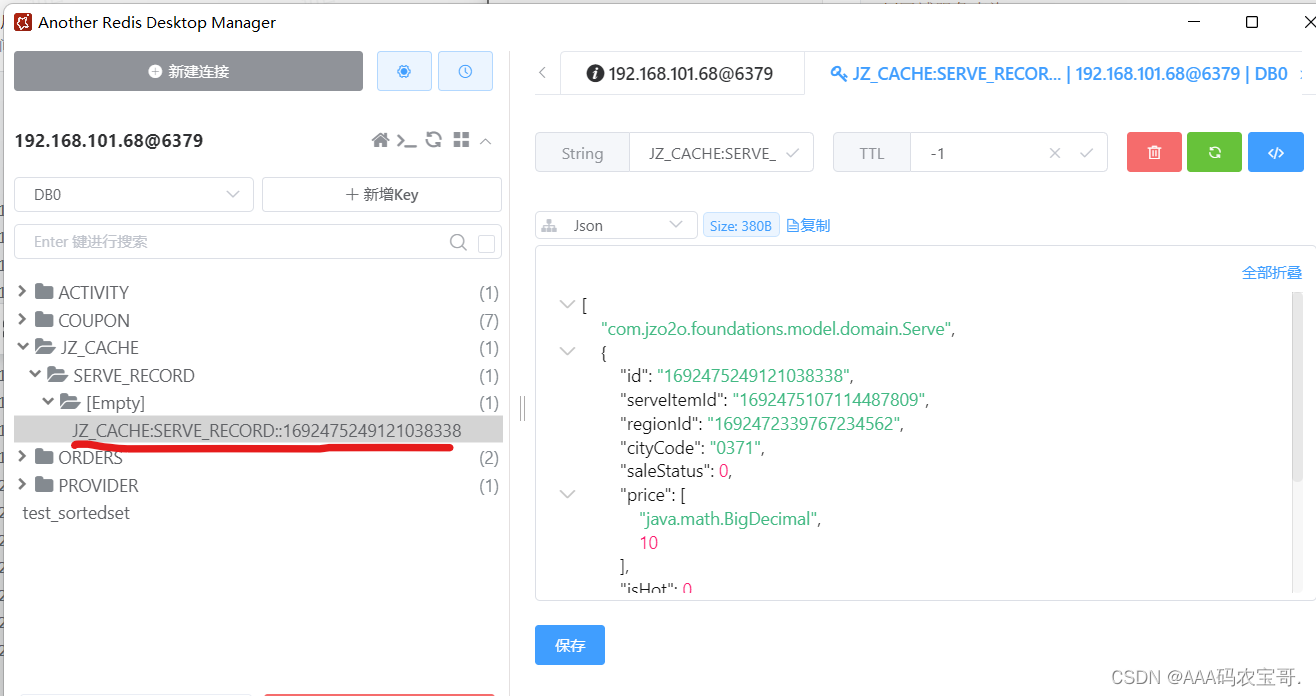
我们可以看到key和value,以及缓存时间ttl=-1,这是不合理的,我们对缓存肯定有时间的限制。
虽然数据被成功缓存,如果想调整缓存过期时间怎么做呢?
在@Cacheable注解中有一个属性为cacheManager,表示缓存管理器,通过缓存管理器可以设置缓存过期时间。
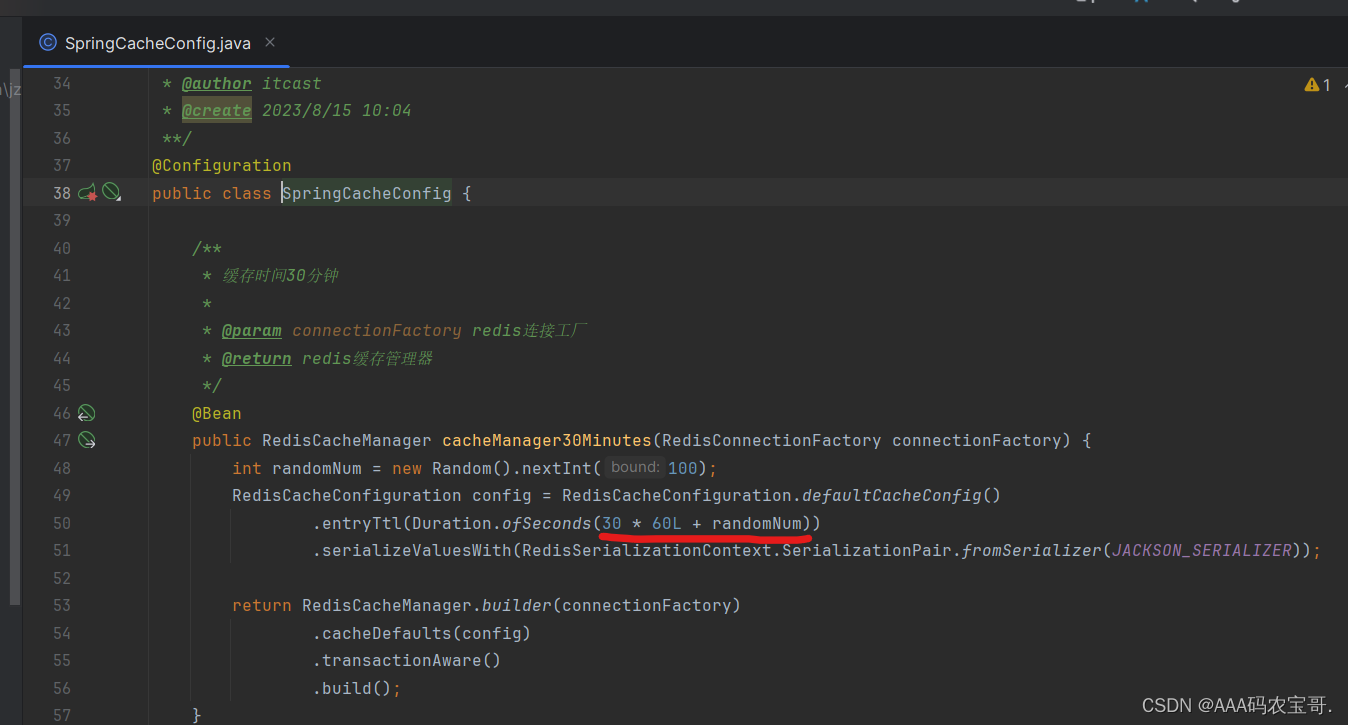
所有缓存相关的基础类都在jzo2o-redis工程,在jzo2o-redis工程定义spring cache需要的缓存管理器,在com.jzo2o.redis.config.SpringCacheConfig中:
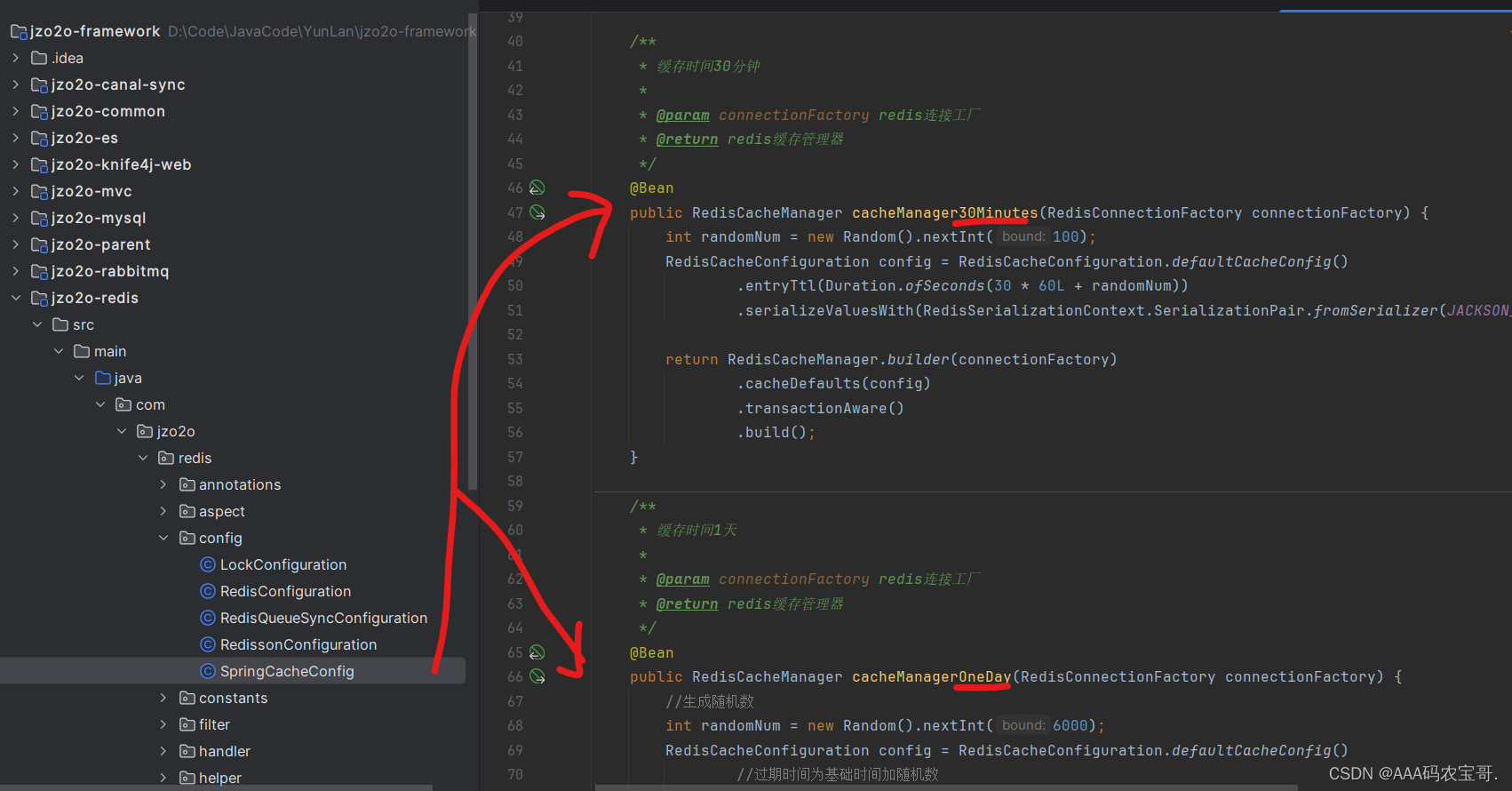
上图中共包括三个缓存管理器:
缓存时间为30分钟、一天、永久,分别对应的bean的名称为:cacheManager30Minutes、cacheManagerOneDay、cacheManagerForever。
下边我们在@Cacheable注解中指定缓存管理器为cacheManagerOneDay,即缓存时间为一天。
@Cacheable(value = RedisConstants.CacheName.SERVE,key = "#id",cacheManager = RedisConstants.CacheManager.ONE_DAY)
@Override
public Serve queryServeByIdCache(Long id) {Serve serve = baseMapper.selectById(id);return serve;
}
重新运行单元测试方法,我们发现缓存的过期时间没有改变,这是为什么?
