转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
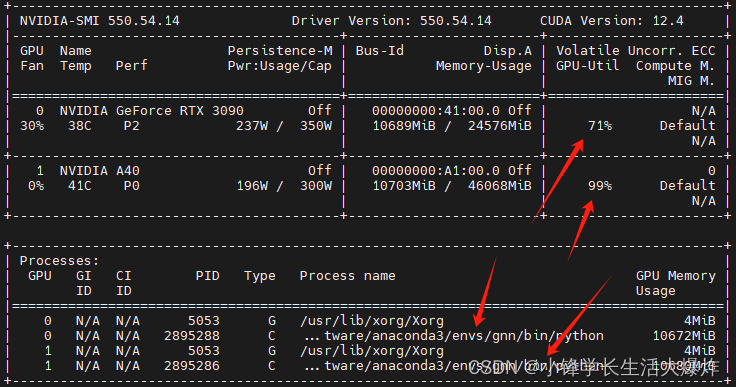
PyTorch中的DDP会将模型复制到每个GPU中。
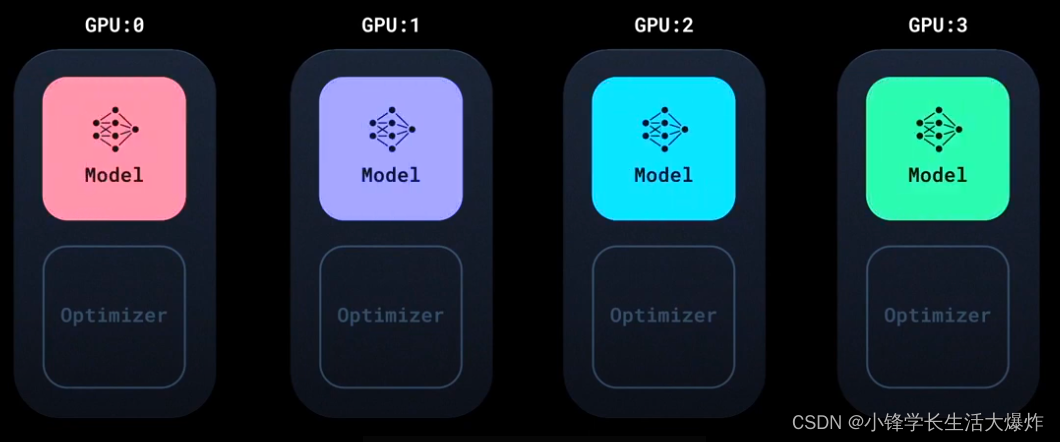
梯度同步默认使用Ring-AllReduce进行,重叠了通信和计算。

示例代码:
视频:https://youtu.be/Cvdhwx-OBBo
代码:multigpu.py
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoaderimport torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import osimport dgl
from dgl.data import RedditDataset
from dgl.nn.pytorch import GraphConvdef ddp_setup(rank, world_size):"""DDP初始化设置。参数:rank (int): 当前进程的唯一标识符。world_size (int): 总进程数。"""os.environ["MASTER_ADDR"] = "localhost" # 设置主节点地址os.environ["MASTER_PORT"] = "12355" # 设置主节点端口init_process_group(backend="nccl", rank=rank, world_size=world_size) # 初始化进程组torch.cuda.set_device(rank) # 设置当前进程使用的GPU设备class GCN(torch.nn.Module):def __init__(self, in_feats, h_feats, num_classes):"""初始化图卷积网络(GCN)。参数:in_feats (int): 输入特征的维度。h_feats (int): 隐藏层特征的维度。num_classes (int): 输出类别的数量。"""super(GCN, self).__init__()self.conv1 = GraphConv(in_feats, h_feats) # 第一层图卷积self.conv2 = GraphConv(h_feats, num_classes) # 第二层图卷积def forward(self, g, in_feat):"""前向传播。参数:g (DGLGraph): 输入的图。in_feat (Tensor): 输入特征。返回:Tensor: 输出的logits。"""h = self.conv1(g, in_feat) # 进行第一层图卷积h = F.relu(h) # ReLU激活h = self.conv2(g, h) # 进行第二层图卷积return hclass Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int,) -> None:"""初始化训练器。参数:model (torch.nn.Module): 要训练的模型。train_data (DataLoader): 训练数据的DataLoader。optimizer (torch.optim.Optimizer): 优化器。gpu_id (int): GPU ID。save_every (int): 每隔多少个epoch保存一次检查点。"""self.gpu_id = gpu_idself.model = model.to(gpu_id) # 将模型移动到指定GPUself.train_data = train_dataself.optimizer = optimizerself.save_every = save_everyself.model = DDP(model, device_ids=[gpu_id]) # 使用DDP包装模型def _run_batch(self, batch):"""运行单个批次。参数:batch: 单个批次的数据。"""self.optimizer.zero_grad() # 梯度清零graph, features, labels = batchgraph = graph.to(self.gpu_id) # 将图移动到GPUfeatures = features.to(self.gpu_id) # 将特征移动到GPUlabels = labels.to(self.gpu_id) # 将标签移动到GPUoutput = self.model(graph, features) # 前向传播loss = F.cross_entropy(output, labels) # 计算交叉熵损失loss.backward() # 反向传播self.optimizer.step() # 更新模型参数def _run_epoch(self, epoch):"""运行单个epoch。参数:epoch (int): 当前epoch号。"""