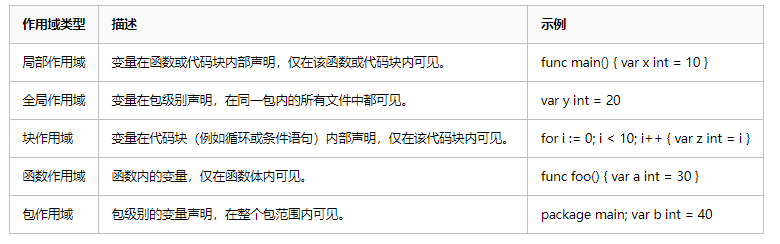
1 Git原理
版本控制系统在软件开发和团队协作中扮演着至关重要的角色。它们帮助开发人员跟踪和管理代码的变化,协调多人同时编辑同一代码库,回溯历史版本,并解决代码冲突等问题。Git作为当今最流行的分布式版本控制系统,为开发人员提供了强大的功能和灵活性。
本次汇报的主题将聚焦于Git原理、Gitflow与多人协作。我们将深入解析Git的工作原理、核心概念。
1.1 Git Objects
我们从git一次提交作为切入点,即”git add .“,”git commit -m ”xxx“”。
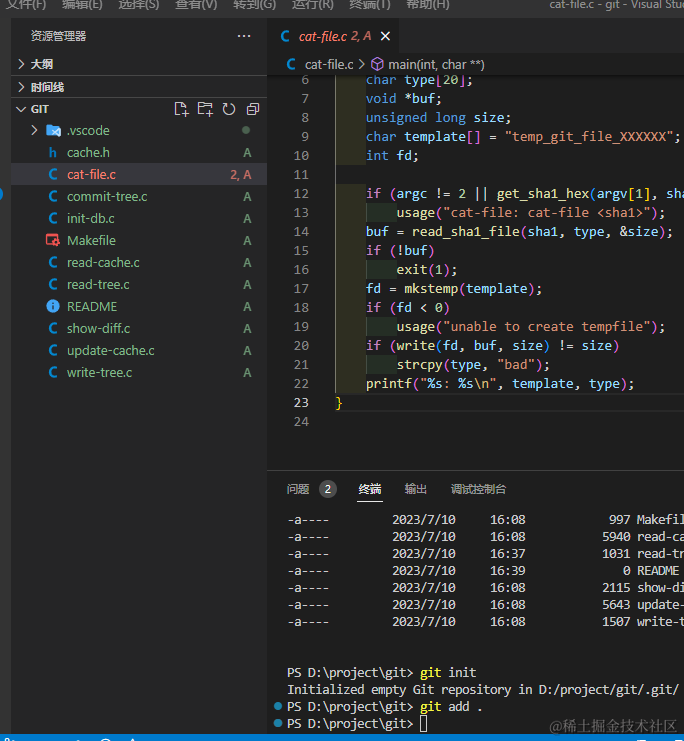
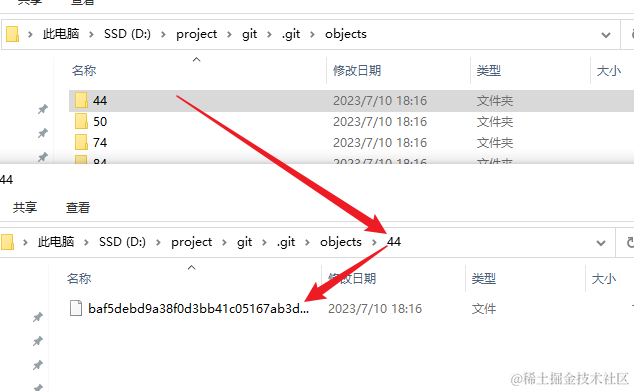
这份很明显一眼看过去就是hash值的文件名./44/baf5debd9a38f0d3bb41c05167ab3da0f9ffdf是怎么回事呢?尝试阅读一个文件,会发现都是乱码,这是因为这些都是二进制文件。

git提供了具体的查看方式。对于这个文件,我们可以得出,hash值为44ba 开头的文件,保存着blob类型的文件内容。
$ git cat-file -p 44baf5debd9a38f0d3bb41c05167ab3da0f9ffdf # 查询文件内容
...一堆内容
$ git cat-file -t 44ba #查询文件类型
blob
我们得到了我们第一个Git Objects,blob类型,保存文件内容的二进制文件块。在此基础上,我们以此类推可以得出其他被我们通过git add命令添加到暂存区的Git Objects。
按照正常使用流程,我们现在应该执行commit命令,我们尝试执行commit命令,再看看有什么变化。会发现,多了两个新文件。
我们用同样的方式查看其中一个的内容,那么我们现在接触到了第二种类型的git objects,tree类型的Git Objects保存了一个commit内的文件信息,这些文件信息包括文件权限、文件名。

现在的关系可以用下边的图表示。
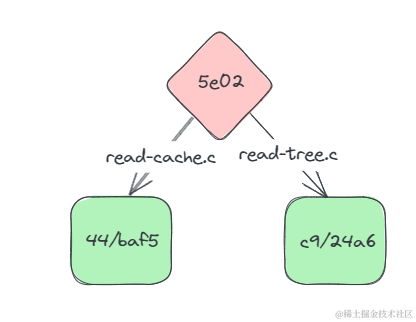
而另一个,保存着commit的信息,这是第三种Git Objects类型,包含了作者信息、commit者信息、commit内容和commit对应树的信息。
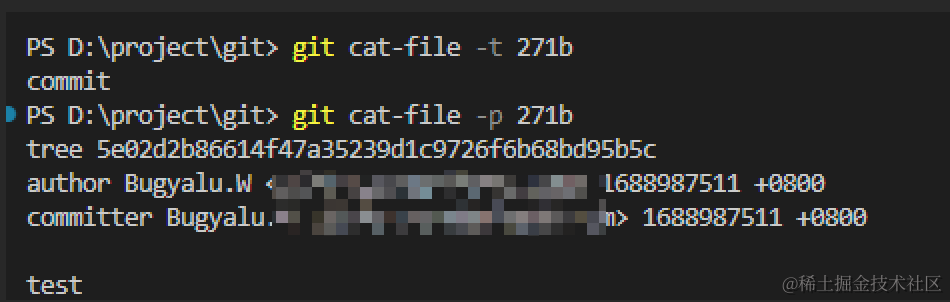
此时的关系图如下:
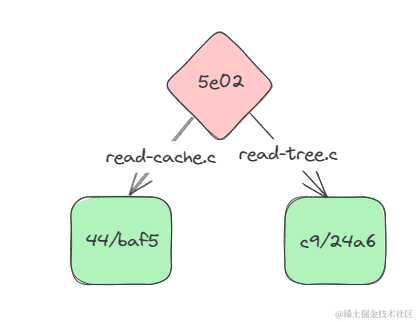
我们目前提交的文件都是根目录下文件,没有尝试过文件夹里的和文件夹里的文件夹里的(嵌套)文件。为了方便大家理解,我们尝试添加两个文件。
git add .\.vscode
git commit -m "test for dir"