原因是根据前边的缓存流程:
先查询缓存,如果缓存存在则直接查询缓存返回数据,不再向缓存存储 数据。
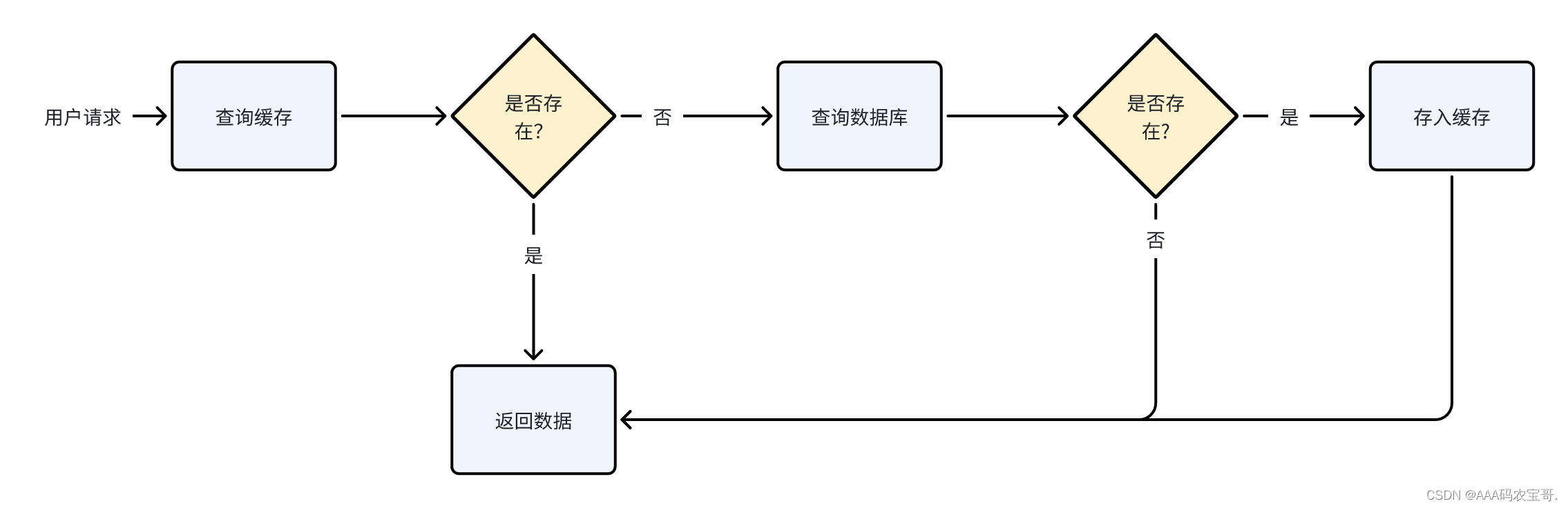
所以我们需要删除缓存,重新运行测试方法:
测试通过,观察redis中的缓存,过期时间已经改变,这说明我们设置的缓存管理器生效。
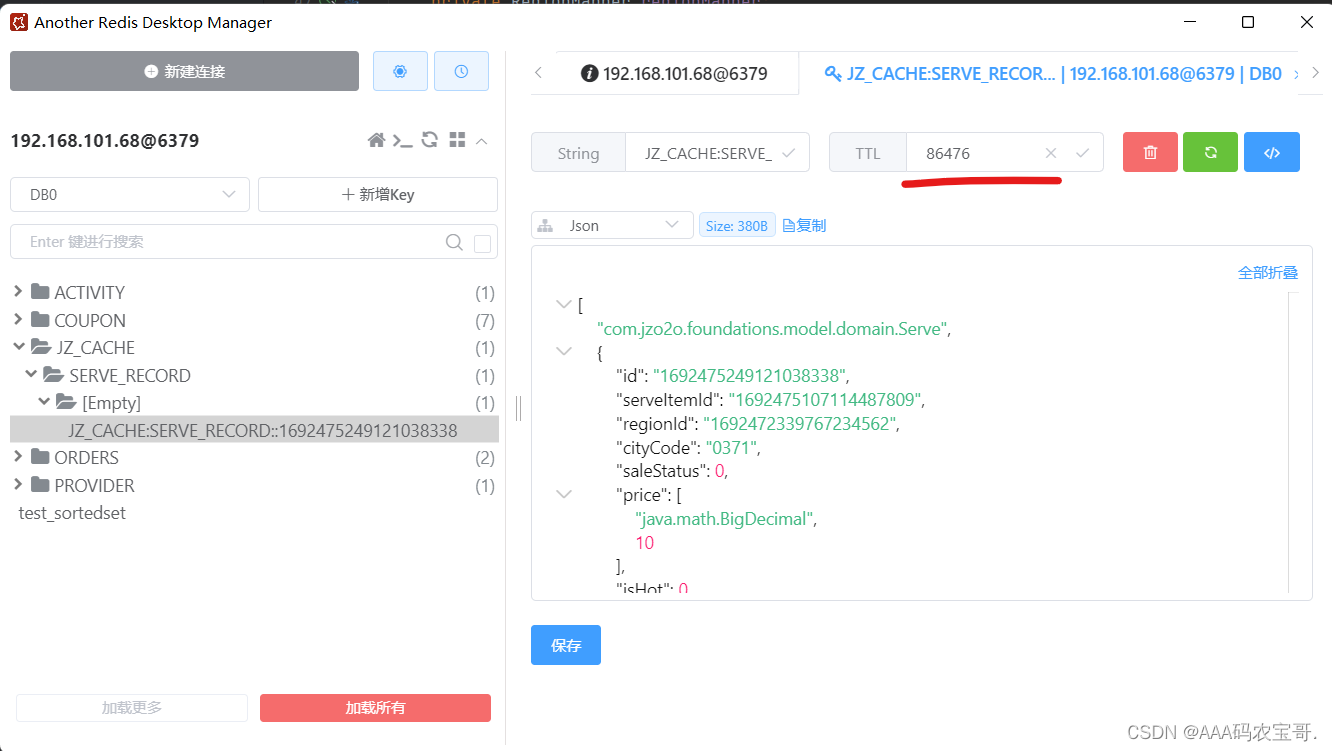
由于缓存时间加了随机数,缓存一天的时间为90000秒左右。
关于缓存时间加随机数的原因稍后讲解。
3.2.5 工作原理
Spring Cache是基于AOP原理,对添加注解@Cacheable的类生成代理对象,在方法执行前查看是否有缓存对应的数据,如果有直接返回数据,如果没有调用源方法获取数据返回,并缓存起来,下边跟踪Spring Cache的切面类CacheAspectSupport.java中的private Object execute(final CacheOperationInvoker invoker, Method method, CacheOperationContexts contexts)方法。
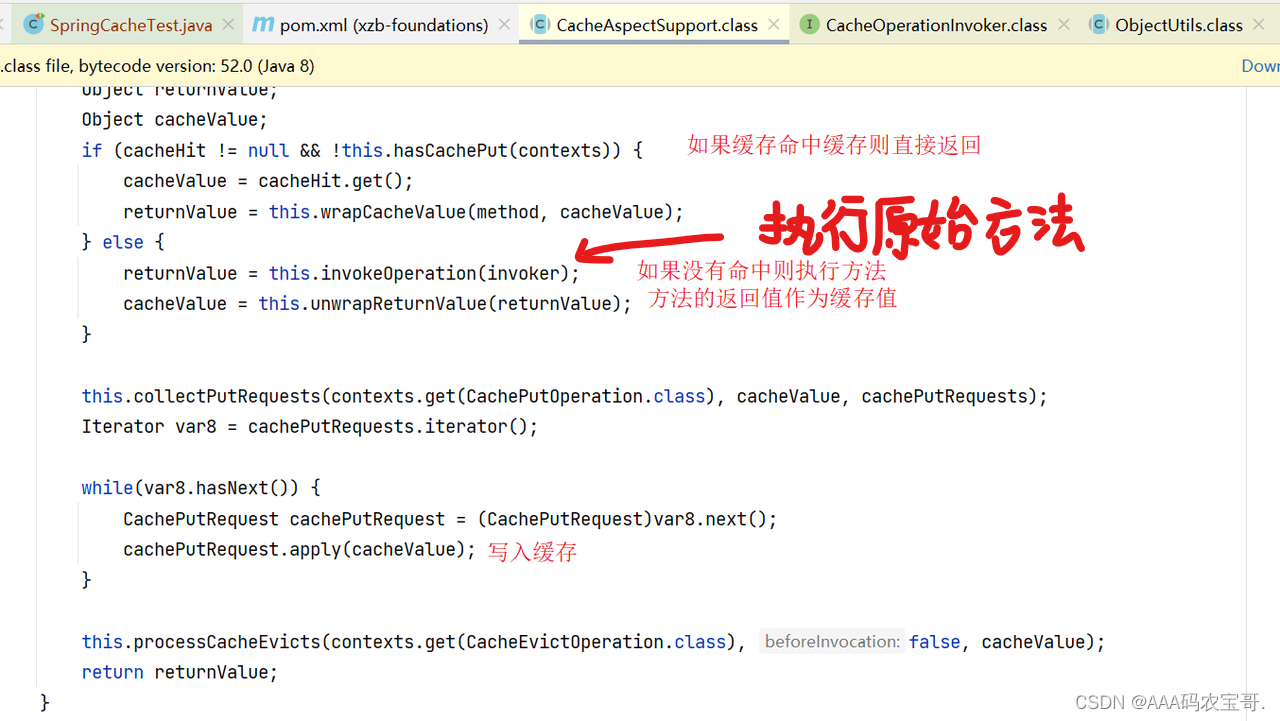
分别测试命中缓存和未命中缓存的情况。
第一次查询(redis中没有缓存)时执行方法查询数据库,第二次命中缓存直接查询redis不再执行方法。
3.3 测试Spring Cache-@CachePut-@CacheEvict
目标:学会使用@CacheEvict和@CachePut注解
在Spring Cache入门中使用了@Cacheable 注解,它实现的是查询时进行缓存。
下边测试另外两个常用 的注解,如下:
@CachePut:用于更新缓存,将方法的返回值放到缓存中
@CacheEvict:用于删除缓存,将一条或多条数据从缓存中删除。
其它注解在项目开中用到时再进行讲解,也可以自行查阅资料测试。
3.3.1 测试@CachePut
CachePut注解实现的是将方法的返回值放到缓存中。
在服务上架后会将区域服务的信息写入缓存,服务下架会从缓存删除,下边我们实现服务上架将服务写入缓存。
找到服务上架的方法,在方法上添加@CachePut注解:
@Override
@Transactional
@CachePut(value = RedisConstants.CacheName.SERVE, key = "#id", cacheManager = RedisConstants.CacheManager.ONE_DAY)
public Serve onSale(Long id){Serve serve = baseMapper.selectById(id);if(ObjectUtil.isNull(serve)){throw new ForbiddenOperationException("区域服务不存在");}//上架状态Integer saleStatus = serve.getSaleStatus();......
上边代码同样指定了缓存名称、缓存key及缓存管理器(缓存过期时间为一天)。
编写单元测试方法测试服务上架方法。
找一个草稿或下架状态的服务执行上架操作,也可以在serve表中找一个测试数据更改状态为0。
选择他进行上架缓存
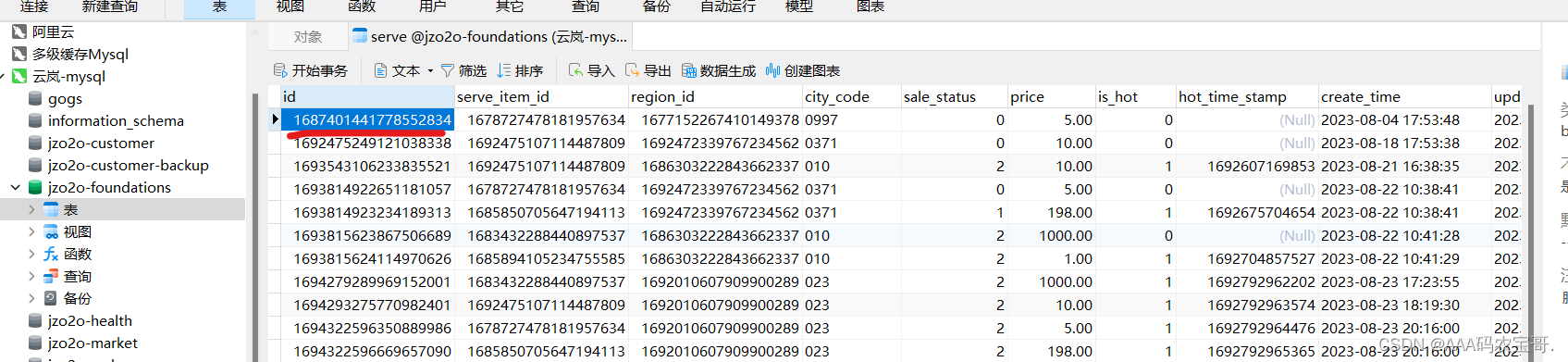
//服务上架测试
@Test
public void test_onSale(){//从serve表找一条下架的服务(sale_status '售卖状态,0:草稿,1下架,2上架',)Serve serve = serveService.onSale(1715263395009191938L);Assert.notNull(serve,"服务为空");
}
启动测试,成功缓存
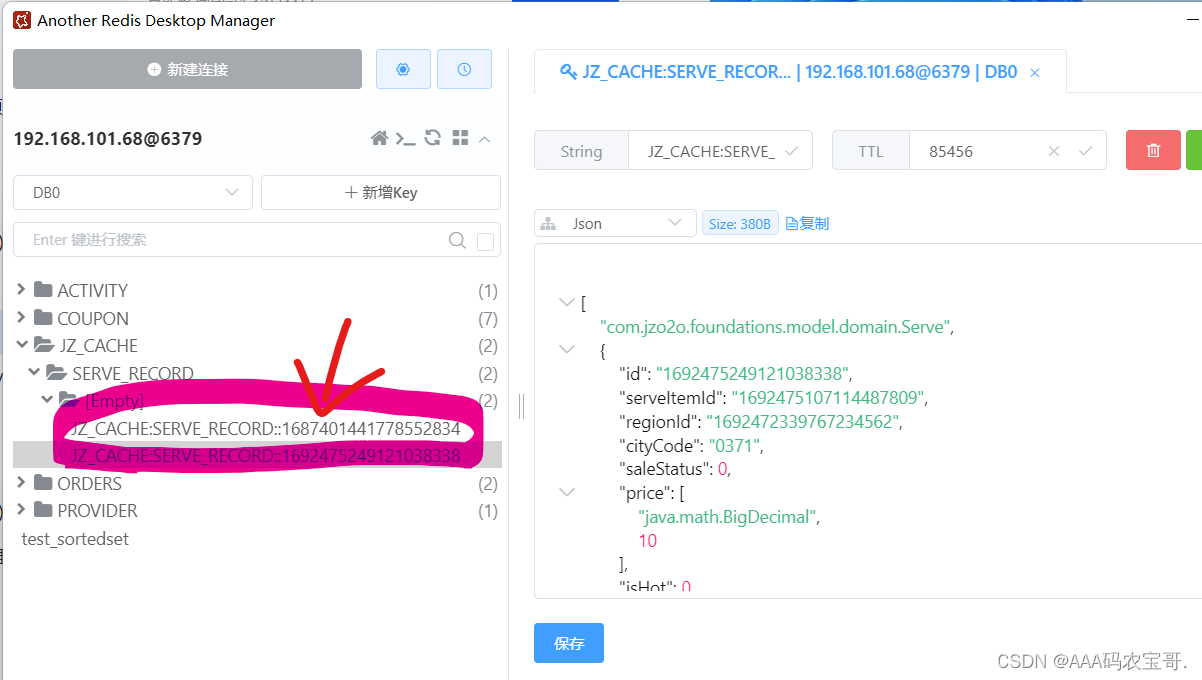
3.3.2 测试@CacheEvict
下边测试服务下架删除缓存。
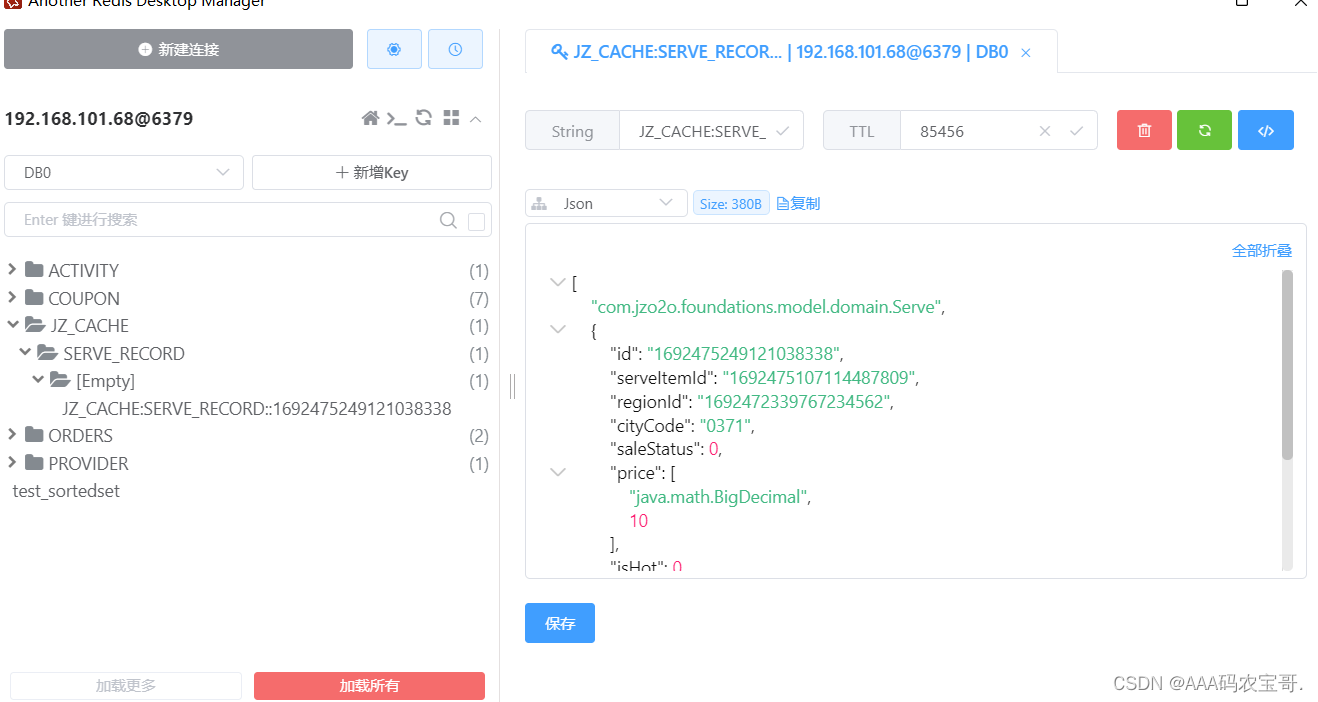
找到服务下架的方法,添加@CacheEvict注解
@Override
@Transactional
@CacheEvict(value = RedisConstants.CacheName.SERVE, key = "#id")
public Serve offSale(Long id){Serve serve = baseMapper.selectById(id);if(ObjectUtil.isNull(serve)){throw new ForbiddenOperationException("区域服务不存在");
这里是删除缓存所以不用再指定缓存管理器。
编写单元测试方法进行测试。
启动测试,删除缓存。
3.3.3 总结
Spring Cache有哪些常用的注解,都有什么用?
@EnableCaching:开启缓存注解功能
@Cacheable:查询数据时缓存,将方法的返回值进行缓存。 @CacheEvict:用于删除缓存,将一条或多条数据从缓存中删除。
@CachePut:用于更新缓存,将方法的返回值放到缓存中 @Caching:组合多个缓存注解;
4 缓存常见问题
4.1 缓存穿透问题
目标:理解缓存穿透问题,掌握缓存穿透的解决方案
在使用缓存时特别是在高并发场景下会遇到很多问题,常用的问题有缓存穿透、缓存击穿、缓存雪崩以及缓存一致性问题。
下边介绍缓存穿透问题及解决方案
4.1.1 什么是缓存穿透问题
缓存穿透是指请求一个不存在的数据,缓存层和数据库层都没有这个数据,这种请求会穿透缓存直接到数据库进行查询。它通常发生在一些恶意用户可能故意发起不存在的请求,试图让系统陷入这种情况,以耗尽数据库连接资源或者造成性能问题。
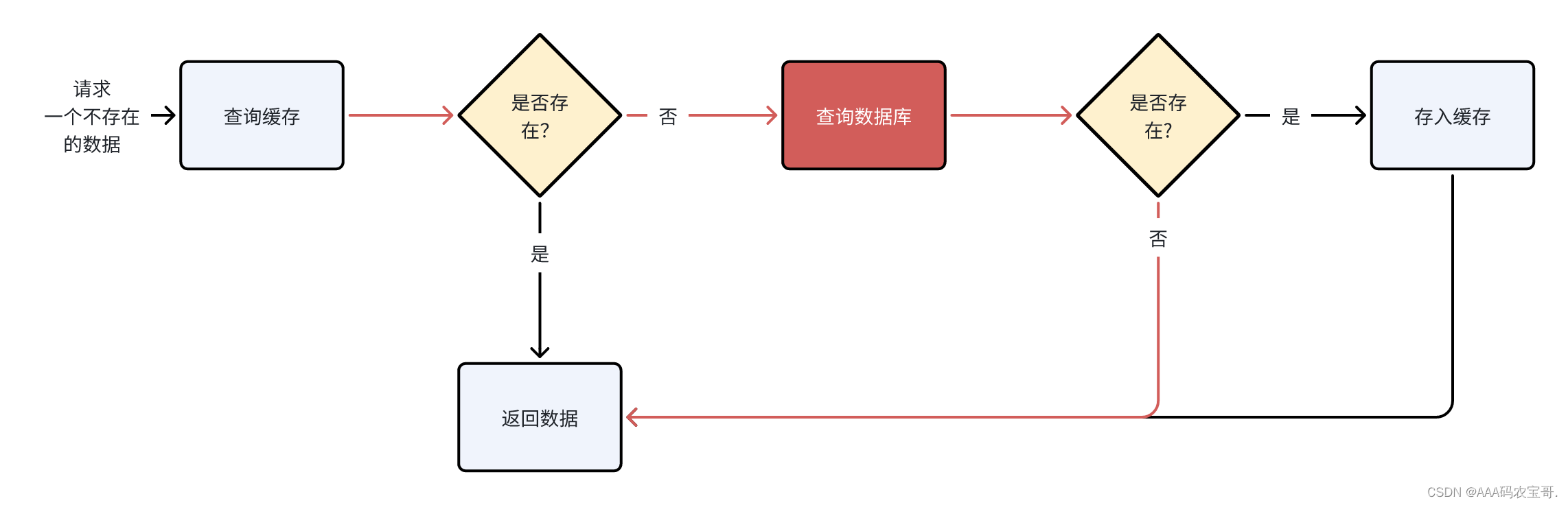
比如:在快速入门程序中,查询一个缓存中不存在的数据将会执行方法查询数据库,数据库也不存在此数据,查询完数据库也没有缓存数据,缓存没有起到作用。
4.1.2 解决方案
如何解决缓存穿透?
4.1.2.1 对请求增加校验机制
比如:查询的Id是长整型并且是19位,如果发来的不是长整型或不符合位数则直接返回不再查询数据库。
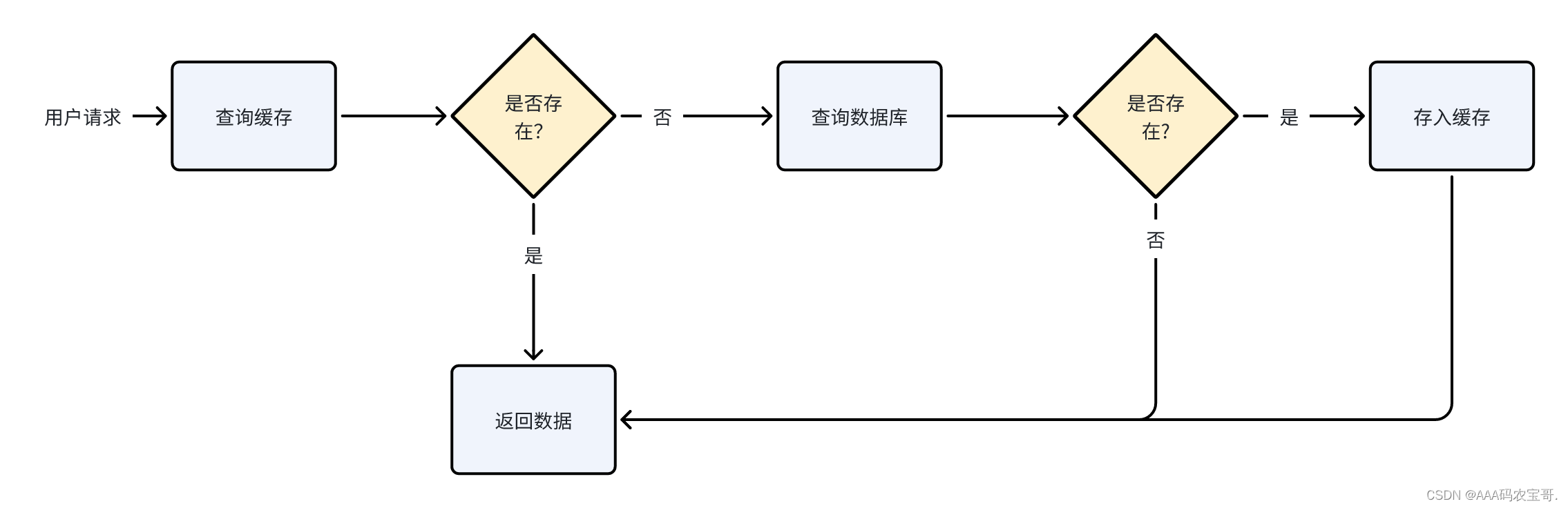
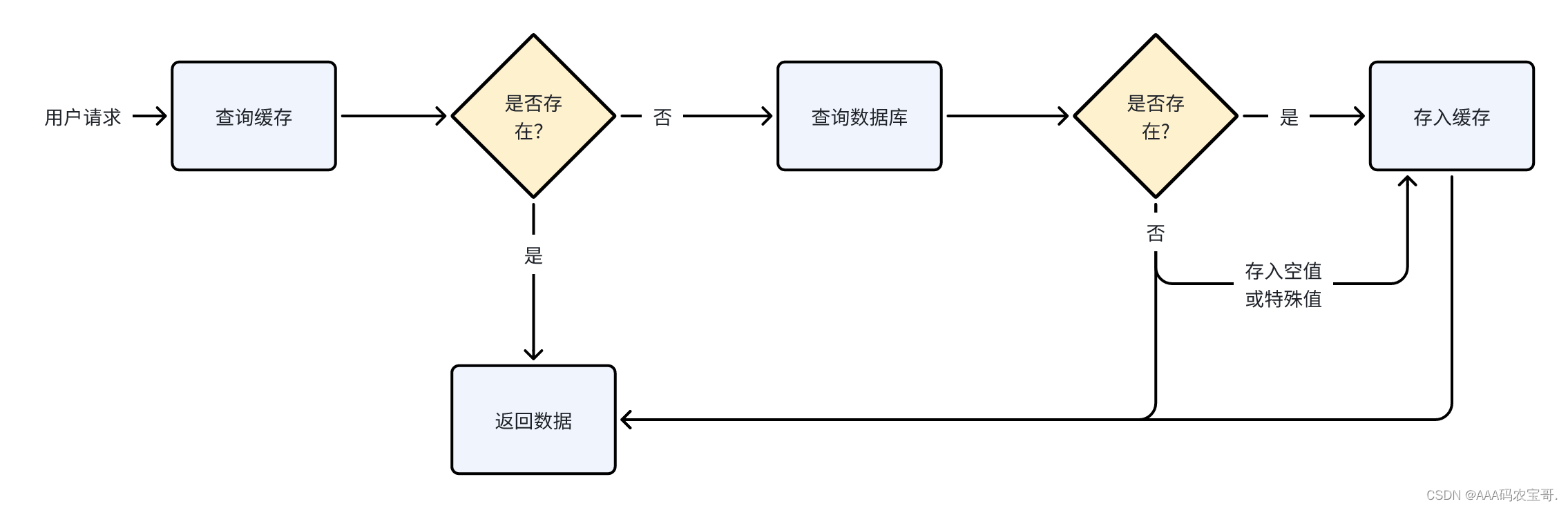
4.1.2.2 缓存空值或特殊值
当查询数据库得到的数据不存在,此时我们仍然去缓存数据,缓存一个空值或一个特殊值的数据,避免每次都会查询数据库,避免缓存穿透。
流程如下:
下边通过测试查询区域服务,查询一下不存在的区域服务:
//区域服务查询
@Test
public void test_queryServeByIdCache2(){//指定一个不存在serve表的idServe serve = serveService.queryServeByIdCache(123L);Assert.notNull(serve,"服务为空");
}
当查询一个数据库不存在的数据时向redis缓存了NullValue对象。
第一次会查询数据库,得到一个空值,缓存一个空值。
第二次不再查询数据库。
第一次进入方法查询数据库,第二次不进入方法直接从缓存查询出空值。
查看redis,缓存内容如下:
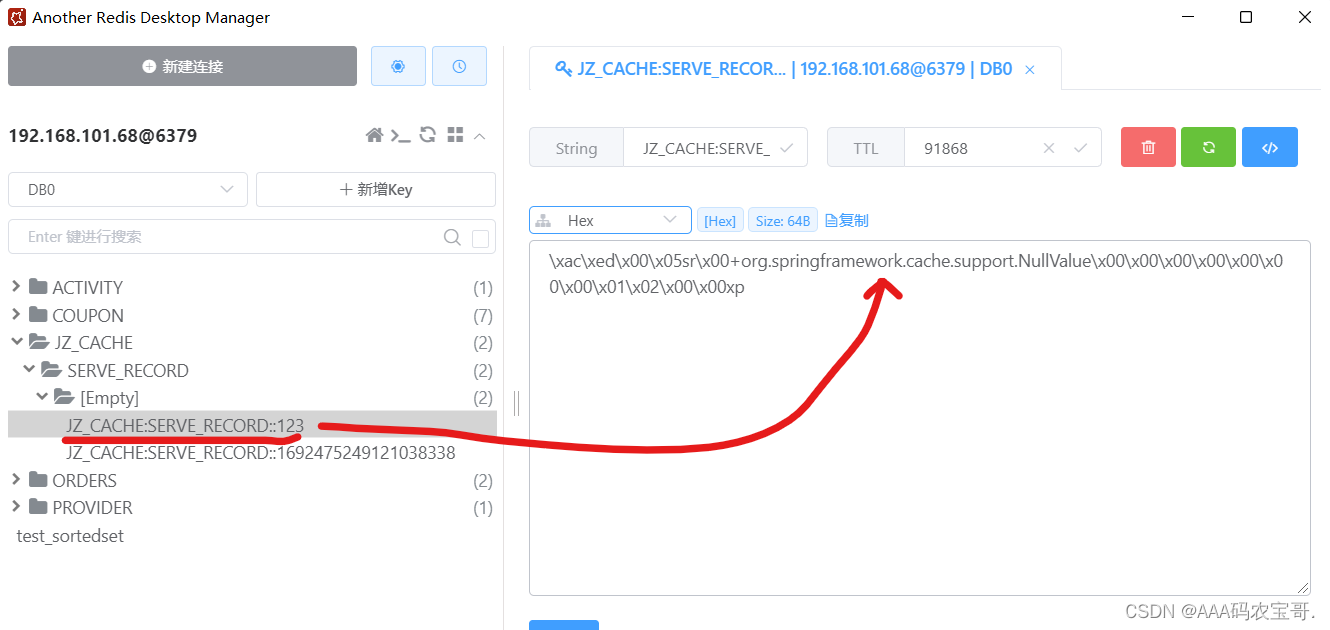
4.1.2.3 使用布隆过滤器
1) 什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种数据结构,用于快速判断一个元素是否属于一个集合中。
它使用多个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点,将Bit array理解为一个二进制数组,数组元素是0或1。
当一个元素加入集合时,通过N个散列函数将这个元素映射到一个Bit array中的N个点,把它们设置为1。
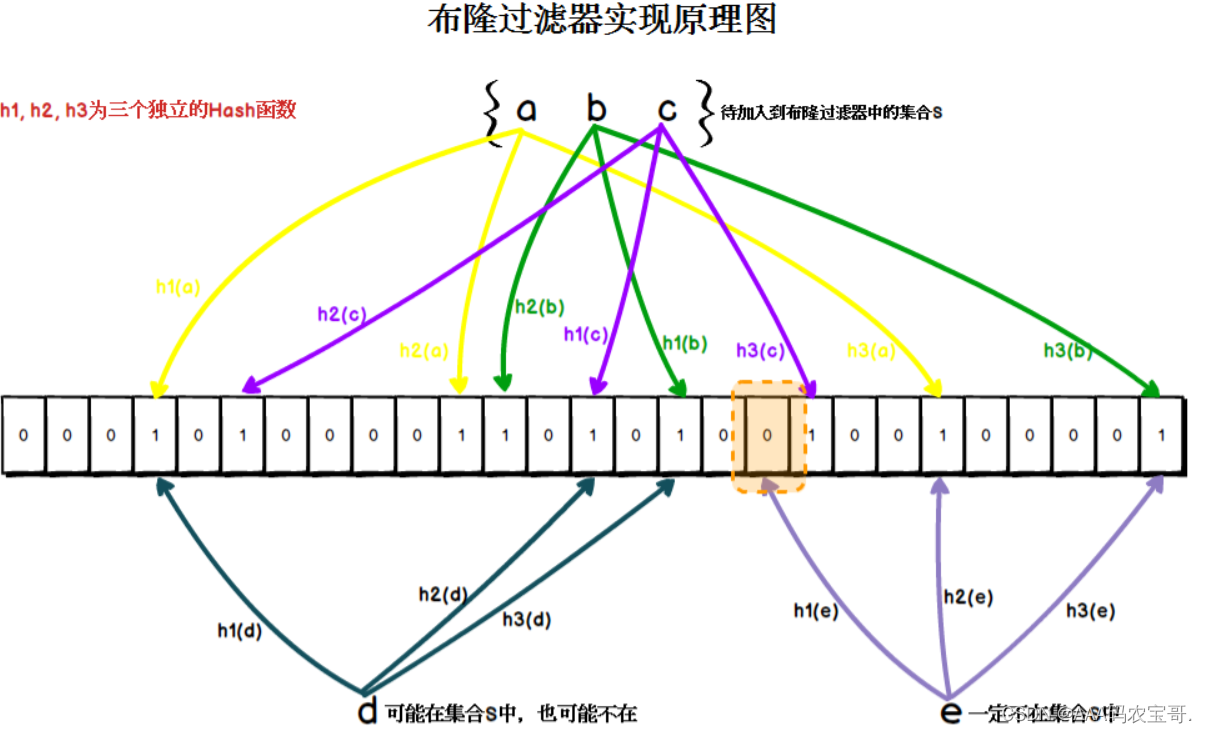
检索某个元素时再通过这N个散列函数对这个元素进行映射,根据映射找到具体位置的元素,如果这些位置有任何一个0,则该元素一定不存在,如果都是1很可能存在误判。
哈希函数的基本特性:
同一个数使用同一个哈希函数计算哈希值,其哈希值总是一样的。
对不同的数用相同的哈希函数计算哈希值,其哈希值可能一样,这称为哈希冲突。
哈希函数通常是单向的不可逆的,即从哈希值不能逆向推导出原始输入。这使得哈希函数适用于加密和安全应用。
为什么会存在误判?
主要原因是哈希冲突。布隆过滤器使用多个哈希函数将输入的元素映射到位数组中的多个位置,当多个不同的元素通过不同的哈希函数映射到相同的位数组位置时就发生了哈希冲突。
由于哈希函数的有限性,不同的元素可能会映射到相同的位置上,这种情况下即使元素不在布隆过滤器中可能产生误判,即布隆过滤器判断元素在集合中。
如何降低误判率?
增加Bit array空间,减少哈希冲突,优化散列函数,使用更多的散列函数。
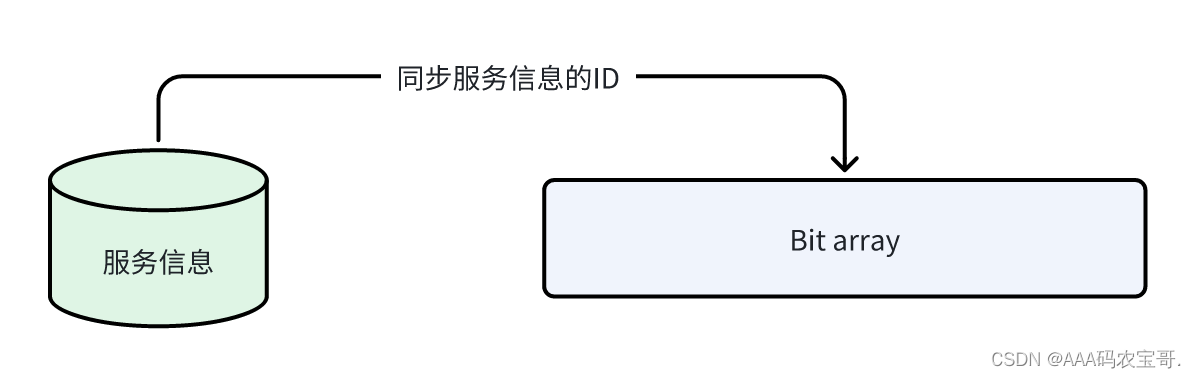
2) 如何使用布隆过滤器?
将要查询的元素通过N个散列函数提前全部映射到Bit array中,比如:查询服务信息,需要将全部服务的id提前映射到Bit array中,当去查询元素是否在数据库存在时从布隆过滤器查询即可,如果哈希函数返回0则表示肯定不存在。
布隆过滤器的优点是:二进制数组占用空间少,插入和查询效率高效。
缺点是存在误判率,并且删除困难,因为同一个位置由于哈希冲突可能存在多个元素,删除某个元素可能删除了其它元素。
布隆过滤器的应用场景?
1、海量数据去重,比如URL去重,搜索引擎爬虫抓取网页,使用布隆过滤器可以快速判定一个URL是否已经被爬取过,避免重复爬取。
2、垃圾邮件过滤:使用布隆过滤器可以用于快速判断一个邮件地址是否是垃圾邮件发送者,对于海量的邮件地址,布隆过滤器可以提供高效的判定。
3、安全领域:在网络安全中,布隆过滤器可以用于检查一个输入值是否在黑名单中,用于快速拦截一些潜在的恶意请求。
4、避免缓存穿透:通过布隆过滤器判断是否不存在,如果不存在则直接返回。
3) 如何代码实现布隆过滤器?
使用redit的bitmap位图结构实现。
使用redisson实现。
使用google的Guava库实现。
下边举例说明:
引入依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.2-jre</version>
</dependency>
测试代码:
public class BloomFilterExample {public static void main(String[] args) {// 创建一个布隆过滤器,预期元素数量为1000,误判率为0.01BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000, 0.01);// 添加元素到布隆过滤器bloomFilter.put("example1");bloomFilter.put("example2");bloomFilter.put("example3");// 测试元素是否在布隆过滤器中System.out.println(bloomFilter.mightContain("example1")); // trueSystem.out.println(bloomFilter.mightContain("example4")); // false}
}
在上述代码中,我们创建了一个预期包含1000个元素、误判率为0.01的布隆过滤器。然后,我们向布隆过滤器中添加了三个元素(“example1”、“example2” 和 “example3”),并测试了几个元素是否在布隆过滤器中。
请注意,误判率是你可以调整的一个参数。较低的误判率通常需要更多的空间和计算资源。
4.1.3 小结
本项目使用缓存空值或特殊值的方法去解决缓存穿透。
4.2 缓存击穿问题
目标:理解缓存击穿问题,掌握缓存击穿的解决方案。
4.2.1 什么是缓存击穿
缓存击穿发生在访问热点数据,大量请求访问同一个热点数据,当热点数据失效后同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用。
比如某手机新品发布,当缓存失效时有大量并发到来导致同时去访问数据库。
4.2.2 解决方案
4.2.2.1 使用锁
单体架构下(单进程内)可以使用同步锁控制查询数据库的代码,只允许有一个线程去查询数据库,查询得到数据库存入缓存。
synchronized(obj){//查询数据库//存入缓存
}
分布式架构下(多个进程之间)可以使用分布式锁进行控制。
// 获取分布式锁对象
RLock lock = redisson.getLock("myLock");
try {// 尝试加锁,最多等待100秒,加锁后自动解锁时间为30秒boolean isLocked = lock.tryLock(100, 30, java.util.concurrent.TimeUnit.SECONDS);if (isLocked) {//查询数据库//存入缓存} else {System.out.println("获取锁失败,可能有其他线程持有锁");}
} catch (InterruptedException e) {e.printStackTrace();
} finally {// 释放锁lock.unlock();System.out.println("释放锁...");
}
4.2.2.2 热点数据不过期
可以由后台程序提前将热点数据加入缓存,缓存过期时间不过期,由后台程序做好缓存同步。
例如:当服务上架后将服务信息缓存到redis且永不过期,此时需要使用put注解。
4.2.2.3 缓存预热
分为提前预热、定时预热。
提前预热就是提前写入缓存。
定时预热是使用定时程序去更新缓存。
4.2.2.4 热点数据查询降级处理
对热点数据查询定义单独的接口,当缓存中不存在时走降级方法避免查询数据库。
4.2.3 小结
本项目对热点数据定时预热,使用定时任务刷新缓存保证缓存永不过期,解决缓存穿透问题。
4.3 缓存雪崩问题
目标:理解缓存雪崩问题,掌握缓存雪崩的解决方案。
4.3.1 什么是缓存雪崩
缓存雪崩是缓存中大量key失效后当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用。
比如对某信息设置缓存过期时间为30分钟,在大量请求同时查询该类信息时,此时就会有大量的同类信息存在相同的过期时间,一旦失效将同时失效,造成雪崩问题。
4.3.2 解决方案
4.3.2.1 使用锁进行控制
思路同缓存击穿。
4.3.2.2 对同一类型信息的key设置不同的过期时间
通常对一类信息的key设置的过期时间是相同的,这里可以在原有固定时间的基础上加上一个随机时间使它们的过期时间都不相同。
具体实现:在framework工程中定义缓存管理器指定过期时间加上随机数。
4.3.2.3 缓存定时预热
不用等到请求到来再去查询数据库存入缓存,可以提前将数据存入缓存。使用缓存预热机制通常有专门的后台程序去将数据库的数据同步到缓存。
4.3.3 小结
本项目对key设置不同的过期时间解决缓存雪崩问题。
4.4 缓存不一致问题
4.4.1 什么是缓存不一致问题
缓存不一致问题是指当发生数据变更后该数据在数据库和缓存中是不一致的,此时查询缓存得到的并不是与数据库一致的数据。
**缓存不一致会导致什么后果?**比如:查看商品信息的价格与真实价格不一致,影响用户体验,如果直接使用缓存中的价格去计算订单金额更会导致计算结果错误。
造成缓存不一致的原因可能是在写数据库和写缓存两步存在异常,也可能是并发所导致。
写数据库和写缓存导致不一致称为双写不一致,比如:先更新数据库成功了,更新缓存时失败了,最终导致不一致。
并发导致缓存不一致举例如下:
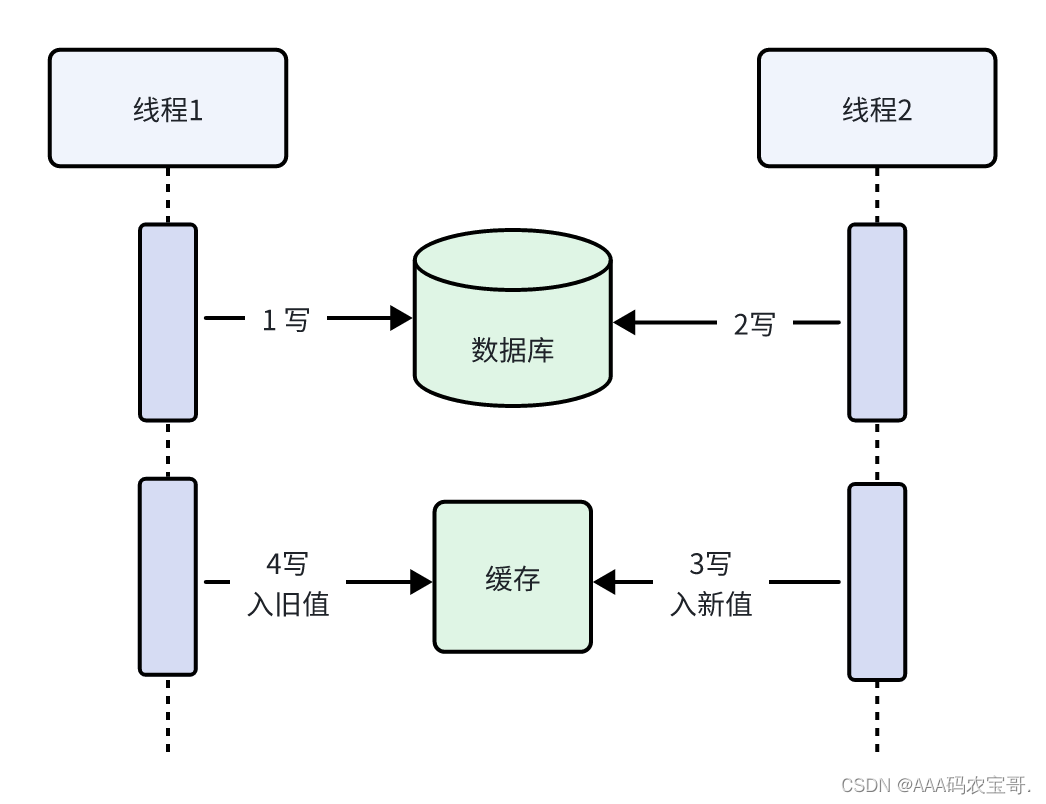
执行流程:
线程1先写入数据库X,当去写入缓存X时网络卡顿
线程2先写入数据库Y
线程2再写入缓存Y
线程1 写入缓存旧值X覆盖了新值Y
即使先写入缓存再写数据在并发环境也可能存在问题,如下图:
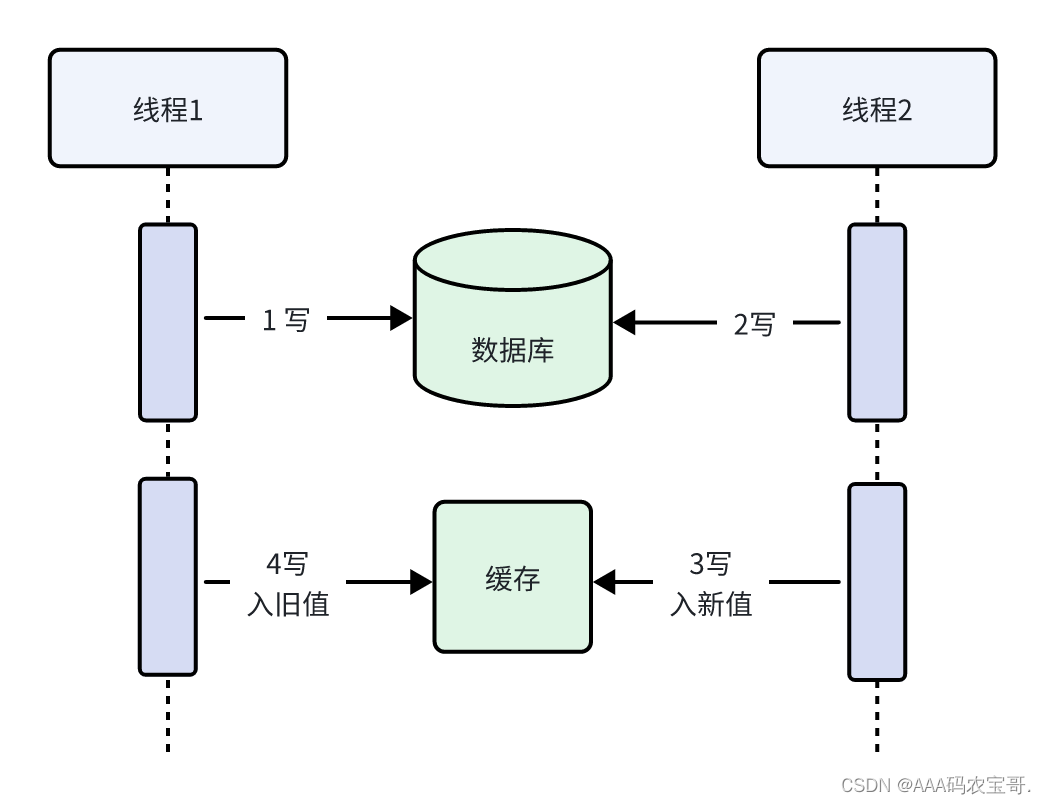
流程:
线程1先写入缓存X,当去写入数据库X时网络卡顿
线程2先写入缓存Y
线程2再写入数据库Y
线程1 写入数据库旧值X覆盖了新值Y
4.4.2 解决方案
4.4.2.1 使用分布式式锁
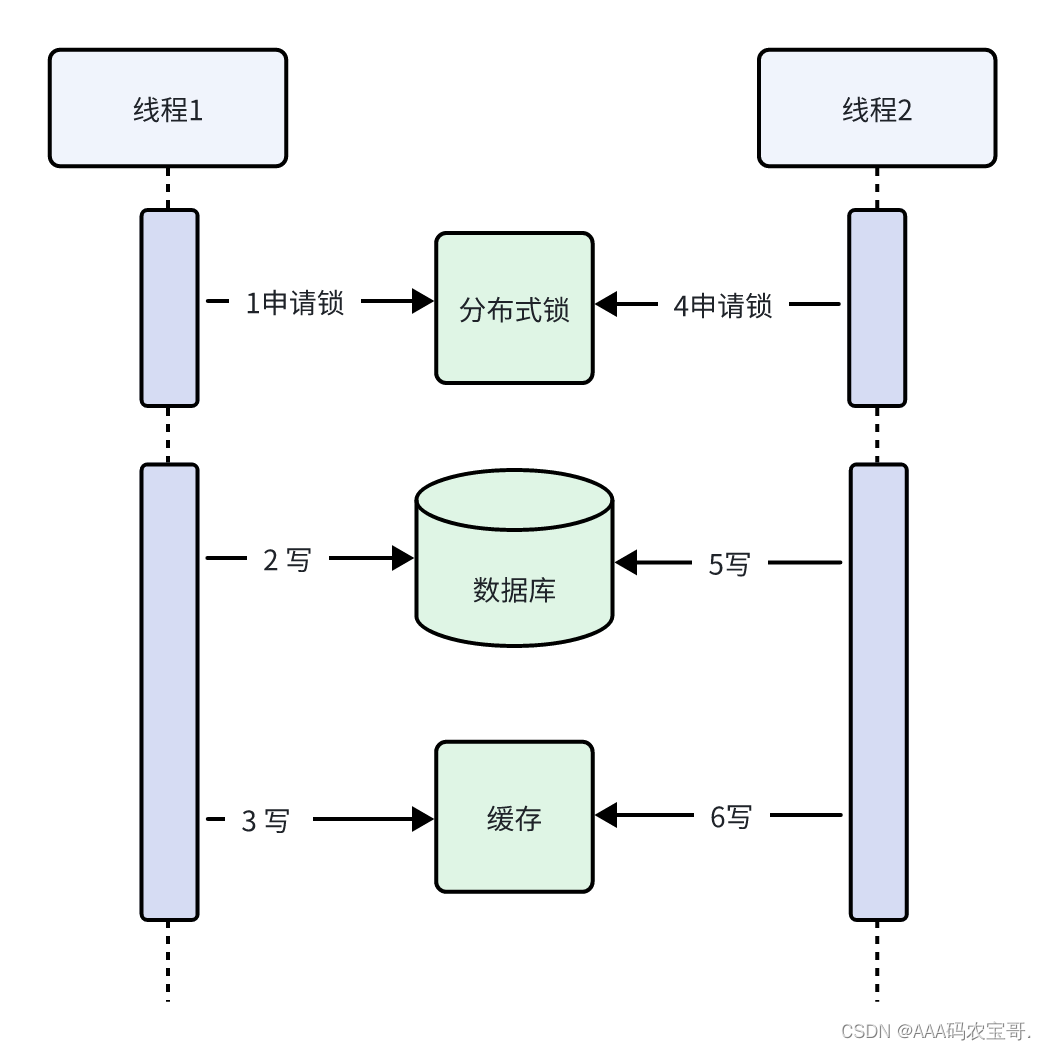
流程:
线程1申请分布式锁,拿到锁。此时其它线程无法获取同一把锁。
线程1写数据库,写缓存,操作完成释放锁。
线程2申请分布锁成功,写数据库,写缓存。
对双写的操作每个线程顺序执行。
对操作异常问题仍需要解决:写数据库成功写缓存失败了,数据库需要回滚,此时就需要使用分布式事务组件。
使用分布式锁解决双写一致性不仅性能低下,复杂度增加。
4.4.2.2 延迟双删
既然双写操作存在不一致,我们把写缓存改为删除缓存呢?
