目录
- Java 集合框架详谈及代码分析(Iterable->Collection->List、Set->各接口实现类、Map->各接口实现类)
- 1、集合概述
- 1-1:Java 集合概述
- 1-2:List、Set、Map 三者的区别?
- 1-3:集合框架底层数据结构分析
- 1-3-1:List 接口
- ArrayList:底层的数据结构是 Object[] 数组
- Vector:底层的数据结构是 Object[] 数组
- LinkedList:底层的数据结构是 双向链表
- 1-3-2:Set 接口
- HashSet(元素是 无序、唯一):
- LinkedHashSet:(元素是 有序、唯一)
- TreeSet(元素是 有序、唯一):
- 1-3-3:Map 接口
- HashMap :元素是 无序存储的
- LinkedHashMap:元素是 有序存储的
- HashTable:元素是 无序存储的
- TreeMap:元素是 有序存储的
- 1-4:如何选用集合?
- 1-5:Iterator 迭代器
- 迭代器 Iterator 是什么?
- 简单使用迭代器
- 遍历 List 集合
- 代码:
- 遍历 Map 集合
- 代码:
- 小总结:
- 1-6:线程安全和不安全的集合介绍
- 2、List 接口集合分析
- 2-1:ArrayList 和 Vector 的区别?
- 2-2:ArrayList 和 LinkedList 的区别?
- 2-3:双向链表和双向循环链表 --> 图解
- 3、Set 接口集合分析
- 3-1:comparable 和 Comparator 的区别
- 3-1-1:Comparator 定制排序
- 代码:
- 3-2:无序性和不可重复性的含义
- 无序性:
- 不可重复性:
- 3-3:HashSet、LinkedHashSet 和 TreeSet 三者的区别
- 4、Map 接口集合分析
- 4-1:HashMap 和 Hashtable 的区别
- 4-2:HashMap 和 HashSet 区别
- 4-3:HashMap 和 TreeMap 区别
- 代码:
- 4-4:HashSet 如何检查重复
- hashCode() 与 equals() 的相关规定:
- == 与 equals 的区别
- 4-5:ConcurrentHashMap 和 Hashtable 的区别
- 5、注意事项:
- 不要在 foreach 循环里进行元素的 remove / add 操作
- 代码示例:
Java 集合框架详谈及代码分析(Iterable->Collection->List、Set->各接口实现类、Map->各接口实现类)
1、集合概述
1-1:Java 集合概述
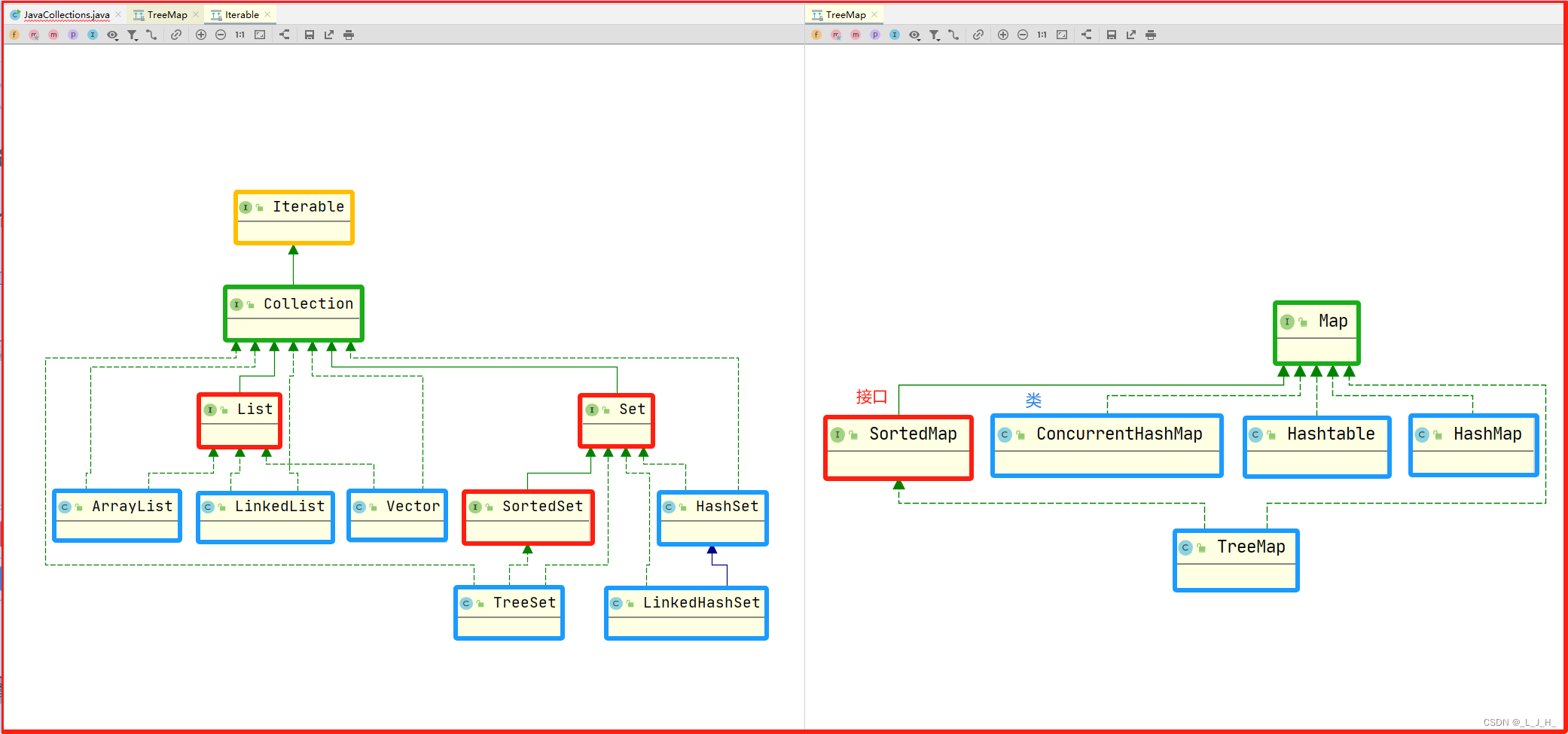
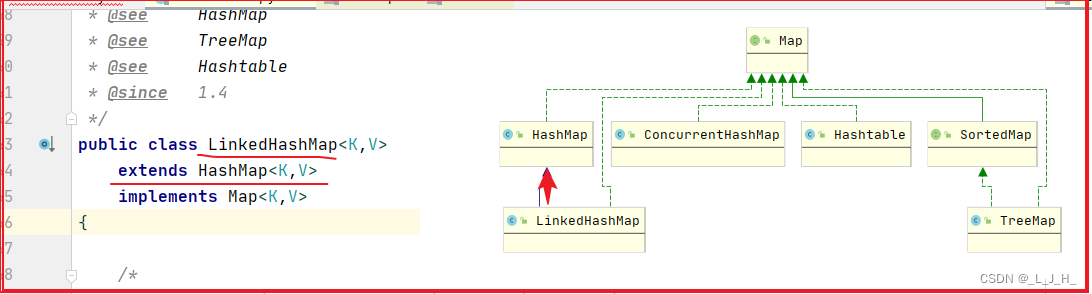
Java 集合框架包括一组接口和类,核心接口包括 Collection、List、Set 和 Map,它们定义了不同类型的集合操作和行为。
如图:List 和 Set 这两个集合接口都继承了 Collection 接口,而 Map 独立于 Collection 接口,用于存储键值对。
简单在IDEA工具上展示常用集合的继承关系:
List 接口的主要实现类:ArrayList、LinkedList、Vector;
Set 接口的主要实现类:HashSet、LinkedHashSet、TreeSet;
Map 接口的主要实现类:HashMap、ConcurrentHashMap、TreeMap、HashTable;
1-2:List、Set、Map 三者的区别?
