文章目录
- 前言
- 一、Linux系统Centos7安装配置JDK8
- 二、Linxu系统Centos7中搭建Hadoop3.1.0服务
- 下载地址
- 服务1:详细步骤(初始化与启动dfs服务)
- 详细步骤
- 配置环境变量
- 服务2:Hadoop(YARN)环境搭建
- 三、Linux系统搭建Hive3.1.2服务
- 前提条件
- 安装MySQL 5.7.27
- Hive3.1.2详细安装配置步骤
- 下载地址
- 详细安装步骤
- 启动Hive服务与配置环境变量
- IDEA远程连接Hive服务
- 前置准备
- Java程序来连接Hive
- 四、Linux系统搭建Hbase2.2.4
- 说明
- 下载Zookeeper3.4.5以及Hbase2.2.4
- 安装Zookeeper3.4.5全流程(单机)
- 安装Hbase2.2.4全流程(单机)
- 详细安装流程
- Java客户端连接Hbase
- 五、Javaweb项目及lib包依赖
- 功能描述
- 测试服务快速命令
- 六、快捷命令汇总
- 快速关闭各个服务
- 快速启动各个服务
- 番外:极速搭建大数据配套环境(导入Virtualbox)
- 导入提前搭建好的环境
- ①配置静态ip地址
- ②配置域名映射
- 测试环境
前言
博主介绍:✌目前全网粉丝3W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
视频平台:b站-Coder长路
本期大数据实战项目功能演示及环境搭建教程(b站):https://www.bilibili.com/video/BV1F6421V7dY
一、Linux系统Centos7安装配置JDK8
下载地址:https://www.oracle.com/java/technologies/downloads/#java8
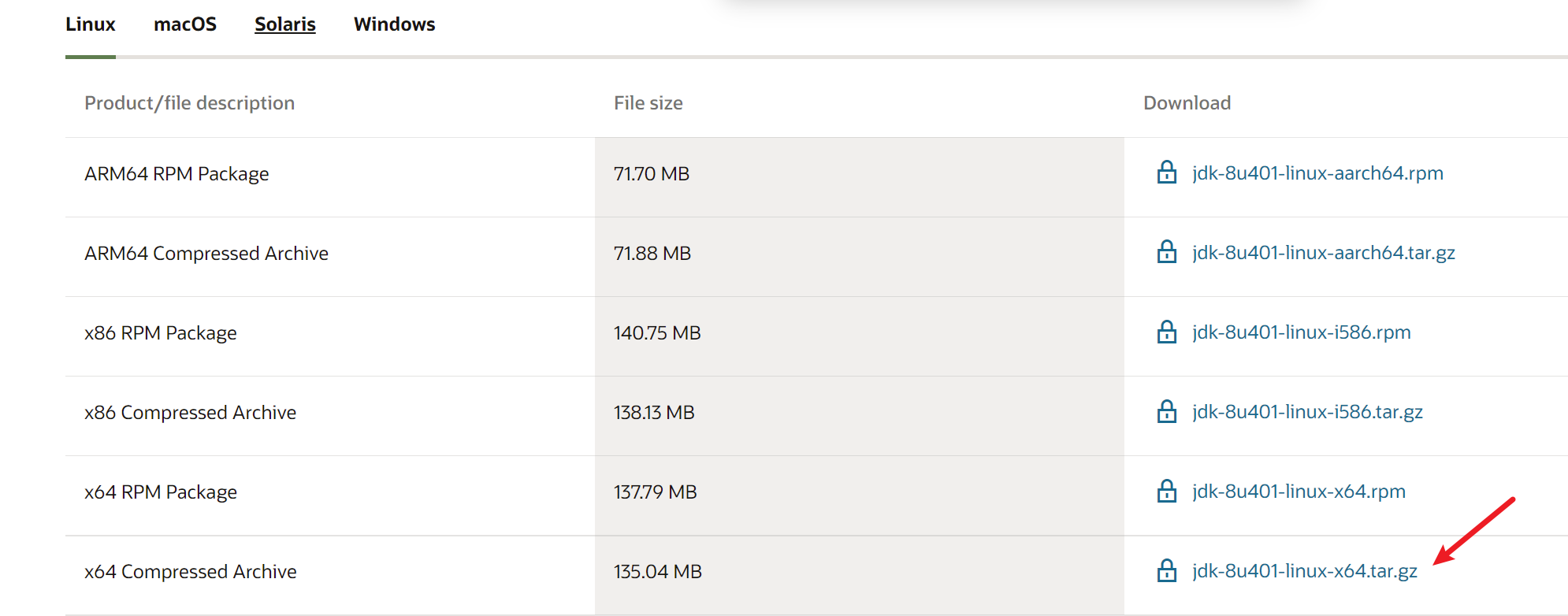
安装步骤如下:
①将JDK8的安装上传到服务器上
mkdir /opt/toolsmkdir /opt/server

②解压JDK8到指定目录
cd /opt/toolstar -zvxf jdk-8u221-linux-x64.tar.gz -C /opt/server
③编辑配置环境变量
vim /etc/profile# 文件末尾增加 指定jdk目录
# jdk
export JAVA_HOME=/opt/server/jdk1.8.0_221
export PATH=${JAVA_HOME}/bin:$PATH# 使配置生效
source /etc/profile
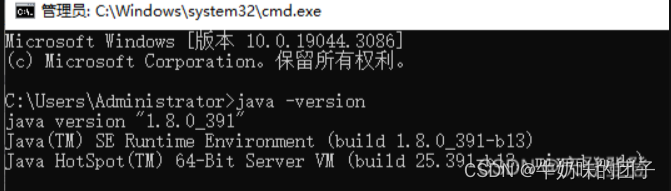
③测试JDK是否安装成功
java -version

二、Linxu系统Centos7中搭建Hadoop3.1.0服务
下载地址
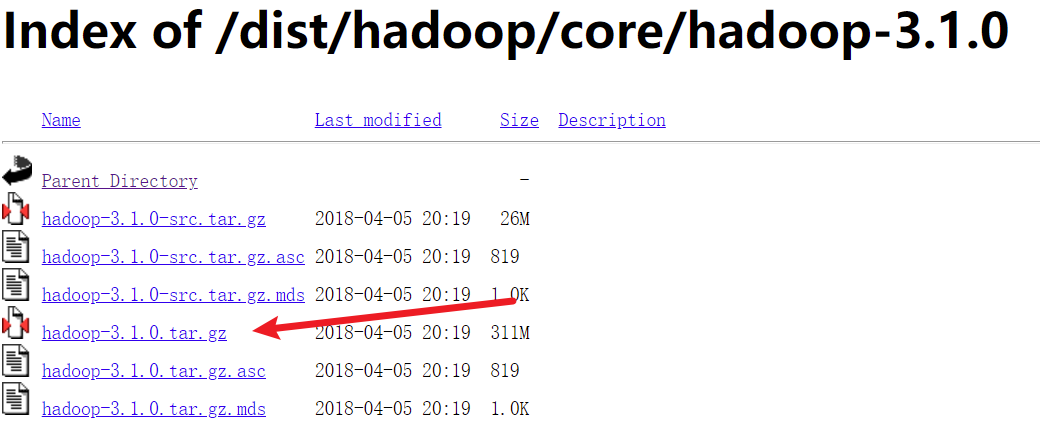
Hadoop下载地址:https://archive.apache.org/dist/hadoop/core/
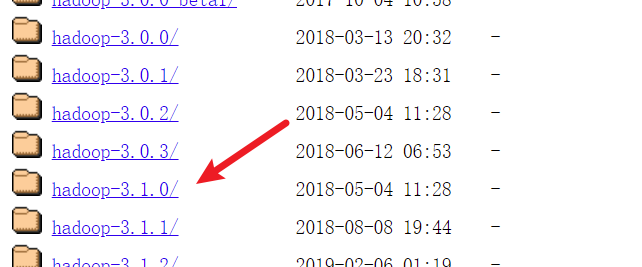
选择tar.gz压缩包下载:
服务1:详细步骤(初始化与启动dfs服务)
详细步骤
步骤1:配置免密登录
Hadoop 组件之间需要基于 SSH 进行通讯,配置免密登录后不需要每次都输入密码,配置映射:
vim /etc/hosts# 文件末尾增加(之前增加过无需增加)
192.168.10.120 server
生成私钥:
# 不断回车即可
ssh-keygen -t rsa
授权,进入 ~/.ssh 目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
步骤2:解压Hadoop
将文件上传/opt/tools:

解压Hadoop压缩包到server目录:
cd /opt/toolstar -zvxf hadoop-3.1.0.tar.gz -C /opt/server/
步骤3:配置Hadoop
修改配置文件hadoop-env.sh文件,设置JDK的安装路径:
# 进入到hadoop的配置文件目录
cd /opt/server/hadoop-3.1.0/etc/hadoop# 打开hadoop的环境配置脚本
vim hadoop-env.sh# 配置一开始的Java环境变量
export JAVA_HOME=/opt/server/jdk1.8.0_221
修改core-site.xml文件,分别指定hdfs 协议文件系统的通信地址及hadoop 存储临时文件的目录(程序运行可自动创建):
vim core-site.xml
<configuration><property><!--指定 namenode 的 hdfs 协议文件系统的通信地址这里server是域名 我们提前配置了hosts文件--><name>fs.defaultFS</name><value>hdfs://server:8020</value></property><property><!--指定 hadoop 数据文件存储目录--><name>hadoop.tmp.dir</name><value>/opt/server/hadoop-3.1.0/data</value></property><!--下面两个配置解决:idea远程连接hive失败问题--><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property>
