博客主页:花果山~程序猿-CSDN博客
文章分栏:Linux_花果山~程序猿的博客-CSDN博客
关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长!

目录
一,前提
二,IP协议格式
三,IP数据包分片
三,网段划分
1.子网掩码
网段的理解
例子
2. NAT技术
私有IP与公有IP
NAT工作原理示例
私有ip访问外部网站(内部到外部)
外部网站响应(外部到内部)
3. 路由
嗨!收到一张超美的图,愿你每天都能顺心!

一,前提
在学习网络层之前,我们可以回顾一下上一层——传输层,这里以TCP协议为例,TCP业绩叫传输控制协议,需要保证报文传递的可靠性,将应用层下达的数据进行拆分,形成一个个TCP段(通过序列号保证可靠传输和有序接收,通过确认,检测,重传等机制),然后再向网络层进行交付,而在接收机器上传输层等待下层向上交付,这个中间的过程传输层则不关心。
传输层保证的是数据的可靠性,以及数据丢失重传等策略,网络层功能又什么? (为了避免误导,这里用AI回答)
网络层,主要职责是负责数据包在网络中的传输和路由选择,它是实现不同网络之间互联的基础。
二,IP协议格式

属性讲解
三,IP数据包分片
第二层属性比较特殊,在了解这些之前,我们首先理解一下分片概念。
我们知道一个IP数据包支持6.5w字节,这里提前透露数据链路层的知识,数据链路层每次传输字节数是有限制的,假设只支持1500字节,那么IP数据包就需要分片,同时需要多次传递。(对于分片的策略有这个功能,但并不推荐,原因可以查查资料)
进行分片后就容易出现问题,如下面问题:
1. 在接收方网络层进行组装时,如何保证数据片的是同一份IP报文,顺序,以及完整性?
首先我们先认识一下这三个属性信息:
- 16位标识(id): 标识唯一主机发送的报文。如果IP报文在数据链路层被分片了, 那么每一个片里面的这个id都是相同的。——保证分片为同一份IP数据包
- 13位分片偏移(framegament offset): 是分片相对于原始IP报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值 * 8 得到的。因此, 除了最后一个报文之外, 其他报文的长度必须是8的整数倍(否则报文就不连续了)。
- 3位标志字段:
- 第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要用到)。
- 第二位置为1表示禁止分片, 这时候如果报文长度超过MTU, IP模块就会丢弃报文.
- 第三位表示"更多分片", 如果分片了的话, 最后一个分片置为1, 其他是0。类似于一个结束标记。

三,网段划分
我们知道IPv4最大可以容纳42亿台主机,同时我们知道IPv4也即将面临地址不够用的情况,面对不够用的情况,人们想出了子网掩码,私有IP&公网IP的方式来缓解IP地址的枯竭。
首先我们得有一个全球的视角,IP地址有32位,每个国家也都需要IP地址资源,从左侧开始(255.255.255.255),假设美国拿1开头的IP,中国拿2开头的IP资源,国家以这样的方式来划分IP资源,然后在国内再进行划分(以中国为例),河北省拿21...开头的ip,河南拿22...开头的ip,通过这样的方式将IP地址划分,知道单个主机,这样就会形成两个部分,也就是要说的 IP 地址有两个部分:网络号 + 主机号
网络号 : 保证相互连接的两个网段具有不同的标识 ;主机号 : 同一网段内 , 主机之间具有相同的网络号 , 但是必须有不同的主机号 ;关于网段定义,我们后面聊完私有IP,公网IP后说。
- 有一种技术叫做DHCP, 能够自动的给子网内新增主机节点分配IP地址, 避免了手动管理IP的不便.
- 一般的路由器都带有DHCP功能. 因此路由器也可以看做一个DHCP服务器.
在曾经也有一些如何设置主机号和网络号方案,如下: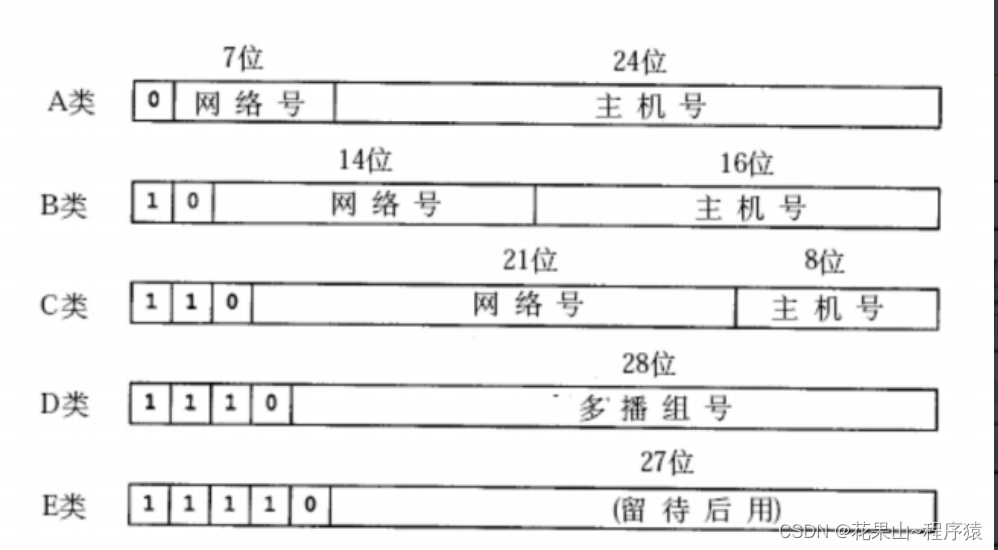
但这方案的弊端也很明显,大部分的企业或者组织更愿意选择B类的方案,导致B类方案地址缺乏,更重要的是并不是所有企业分配到的IP地址都能被使用,因此缺少一种动态分配网络号与主机号的占比的方案,称为CIDR(Classless Interdomain Routing),由此子网掩码出现。
1.子网掩码

网段的理解
这些IP地址共享相同的网络部分,意味着它们位于同一个逻辑网络或者可以无需通过路由器直接相互通信的网络部分。
更具体地说,当一个大的IP地址空间被划分为若干小的、可管理的部分时,每一个这样的部分就称为一个网段。这个划分过程通常是通过应用一个子网掩码来实现的,子网掩码决定哪些位表示网络部分,哪些位表示主机部分。
例子
假设我们有一个IP地址 192.168.1.10 和子网掩码 255.255.255.0。
- IP地址
192.168.1.10转换为二进制是11000000.10101000.00000001.00001010 - 子网掩码
255.255.255.0转换为二进制是11111111.11111111.11111111.00000000
通过与运算,我们可以确定网络部分:
11000000.10101000.00000001.00000000(即192.168.1.0)
所以,网段指的是所有具有相同前三部分(网络部分)的IP地址集合,也就是所有形如 192.168.1.x 的地址(其中x代表可能的主机号部分,范围通常是1到254)。在这个例子中,192.168.1.0 到 192.168.1.255 就构成了一个网段,所有这些地址都在同一个逻辑网络中,理论上可以直接互相通信,不需要路由器来进行跨网段的路由。
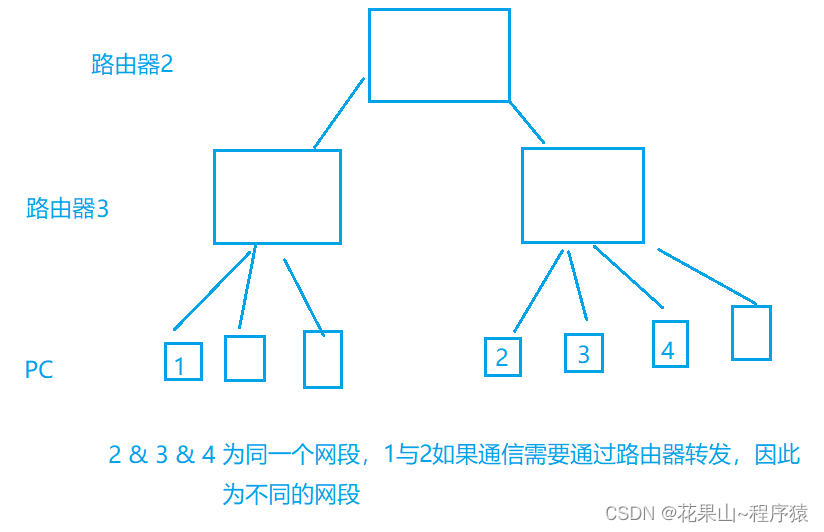
可IPv4的地址仍旧不够用,CIDR在一定程度上缓解了IP地址不够用的问题(提高了利用率, 减少了浪费, 但是IP地址的绝对上限并没有增加), 仍然
- 动态分配IP地址: 只给接入网络的设备分配IP地址. 因此同一个MAC地址的设备, 每次接入互联网中, 得到的IP地址不一定是相同的;(上限没有提高,只是提高了利用率)
- IPv6: IPv6并不是IPv4的简单升级版. 这是互不相干的两个协议, 彼此并不兼容; IPv6用16字节128位来表示一个IP地址; 但是目前IPv6还没有普及(有一部分原因是NAT技术大大缓解了IPv4的地址缺失);
- NAT技术(后面会重点介绍);
2. NAT技术
NAT(Network Address Translation,网络地址转换)技术通过允许一个私有网络内的多个设备共享一个或少数几个公有IP地址访问互联网,从而有效缓解了IPv4地址的紧缺问题。这里通过一个简化例子来说明NAT的工作原理:
私有IP与公有IP
首先,了解一下概念:
- 私有IP地址(局域网):这些地址在RFC 1918中定义,用于内部网络,不能直接在互联网上路由。常见的私有IP地址段包括:10.0.0.0/8、172.16.0.0/12、192.168.0.0/16。
- 公有IP地址(全球级的广域网):全球唯一的IP地址,可以直接在互联网上路由,但数量有限(多为一些大型跨国企业)。
NAT工作原理示例
假设有一个小型企业网络,内部有三台电脑,它们的私有IP地址分别为:
- 电脑A: 192.168.1.10
- 电脑B: 192.168.1.11
- 电脑C: 192.168.1.12
这个企业只有一个公有IP地址,例如:203.0.113.42,由路由器管理并用于外部通信。
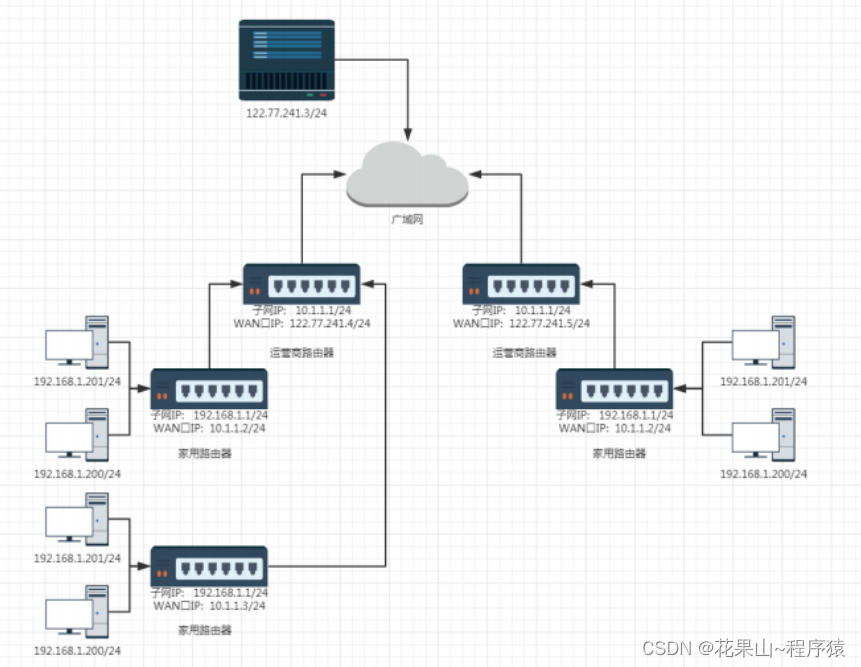
私有ip访问外部网站(内部到外部)