List:存储的元素是有序的、可重复的。
Set:存储的元素是无序的、不可重复的。
Map:使用键值对(key-value)进行存储,key 是唯一的、无序的、不可重复的,value 是无序的、可重复的,每个键(key)最多映射到一个值(value)。
1-3:集合框架底层数据结构分析
散列表,又叫哈希表,里面的元素是无序存储的,而链表和红黑树则是有序的。
Collection 接口下的集合:
1-3-1:List 接口
List 接口下的实现类的底层数据结构
ArrayList:底层的数据结构是 Object[] 数组
Vector:底层的数据结构是 Object[] 数组
LinkedList:底层的数据结构是 双向链表
1-3-2:Set 接口
HashSet(元素是 无序、唯一):
基于 HashMap 实现的,底层采用 HashMap 来保存元素。
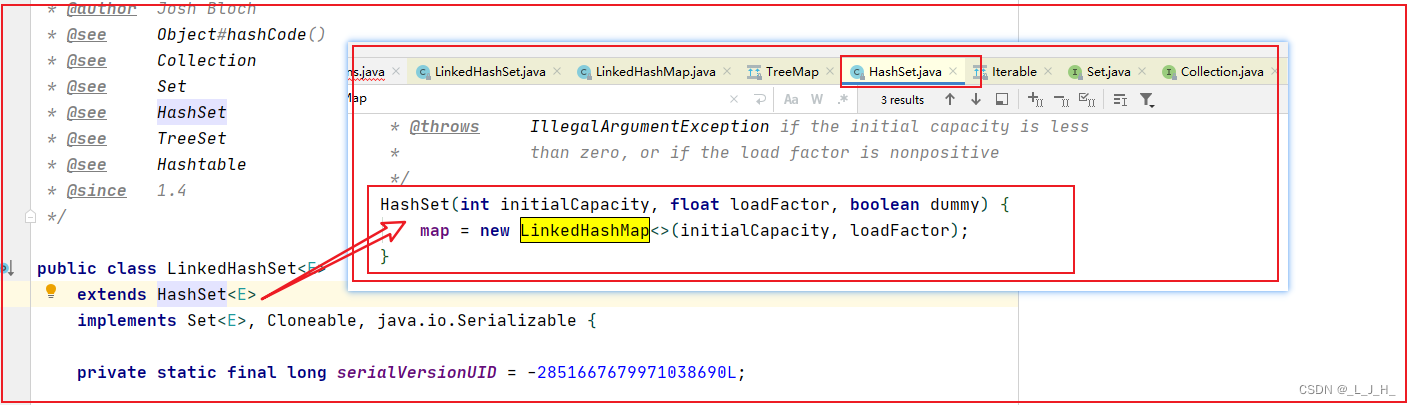
LinkedHashSet:(元素是 有序、唯一)
LinkedHashSet 是 HashSet 的子类,其内部是通过 LinkedHashMap 来实现的。
一些源代码:
TreeSet(元素是 有序、唯一):
底层是基于红黑树实现的(自平衡的排序二叉树)
1-3-3:Map 接口
key 是唯一的,value是 可重复的。
HashMap :元素是 无序存储的
JDK1.8 之前,HashMap 是由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(通过“拉链法”解决冲突);
JDK1.8 之后,在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认是 8 )时,会将链表转化为红黑树,以减少搜索时间。
注意:在将链表转成红黑树之前会进行判断,如果当前数组的长度小于 64 ,那么会先进行数组扩容,而不是直接转换成红黑树,只有数组长度达到或超过 64 时,才会转成红黑树。
HashMap 数组扩容时,会将数组的容量扩充为原先的一倍,并重新分配现有的键值对到新的数组中。
LinkedHashMap:元素是 有序存储的
LinkedHashMap 继承自 HashMap ,所以他的底层仍然是基于拉链式散列结构,即由数组+链表/红黑树组成。
并且在这个数据结构的基础上,增加了一条 双向链表 ,作用是可以维护键值对(元素)的插入顺序和访问顺序。
访问顺序:每次通过 get、put 等方法访问该集合里面的元素时,该元素会被移动到链表的末尾,同理,较少访问到的元素则会位于链表的头部。
HashTable:元素是 无序存储的
数组 + 链表组成的,数组是 HashMap 的主体,链表则是为了解决哈希冲突而存在的。
HashTable 基本不怎么用了,都是由 HashMap 来代替。
TreeMap:元素是 有序存储的
基于红黑树(自平衡的排序二叉树)实现的。
1-4:如何选用集合?
需要根据键(key)获取到元素值时,就选用 Map 接口下的集合:
存储元素需要排序时,选择 TreeMap ;
存储元素不需要排序时,选择 HashMap ;
元素需要保证线程安全,选择 ConcurrentHashMap ;
当我们只需要存放元素值时,就选择实现 Collection 接口的集合(List、Set):
需要保证元素唯一时,选择实现了 Set 接口的集合:TreeSet 或 HashSet ;
不需要保证元素唯一,选择实现 List 接口的集合:ArrayList 或 LinkedList ;
1-5:Iterator 迭代器
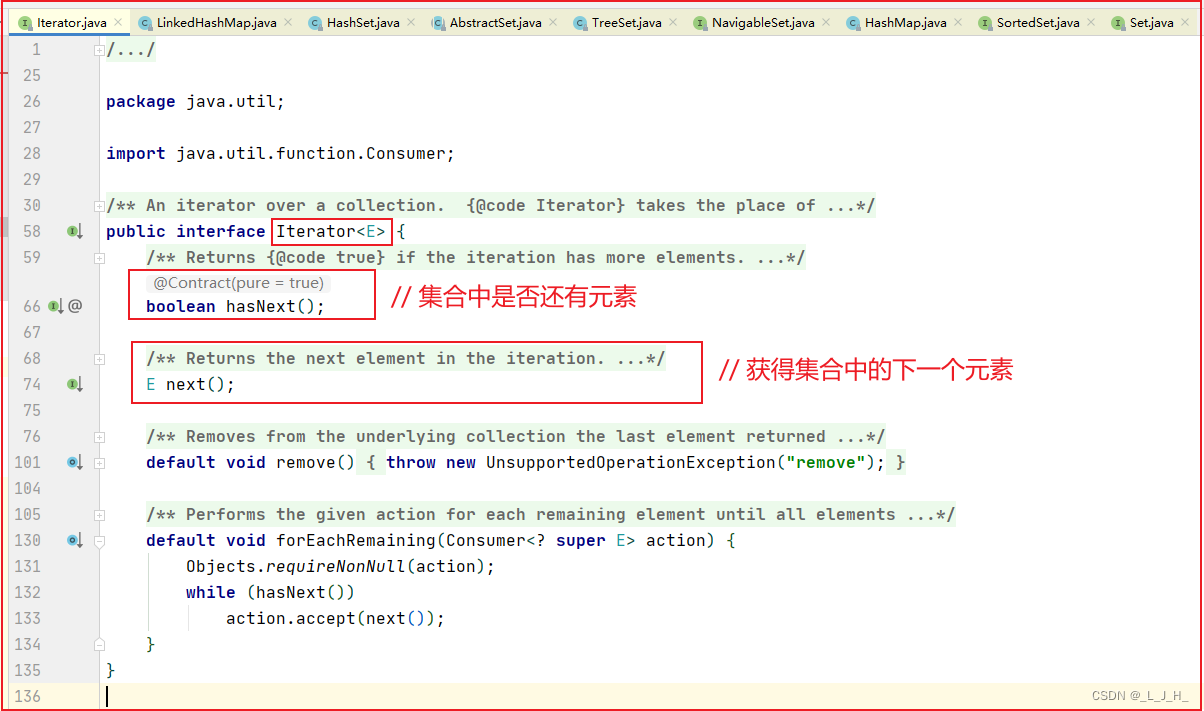
迭代器 Iterator 是什么?
