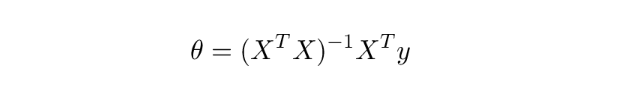每一轮技术浪潮出现时,冲在最前面的都是朝气蓬勃的年轻人。
当大模型代表的人工智能浪潮席卷全球,作为移动互联网“原住民”的年轻开发者,可以说是最活跃的群体。他们的脸庞还有些稚嫩,但在技术和方向上有着自己的想法,在火热的 AI 赛道里加速狂奔,努力打下一片新天地。
面壁智能 CTO 曾国洋就是其中的佼佼者,26 岁的年纪管理着清华系明星大模型创业公司的研发团队,坚定地踏上了 AGI 征途。
01 十多年开发经验的创业公司 CTO
在许多人的印象中,24 岁不过是研究生刚毕业的年纪,刚刚进入职场,扮演的还是“学徒”的角色。但在曾国洋的故事里,24 岁已经作为 CTO 带领着面壁智能的核心技术团队,同时也是一位有着十多年经验的资深开发者。
和 OpenAI 的创始人 Sam Altman 一样,曾国洋在 8 岁就开始学编程。身边的朋友、老师、父母等潜移默化地告诉他:“会写代码”是一件很厉害的事。于是从 Visual Basic 开始,懵懵懂懂地开启了编程之路。
到了中学时,曾国洋已经系统性地接触了 C/C++,喜欢在网上看一些国内外的资料,尝试写出更复杂的程序。因为“写代码”的爱好,曾国洋在高二时先后获得全国青少年信息学竞赛金牌和亚太地区信息学竞赛金牌,并因此被保送到清华,为日后的大模型创业埋下了伏笔。
没有高考压力的曾国洋,在 2015 年的冬令营上了解到旷视正在招实习生,抱着试一试的心态报了名,由此正式步入 AI 领域。
AlphaGo 和李世石的围棋大战,点燃了深度学习的热潮,无数年轻人为之彻夜不眠,曾国洋也不例外。大二期间,在室友的引荐下,曾国洋加入了清华大学 NLP 实验室,误打误撞成为中国最早一批大模型研究员,并在后来成为悟道·文源中文预训练模型团队的骨干成员。
十多年的开发经验,培养了曾国洋的工程化思维和能力,大学毕业时不甘于做象牙塔里的学术派,毅然加入到了大模型浪潮中。
在 OpenAI 发布 GPT-3 的第二年,为了解决大模型“训练难、微调难、应用难”的挑战,曾国洋作为联合发起人创建了 OpenBMB 开源社区,旨在打造大规模预训练语言模型库与相关工具,加速百亿级以上大模型的训练、微调与推理,以降低大模型的使用门槛,实现大模型的标准化、普及化和实用化,让大模型能够飞入千家万户。
清华大学计算机系长聘副教授刘知远在 2022 年牵头创办面壁智能时,曾国洋果断放弃了手里的多个 Offer,担纲这家大模型创业公司的技术 1 号位,完成了从一线开发者到大模型创业公司 CTO 的华丽转身。
02 “高效大模型就是面壁智能”
Scaling law,被看作是 OpenAI 的核心技术,简单来说,可以通过更复杂的模型、更大的数据量、更多的计算资源,提高模型的性能。前两年,国内外企业都在卷参数量,做到了千亿、万亿,甚至是十万亿,越到后面,但大家渐渐发现参数量更大,不代表模型效果更好。
在曾国洋看来:如果大模型作为实现 AGI 的关键路径,但成本却无比高昂,那么即使实现了 AGI,但 AGI 比人还贵、那也没太大意义,所以要降低模型成本。对于大模型落地来说,效率是很个关键的问题,需要控制成本来达到更好的效果,这样才能去扩展大模型的应用边界。
不久前举办的鲲鹏昇腾开发者大会 2024 上,曾国洋在演讲中表示:“面壁智能持续引领高效大模型路线,推动大模型高效训练、快步应用落地,以更快速度,更低成本,提供最优智能实现方案。”
首先要解决的就是高效训练。
公开数据显示,OpenAI 训练 GPT-3 的成本约为 430 万美元,到了 GPT-4 已经上涨到 7800 万美元,谷歌 Gemini Ultra 在计算上花费了 1.91 亿美元…比大模型能力更早指数性增长的,居然是大模型的训练成本。
该怎么提升大模型训练效率呢?
