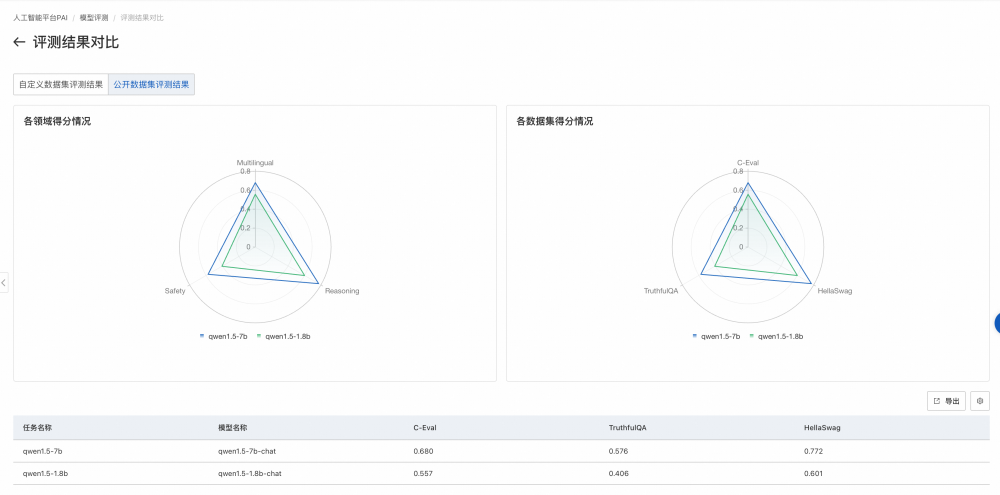
本文主要介绍如何在无需网关,无需配置 HttpClient 的情况下,使用 Semantic Kernel 直接调用本地大模型与阿里云灵积 DashScope 等 OpenAI 接口兼容的大模型服务。
1. 背景
一直以来,我们都在探索如何更好地利用大型语言模型(LLM)的能力。Semantic Kernel 作为一个微软开源的语义内核 SDK,它提供了一种高效的方式让用户可以在自己的应用程序中集成大语言模型 (LLM) 的强大功能。
同时,随着 OpenAI 的发展,其接口调用方式已被广泛采用和认可,成为了众多大型语言模型的标准接口或兼容标准。在 .Net 使用的 OpenAI 库,大家之前一直广泛使用的是 Azure.AI.OpenAI ,但是因为设计上的一些限制,我们无法直接调用本地大模型或者一些兼容 OpenAI 接口的大模型服务。因为内部审计,统一管理,成本分摊,无法直接访问或自建服务等原因,可以方便的修改服务地址,一直是大家的迫切需求。
近期 OpenAI 正式发布了第一个官方 .NET 版的测试 SDK,Azure.AI.OpenAI 的 2.x 版本,这个版本的 SDK 也将基于这个新的 SDK 进行开发。但是目前这个 SDK 还处于测试阶段。

在之前的文章中,我也介绍了如何在 Semantic Kernel 中使用本地大模型的临时方案。当前随着 Semantic Kernel 的不断完善,我们有了更方便的方式来调用本地大模型与阿里云灵积 DashScope 等一些兼容 OpenAI 接口的大模型服务。
2. 本地服务
相信大家都有自己的本地大模型服务,或者是一些兼容 OpenAI 接口的大模型服务。本地大模型部署的方式有很多种,也越来越简单,我们可以方便的使用 Ollama、llama-server(llama.cpp) 等开源项目,来运行 Llama 3, Phi 3, Qwen2, Mistral,Gemma 等流行的大模型。
在这里我介绍一下我近期的一个开源项目 LLamaWorker,一个基于 LLamaSharp 的 ASP.NET 项目,提供 OpenAI 兼容的接口,感兴趣的同学可以了解一下。
虽然都是开源项目,但相比较而言,Ollama 更适合普通用户。而 llama.cpp 和 LLamaWorker 更适合开发者,可以更方便的进行二次开发和项目集成。
3. 代码实现
在 Semantic Kernel 中,提供了一个实验性的功能,在 OpenAI 连接器中提供了自定义服务端点的功能。这个功能可以让我们直接调用本地大模型或者一些兼容 OpenAI 接口的大模型服务。
我们可以通过 AddOpenAIChatCompletion() 创建自定义的 OpenAI 服务。对于
var services = new ServiceCollection();
services.AddKernel();
services.AddOpenAIChatCompletion("qwen-long", new Uri("https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"), "you key");
4. 注意事项
使用 AddOpenAIChatCompletion 时,我们需要输入完整的 ChatCompletion 端点,这与之前的使用习惯并不一致。
另外,由于改功能也尚处于试验阶段,并且其依赖的 Azure.AI.OpenAI 还是 1.0 的版本,对于后面的推出的 2.x 还并没有升级适配,还是需要时刻关注该接入方式的变更。
5. 最后
Semantic Kernel 的出现为开发者提供了一个强大且灵活的工具,使得在不同的环境下调用大型语言模型变得更加简单和高效。通过直接调用本地大模型或兼容 OpenAI 接口的服务,我们可以更好地控制数据的隐私和安全,同时也能够根据自己的需要调整服务的配置和性能。
此外,随着技术的发展和社区的贡献,我们期待看到更多的开源项目和工具的出现,这将进一步降低技术门槛,让更多的开发者和企业能够轻松地利用大型语言模型的强大能力。