迭代器也是设计模式的一种,叫做 迭代器模式。
源码是这样的:
简单使用迭代器
遍历 List 集合
优点:如果在迭代器遍历该list集合期间,有其他线程修改了集合中的元素值,那么迭代器就会报错:ConcurrentModificationException
注意点:如果通过迭代器遍历完了,因为业务需求,需要再遍历一次,就只能再通过 list.iterator(); 再一次获取迭代器来遍历。
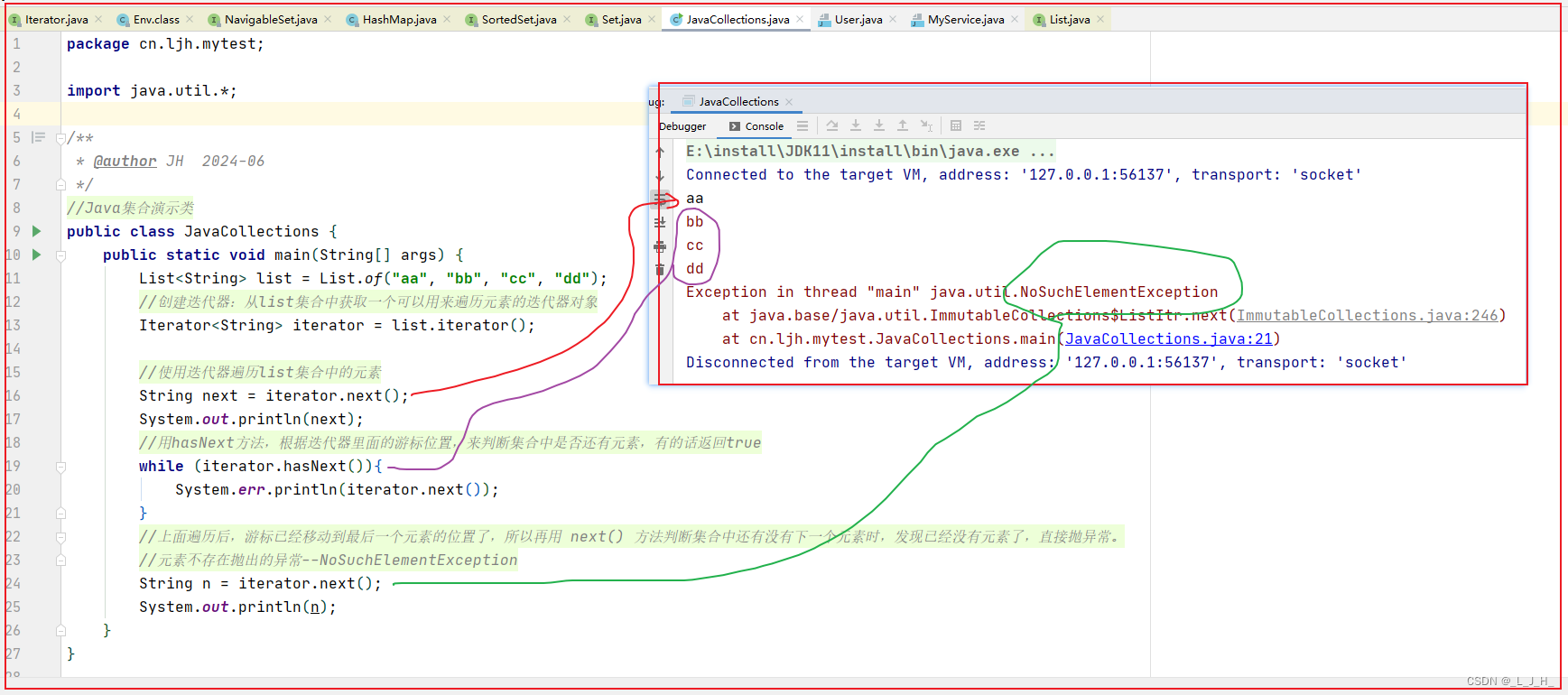
代码:
//Java集合演示类
public class JavaCollections {public static void main(String[] args) {List<String> list = List.of("aa", "bb", "cc", "dd");//创建迭代器:从list集合中获取一个可以用来遍历元素的迭代器对象Iterator<String> iterator = list.iterator();//使用迭代器遍历list集合中的元素String next = iterator.next();System.out.println(next);//用hasNext方法,根据迭代器里面的游标位置,来判断集合中是否还有元素,有的话返回truewhile (iterator.hasNext()){System.err.println(iterator.next());}//上面遍历后,游标已经移动到最后一个元素的位置了,所以再用 next() 方法判断集合中还有没有下一个元素时,发现已经没有元素了,直接抛异常。//元素不存在抛出的异常--NoSuchElementExceptionString n = iterator.next();System.out.println(n);}
}
遍历 Map 集合
简单演示下用 Iterator 迭代器遍历 Map 集合。
如图,源码中,因为 Iterator 迭代器是由 Iterable 接口提供的,而 Collection 接口继承了 Iterable 接口,而 List 接口 和 Set 接口又继承了 Collection 接口,所以 List 和 Set 集合可以使用迭代器,但是 Map 就不行了,因为 Map 并不是继承 Iterable 接口。
所以当我们要用迭代器去遍历 HashMap 集合时,需要先把 HashMap 集合通过 entrySet() 方法转换成映射 Set 集合。
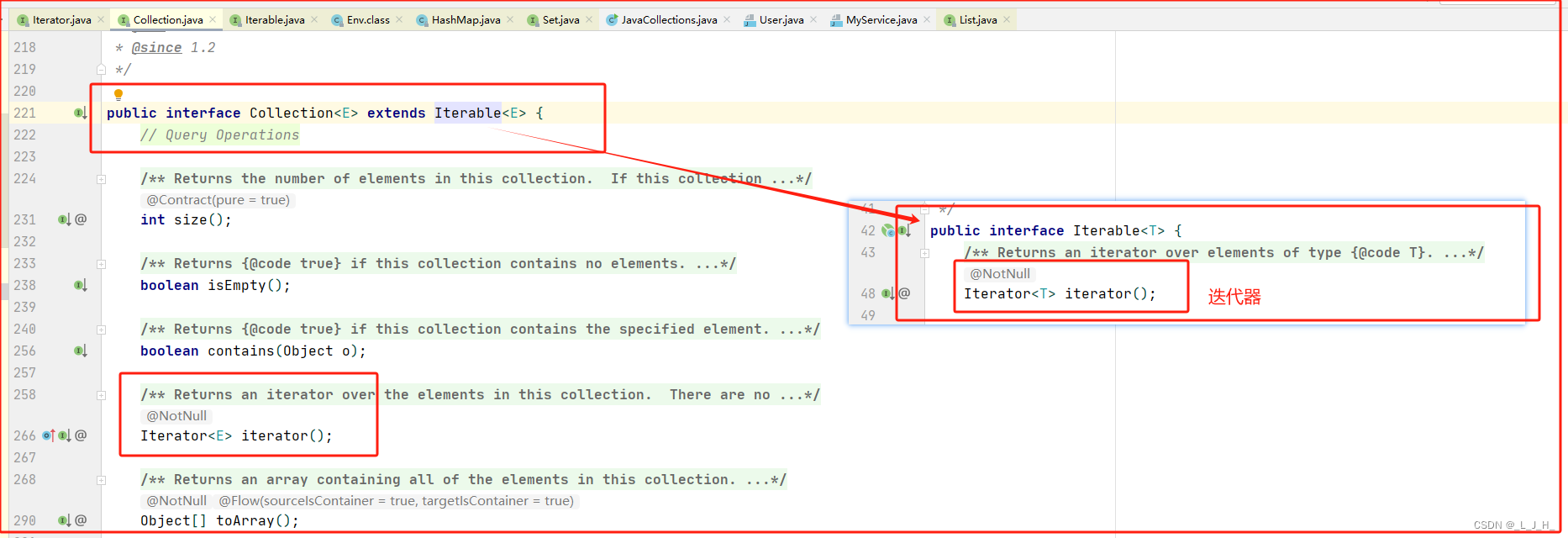
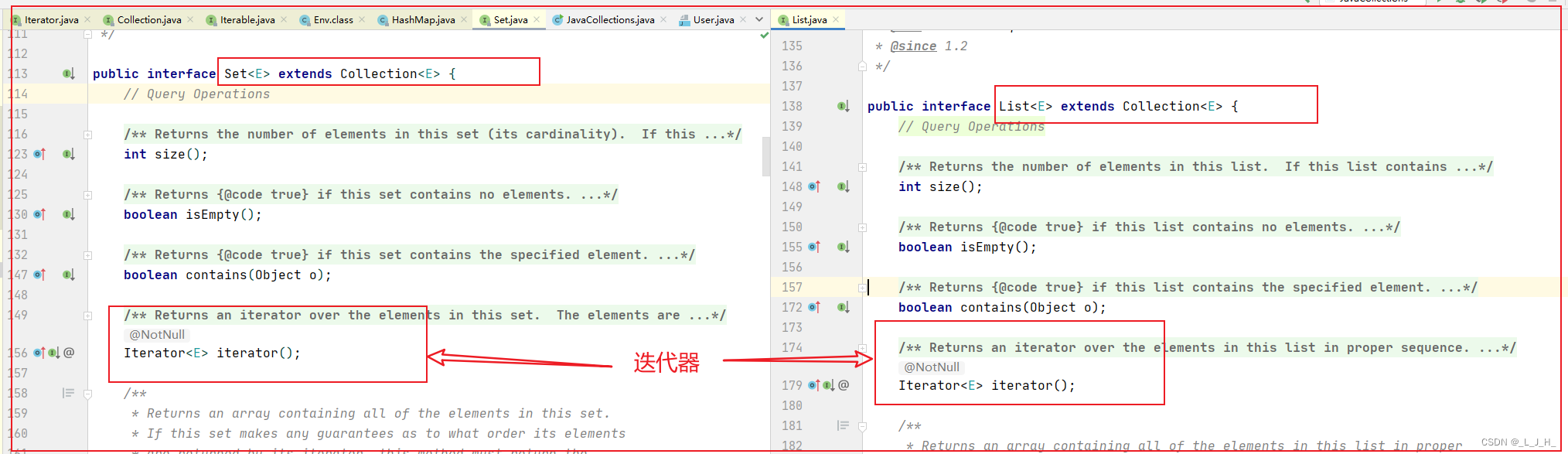
如图:迭代器遍历 HashMap 代码实现
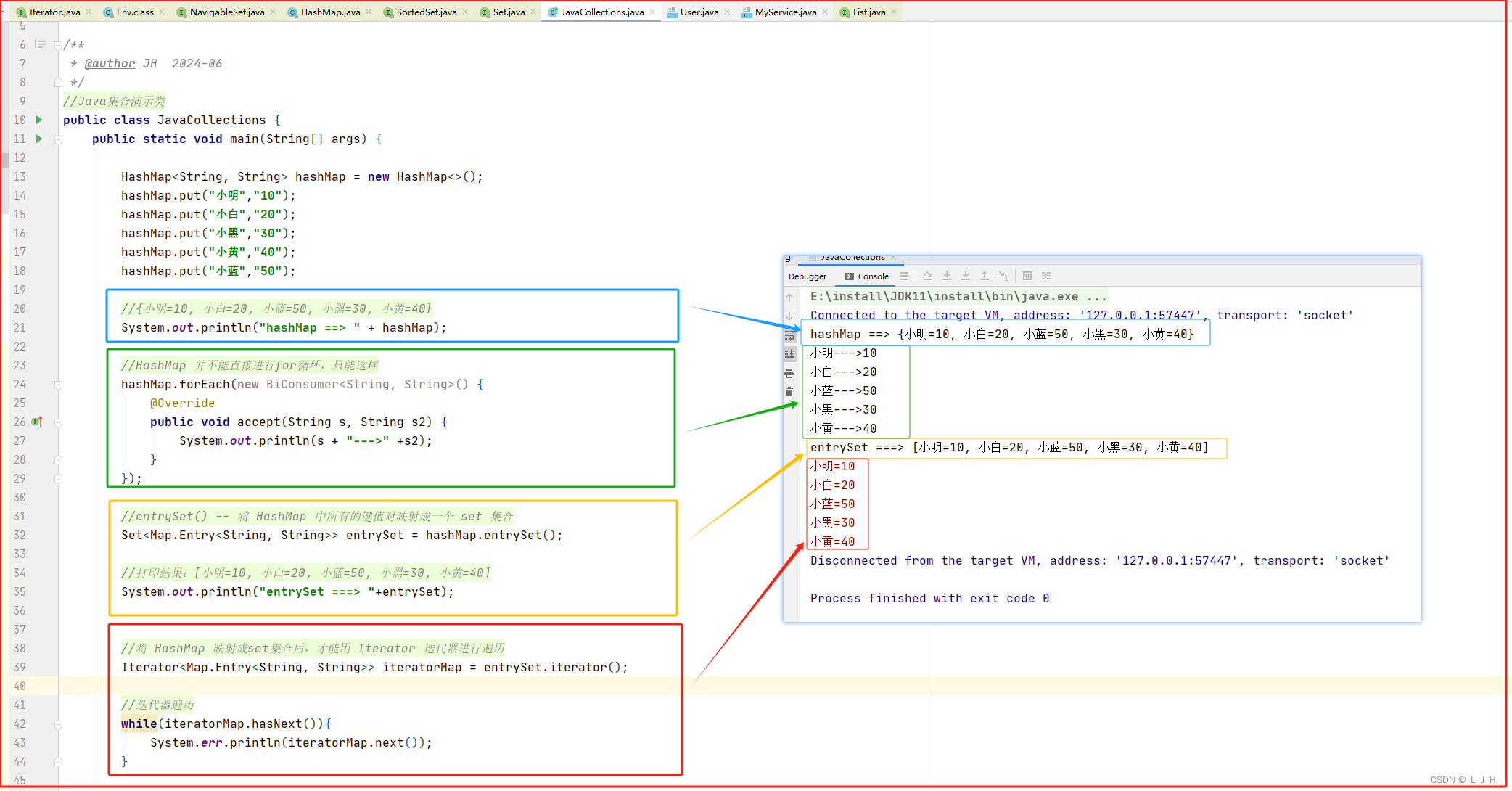
代码:
//Java集合演示类