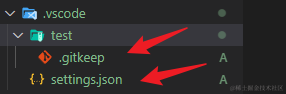
这次走完,我们观察一下生成的Git Objects。本轮commit生成了367B、20ac、30d7、4172、64c7、
$ git cat-file -p 367b
tree 20ac6ca38672867522c310d493ac2b74d65be4fa
parent 873e351820080142fc41bb090bb9a8550d2fd3eb
author Bugyalu.W <xxx> 1689058165 +0800
committer Bugyalu.W <xxx> 1689058165 +0800test for dir$ git cat-file -p 20ac
040000 tree 4172f27bc0e6b61e60129e511683b1b040f284e1 .vscode
100644 blob c924a6e0fc4c36bad6f23cb87ee59518c771f936 read-cache.c
100644 blob 44baf5debd9a38f0d3bb41c05167ab3da0f9ffdf read-tree.c$ git cat-file -t 30d7
blob
$ git cat-file -t 30d7
1$ git cat-file -t 4172
tree
$ git cat-file -p 4172
100644 blob 85c2121b25dcaa4a1ca47a24426a34857ad1644d settings.json
040000 tree 64c71c93d26b15d984ef1c805c69cd35c9c5348c test$ git cat-file -t 64c7
tree
$ git cat-file -p 64c7
100644 blob 30d74d258442c7c65512eafab474568dd706c430 .gitkeep$ git cat-file -t 873e
commit
$ git cat-file -p 873e
tree 5e02d2b86614f47a35239d1c9726f6b68bd95b5c
author Bugyalu.W <xxx> 1689058072 +0800
committer Bugyalu.W <xxx> 1689058072 +0800test
只看上边这份玩意儿实在是爆炸,所以我继续拉了一份关系图。可以发现,所有的文件夹都将作为一个tree节点,作为子树存在。

同时你会发现,我们新提交的commit,其内容中多了一个parent ,指向了上一个commit节点。
1.2 Git分区
Git的三个核心分区指的是:仓库、suoyin区、工作区三个分区。
1.2.1 仓库
仓库是哪一部分呢?