print(f"[GPU{self.gpu_id}] Epoch {epoch} | Steps: {len(self.train_data)}")for batch in self.train_data:self._run_batch(batch) # 运行每个批次def _save_checkpoint(self, epoch):"""保存训练检查点。参数:epoch (int): 当前epoch号。"""ckp = self.model.module.state_dict() # 获取模型的状态字典PATH = "checkpoint.pt" # 定义检查点路径torch.save(ckp, PATH) # 保存检查点print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):"""训练模型。参数:max_epochs (int): 总训练epoch数。"""for epoch in range(max_epochs):self._run_epoch(epoch) # 运行当前epochif self.gpu_id == 0 and epoch % self.save_every == 0:self._save_checkpoint(epoch) # 保存检查点def load_train_objs():"""加载训练所需的对象:数据集、模型和优化器。返回:tuple: 数据集、模型和优化器。"""data = RedditDataset(self_loop=True) # 加载Reddit数据集,并添加自环graph = data[0] # 获取图train_mask = graph.ndata['train_mask'] # 获取训练掩码features = graph.ndata['feat'] # 获取特征labels = graph.ndata['label'] # 获取标签model = GCN(features.shape[1], 128, data.num_classes) # 初始化GCN模型optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) # 初始化优化器train_data = [(graph, features, labels)] # 准备训练数据return train_data, model, optimizerdef prepare_dataloader(dataset, batch_size: int):"""准备DataLoader。参数:dataset: 数据集。batch_size (int): 批次大小。返回:DataLoader: DataLoader对象。"""return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=True,collate_fn=lambda x: x[0] # 自定义collate函数,解包数据集中的单个元素)def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):"""主训练函数。参数:rank (int): 当前进程的唯一标识符。world_size (int): 总进程数。save_every (int): 每隔多少个epoch保存一次检查点。total_epochs (int): 总训练epoch数。batch_size (int): 批次大小。"""ddp_setup(rank, world_size) # DDP初始化设置dataset, model, optimizer = load_train_objs() # 加载训练对象train_data = prepare_dataloader(dataset, batch_size) # 准备DataLoadertrainer = Trainer(model, train_data, optimizer, rank, save_every) # 初始化训练器trainer.train(total_epochs) # 开始训练destroy_process_group() # 销毁进程组if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='Simple distributed training job')parser.add_argument('--total_epochs', default=50, type=int, help='Total epochs to train the model')parser.add_argument('--save_every', default=10, type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=8, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()world_size = torch.cuda.device_count() # 获取可用GPU的数量mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size) # 启动多个进程进行分布式训练