public class JavaCollections {public static void main(String[] args) {HashMap<String, String> hashMap = new HashMap<>();hashMap.put("小明","10");hashMap.put("小白","20");hashMap.put("小黑","30");hashMap.put("小黄","40");hashMap.put("小蓝","50");//{小明=10, 小白=20, 小蓝=50, 小黑=30, 小黄=40}System.out.println("hashMap ==> " + hashMap);//HashMap 并不能直接进行for循环,只能这样hashMap.forEach(new BiConsumer<String, String>() {@Overridepublic void accept(String s, String s2) {System.out.println(s + "--->" +s2);}});//entrySet() -- 将 HashMap 中所有的键值对映射成一个 set 集合Set<Map.Entry<String, String>> entrySet = hashMap.entrySet();//打印结果:[小明=10, 小白=20, 小蓝=50, 小黑=30, 小黄=40]System.out.println("entrySet ===> "+entrySet);//将 HashMap 映射成set集合后,才能用 Iterator 迭代器进行遍历Iterator<Map.Entry<String, String>> iteratorMap = entrySet.iterator();//迭代器遍历while(iteratorMap.hasNext()){System.err.println(iteratorMap.next());}}
}
小总结:
Iterator 对象称为迭代器,是设计模式中的一种,迭代器可以对集合进行遍历,它的特点是更加安全,因为它可以确保,在遍历当前集合元素期间,如果元素被其他线程更改到,会抛出 ConcurrentModificationException 异常。
1-6:线程安全和不安全的集合介绍
ArrayList、LinkedList、HashMap、TreeSet、TreeMap 都是线程不安全的。
如果要使用线程安全的集合,下面是一些替代关系:
1、ConcurrentHashMap: 可以看作是线程安全的 HashMap;
2、CopyOnWriteArrayList:可以看作是线程安全的 ArrayList ;
在读多写少的场合性能⾮常好,远远好于 Vector .
3、ConcurrentLinkedQueue: 可以看做⼀个线程安全的 LinkedList;
ConcurrentLinkedQueue 是高效的并发队列,使用链表实现,是一个非阻塞队列。
4、ConcurrentSkipListMap:跳表的实现,这是一个 Map,使用 跳表 的数据结构进行快速查找。
2、List 接口集合分析
2-1:ArrayList 和 Vector 的区别?
1、ArrayList 是 List 的主要实现类,底层使用 Object[] 数组进行元素存储,适用于频繁的查找工作,线程不安全;
2、Vector 是 List 的古老实现类,底层使用 Object[] 数组进行元素存储,线程是安全的。
2-2:ArrayList 和 LinkedList 的区别?