</configuration>
修改hdfs-site.xml,指定 dfs 的副本系数:
vim hdfs-site.xml
<configuration><property><!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1--><name>dfs.replication</name><value>1</value></property><property><!-- AccessControlException: Permission 报错解决 --><name>dfs.permissions.enabled</name><value>false</value></property>
</configuration>
修改workers文件,配置所有从属节点:
vim workers# 配置所有从属节点的主机名或 IP 地址,由于是单机版本,所以指定本机即可:
server
步骤4:初始化并启动HDFS
初始化,第一次启动 Hadoop 时需要进行初始化,进入 /opt/server/hadoop-3.1.0/bin目录下,执行以下命令:
cd /opt/server/hadoop-3.1.0/bin# 初始化
./hdfs namenode -format
步骤5:配置启动用户(Hadoop 3中不允许使用root用户来一键启动集群)
cd /opt/server/hadoop-3.1.0/sbin/# 编辑start-dfs.sh、stop-dfs.sh,在顶部加入以下内容
vim start-dfs.shvim stop-dfs.sh
# 文件顶部第二行位置加入内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
步骤6:启动HDFS
# 启动HDFS,进入/opt/server/hadoop-3.1.0/sbin/ 目录下,启动 HDFS
cd /opt/server/hadoop-3.1.0/sbin/# 启动HDFS
./start-dfs.sh
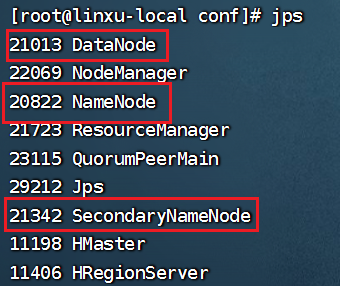
查看是否启动:
jps
若是有下面三个运行服务,那么就表示运行成功:
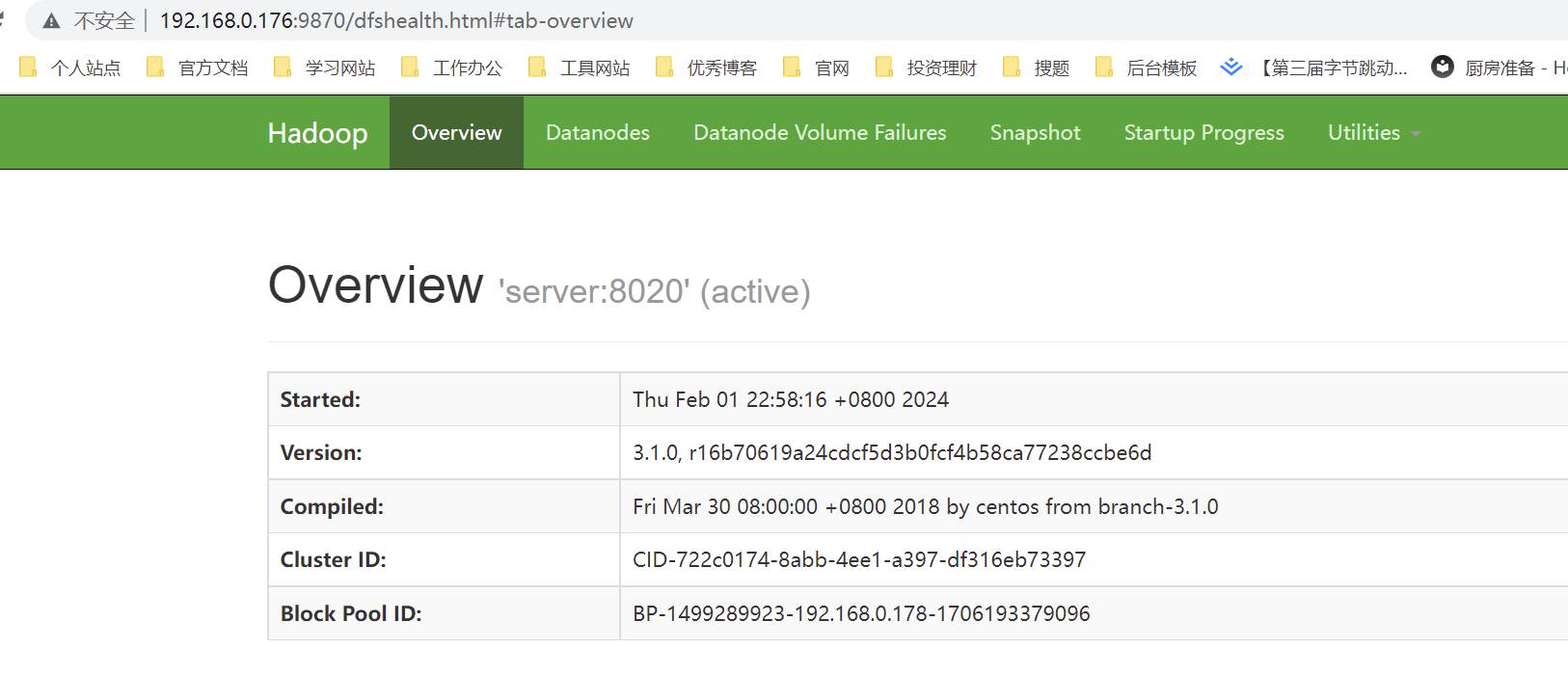
此时我们也可以在本地访问虚拟机的9870端口:
http://192.168.10.120:9870/
配置环境变量
# 编辑配置文件
vim /etc/profile# 在底部添加下面两行环境变量
# hadoop
export HADOOP_HOME=/opt/server/hadoop-3.1.0
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin# 使配置文件生效
source /etc/profile
服务2:Hadoop(YARN)环境搭建
步骤1:修改mapred-site.xml配置文件
cd /opt/server/hadoop-3.1.0/etc/hadoop# 编辑配置文件
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
步骤2:修改yarn-site.xml文件,配置 NodeManager 上运行的附属服务
vim yarn-site.xml
<configuration><property><!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可
以在
Yarn 上运行 MapRedvimuce 程序。--><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
步骤3:配置启动用户(Hadoop 3中不允许使用root用户来一键启动集群)
cd /opt/server/hadoop-3.1.0/sbin/vim start-yarn.sh
vim stop-yarn.sh
# start-yarn.sh stop-yarn.sh在两个文件顶部添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
步骤4:启动服务
# 进入 ${HADOOP_HOME}/sbin/ 目录下,启动 YARN:
cd ${HADOOP_HOME}/sbin/# 启动yarn服务
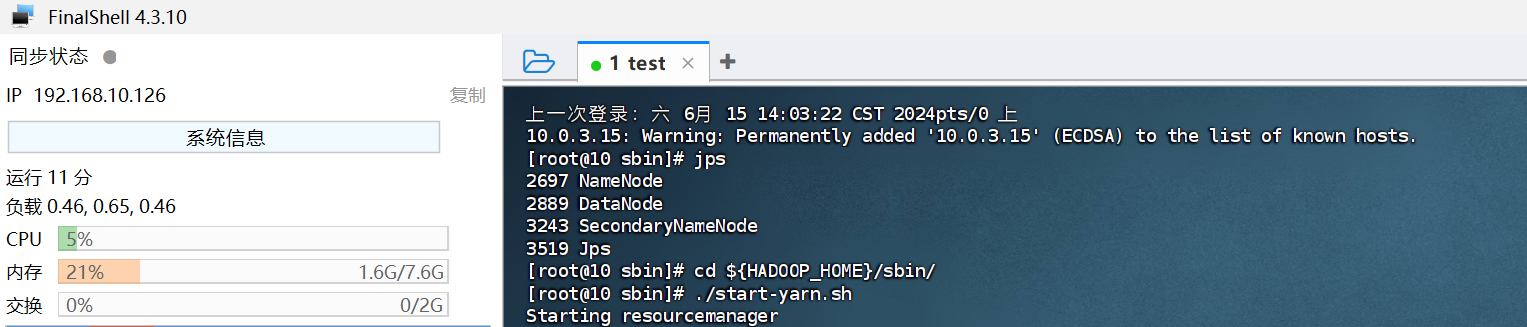
./start-yarn.sh
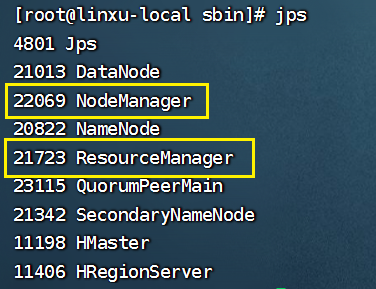
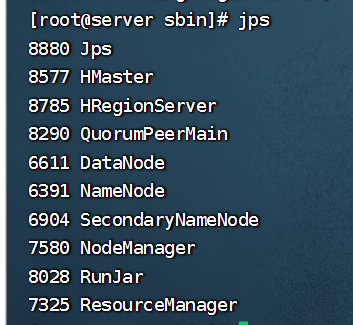
验证是否成功,我们输入JPS,若是有下面两个服务则启动成功:
jps
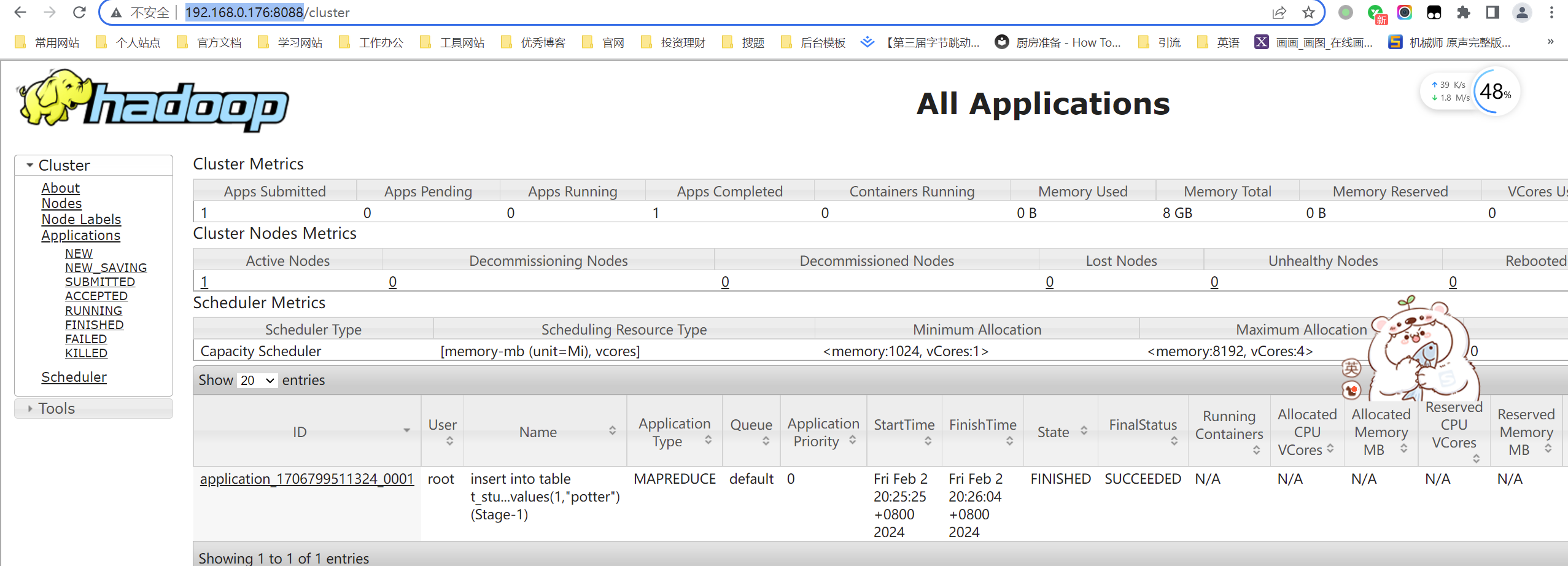