面壁智能在 2024 年初的一篇论文中提出了思路:如果大模型还未训练出来时就能预测性能大约在什么水平,可以先通过小模型做实验、调参数,再按照相同的数据配比、数调整等方法训练大模型。
其实在 2023 年,面壁智能就已经开始探索高效的 Scaling Law,用小十倍参数模型预测大十倍参数模型的性能,并且取得了不错的成绩:
旗舰端侧基座模型 MiniCPM 用 2.4B 的参数量,在性能上越级超越 Mistral-7B、Llama2-13B 乃至更大的全球知名模型;旗舰端侧多模态模型 MiniCPM-V 刷新了开源模型最佳 OCR 表现,部分能力比肩世界级多模态模型标杆 Gemini-Pro 与 GPT-4V。前两天发布的端侧最强多模态模型 MiniCPM-Llama3-V 2.5 ,超越多模态巨无霸 Gemini Pro 、GPT-4V 实现了「以最小参数,撬动最强性能」的最佳平衡点。“大”并非是唯一选项,小模型也可以实现同样的效果。
面壁智能的“高效”,不单单体现在训练环节。
在部署方面,面壁智能是模型厂商中最早提出“端云协同”的,通过协同推理的方式降低降低推理部署的成本、时延和能耗,让大模型可以跑在手机、电脑、汽车、音箱等低功耗的芯片。
以及大模型驱动的群体智能技术体系,包含智能体通用平台 AgentVerse、技术协同同台、应用层面的多智能体协作开发框架 ChatDev,帮助开发者打通大模型落地应用的最后一公里。
03 全流程加速大模型应用升级
基于丰厚原创技术底蕴,并匹配大模型这一系统工程的本质要求,面壁打造了一条从数据原材料、到模型制作过程中精湛训练与调校工艺环环相扣的全高效生产线。
譬如面壁智能独家的“沙盒实验”,让小模型验证大模型性能成为可能;Ultra 对齐技术,可以有效大模型的综合表现;现代化数据工厂,形成从数据治理到多维评测的闭环;高效的 Infra,为面壁智能的大模型训练打好了地基;训练框架 BMTrain、推理框架 BMINF、压缩框架 BMCook 和微调框架 BMTune 构成工具套件平台,可在降低 90%的训练成本同时,将推理速度提升 10 倍。
在创立之初,面壁智能就开始将大模型和国产软硬件基础设施做适配,想要从全流程加速大模型应用升级。直接的例子就是面壁智能和昇腾 AI 在软硬件的深度合作。
比如面壁智能基于昇腾基础软硬件完成了 CPM-BEE 大模型和 BMTrain 加速框架的迁移,通过两个关键步骤实现了 BMTrain 和昇腾的适配,通过亲和融合算子替换实现了大模型的性能提升,最终让 CPM、llama 等模型的集群训练性能与业界持平。
再比如基于昇腾底座采用 MindSpore 框架开展了深入的创新研究。在微调方面,面壁智能实现了多个下游任务 Sora 在使用不超过 1%的模型参数微调时,仍然能够超越其他微调方式;针对推理场景,面壁智能通过量化、蒸馏、剪枝等技术的灵活组合,在多项任务上压缩至 1/3 时,模型精度仍能保持 99%。
国内的大模型团队中,同时从算力、数据、算法切入的团队并不多见,为何面壁智能选择和昇腾 AI 一起,全面系统地推进大模型上下游工程?
曾国洋曾在媒体采访中这样说道:“我们追求的是,在同样的时间、同等参数量的条件下,实现更优的 Scaling Law。当模型的效率优化到一定程度的时候,如果要继续精进下去,就需要数据、算力与算法多者结合。”
这种不给自己设限的挑战精神,所带来的不单单是效率,还有通往 AGI 道路时的底气。
不少大模型团队为算力卡脖子问题焦虑的时候,曾国洋态度相当镇定:“对于比较早开展大模型研发的团队来说,国产化适配基本上都已经完成了,因为做的早嘛。其实国产化算力的差距没有想象的那么大,特别是像昇腾这些设备,目前已经达到了大规模商用的水平。”
和面壁智能一样,昇腾 AI 也在全流程使能大模型创新落地,从大模型的开发训练到推理部署。正是这些同道人的相向而行,让大模型开发不再是复杂的超级工程,每个开发者都能参与其中。
04 写在最后
大模型市场竞争激烈,技术迭代日新月异,但曾国洋连续几个月工作都不觉疲惫,用他自己的话说“因为我很相信 AGI 会实现。”
这正是年轻人的“可爱之处”,他们有挑战新事物的勇气,也有躬身入局的行动力,更重要的是,他们还是一群有理想的开发者。就像曾国洋在创办 OpenBMB 开源社区的初心:帮助千千万万的开发者降低门槛,让大模型飞入千家万户。面壁智能无疑是理想和初心的延续。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