1、线程安全方面:
ArrayList 和 LinkedList 都是不同步的,也就是 线程都是不安全的。
(同步是指多个线程之间协调执行的机制。
比如多个线程同时修改这个集合,因为不是同步的,可能就导致数据操作不是原子性的,会出现数据不一致的问题)
2、底层数据结构:
ArrayList 底层使用的是 Object 数组;
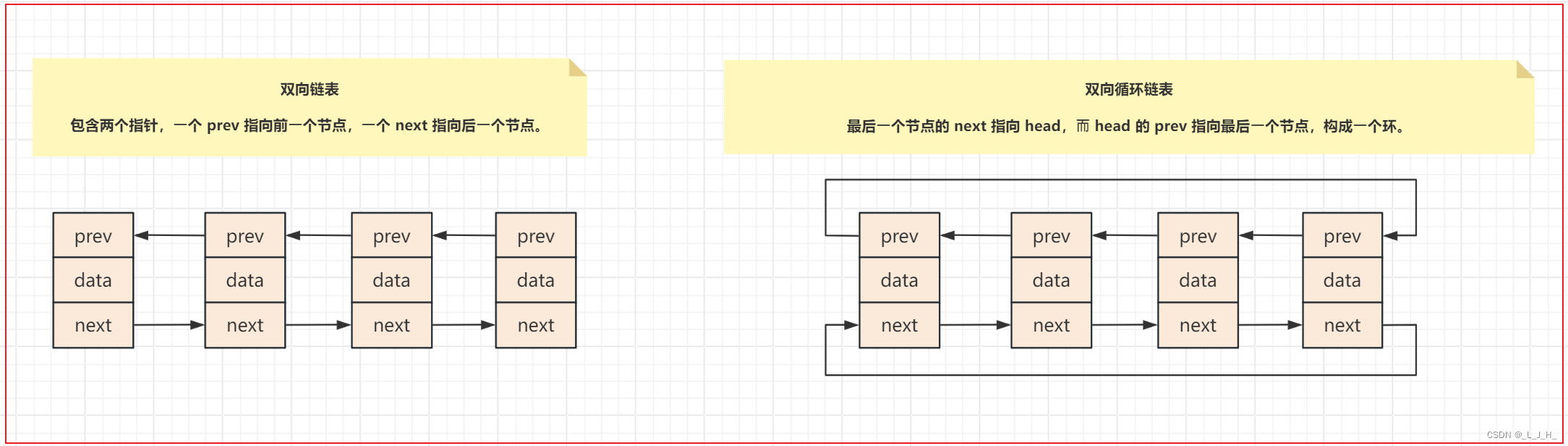
LinkedList 底层使用的是 双向链表 的数据结构;
3、是否支持快速随机访问:
快速随机访问就是通过元素的序号快速获取元素的对象,也就是 get(int index) 方法。
ArrayList 支持;LinkedList 不支持。
4、内存空间占用问题:
ArrayList 主要是在 List 列表的结尾会预留一定的容量空间;
LinkedList 主要是每个元素都需要消耗比 ArrayList 更多的空间
(LinkedList 的每个元素的前后都需要占据4个字节的空间,然后本身元素也要占据 4个字节的空间)
2-3:双向链表和双向循环链表 --> 图解
3、Set 接口集合分析
3-1:comparable 和 Comparator 的区别
comparable 接口有一个 compareTo 方法来对集合进行排序;
Comparator 接口有一个 compare 方法来对集合进行排序。

3-1-1:Comparator 定制排序
Comparator 的 compare 方法实现了逆序排序(从大到小)
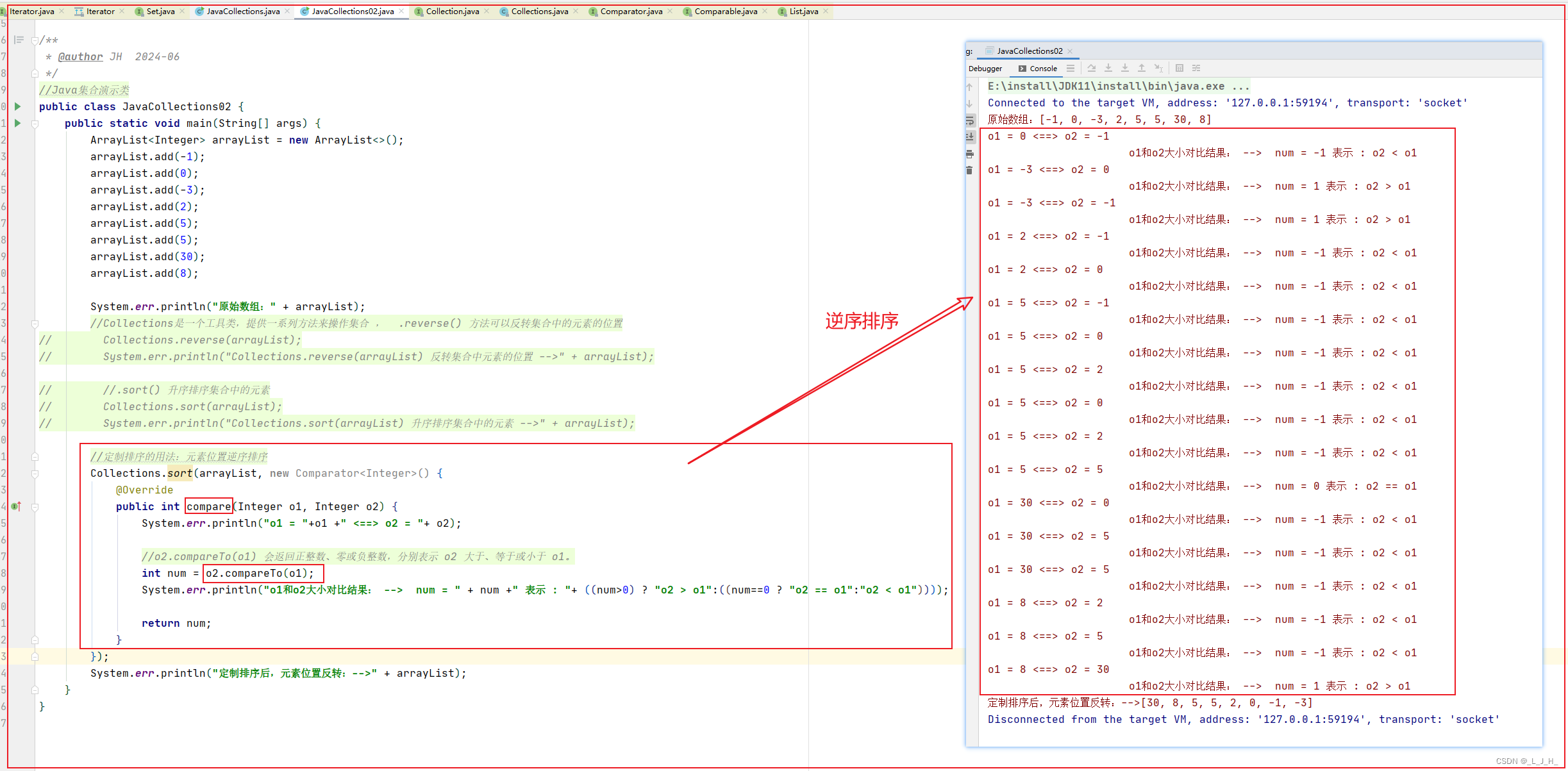
代码:
//Java集合演示类
public class JavaCollections02 {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(-1);arrayList.add(0);arrayList.add(-3);arrayList.add(2);arrayList.add(5);arrayList.add(5);arrayList.add(30);arrayList.add(8);System.err.println("原始数组:" + arrayList);//Collections是一个工具类,提供一系列方法来操作集合 , .reverse() 方法可以反转集合中的元素的位置
// Collections.reverse(arrayList);
// System.err.println("Collections.reverse(arrayList) 反转集合中元素的位置 -->" + arrayList);// //.sort() 升序排序集合中的元素
// Collections.sort(arrayList);
// System.err.println("Collections.sort(arrayList) 升序排序集合中的元素 -->" + arrayList);//定制排序的用法:元素位置逆序排序Collections.sort(arrayList, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {System.err.println("o1 = "+o1 +" <==> o2 = "+ o2);//o2.compareTo(o1) 会返回正整数、零或负整数,分别表示 o2 大于、等于或小于 o1。int num = o2.compareTo(o1);System.err.println("o1和o2大小对比结果: --> num = " + num +" 表示 : "+ ((num>0) ? "o2 > o1":((num==0 ? "o2 == o1":"o2 < o1"))));return num;}});System.err.println("定制排序后,元素位置反转:-->" + arrayList);}
}
3-2:无序性和不可重复性的含义
无序性:
无序性不等于随机性,无序性是指存储的数据元素在底层数组中,并非按照数组索引的顺序添加的,而是根据数据的哈希值决定的。
不可重复性:
不可重复性是指添加的元素按照 equals() 判断时,返回 false,需要同时重写 equals() 方法和 HashCode() 方法。
3-3:HashSet、LinkedHashSet 和 TreeSet 三者的区别