这个时候就牵扯出一个问题,首先我们知道git是支持多分支的,这意味着我们的关系图还可以继续补充,那么git是怎么处理这一块的呢?
这里就不是objects的内容了,我们来到.git根目录,可以发现其包含一个HEAD文件。
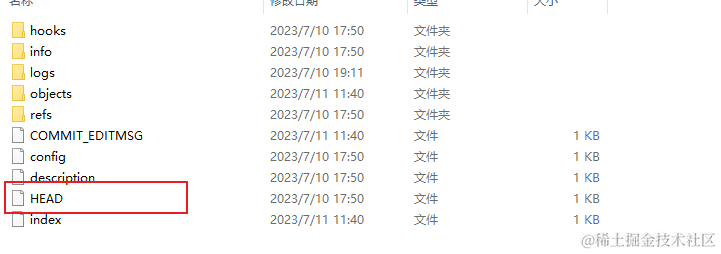
查看文件内容,很容易发现这里保存着指向当前分支的指针。

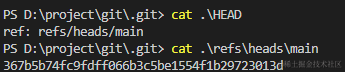
相应的,我们查看master文件,得到一串hash字符串,对比我们的关系图会知道,这个hash字符串相当于指着我们最新的commit,于是我们可以继续绘制出关系图。

为了让关系图体现得更明显,我们可以尝试建立并且切换到main分支。
git branch main
git checkout main
此时objects文件夹中文件没有变化,新增了refs/heads/main,HEAD出现变化,可以据此得出最新的关系图。
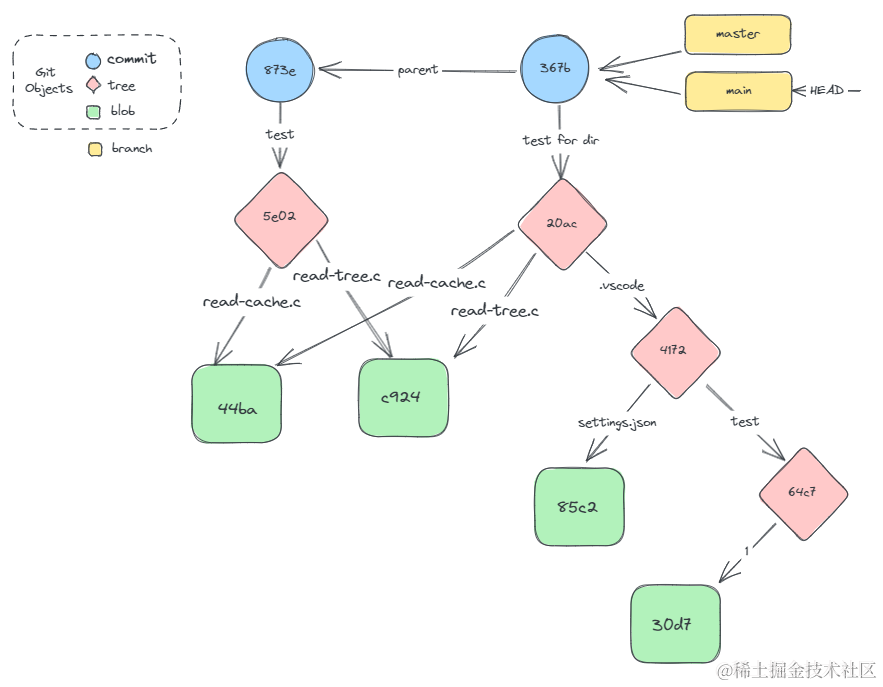
那么综上所述,我们现在知道了git是怎么存储分支、文件内容、目录结构和commit信息的啦。
1.2.2 索引区
首先,我们要知道索引区和暂存区概念的差别。
暂存区是Git用于准备提交的更改的中间区域。暂存区保证了我们对工作区中的文件进行修改后,这些更改并不会立即被提交到仓库中,你可以对这部分文件做更精细的删改后再进行commit。
而索引区,包含了暂存区,也包含了当前commit所有blob类节点的索引。
git的索引区保存在根目录的index文件,尝试查看它,发现这是一个二进制文件。
由于它不是一个Git Objects,我们不能通过cat-file命令查看,而应该使用ls-files,该命令专门用来查看index文件。
git ls-files --stage
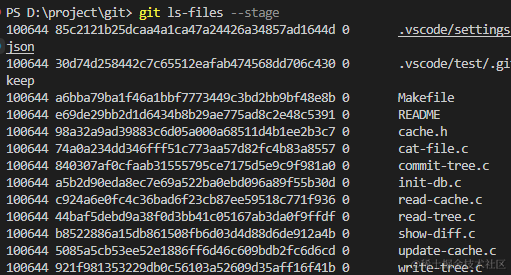
会发现,git的暂存区文件保存了所有待提交(即已经add,但是没有commit)的文件和所有已提交的文件,包含了它们的hash值和文件路径文件名。
如果我们把所有暂存的文件取消暂存,再次查看index索引文件,就会发现,此时剩下四个文件,这四个文件正是我们上一张关系图中四个blob型git objects。
$ git ls-files --stage
100644 85c2121b25dcaa4a1ca47a24426a34857ad1644d 0 .vscode/settings.json
100644 30d74d258442c7c65512eafab474568dd706c430 0 .vscode/test/.gitkeep
100644 c924a6e0fc4c36bad6f23cb87ee59518c771f936 0 read-cache.c
100644 44baf5debd9a38f0d3bb41c05167ab3da0f9ffdf 0 read-tree.c
也就是说,index文件相当于一个待形成的新commit节点,里边包含了一个commit类型Git Object的部分信息,但不同的是,这里保存的是纯blob节点,并没有tree节点。我们由此另外绘制一份关系图。
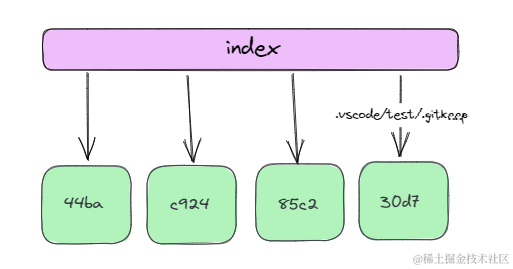
我们尝试修改30d7,也就是目前的.gitkeep文件,并将它添加到暂存区。此时观察index变化。会发现,此时index中原本的.gitkeep文件,指向的blob节点更新了,从30d7改向了e2e1。此时的关系图如下,相当于原本指向30d7的指针现在指向了e2e1.
$ git ls-files --stage
100644 85c2121b25dcaa4a1ca47a24426a34857ad1644d 0 .vscode/settings.json
100644 e2e107ac61ac259b87c544f6e7a4eb03422c6c21 0 .vscode/test/.gitkeep
100644 c924a6e0fc4c36bad6f23cb87ee59518c771f936 0 read-cache.c
100644 44baf5debd9a38f0d3bb41c05167ab3da0f9ffdf 0 read-tree.c
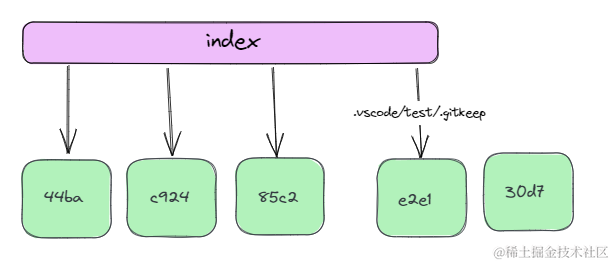
如果我们再执行commit,此时检查index没有变化,但是我们的关系图现在呈现成下图。
git commit -m "change .gitkeep"
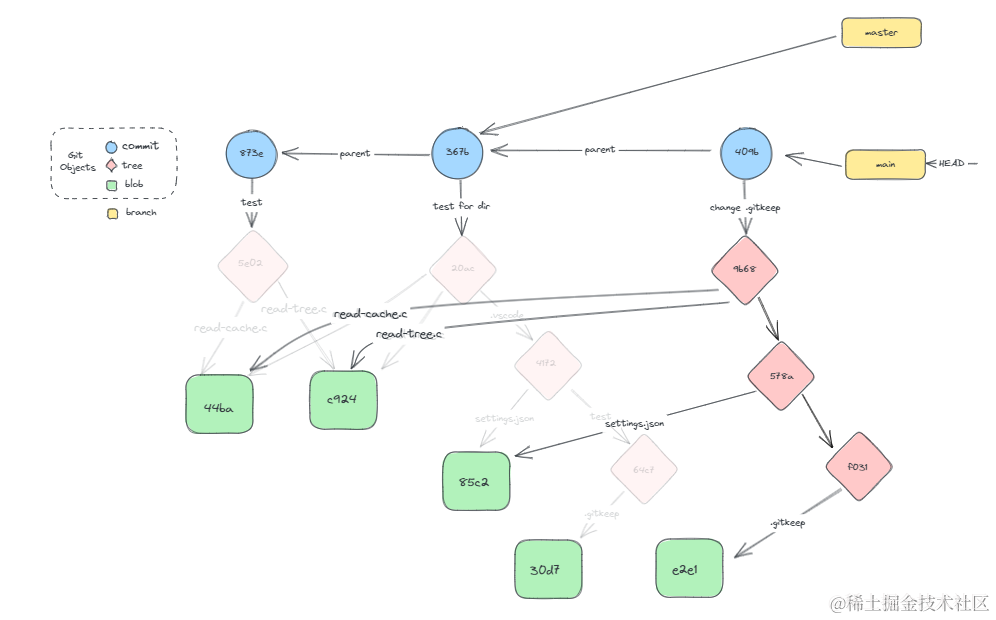
我们发现和上次commit有这些不同:
- Git根据当前索引index,新生成了一个commit节点。
- HEAD指向的当前分支指针变化,指向了新生成的commit节点。
- 凡是涉及到.gitkeep文件的tree节点的hash都发生了变化。
1.2.3 工作区
最后一个概念是工作区,工作区指的是在我们电脑上的文件本身,这个概念在git中是最薄弱的,因为我们对工作区的操作其实就是我们日常工作中对文件的操作,在我们真正执行git命令之前,这部分工作区的内容不会在git仓库和索引区中体现。
1.3 数据完整性与包文件压缩
在上边的一系列原理中,我们有提到一嘴git仓库中有很多哈希文件,这涉及到git另一个知识点。
诸位有没有想象过,如果真的用一个仓库完整保存一个项目从零到一的所有文件,那这份仓库会有多大,会有多大?
所以显然,一定要采取一些压缩机制。
上文中出现的哈希值,都是来源于Git对于SHA-1哈希算法的应用,Git在生成不同的Git Object时,都会有其哈希值的计算的过程,hash值将作为Git Object节点的唯一标识。这些节点互相关联,从关系图中很容易看出这是一根哈希树。
根据这些哈希值,一方面可以在objects文件夹中找到不同的Git Object,而其中的blob类型object,即保存着文件的实际内容,另一方面,通过SHA1哈希算法和哈希树的机制保证了历史记录不可篡改,因为当你修改了某个节点,那么与之相关的tree节点、commit节点再到commit节点之后所有的节点的hash值都应该变化,很容易发现问题。
这些object节点,通过zlib算法对对象内容进行压缩,通过hash值比较的方式来确保重复内容只存贮一次,减少存储占用。而在使用时,又可以通过解压算法还原出原本的内容。
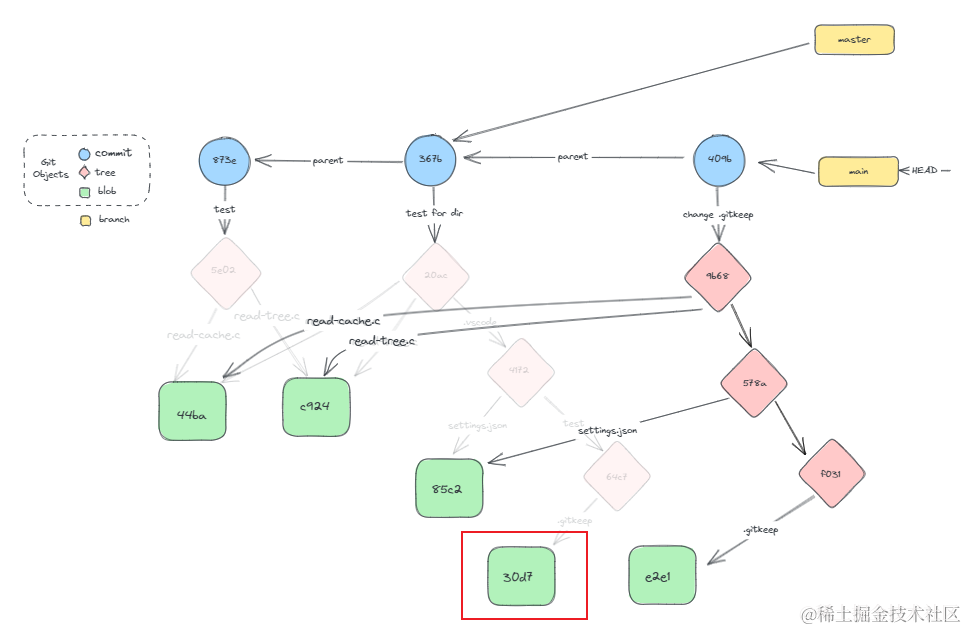
除却这些操作外,git还引入了进一步压缩的方式。看到上边的关系图,我们会发现在当前commit中,出现了一个blob节点不在树上的情况。
长此以往,这里就出现了优化空间,因为部分blob节点可能很长时间内不再使用,属于冷数据。那么git就对此做了优化,git会定期把松散对象文件打包成包文件(packfile),进一步减少文件碎片。根据对象存储方式,可分为loose object和packed object。loose object 是单独文件的松散对象,packed object 则是存在于包文件中的压缩对象。Git会在两种对象间转换,以优化仓库存储。
2 Gitflow流程与模式
2.1 Git flow
首先,来看一下标准的git flow演示图。
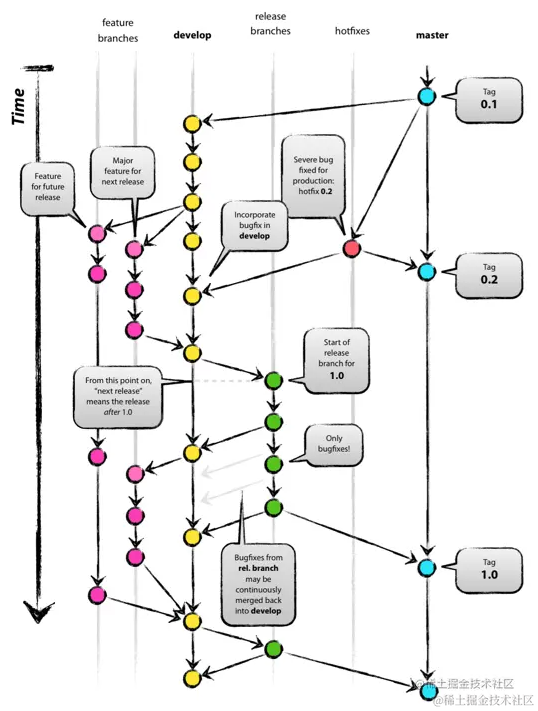
图片来源:《字节研发设施下的 Git 工作流》
这一串复杂的流程,就是最经典的gitflow工作流,Git flow。
在这个流程中,Git flow制定了非常严格的分支管理规则,分支被区分为:
- master(主分支):用于发布新版本,在这里打tag作为版本。
- develop(开发分支):用于集成各种功能分支,是一个较稳定的开发进度分支。
- feature(特性分支):feature分支的源分支是develop分支,所有新功能开发都通过专门的特征分支(feature branch)来开发,开发完成后合并回develop分支。feature分支是多分支,命名上参考”feature/xxx“,在合并后删除本分支。
- hotfix(紧急修复分支):线上代码出现严重Bug需要紧急修复时使用该分支。hotfix分支起源于master分支(也就是线上代码),开发完成后合并至master分支同时合并到develop分支以确保下一个版本的代码也包含这个hotfix补丁。hotfix分支是多分支,命名上参考”hotfix/xxx“,在合并后删除本分支。
- bugfix(问题修复分支):专门用于修复开发环境的bug,源分支是develop分支,最终也合并到develop分支。bugfix分支是多分支,命名上参考”bugfix/xxx“,在合并后删除本分支。
- release(发布分支):当develop分支代码测试完毕,准备发布时,将从develop分支发起release分支,进入release阶段的代码将不允许新特性的添加(也就是不允许feature分支合并入develop分支或者release分支)。release分支将进行最终最严格的测试。release分支接受为了修复bug而产生的提交。release分支持续变动,直至开发工作验收通过,这时release分支将会打上版本tag合并至master分支同时合并至devlop分支以确保develop分支是master分支的直接后继。release分支是多分支,命名上参考”release/xxx“,在合并后不一定需要删除本分支。
Git flow的优势和劣势是非常明显的,其优点:
