目录
一、引入所需要的库
二、制作数据集
三、搭建神经网络
四、训练网络
五、测试网络
本博客实验环境为jupyter
一、引入所需要的库
torch库是核心,其中torch.nn 提供了搭建网络所需的所有组件,nn即神经网络。matplotlib类似与matlab,其中pyplot用于进行数据可视化,如绘制图表、曲线等。%matplotlib inline: 这是IPython(Jupyter Notebook)的魔法命令,用于在Notebook中直接显示Matplotlib绘制的图表,而不是弹出一个新窗口显示。
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline# 展示高清图
from matplotlib_inline import backend_inline #导入Matplotlib库中的backend_inline模块,用于控制图表的显示方式。
backend_inline.set_matplotlib_formats('svg') #设置Matplotlib图表的显示格式为SVG格式,SVG格式的图表在显示时具有高清晰度,适合用于展示精细的图形。二、制作数据集
主要任务是读取数据集,划分为训练集和测试集,一定要随机划分。
读取的数据集中共760组数据,共8个输入特征,1个输出特征。
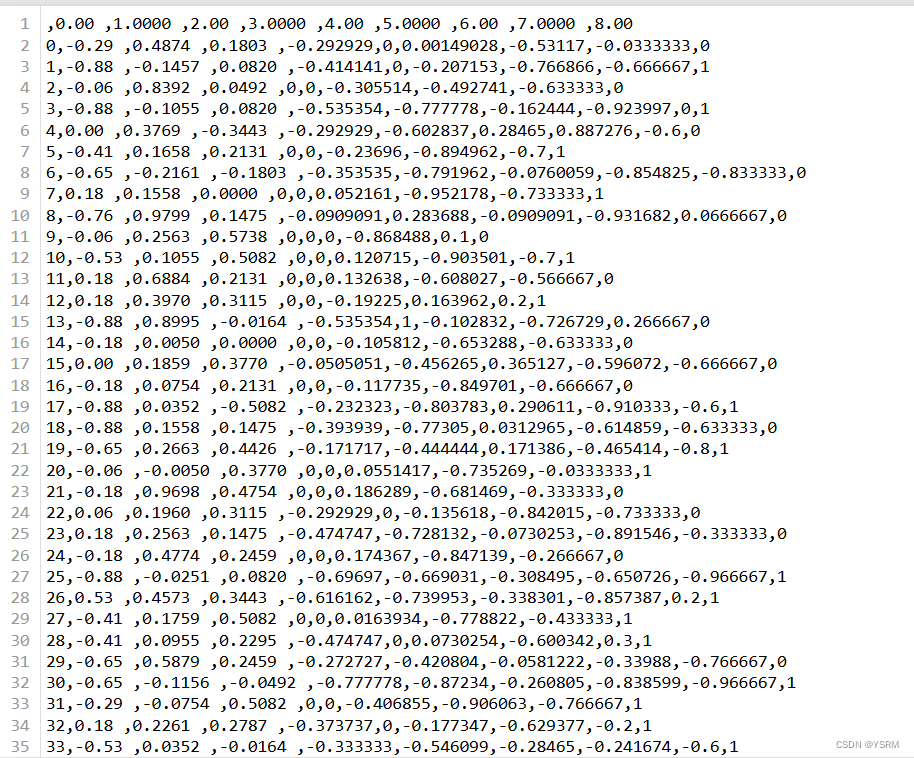
其中第一列是索引,从0开始,70%为训练集,30%为测试集。
#读取数据
df = pd.read_csv('Data.csv', index_col=0)#之前的pandas库中有介绍到,即df为读取后的对象,以第一列为索引
arr = df.values #转化为numpy数组
arr = arr.astype(np.float32)#转化为深度学习常用的单精度浮点类型
ts = torch.tensor(arr)#转化为张量tensor
ts = ts.to('cuda')#送到cuda设备上即gpu上计算 # 划分训练集与测试集
train_size = int(len(ts) * 0.7) #训练集的大小为百分之七十
test_size = len(ts) - train_size #测试集的大小为百分之三十
ts = ts[ torch.randperm( ts.size(0) ) , : ] #随机打乱数据集中样本的顺序
train_Data = ts[ : train_size , : ] #将前百分之七十行给训练集
test_Data = ts[ train_size : , : ] #将百分之七十后的行给测试集 三、搭建神经网络
主要是构建DNN类,需要对python的类定义有较为深入的理解能力。
class DNN(nn.Module): #定义了一个名为DNN的PyTorch模型类,该类继承自nn.Module类,表示这是一个神经网络模型。def __init__(self): #定义了模型的初始化方法''' 搭建神经网络各层 ''' super(DNN,self).__init__() #调用父类的初始化方法,确保模型的其他部分也能够被正确初始化。self.net = nn.Sequential( # 按顺序搭建各层 nn.Linear(8, 32), nn.Sigmoid(), # 第1层:全连接层 ,是一个包含32个神经元的全连接层,输入特征数为8(表示输入数据维度为8),并使用Sigmoid激活函数。nn.Linear(32, 8), nn.Sigmoid(), # 第2层:全连接层 ,是一个包含8个神经元的全连接层,输入特征数为32,同样使用Sigmoid激活函数。nn.Linear(8, 4), nn.Sigmoid(), # 第3层:全连接层 ,是一个包含4个神经元的全连接层,输入特征数为8,同样使用Sigmoid激活函数。