HashSet:是 Set 接口的主要实现类,HashSet 的底层是 HashMap,线程是不安全的,可以存储 null 值。
LinkedHashSet:是 HashSet 的子类,能够按照添加的顺序遍历。
TreeSet:底层是使用红黑树,能够按照添加元素的顺序进行遍历,排序的方式有自然排序和定制排序(通过 Comparator 的 compare 方法来定制排序)。
4、Map 接口集合分析
4-1:HashMap 和 Hashtable 的区别
1、线程是否安全:
HashMap 是线程不安全的;HashTable 是线程安全的,因为 HashTable 内部的方法基本都经过 synchronized 关键字修饰过。
如果要保证线程安全的话,就直接使用 ConcurrentHashMap
2、效率:
因为线程安全问题,所以 HashMap 效率要比 HashTable 高一点。
另外,HashTable 基本被淘汰了,尽量不适用它。
3、对 Null Key 和 Null Value 的支持:
HashMap 可以存储 null 的 key 和 value,但是 null 作为 key 只能有一个,null 作为值可以有多个;
HashTable 不允许有null key 和 null 值,否则会报错。
4、初始容量大小和每次扩充容量大小的不同:
创建时如果不指定初始容量值,HashMap 默认的初始化大小为 16 ,之后每次扩充,容量变为原来的 2 倍。而 HashTable 默认的初始化大小为 11,之后每次扩充,容量变为原来的 2n+1。
创建时如果设置了初始容量值,那么 HashMap 会将其扩充为 2 的幂次方大小,也就是说 HashMap 总是使用 2 的幂作为哈希表的大小。而 HashTable 会直接使用我们给定的初始容量值。
比如我给 HashMap 的初始容量值时 8,HashMap 在内部会将这个值调整为比 8 大且最接近 8 的一个 2 的幂次方,那么扩充为 2 的幂次方大小就是:16,也就是扩充为原来容量的两倍。
示例:8 是 2 ^ 3 ,那么比8大且最接近,就是 2 ^ 4 ,就是16
如果我设置为 20 ,那么比 20 大又最接近的就是 2 ^ 5 = 32
问题:初始容量设置为 20 ,根据 2 的幂次方来扩充,选择的是 32 ,也不是原来的两倍呀。
解答:对于 HashMap 来说,在进行扩容时,并不是严格按照原来容量的两倍进行扩容的,当 HashMap 中的元素数量达到当前容量与负载因子的乘积时(默认负载因子为 0.75),HashMap 就会进行扩容操作。
在设置初始容量为 20 的情况下,HashMap 首先会找到大于等于 20 的最小的 2 的幂,即 32,作为初始容量。
当 HashMap 中元素数量达到 32 * 0.75 = 24 时,HashMap 将进行扩容操作,将容量扩大为 32 的两倍,即 64。
注意:初始容量的设置只会在一开始时,通过 2 的幂次方进行调整,调整为不小于指定初始容量的最接近的 2 的幂次方大小。
而在后续扩容过程中,HashMap 会将当前容量直接扩容为两倍,从而保持容量始终为 2 的幂次方。
5、底层数据结构:
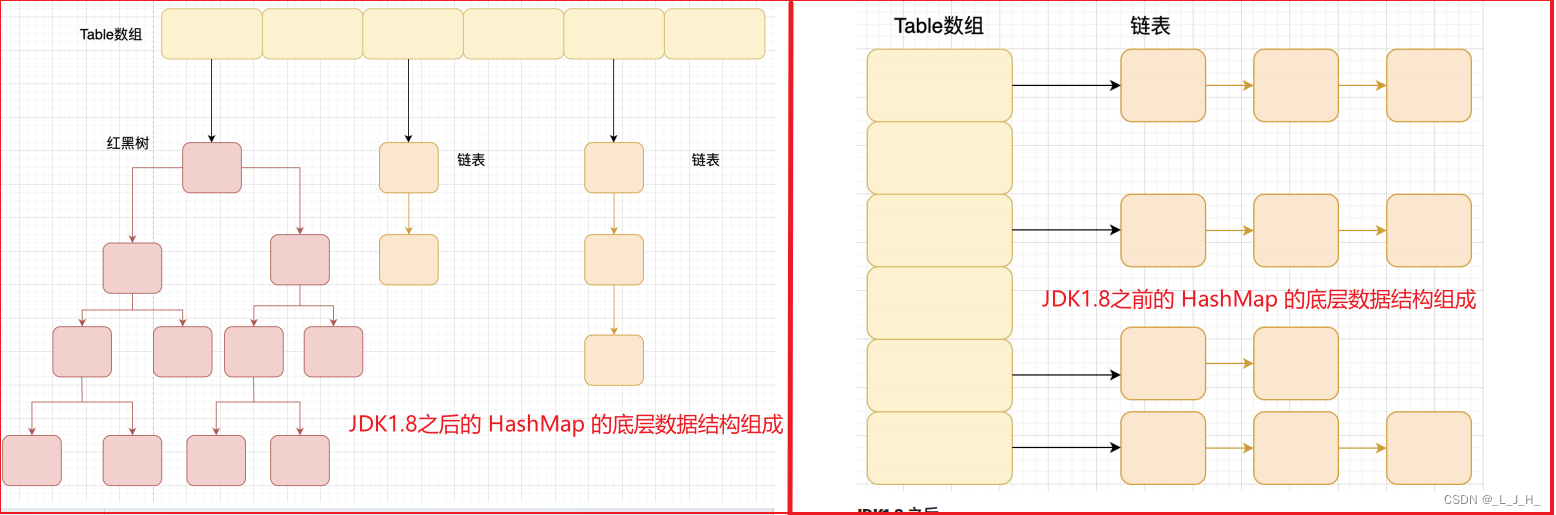
HashMap 的底层数据结构是:数组+链表+红黑树
JDK1.8 之后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认是 8 )时,会将链表转化为红黑树,以减少搜索时间。
注意:在将链表转成红黑树之前会进行判断,如果当前数组的长度小于 64 ,那么会先进行数组扩容,而不是直接转换成红黑树,只有数组长度达到或超过 64 时,才会转成红黑树。
HashMap 数组扩容时,会将数组的容量扩充为原先的一倍,并重新分配现有的键值对到新的数组中。
HashTable 的底层数据结构是:数组+链表,但是没有转成红黑树的机制
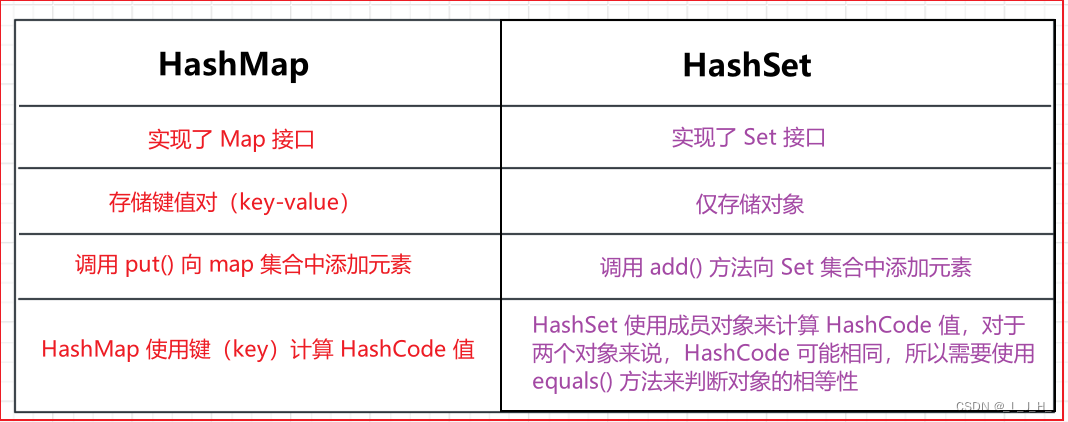
4-2:HashMap 和 HashSet 区别
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet ⾃⼰不得不实现之外,其他⽅法都是直接调⽤ HashMap 中的⽅法。
4-3:HashMap 和 TreeMap 区别
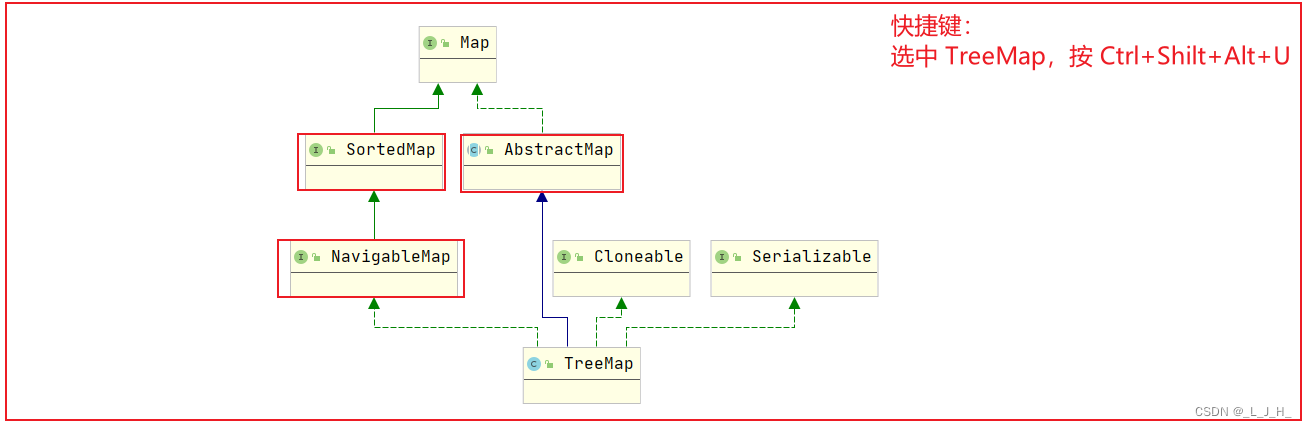