先写数据库再删除缓存,如果删除缓存失败了缓存也就不一致了,那我们改为:先删除缓存再写数据库,如下图:
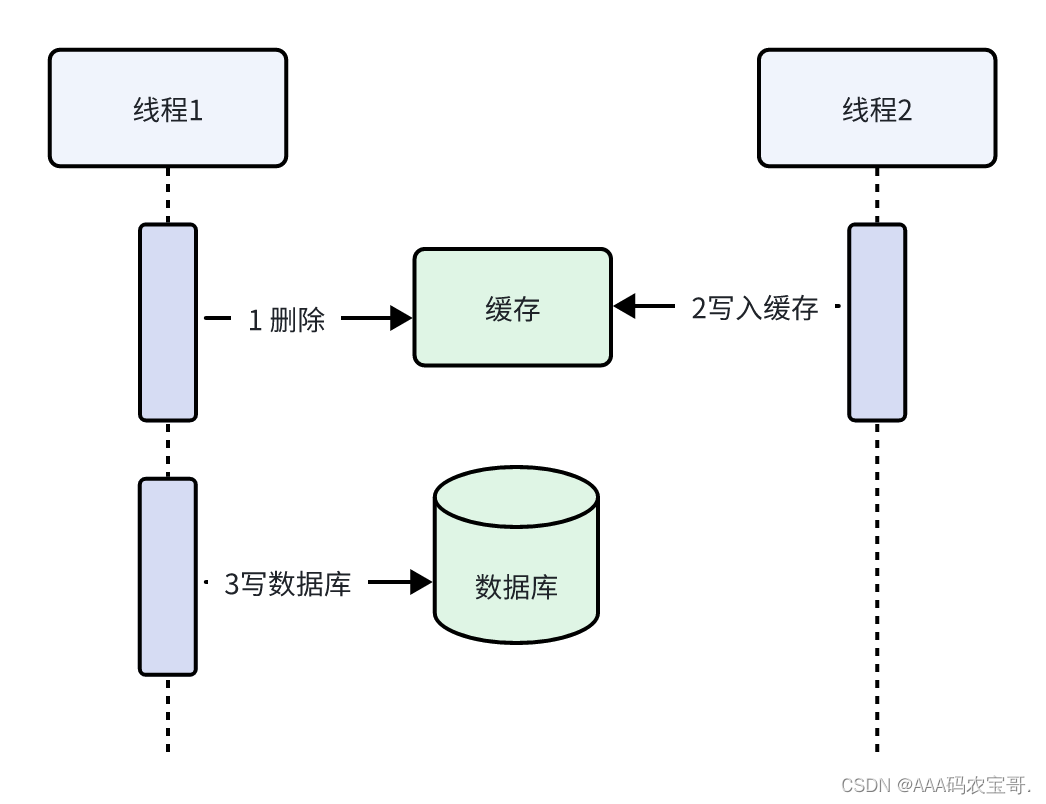
执行流程:
线程1删除缓存
线程2读缓存发现没有数据此时查询数据库拿到旧数据写入缓存
线程1写入数据库
即使线程1删除缓存、写数据库操作后线程2再去查询缓存也可能存在问题,如下图:
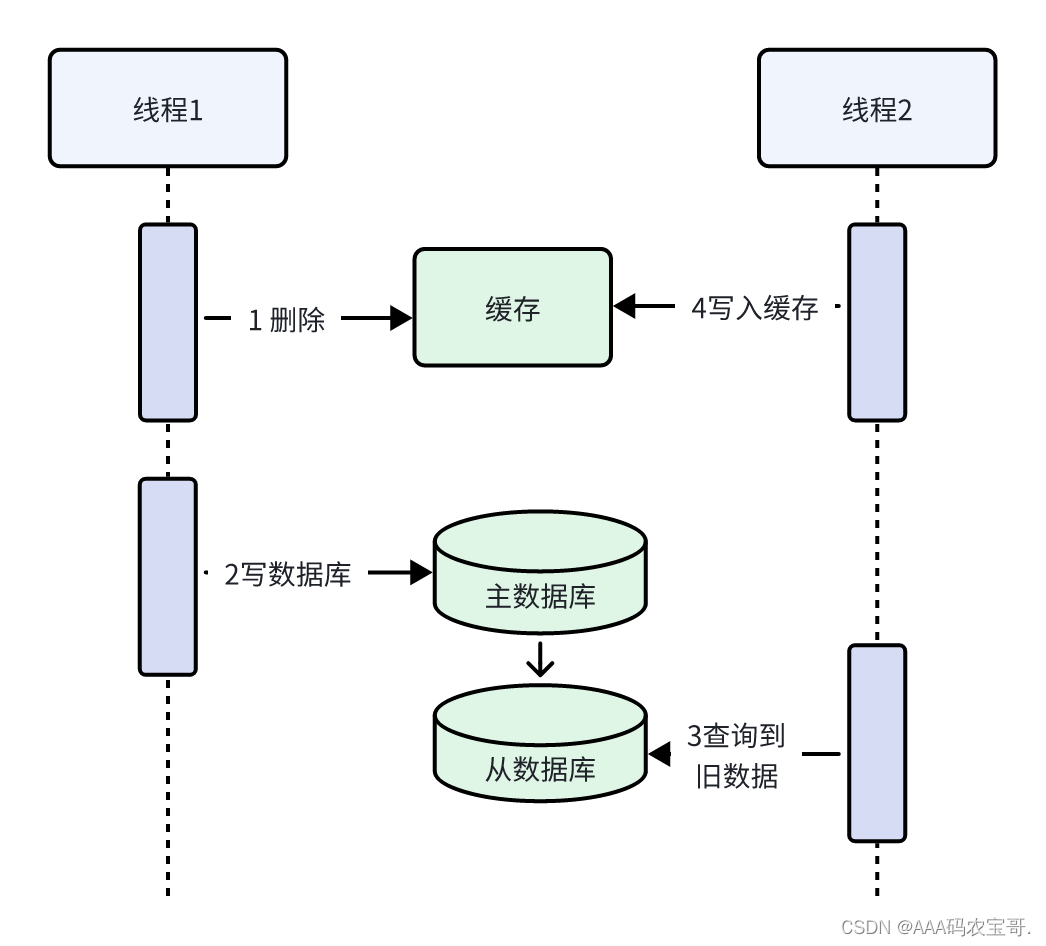
线程1向主数据库写,线程2向从数据库查询,流程如下:
线程1删除缓存
线程1向主数据库写,数据向从数据库同步
线程2查询缓存没有数据,查询从数据库,得到旧数据
线程2将旧数据写入缓存
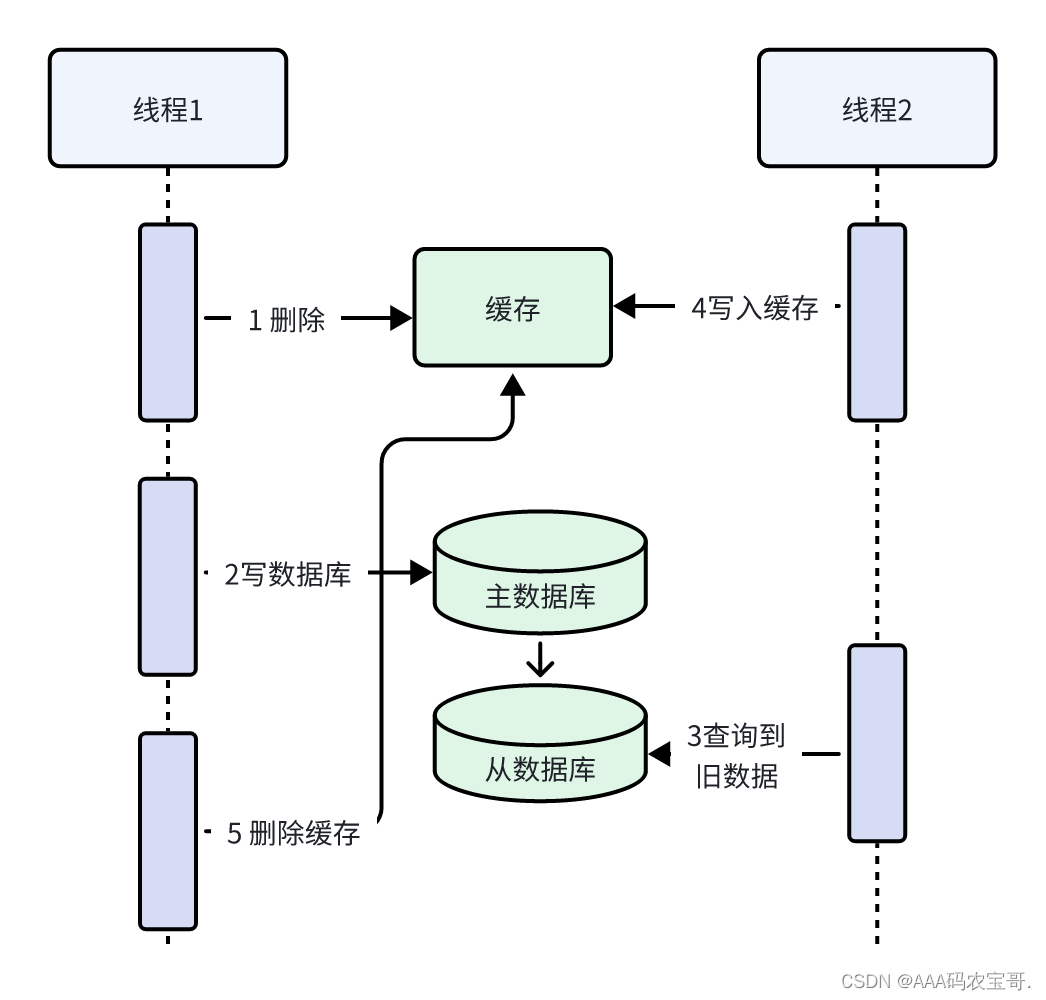
解决上边的问题采用延迟双删:
线程1先删除缓存,再写入主数据库,延迟一定时间再删除缓存。
上图线程1的动作简化为下图:
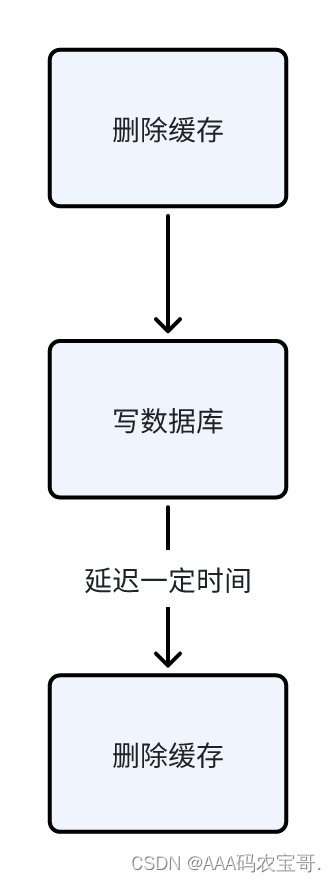
延迟多长时间呢?