查看 Web UI 界面,端口为 8088:
http://192.168.10.120:8088/
三、Linux系统搭建Hive3.1.2服务
前提条件
安装Hadoop(基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上)。
安装MySQL(MySQL作为Hive的元数据存储库)。
安装MySQL 5.7.27
选择MySQL5.7.27:

安装步骤:
①卸载Centos7自带mariadb
# 查找
rpm -qa|grep mariadb
# mariadb-libs-5.5.52-1.el7.x86_64
# 卸载,根据指定名字
rpm -e mariadb-libs-5.5.52-1.el7.x86_64 --nodeps
②上传MySQL安装压缩包
# 创建mysql安装包存放点
mkdir /opt/server/mysql# 进入到上传目录
cd /opt/tools# 解压
tar xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar -C /opt/server/mysql/# 安装依赖
yum -y install libaio
yum -y install libncurses*
yum -y install perl perl-devel
yum -y install net-tools
# 切换到安装目录
cd /opt/server/mysql/
# 安装
rpm -ivh mysql-community-common-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.27-1.el7.x86_64.rpm
③启动MySQL服务
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码(获取到密码之后)
cat /var/log/mysqld.log | grep password
④修改初始的随机密码,并进行授权
# 登录mysql
mysql -u root -p
Enter password: #输入在日志中生成的临时密码# 更新root密码 设置为root
set global validate_password_policy=0;
set global validate_password_length=1;
set password=password('root');# 授权账户 root、root
grant all privileges on *.* to 'root' @'%' identified by 'root';
# 刷新
flush privileges;
⑤设置MySQL自启动
#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld#建议设置为开机自启动服务
systemctl enable mysqld#查看是否已经设置自启动成功
systemctl list-unit-files | grep mysqld
Hive3.1.2详细安装配置步骤
下载地址
hive下载地址:https://archive.apache.org/dist/hive/
详细安装步骤
同样上传到目录中/opt/tools:
①解压hive压缩包:
# 切换到安装包目录
cd /opt/tools# 解压到/root/server目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/server/
②上传MySQL的驱动包
# 上传mysql-connector-java-5.1.38.jar
cd /opt/server/apache-hive-3.1.2-bin/lib
③修改hive环境变量文件,指定Hadoop的安装路径
# 进入到配置文件目录
cd /opt/server/apache-hive-3.1.2-bin/conf# 复制一份环境配置
cp hive-env.sh.template hive-env.shvim hive-env.sh
# 加入以下内容
HADOOP_HOME=/opt/server/hadoop-3.1.0
④新建 hive-site.xml 文件,配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
- 需要修改用户名、密码,即20、24行。
- 设置mysql的连接ip地址,这里是server,可改为相应的ip地址。
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 存储元数据mysql相关配置 /etc/hosts 其中server为服务ip地址,我们这里配置了域名--><property><name>javax.jdo.option.ConnectionURL</name><value> jdbc:mysql://server:3306/hive?
createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&chara
cterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property>
</configuration>
⑤将mysql对应的jdbc驱动包放入到hive的lib目录下:
上传上去:
放入到服务器中的lib目录下:/opt/server/apache-hive-3.1.2-bin/lib
⑥当使用的 hive 是 2以上版本时,必须手动初始化元数据库,初始化命令:
# 进入到bin目录
cd /opt/server/apache-hive-3.1.2-bin/bin# 初始化前先创建数据库hive
mysql -u root -proot
create database hive charset=utf8;# 执行初始化
./schematool -dbType mysql -initSchema
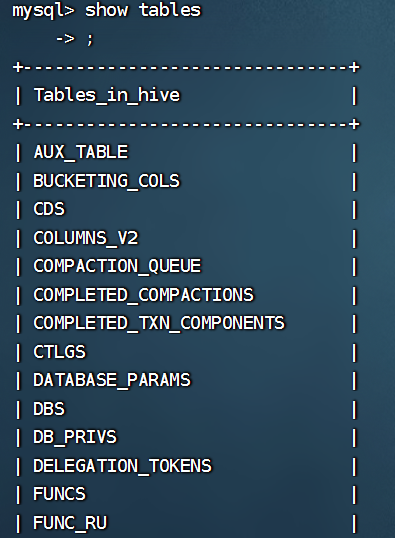
初始化成功后,我们可进入到mysql,看到hive数据库中,包含了74张表:
mysql -u root -prootshow databases;
启动Hive服务与配置环境变量
①添加环境变量:
vim /etc/profile# 配置信息如hive的安装目录
# hive
export HIVE_HOME=/opt/server/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH# 刷新配置
source /etc/profile
②启动Hive
hive
若是我们在hive的交互命令行中输入查看所有数据库中,若是有default表示搭建成功:
show databases;

IDEA远程连接Hive服务
前置准备
# 检查hive server2是否启动:若是有我们开启hive远程连接
netstat -anp |grep 10000# 开启远程连接(非后台运行)
hive --service hiveserver2
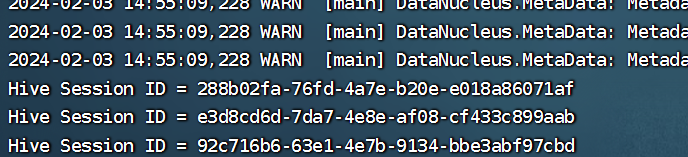
若是出现下面四个Hive Session:
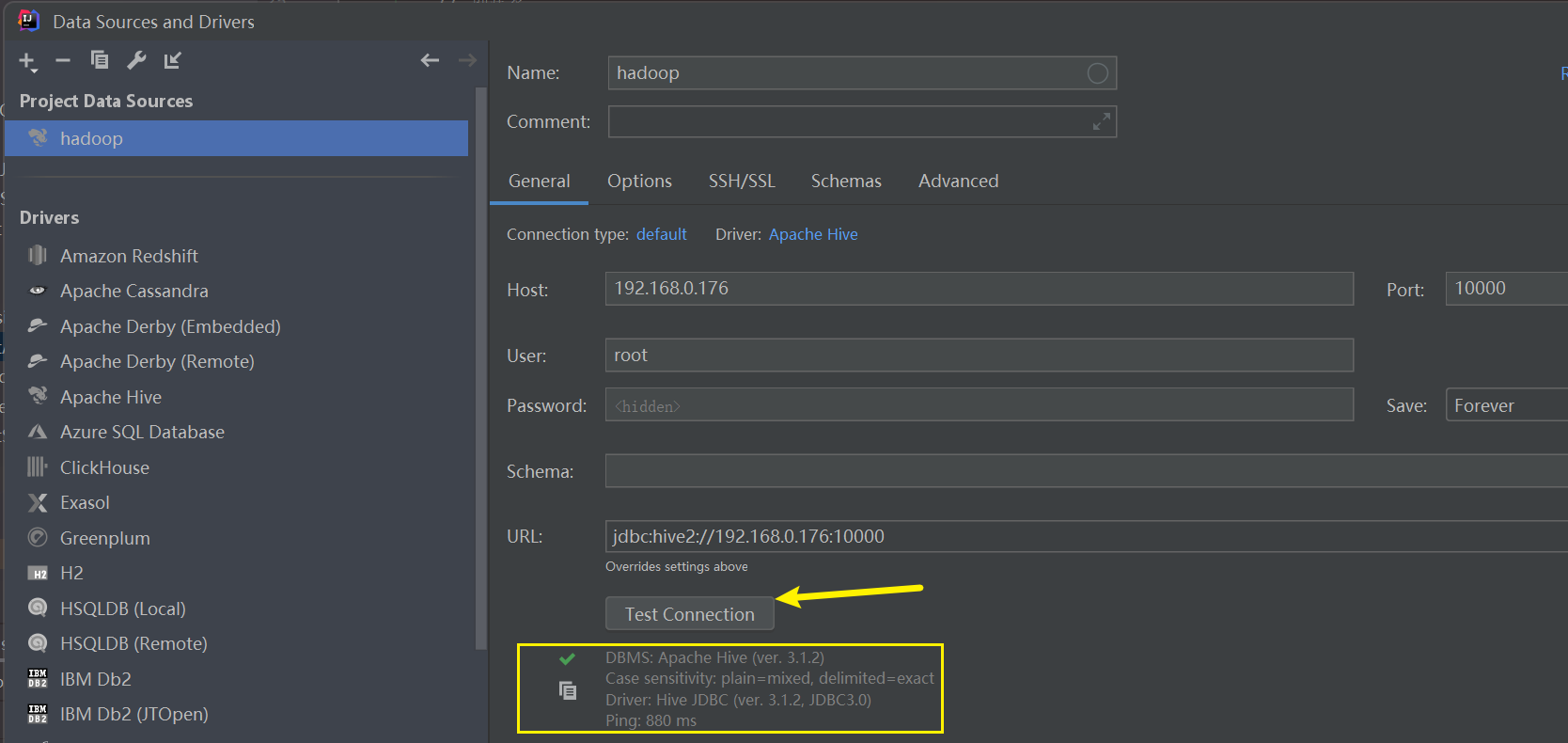
然后我们点击IDEA的测试即可,连接成功在Hive远程服务程序会显示OK:
jdbc:hive2://192.168.10.120:10000root、root
我们也可以后台运行方式:
# 开启远程连接(后台运行)
# nohup: 忽略SIGHUP信号,使命令在终端关闭后继续运行。 hive --service hiveserver2: 启动HiveServer2服务。
# > hiveserver2.log: 将标准输出重定向到hiveserver2.log文件。
# 2>&1: 将标准错误输出重定向到与标准输出相同的文件。
# &: 将命令放入后台运行。
nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &# 关闭服务方式
ps aux | grep hiveserver2
kill -9 <PID>
Java程序来连接Hive
选择和Hive版本3.1.2的jar包,接着我们来测试程序:
public static void main(String[] args) throws Exception {String driver = "org.apache.hive.jdbc.HiveDriver";String url = "jdbc:hive2://192.168.10.120:10000/default";Class.forName(driver);Connection connection = DriverManager.getConnection(url, "root", "root");Statement statement = connection.createStatement();
}
四、Linux系统搭建Hbase2.2.4
说明
Hbase基于hadoop、zookeeper、jdk。
下载Zookeeper3.4.5以及Hbase2.2.4
zookeeper下载地址:https://archive.apache.org/dist/zookeeper/
Hbase下载地址:https://archive.apache.org/dist/hbase/
下载好之后上传压缩包到服务器上:
/opt/tools
安装Zookeeper3.4.5全流程(单机)
步骤1:解压zookeeper安装包
cd /opt/toolstar -zxvf zookeeper-3.4.5.tar.gz -C /opt/server
步骤2:修改zoo.cfg配置
- 需要修改的是dataDir、server.0的ip地址
cd /opt/server/zookeeper-3.4.5/conf# 复制一份配置文件
cp zoo_sample.cfg zoo.cfg# 编辑配置文件
vim zoo.cfg# 修改配置内容如下
dataDir=/opt/server/zookeeper-3.4.5/data
clientPort=2181
server.0=server:2287:3387