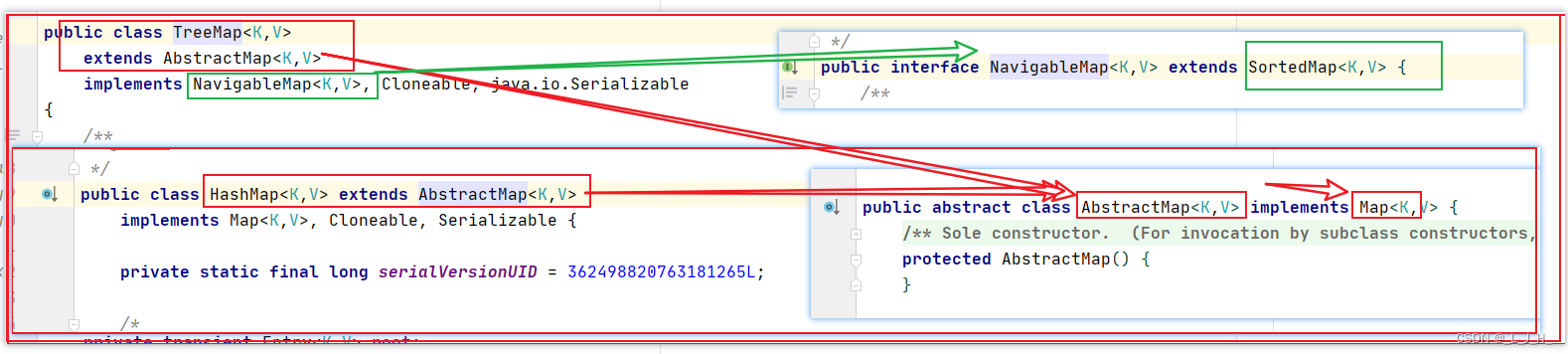
TreeMap 和 HashMap 都继承自 AbstractMap ,但是需要注意的是 TreeMap 它还实现了NavigableMap 接口和 SortedMap 接口。
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现 SortMap 接口让 TreeMap 有了对集合中的元素根据键排序的能力,默认是按 key 的升序排序,不过我们也可以指定排序的比较器(使用 Comparator 接口的 compare 方法)。
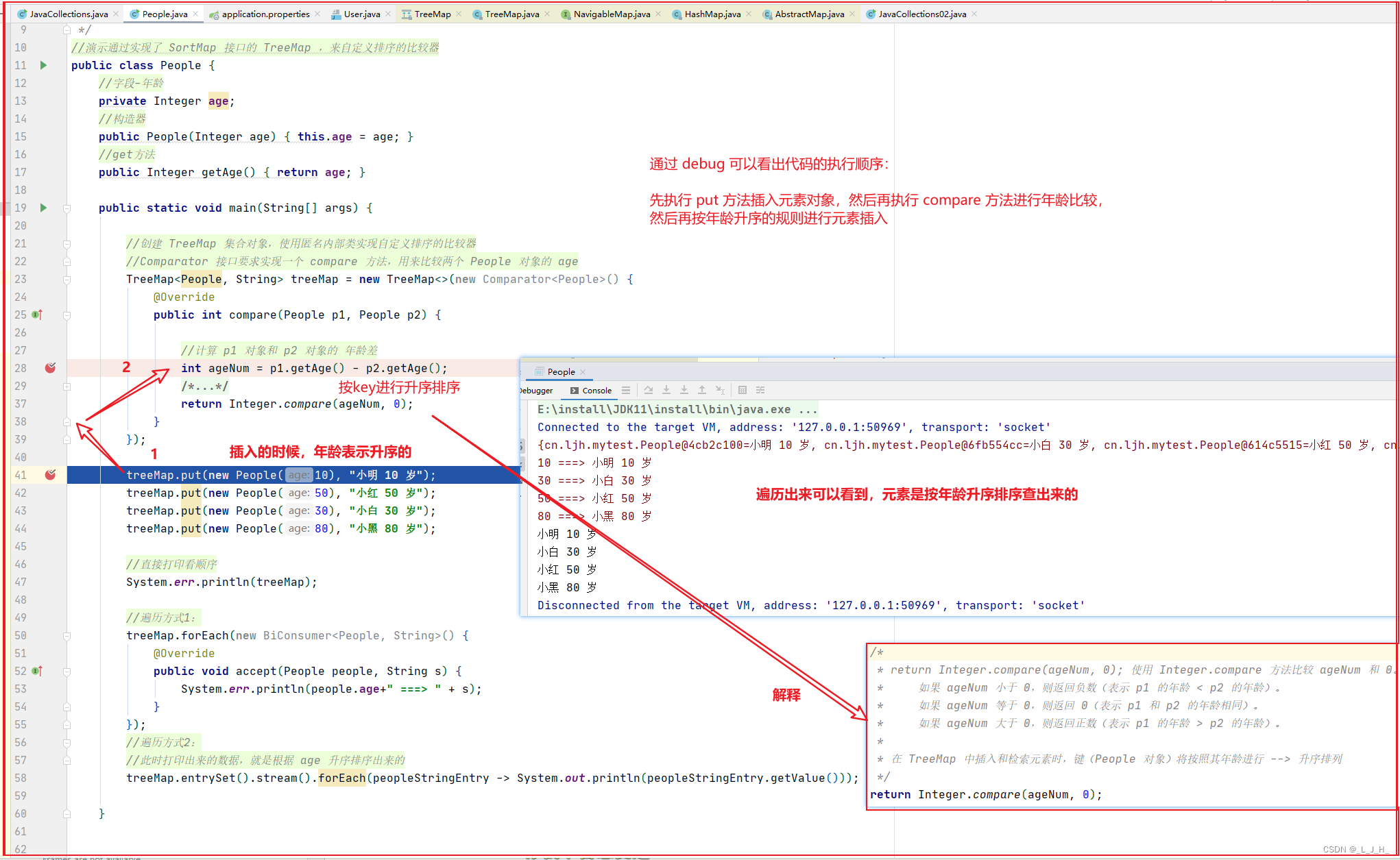
示例代码如下:
如图可以看出,TreeMap 中的元素已经是按照 People 的 age 字段的升序来排列了。
相比于 HashMap 来说, TreeMap 主要多了对集合中的元素根据键(key)排序的能力以及对集合内元素
的搜索的能力。
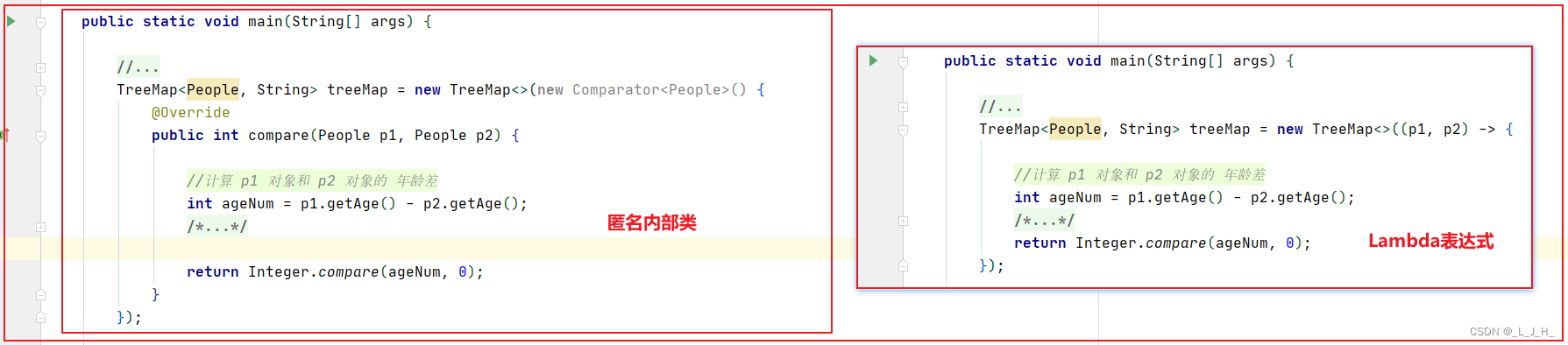
上面是通过传⼊匿名内部类的方式实现的,可以将代码替换成 Lambda 表达式实现的⽅式:

TreeMap 的继承关系图例:
代码:
package cn.ljh.mytest;import java.util.Comparator;
import java.util.TreeMap;
import java.util.function.BiConsumer;/*** @author JH 2024-06*/
//演示通过实现了 SortMap 接口的 TreeMap ,来自定义排序的比较器
public class People {//字段-年龄private Integer age;//构造器public People(Integer age) { this.age = age; }//get方法public Integer getAge() { return age; }public static void main(String[] args) {//创建 TreeMap 集合对象,使用匿名内部类实现自定义排序的比较器//Comparator 接口要求实现一个 compare 方法,用来比较两个 People 对象的 ageTreeMap<People, String> treeMap = new TreeMap<>(new Comparator<People>() {@Overridepublic int compare(People p1, People p2) {//计算 p1 对象和 p2 对象的 年龄差int ageNum = p1.getAge() - p2.getAge();/** return Integer.compare(ageNum, 0); 使用 Integer.compare 方法比较 ageNum 和 0。* 如果 ageNum 小于 0,则返回负数(表示 p1 的年龄 < p2 的年龄)。* 如果 ageNum 等于 0,则返回 0(表示 p1 和 p2 的年龄相同)。* 如果 ageNum 大于 0,则返回正数(表示 p1 的年龄 > p2 的年龄)。** 在 TreeMap 中插入和检索元素时,键(People 对象)将按照其年龄进行 --> 升序排列*///按 key 进行升序排序return Integer.compare(ageNum, 0);}});treeMap.put(new People(10), "小明 10 岁");treeMap.put(new People(50), "小红 50 岁");treeMap.put(new People(30), "小白 30 岁");treeMap.put(new People(80), "小黑 80 岁");//直接打印看顺序System.err.println(treeMap);//遍历方式1:treeMap.forEach(new BiConsumer<People, String>() {@Overridepublic void accept(People people, String s) {System.err.println(people.age+" ===> " + s);}});//遍历方式2://此时打印出来的数据,就是根据 age 升序排序出来的treeMap.entrySet().stream().forEach(peopleStringEntry -> System.out.println(peopleStringEntry.getValue()));}