- 分支各司其职,能覆盖大部分开发场景。
- 预期master分支中的任何commit都可部署,在出现事故时对于回滚非常友好。
- 严格按照流程执行,出现重大事故的情形会大大降低。
其劣势同样很大:
- 过于繁琐,无法要求所有团队成员按照这个流程严格执行。
- 对持续部署和敏捷开发并不友好。
2.2 Github Flow
Github Flow一种相对更轻量的工作流。其核心概念是Pull Request(简称PR),需要注意的是,PR并非git提供的能力而是Github提供的能力,其强调多仓库、强CR。
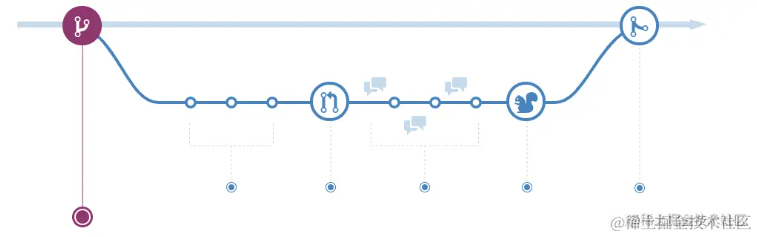
图片来源:《字节研发设施下的 Git 工作流》
一般来讲,Github Flow工作流只有一个主分支(Master)是固定的,且受保护的,只有特定权限的人才可以向master分支合入代码。
在Github Flow中,我们一般来讲需要fork源仓库,在新仓库(注意,Github同样支持本仓库内分支和分支之间的PR)中进行代码提交(一般提交到主分支),当所有的功能开发完毕,则通过PR提交一份描述信息和代码,通知源仓库开发者进行CR,确认无误后,将由源仓库开发者将代码合入主分支。
Github Flow 优点是相对于 GitFlow 来说比较简单,同时由于每次PR都会同步提交描述信息,可以获取更多节点信息,其缺点是因为只有一条 Master 分支,万一代码合入后,由于某些因素 Master 分支不能立刻发布,就会导致最终发布的版本和计划不同。
2.3 Gitlab Flow
Gitlab Flow 是 Git Flow 与 Github Flow 的结合。它吸取了两者的优点,既有适应不同开发环境的弹性,又有单一分支的简单和便利。
我们在Github Flow中提到了PR,而在Gitlab仓库中,有个类似的操作,叫Merge Request(MR)——这两者其实没什么区别,引用某阿里大佬的解释:
- 在 Github 上也可以玩分支模式,提交合并请求同样用 Pull Request。
- 在 Gitlab 上也可以玩 fork 模式,提交合并请求还是 Merge Request。
同时,相比Github flow,GitLabFlow 增加了对预生产环境和生产环境的管理,即 Master 分支对应为开发环境的分支,预生产和生产环境由其他分支(如 Pre-Production、Production)进行管理。
在这种情况下,Master 分支是 Pre-Production 分支的上游,Pre-Production 是 Production 分支的上游。
GitlabFlow 规定代码必须从上游向下游发展:
- 即新功能或修复 Bug 时,特性分支的代码测试无误后,必须先合入 Master 分支
- 然后才能由 Master 分支向 Pre-Production 环境合入
- 最后由 Pre-Production 合入到 Production。