nn.Linear(4, 1), nn.Sigmoid() # 第4层:全连接层 ,是一个包含1个神经元的全连接层,输入特征数为4,同样使用Sigmoid激活函数。这是模型的输出层。) def forward(self, x): ''' 前向传播 ''' y = self.net(x) # 将输入数据x通过模型定义的神经网络结构self.net进行前向传播计算,得到输出y。return y # y即输出数据model = DNN().to('cuda:0') # 创建子类的实例,并搬到GPU上 这个代码可以当做模板,其中需要修改的部分为网络层的搭建,输入特征,中间层,输出特征一般都要为2的n次幂。
这就是该实例的各层。

四、训练网络
通过前向传播,反向传播等操作,本质上是不断调整权重和偏置。
loss_fn = nn.BCELoss(reduction='mean')#选择二元交叉熵损失函数作为模型的损失函数,其中reduction='mean'表示采用平均损失值作为最终的损失值。
learning_rate = 0.005 # 设置学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练网络
epochs = 5000 #设置训练的总轮数为5000。
losses = [] # 记录损失函数变化的列表 # 给训练集划分输入与输出
X = train_Data[ : , : -1 ] # 前8列为输入特征
Y = train_Data[ : , -1 ].reshape((-1,1)) # 后1列为输出特征
for epoch in range(epochs): #对于每个epoch进行循环。Pred = model(X) #通过模型进行一次前向传播,得到模型的预测结果Pred。loss = loss_fn(Pred, Y) #计算模型预测结果与实际标签之间的损失值。losses.append(loss.item()) #将当前轮次的损失值记录到losses列表中。optimizer.zero_grad() #清空上一轮的梯度信息。loss.backward() #进行反向传播,计算梯度。optimizer.step() #根据优化算法更新模型的参数,完成一轮训练。#绘制损失函数随训练轮次变化的图像,用于可视化训练过程中损失值的变化。
Fig = plt.figure()
plt.plot(range(epochs), losses)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show() 生成结果为
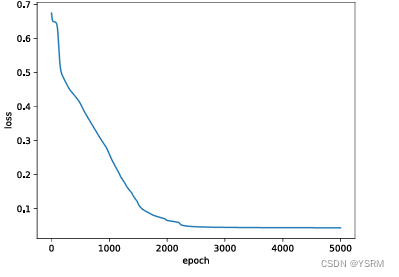
可以发现随着训练的进行,loss开始减少。
五、测试网络
通过用训练好的模型对测试集进行测试,由于只有一个输出特征为0或者1,将大于0.5的置为1,小于0.5的置为0,可以类比成可能性从0到1。
# 测试网络
# 给测试集划分输入与输出
X = test_Data[ : , : -1 ]
Y = test_Data[ : , -1 ].reshape((-1,1))
with torch.no_grad(): #进入上下文管理器,表示接下来的计算不会被记录在计算图中,因此不会影响梯度的计算。Pred = model(X) Pred[Pred>=0.5] = 1 Pred[Pred<0.5] = 0 correct = torch.sum( (Pred == Y).all(1) ) #统计预测正确的样本数,使用.all(1)表示在第1维度(即行)上进行比较,得到一个布尔张量,再进行求和操作。total = Y.size(0) #获取试集样本总数。print(f'测试集精准度: {100*correct/total} %') 一般精准度得百分之八九十才合格哦,所以精度不高很有可能是训练集或者环境的问题,所以训练前一定要做好准备工作,因为训练一个模型要花费很久时间。