步骤3:修改myid:
mkdir -p /opt/server/zookeeper-3.4.5/dataecho '0' > /opt/server/zookeeper-3.4.5/data/myid
配置环境变量:
vim /etc/profile# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/server/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin# 刷新配置
source /etc/profile
步骤4:启动服务
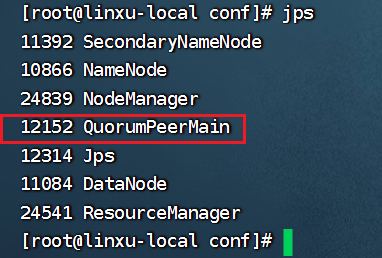
zkServer.sh start
输入jps显示当前运行进程,对于QuorumPeerMain即为zookeeper进程程序:
jps
安装Hbase2.2.4全流程(单机)
详细安装流程
步骤1:解压Hbase2.2.4
# 首先进入到压缩包路径,
cd /opt/toolstar -zxvf hbase-2.2.4-bin.tar.gz -C /opt/server
步骤2:配置hbase-env.sh配置信息
cd /opt/server/hbase-2.2.4/confvim hbase-env.sh # 28行添加JDK环境
export JAVA_HOME=/opt/server/jdk1.8.0_221
# 126行关闭zookeeper管理,是否管理自己的zookeeper实例(不使用自带的)
export HBASE_MANAGES_ZK=false
步骤3:编辑hbase-site.xml配置信息:
- hbase.rootdir:填写端口号一定要与hadoop初始核心的端口一致。
- hbase.zookeeper.property.dataDir:与原本zookeeper的要一致。
- hbase.zookeeper.quorum:指明的是服务地址。
- hbase.tmp.dir:自定义hbase的tmp目录。
- zookeeper.znode.parent:相对应zookeeper的节点。
# 编辑hbase-site.xml
vim hbase-site.xml
# 添加内容如下:
# ①修改hdfs的ip地址,注意端口要与hadoop中的core-site.xml里的fs.defaultFS一致。!!!!!!!!
# ②修改zookeeper的路径
<configuration><!-- Hbase数据在HDFS中的存放位置 --><property><name>hbase.rootdir</name><value>hdfs://server:8020/hbase</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/opt/server/zookeeper-3.4.5/data</value></property><!-- Hbased的运行模式,false为单机模式,true为分布式模式.若为false,Hbase和Zookeeper会运行在同一个JVM里 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- zookeeper的服务地址 --><property><name>hbase.zookeeper.quorum</name><value>server</value><description>The directory shared by RegionServers.</description></property><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><property><name>hbase.tmp.dir</name><value>/opt/server/hbase-2.2.4/tmp</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><property><name>zookeeper.znode.parent</name><value>/hbase/master</value></property>
</configuration>
步骤4:配置服务名
# 修改服务
vim regionservers# 填写域名(默认localhost,我们也可不改)
# 若是没有绑定域名,可设置 vim /etc/hosts 文件末尾增加 192.168.80.100 server
server
步骤5:配置环境变量
vim /etc/profile# 添加
# HBASE_HOME
export HBASE_HOME=/opt/server/hbase-2.2.4
export PATH=$PATH:$HBASE_HOME/bin# 刷新配置
source /etc/profile
启动Hbase:
注意:启动前需要启动hadoop、zookeeper服务!
start-hbase.sh
输入jps查看服务是否启动:
jps
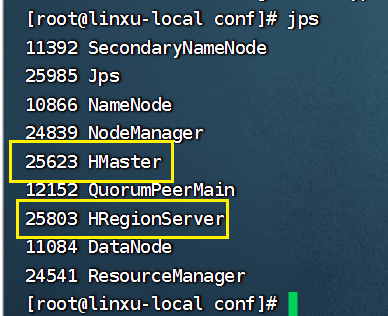
有问题一定要看日志!!!
访问16010端口即可访问Hbase服务:http://192.168.10.120:16010/
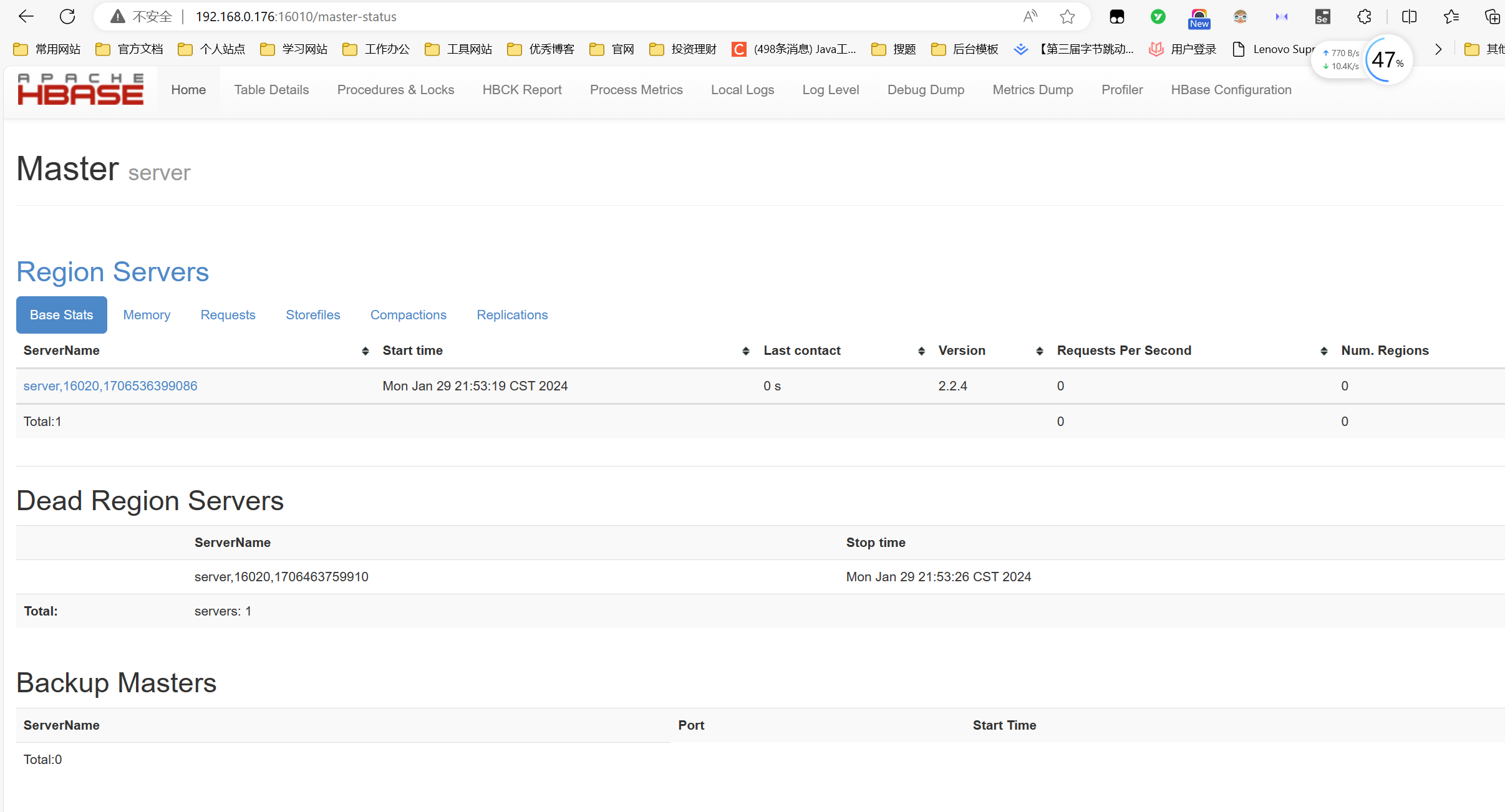
Java客户端连接Hbase
前提,我们需要配置域名映射,因为我们从zookeeper中取到的是服务名,自然我们应该去配置映射:
- 路径位置:C:\Windows\System32\drivers\etc
- 配置信息:192.168.10.120 server
# 刷新DNS解析缓存
ipconfig /flushdns
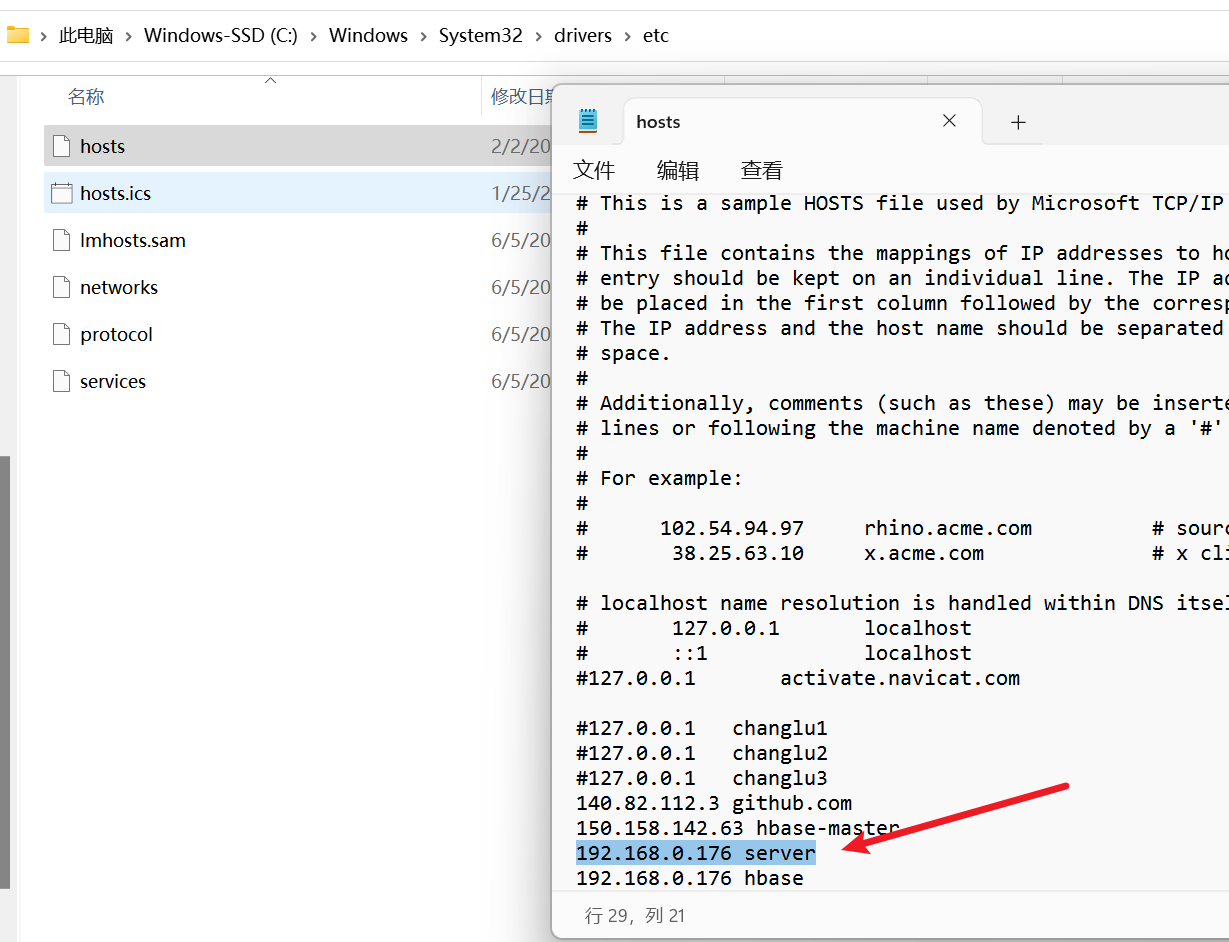
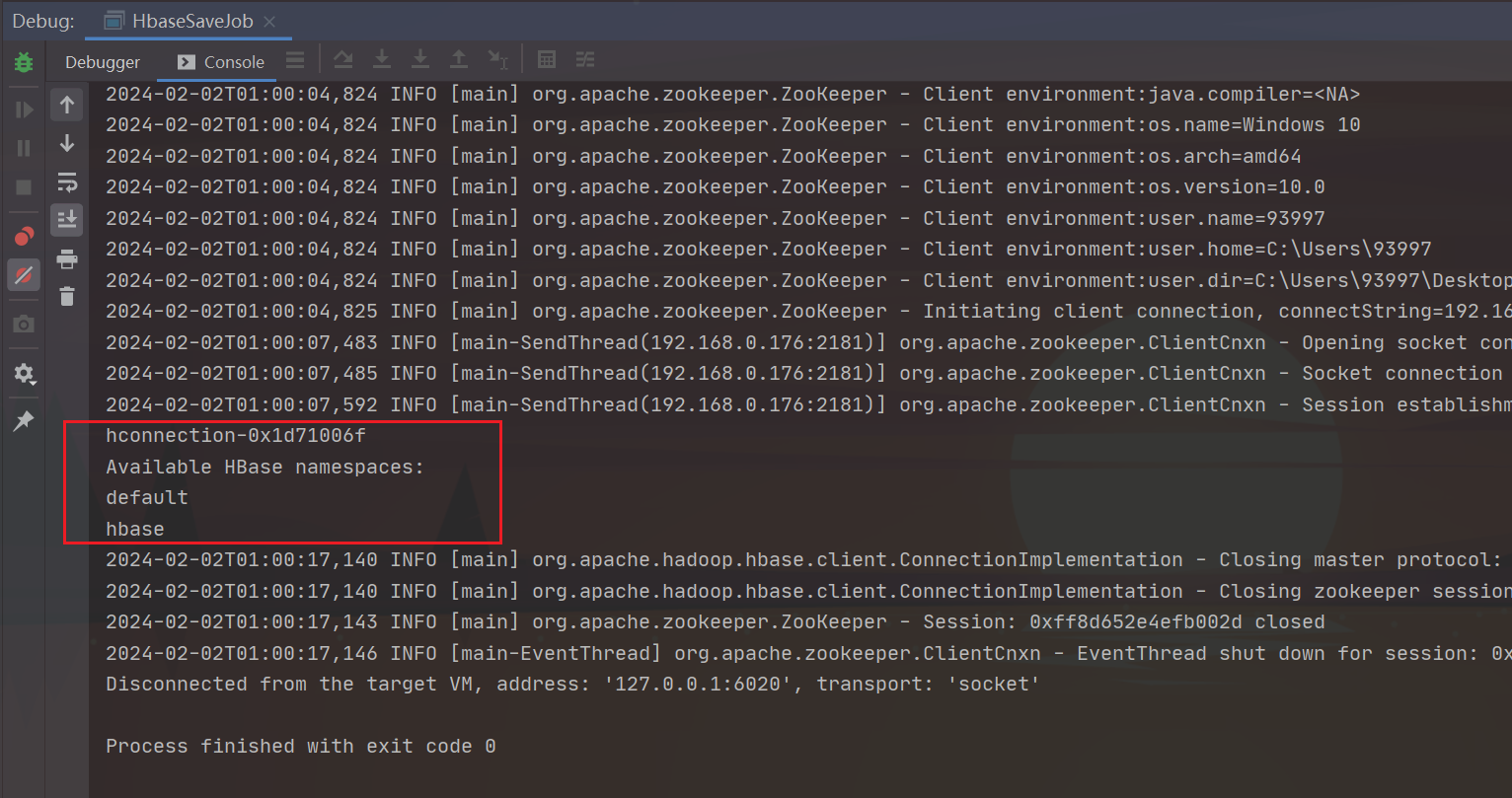
Hbase连接我们只需要知道zookeeper的ip地址以及端口号即可:
public static void main(String[] args) {// 创建 HBase 配置对象Configuration conf = HBaseConfiguration.create();// 设置 ZooKeeper 地址和端口// conf.set("hbase.zookeeper.quorum", ServerConfig.SERVER_IP);conf.set("hbase.zookeeper.quorum", "192.168.10.120");conf.set("hbase.zookeeper.property.clientPort", "2181");conf.set("zookeeper.znode.parent", "/hbase/master");// 建立 HBase 连接try (org.apache.hadoop.hbase.client.Connection connection = ConnectionFactory.createConnection(conf)) {System.out.println(connection);// 获取 HBase 管理对象Admin admin = connection.getAdmin();// 获取所有命名空间NamespaceDescriptor[] namespaces = admin.listNamespaceDescriptors();// 打印命名空间信息System.out.println("Available HBase namespaces:");for (NamespaceDescriptor namespace : namespaces) {System.out.println(namespace.getName());}} catch (IOException e) {e.printStackTrace();}
}
五、Javaweb项目及lib包依赖
功能描述
需要导入的外部jar包:导入hadoop、hdfs、hbase、mapreduce的Jar包,主要是将hadoop解压的目录中的jar包导入,如下:
- /usr/local/hadoop/share/hadoop/common
- /usr/local/hadoop/share/hadoop/hdfs
- /usr/local/hadoop/share/hadoop/hdfs/lib
- /usr/local/hadoop/share/hadoop/mapreduce
- /usr/local/hadoop/share/hadoop/yarn
- /usr/local/hadoop/hbase/lib
测试服务快速命令
Hbase命令:
# 进入Hbase命令行
hbase shell# hbase
# 查看default数据库
list_namespace_tables 'default'# 查看表结构
describe seeds_table# 查看表数据
scan "seeds_table"# 删除数据库表(只删除数据)
truncate 'seeds_table'
# 删除数据库表(数据与结构)
disable 'seeds_table'
drop 'seeds_table'
Hive命令:
# 进入Hive
hive# 查看所有数据库
show databases;# 使用数据库
USE default;# 查看所有表
show tables;# 查询表数据
select * from seeds;# 删除表(原数据和结构)
DROP TABLE IF EXISTS seeds;
-- 仅删除表中的数据,保留表结构
TRUNCATE TABLE seeds;
六、快捷命令汇总
快速关闭各个服务
# 1、关闭hadoop服务
# 进入hadoop目录
cd /opt/server/hadoop-3.1.0/sbin/
# 关闭
./stop-dfs.sh# 2、关闭yarn服务
cd ${HADOOP_HOME}/sbin/
./stop-yarn.sh# 3、关闭hive服务
ps aux | grep hiveserver2
kill -9 <PID># 4、关闭zookeeper
zkServer.sh stop# 5、关闭Hbase(关闭hdfs)
stop-hbase.sh# 查看java进程
jps
快速启动各个服务
# 1、开启hadoop服务
# 进入hadoop目录
cd /opt/server/hadoop-3.1.0/sbin/
# 开启
./start-dfs.sh# 2、开启yarn服务
cd ${HADOOP_HOME}/sbin/
./start-yarn.sh# 3、开启hive远程连接
nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &# 4、开启zookeeper
zkServer.sh start# 5、开启Hbase(开启hdfs)
start-hbase.sh# 查看java进程
jps
番外:极速搭建大数据配套环境(导入Virtualbox)
导入提前搭建好的环境
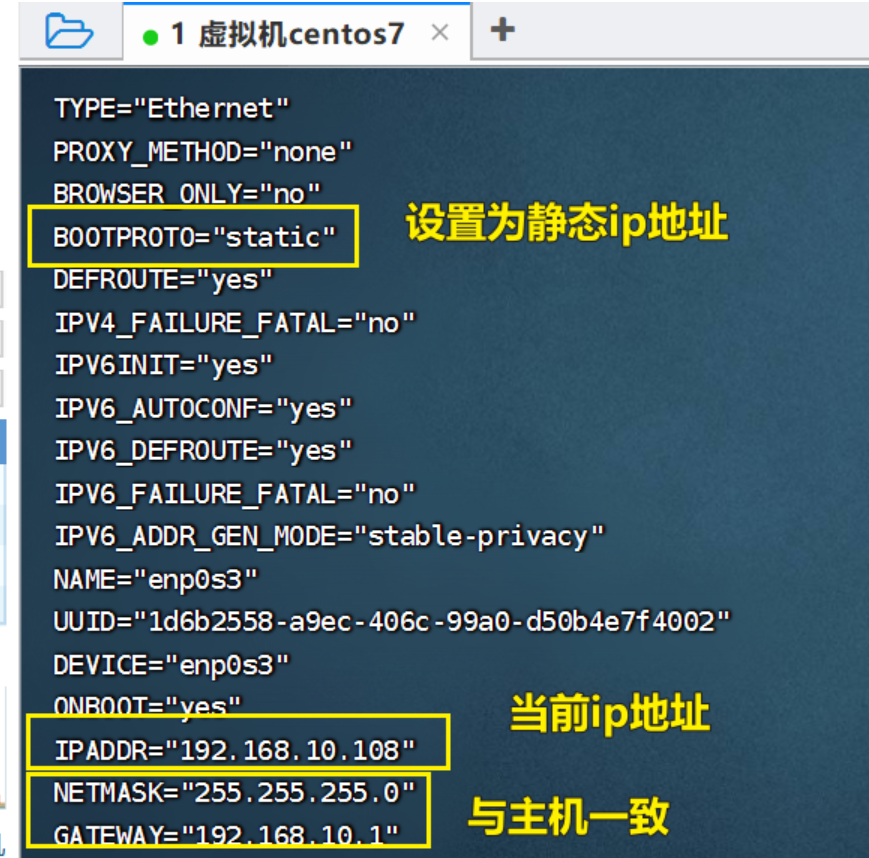
①配置静态ip地址
cd /etc/sysconfig/network-scripts/# 直接修改enp0s3配置文件
vi ifcfg-enp0s3
配置内容直接在ifcfg-enp0s3网卡文件修改(可自行根据主机cmd中的网关地址):
开启网络连接:
配置DNS1:
DNS1: 8.8.8.8
②配置域名映射
Hadoop 组件之间需要基于 SSH 进行通讯,配置免密登录后不需要每次都输入密码,配置映射:
vim /etc/hosts# 文件末尾增加(之前增加过无需增加)
192.168.10.120 server
重启下网卡:
systemctl restart network
测试环境
1、windows环境配置hosts文件
前提,我们需要配置域名映射(Hbase会使用到),因为我们从zookeeper中取到的是服务名,自然我们应该去配置映射:
- 路径位置:C:\Windows\System32\drivers\etc
- 配置信息:192.168.10.126 server
# 刷新DNS解析缓存
ipconfig /flushdns
2、finalshell测试连接
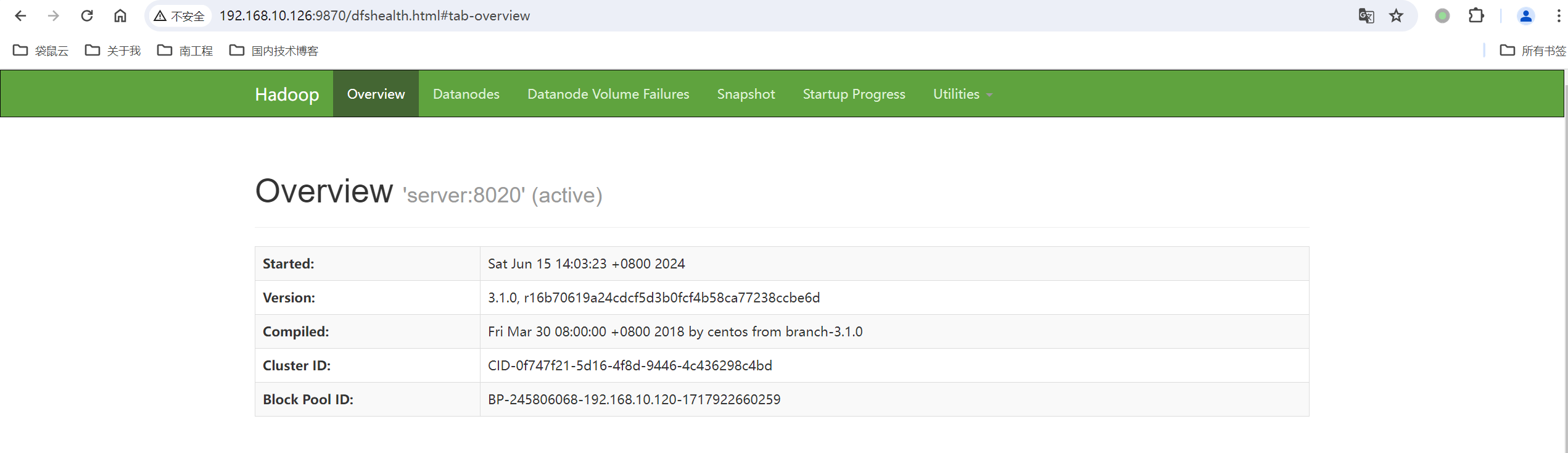
3、访问HDFS:http://server:9870/dfshealth.html#tab-overview
整理者:长路 时间:2024.2.3-6.7