延迟主数据向从数据库同步的时间间隔,如果延迟时间设置不合理也会导致数据不一致。
4.4.2.3 异步同步
延迟双删的目的也是为了保证最终一致性,即允许缓存短暂不一致,最终保证一致性。
保证最终一致性的方案有很多,比如:通过MQ、Canal、定时任务都可以实现。
Canal是一个数据同步工具,读取MySQL的binlog日志拿到更新的数据,再通过MQ发送给异步同步程序,最终由异步同步程序写到redis。此方案适用于对数据实时性有一定要求的场景。
通过Canal加MQ异步任务方式流程如下:
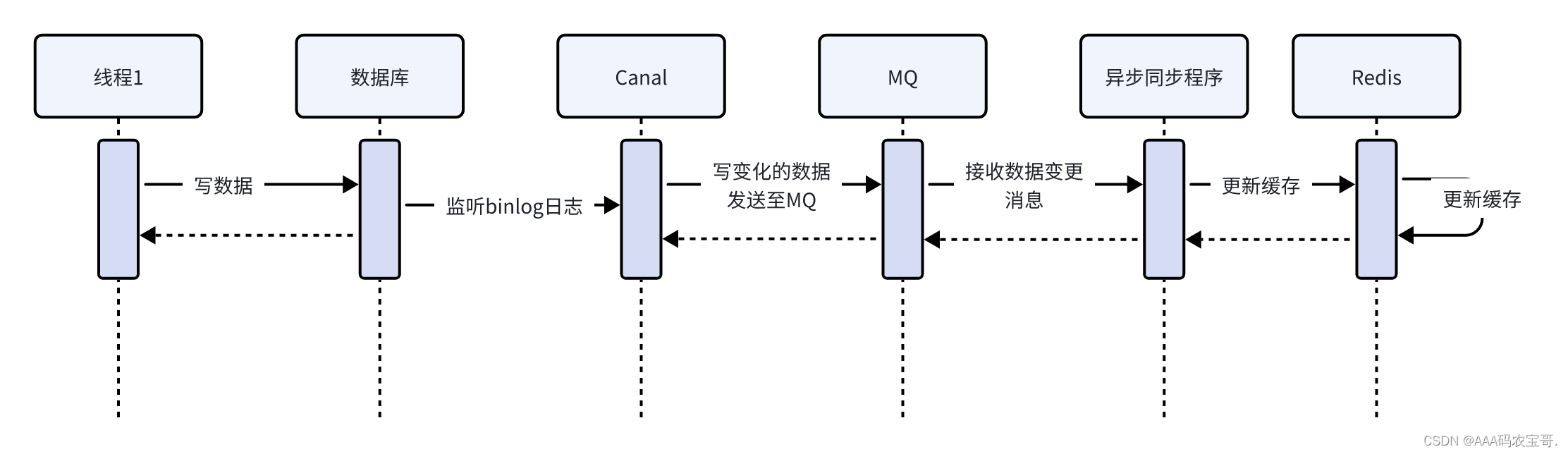
流程如下:
线程1写数据库
canal读取binlog日志,将数据变化日志写入mq
同步程序监听mq接收到数据变化的消息
同步程序解析消息内容写入redis,写入redis成功正常消费完成,消息从mq删除。
定时任务方式流程如下:
专门启动一个数据同步任务定时读取数据同步到redis,此方式适用于对数据实时性要求不强更新不频繁的数据。
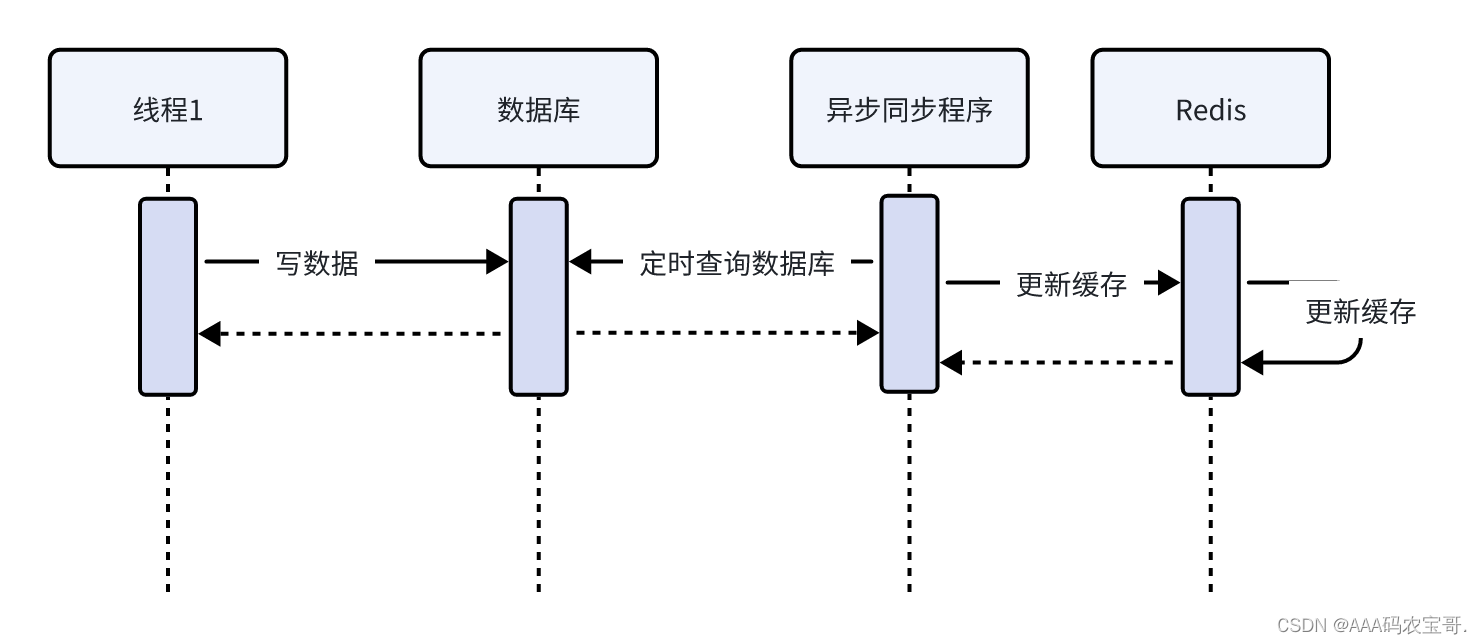
线程1写入数据库(业务数据表,变化日志表)
同步程序读取数据库(变化日志表),根据变化日志内容写入redis,同步完成删除变化日志。
定时时间短,实时性强,cpu占用高,定时时间长,实时性不强,cpu占用低。
4.4.3 小结
我们项目采用Canal和MQ的流程
5 缓存实现
5.1 开通区域列表缓存实现
实现开通区域列表缓存(完成查询缓存、删除缓存)。
5.1.1 缓存方案分析
| 信息内容类型 | 缓存过期时间 | 缓存结构 | 缓存key | 缓存同步方案 |
|---|---|---|---|---|
| 开通区域列表 | 永久缓存 | String | JZ_CACHE::ACTIVE_REGIONS | 查询缓存:查询开通区域列表进行缓存 启用区域:删除开通区域缓存 禁用区域:删除开通区域及其它信息 由定时任务每天凌晨更新缓存 |
| 首页服务列表 | 永久缓存 | String | JZ_CACHE:SERVE_ICON::区域id | 查询缓存:初次查询进行缓存 禁用区域:删除本区域的首页服务列表缓存 由定时任务每天凌晨更新缓存 |
| 服务类型列表 | 永久缓存 | String | JZ_CACHE:SERVE_TYPE::区域id | 查询缓存:初次查询直接缓存 禁用区域:删除本区域的服务类型列表缓存 由定时任务每天凌晨更新缓存 |
| 热门服务列表 | 永久缓存 | String | JZ_CACHE:HOT_SERVE::区域id | 查询缓存:初次查询直接缓存 禁用区域:删除本区域的热门服务列表缓存 由定时任务每天凌晨更新缓存 |
| 服务项信息 | 缓存1天 | String | JZ_CACHE:SERVE_ITEM::服务项id | 启动:添加缓存 禁用:删除缓存 修改: 修改缓存 |
| 服务信息 | 缓存1天 | String | JZ_CACHE:SERVE_RECORD::服务id | 上架:添加缓存 下架:删除缓存 修改: 修改缓存 |
下边分析第一个开通区域列表的缓存方案:
查询缓存:查询已开通区域列表,如果没有缓存则查询数据库并将查询结果进行缓存,如果存在缓存则直接返回
启用区域:删除开通区域信息缓存(再次查询将缓存新的开通区域列表)。
禁用区域:删除开通区域信息缓存,删除该区域下的其它缓存信息,包括:首页服务列表,服务类型列表,热门服务列表。
定时任务:每天凌晨缓存已开通区域列表。
5.1.2 查询缓存实现
下边我们先实现开通区域列表查询缓存。
首先把测试环境准备好:
启动jzo2o-gateway(使用bat脚本)
启动jzo2o-publics(使用bat脚本)
启动jzo2o-customer(使用bat脚本,如果已经通过小程序认证可以不用启动)
启动jzo2o-foundations(使用IDEA)
打开小程序开发工具
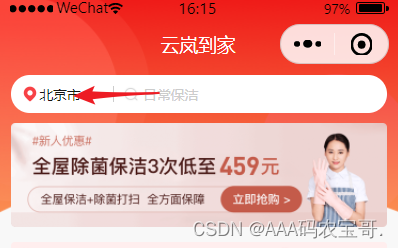
打开小程序,点击首页左上角的地址进入服务地址城市选择页面,如下图:
在定位界面显示已开通城市列表,已开通城市是指在区域管理中所有启用的区域信息,如下图:
跟踪Network找到开通区域列表的URL:/foundations/consumer/region/activeRegionList

打开jzo2o-foundations工程,根据接口地址找到具体的代码:
在com.jzo2o.foundations.controller.consumer.RegionController中找到接口:
@RestController("consumerRegionController")
@RequestMapping("/consumer/region")
@Api(tags = "用户端 - 区域相关接口")
public class RegionController {@Resourceprivate IRegionService regionService;@GetMapping("/activeRegionList")@ApiOperation("已开通服务区域列表")public List<RegionSimpleResDTO> activeRegionList() {return regionService.queryActiveRegionListCache();}}
在com.jzo2o.foundations.service.impl.RegionServiceImpl中找到service方法的实现如下:
@Override
public List<RegionSimpleResDTO> queryActiveRegionListCache() {return queryActiveRegionList();
}
在service方法上添加Spring cache注解:
@Override
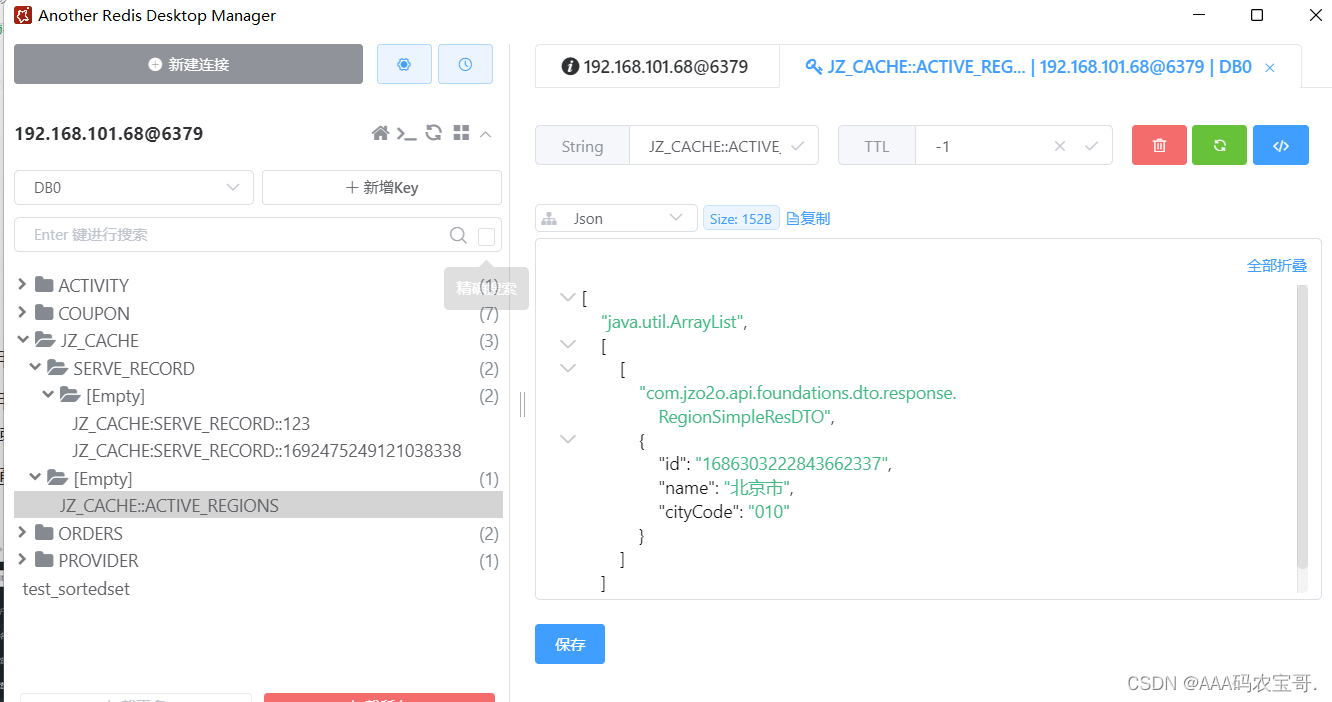
@Cacheable(value = RedisConstants.CacheName.JZ_CACHE, key = "'ACTIVE_REGIONS'", cacheManager = RedisConstants.CacheManager.FOREVER)
public List<RegionSimpleResDTO> queryActiveRegionListCache() {return queryActiveRegionList();
}
说明:
key: 当key用一个固定字符串时需要在双引号中用单引号括起来,如下所示:
key = "'ACTIVE_REGIONS'"
cacheManager :RedisConstants.CacheManager.FOREVER设置了缓存永不过期。
重启jzo2o-foundations工程进行测试。
通过小程序访问定位界面,观察Network:
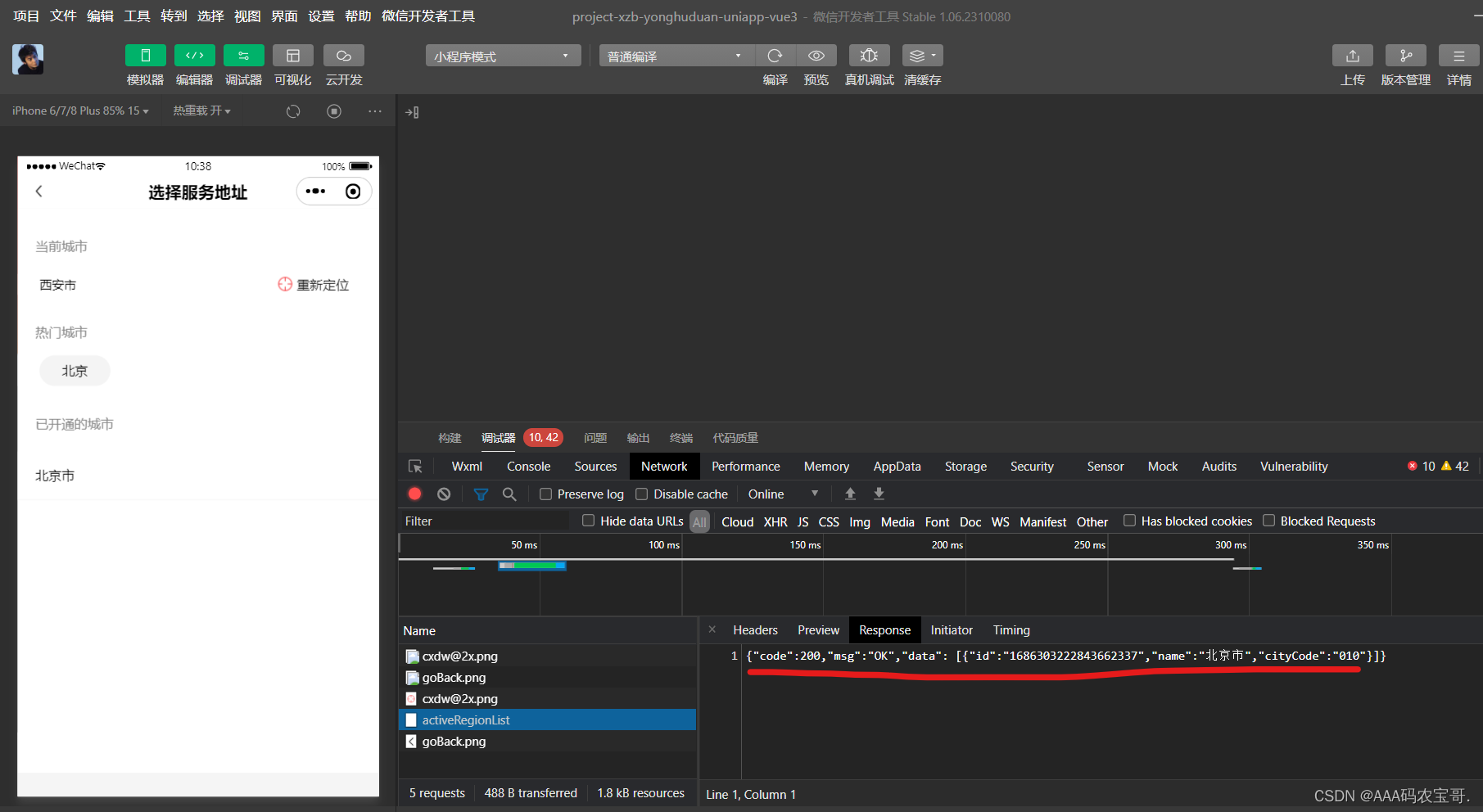
查看缓存
5.1.3 启用区域
启用一个新区域已经开通区域列表需要变更,该如何实现呢?