}4-4:HashSet 如何检查重复
当我们通过 .add() 方法把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加⼊的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。
但是如果发现有相同 hashcode 值的对象,这时会调用 equals() 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加⼊操作成功。
hashCode() 与 equals() 的相关规定:
1、如果两个对象相等,则 hashcode ⼀定也是相同的;
2、两个对象相等,通过 equals 方法对比会返回 true,如:a.equals(b) ==> true
3、两个对象有相同的 hashcode 值,它们也不⼀定是相等的。
4、综上,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
5、hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
== 与 equals 的区别
对于基本数据类型来说,== 比较的是两个值是否相等;
对于引用数据类型来说,== 比较的是两个对象的内存地址。
equals() :判断两个对象是否相等。
没重写前,功能等价于 == ,比较的是地址是否相等;
重写后,就是判断两个对象的内容(地址里的内容)是否相等。

String 的 equals 是重写过的,Object 的 equals 方法比较的是对象的内存地址。
4-5:ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
1、底层数据结构:
ConcurrentHashMap:数组+链表/红⿊⼆叉树
Hashtable:数组+链表
2、实现线程安全的方式:
ConcurrentHashMap:
JDK1.7–> 采用分段锁 技术;
JDK1.8 之后,采用 Node 数组+链表+红黑树 的数据结构,并发控制 采用 synchronized 和 CAS 来实现。
Hashtable :使用 synchronized 实现线程安全。
5、注意事项:
不要在 foreach 循环里进行元素的 remove / add 操作
如果要在循环里面删除和添加元素,要使用 Iterator 方式,如果是并发操作,需要对Iterator 对象加锁。
代码示例:
没使用 Iterator 的 remove 方法来在循环里面删除元素,则会报 ConcurrentModificationException 修改异常。
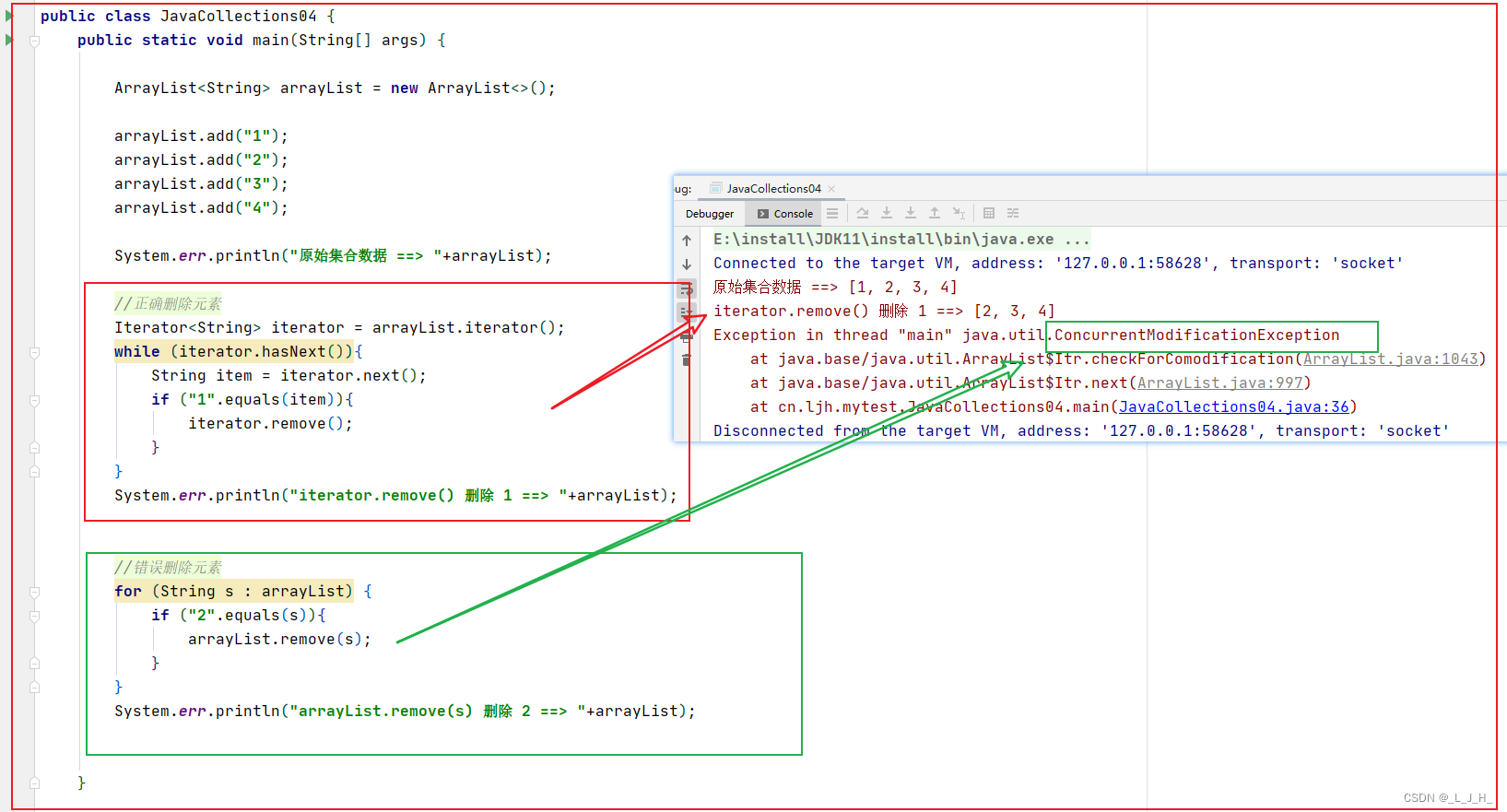
public class JavaCollections04 {public static void main(String[] args) {ArrayList<String> arrayList = new ArrayList<>();arrayList.add("1");arrayList.add("2");arrayList.add("3");arrayList.add("4");System.err.println("原始集合数据 ==> "+arrayList);//正确删除元素Iterator<String> iterator = arrayList.iterator();while (iterator.hasNext()){String item = iterator.next();if ("1".equals(item)){iterator.remove();}}System.err.println("iterator.remove() 删除 1 ==> "+arrayList);//错误删除元素for (String s : arrayList) {if ("2".equals(s)){arrayList.remove(s);}}System.err.println("arrayList.remove(s) 删除 2 ==> "+arrayList);}
}