- 电脑A请求访问互联网:电脑A想要访问一个外部网站,它发送的数据包源IP是其私有IP(192.168.1.10)。
- 路由器进行NAT转换:路由器接收到这个数据包后,使用NAPT(Network Address Port Translation,网络地址端口转换)技术,将数据包的源IP地址替换为公有IP地址(203.0.113.42),同时记录下这个转换关系(源私有IP、源端口到公有IP、新的端口号)。
- 数据包转发:修改后的数据包,现在拥有公有IP地址和一个新的端口号,被路由器转发到互联网上。(这里我们可以联想在学习mysql时,云服务器向公网开放时,要选择接收任一源IP的请求连接,你不会知道那个路由器会为你转发)
外部网站响应(外部到内部)
- 外部响应:当外部服务器响应时,它将数据包发送到公有IP地址(203.0.113.42)和之前路由器分配的新端口号。
- 路由器转换回私有IP:路由器根据之前的转换记录,识别出这个数据包是给电脑A的,然后将目标IP地址和端口号转换回电脑A的私有IP地址(192.168.1.10)和原来的端口号,再将数据包转发给电脑A。
通过这种方式,NAT技术使得企业网络内的多台设备可以共享同一个公有IP地址访问互联网,极大地节省了公有IP地址的消耗,缓解了IPv4地址的紧缺问题。同时,由于私有IP地址对互联网是隐藏的,这也增加了网络的安全性。
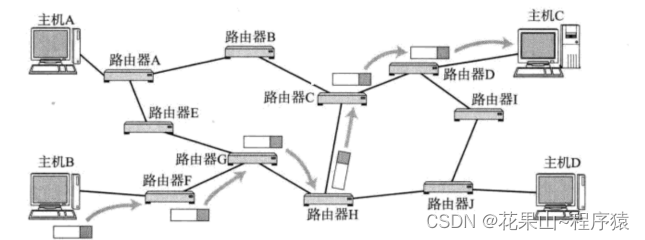
3. 路由
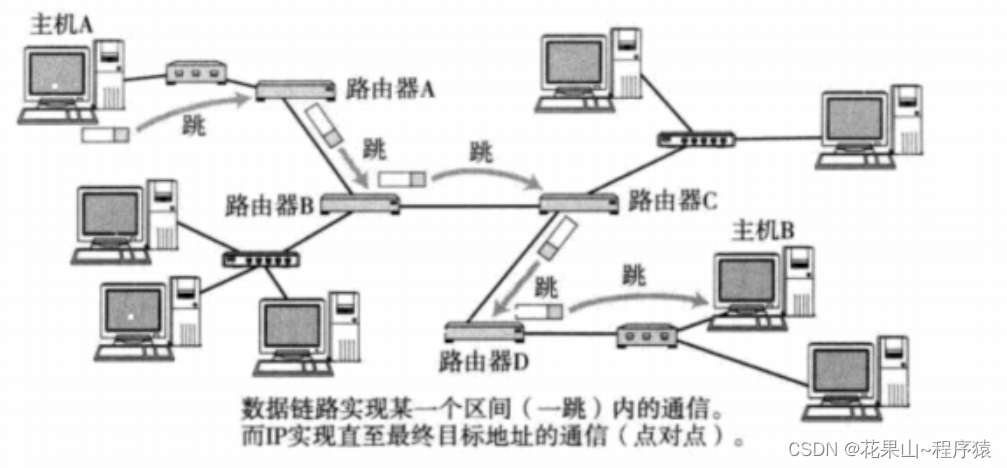
本质上是数据结构上图论部分,感谢兴趣的可以订阅我的高阶数据结构专栏,这里就了解一下。
高阶数据结构_花果山~程序猿的博客-CSDN博客
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获,请动动你发财的小手点个免费的赞,你的点赞和关注永远是博主创作的动力源泉。