启用区域后删除已开通区域列表缓存,当去查询开通区域列表时重新缓存最新的开通区域列表。
可通过接口文档(http://localhost:11509/foundations/doc.html)找到启用区域的接口,如下:
在com.jzo2o.foundations.controller.operation.RegionController#actiavte
@PutMapping("/activate/{id}")
@ApiOperation("区域启用")
@ApiImplicitParams({@ApiImplicitParam(name = "id", value = "区域id", required = true, dataTypeClass = Long.class),
})
public void activate(@PathVariable("id") Long id) {regionService.active(id);
}
在com.jzo2o.foundations.service.impl.RegionServiceImpl中找到service代码的实现,如下:
@Override
public void active(Long id) {//区域信息Region region = baseMapper.selectById(id);//启用状态Integer activeStatus = region.getActiveStatus();//草稿或禁用状态方可启用if (!(FoundationStatusEnum.INIT.getStatus() == activeStatus || FoundationStatusEnum.DISABLE.getStatus() == activeStatus)) {throw new ForbiddenOperationException("草稿或禁用状态方可启用");}
修改为:
@Override
@CacheEvict(value = RedisConstants.CacheName.JZ_CACHE, key = "'ACTIVE_REGIONS'")
public void active(Long id) {//区域信息Region region = baseMapper.selectById(id);//启用状态Integer activeStatus = region.getActiveStatus();//草稿或禁用状态方可启用if (!(FoundationStatusEnum.INIT.getStatus() == activeStatus || FoundationStatusEnum.DISABLE.getStatus() == activeStatus)) {throw new ForbiddenOperationException("草稿或禁用状态方可启用");}
5.1.4 禁用区域
如果是禁用一个区域则需要删除开通区域列表缓存。
找到禁用区域的代码,修改如下:
@Override
@Caching(evict = {@CacheEvict(value = RedisConstants.CacheName.JZ_CACHE, key = "'ACTIVE_REGIONS'")//todo:删除首页服务列表缓存
})
public void deactivate(Long id) {//区域信息Region region = baseMapper.selectById(id);//启用状态Integer activeStatus = region.getActiveStatus();
5.1.5 测试
下边进行测试:
首先重启foundations服务。
启动运营管理(前端)进行测试
先测试启用一个地区,刚刚只有一个北京市能用,我们在上海市添加并上架一个服务后,启用上海市。
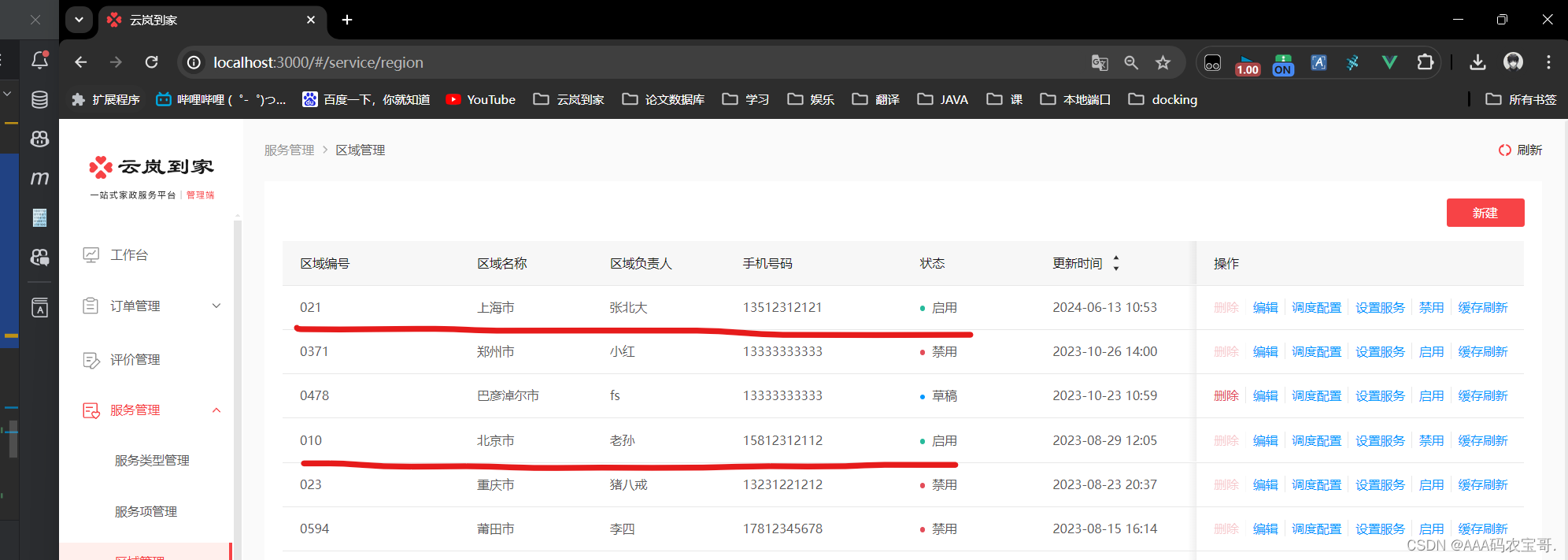
查看缓存
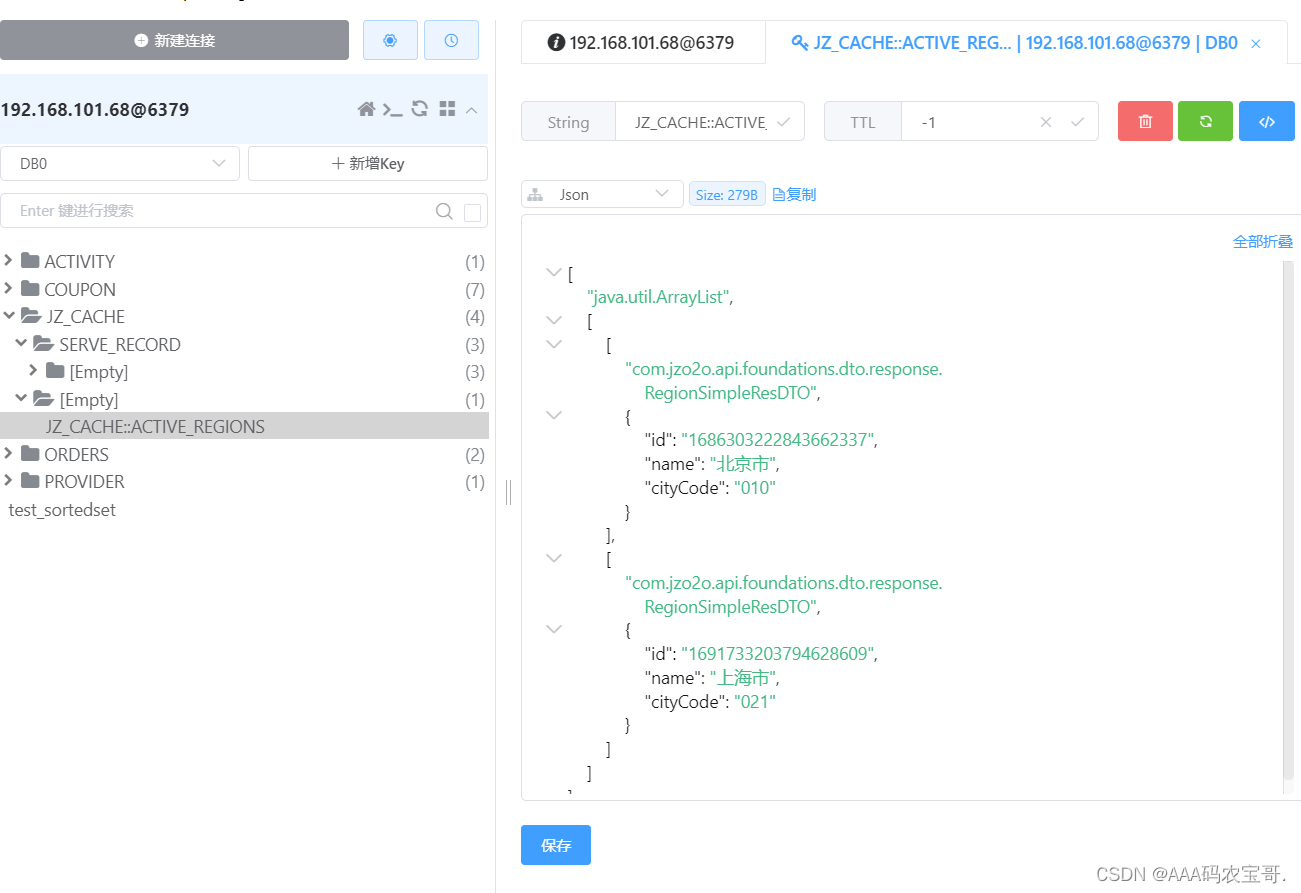
测试禁用区域,将上海区域下边服务全部下架,然后禁用该区域
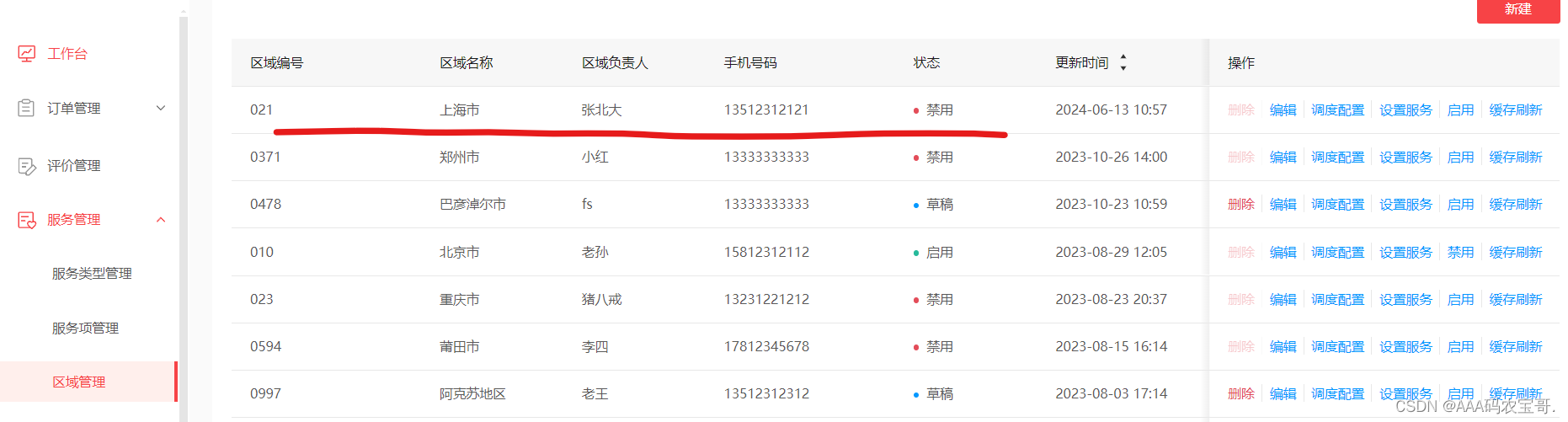
查看缓存,JZ_CACHE::ACTIVE_REGIONS缓存已经删除


![[Qt的学习日常]--常用控件1](https://img-blog.csdnimg.cn/direct/11b2841c8d1c469d948e20f2d9089cfc.png)



![[C++ STL] vector 详解](https://img-blog.csdnimg.cn/direct/6810814cc5f64abca5ed579d5e778c38.png)