Python网络爬虫分步走 – 使用LXML解析网页数据
Web Scraping in Python - Using LXML to Parse Web Data
By Jackson@ML
Lxml作为Python的第三方库,提供易用的且功能强大的API,用来解析XML和HTML文档。事件驱动的API被用于分步骤解析。
本文简要介绍使用lxml库解析网页的基本步骤。
1. 安装导入etree
若要使用xlml,则必须手动安装这个第三方库。
访问pypi.org官网,搜索得到lxml最新版本安装方法。
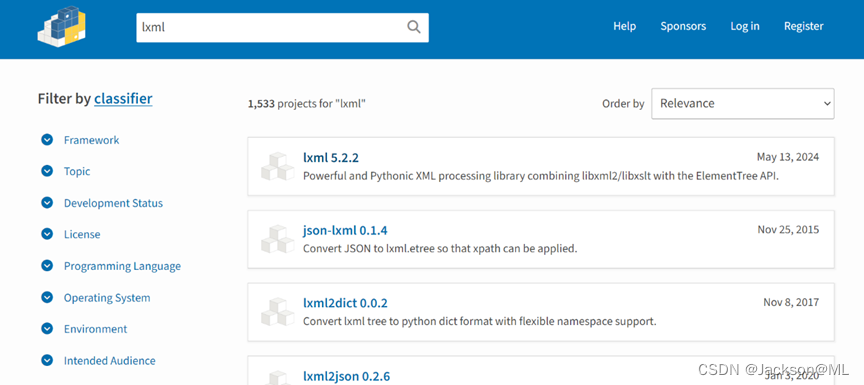
看到最新版本为 lxml 5.2.2, 点击进入下载安装页面。
按照提示,在Windows命令行窗口(cmd) 或者 PowerShell 终端,执行以下命令:
pip install lxml
进行该扩展库安装。

如果该库已安装,类似笔者电脑显示的上图,则忽略。接下来,可以导入使用该库了。
2. 在Anaconda Navigator上运行lxml文件解析
如果需要lxml库解析,首先导入该库,需要使用其下的etree模块;同时,需要对样例xml文件进行解析。
因此,我们先创建一个XML文件。
访问Microsoft.com官网链接,复制XML代码;接下来,打开Anaconda Navigator,随即创建一个文本文件,如下图所示: