原创文章第565篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
我们的研报得现工作,用了两篇文章讲数据准备:
【研报复现】年化16.19%,人工智能多因子大类资产配置策略
【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
今天我们来整理因子集。
研报里没有给出因子细节,我的解读是“根本不重要”。
因此,我就用qlib的Alpha158,结合部分WorldQuant101,还有常用的Ta-lib的技术分析指标来构建因子集。
我把函数集统一了命名,补充了一些函数:Alpha158可以正常工作了:
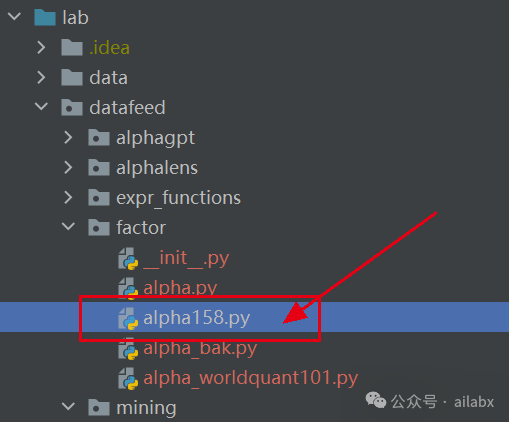
from datafeed.factor.alpha import AlphaBaseclass Alpha158(AlphaBase):def get_fields_names(self):# ['CORD30', 'STD30', 'CORR5', 'RESI10', 'CORD60', 'STD5', 'LOW0',# 'WVMA30', 'RESI5', 'ROC5', 'KSFT', 'STD20', 'RSV5', 'STD60', 'KLEN']fields = []names = []# kbarfields += ["(close-open)/open","(high-low)/open","(close-open)/(high-low+1e-12)","(high-greater(open, close))/open","(high-greater(open, close))/(high-low+1e-12)","(less(open, close)-low)/open","(less(open, close)-low)/(high-low+1e-12)","(2*close-high-low)/open","(2*close-high-low)/(high-low+1e-12)",]names += ["KMID","KLEN","KMID2","KUP","KUP2","KLOW","KLOW2","KSFT","KSFT2",]# =========== price ==========feature = ["OPEN", "HIGH", "LOW", "CLOSE"]windows = range(5)for field in feature:field = field.lower()fields += ["shift(%s, %d)/close" % (field, d) if d != 0 else "%s/close" % field for d in windows]names += [field.upper() + str(d) for d in windows]# ================ volume ===========fields += ["shift(volume, %d)/(volume+1e-12)" % d if d != 0 else "volume/(volume+1e-12)" for d in windows]names += ["VOLUME" + str(d) for d in windows]# ================= rolling ====================windows = [5, 10, 20, 30, 60]fields += ["shift(close, %d)/close" % d for d in windows]names += ["ROC%d" % d for d in windows]fields += ["mean(close, %d)/close" % d for d in windows]names += ["MA%d" % d for d in windows]fields += ["std(close, %d)/close" % d for d in windows]names += ["STD%d" % d for d in windows]#fields += ["slope(close, %d)/close" % d for d in windows]#names += ["BETA%d" % d for d in windows]fields += ["ts_max(high, %d)/close" % d for d in windows]names += ["MAX%d" % d for d in windows]fields += ["ts_min(low, %d)/close" % d for d in windows]names += ["MIN%d" % d for d in windows]fields += ["quantile(close, %d, 0.8)/close" % d for d in windows]names += ["QTLU%d" % d for d in windows]fields += ["quantile(close, %d, 0.2)/close" % d for d in windows]names += ["QTLD%d" % d for d in windows]#fields += ["ts_rank(close, %d)" % d for d in windows]#names += ["RANK%d" % d for d in windows]fields += ["(close-ts_min(low, %d))/(ts_max(high, %d)-ts_min(low, %d)+1e-12)" % (d, d, d) for d in windows]names += ["RSV%d" % d for d in windows]fields += ["ts_argmax(high, %d)/%d" % (d, d) for d in windows]names += ["IMAX%d" % d for d in windows]fields += ["ts_argmin(low, %d)/%d" % (d, d) for d in windows]names += ["IMIN%d" % d for d in windows]fields += ["(ts_argmax(high, %d)-ts_argmin(low, %d))/%d" % (d, d, d) for d in windows]names += ["IMXD%d" % d for d in windows]fields += ["correlation(close, log(volume+1), %d)" % d for d in windows]names += ["CORR%d" % d for d in windows]fields += ["correlation(close/shift(close,1), log(volume/shift(volume, 1)+1), %d)" % d for d in windows]names += ["CORD%d" % d for d in windows]fields += ["mean(close>shift(close, 1), %d)" % d for d in windows]names += ["CNTP%d" % d for d in windows]fields += ["mean(close<shift(close, 1), %d)" % d for d in windows]names += ["CNTN%d" % d for d in windows]fields += ["mean(close>shift(close, 1), %d)-mean(close<shift(close, 1), %d)" % (d, d) for d in windows]names += ["CNTD%d" % d for d in windows]fields += ["sum(greater(close-shift(close, 1), 0), %d)/(sum(abs(close-shift(close, 1)), %d)+1e-12)" % (d, d)for d in windows]names += ["SUMP%d" % d for d in windows]fields += ["sum(greater(shift(close, 1)-close, 0), %d)/(sum(abs(close-shift(close, 1)), %d)+1e-12)" % (d, d)for d in windows]names += ["SUMN%d" % d for d in windows]fields += ["(sum(greater(close-shift(close, 1), 0), %d)-sum(greater(shift(close, 1)-close, 0), %d))""/(sum(abs(close-shift(close, 1)), %d)+1e-12)" % (d, d, d)for d in windows]names += ["SUMD%d" % d for d in windows]fields += ["mean(volume, %d)/(volume+1e-12)" % d for d in windows]names += ["VMA%d" % d for d in windows]fields += ["std(volume, %d)/(volume+1e-12)" % d for d in windows]names += ["VSTD%d" % d for d in windows]fields += ["std(abs(close/shift(close, 1)-1)*volume, %d)/(mean(abs(close/shift(close, 1)-1)*volume, %d)+1e-12)"% (d, d)for d in windows]names += ["WVMA%d" % d for d in windows]fields += ["sum(greater(volume-shift(volume, 1), 0), %d)/(sum(abs(volume-shift(volume, 1)), %d)+1e-12)"% (d, d)for d in windows]names += ["VSUMP%d" % d for d in windows]fields += ["sum(greater(shift(volume, 1)-volume, 0), %d)/(sum(abs(volume-shift(volume, 1)), %d)+1e-12)"% (d, d)for d in windows]names += ["VSUMN%d" % d for d in windows]fields += ["(sum(greater(volume-shift(volume, 1), 0), %d)-sum(greater(shift(volume, 1)-volume, 0), %d))""/(sum(abs(volume-shift(volume, 1)), %d)+1e-12)" % (d, d, d)for d in windows]names += ["VSUMD%d" % d for d in windows]return fields, names
计算出来Qlib的159个因子,
其实因子就是原始数据的数学变形。
在线性模型里还需要分析“多重共线性”的问题,但在机器学习里,反正就是一股脑进去,树模型还能把重要的特征筛选出来。
接下来就是数据集做一个量纲的统一,预处理之类的。
Qlib里有类似的预处理函数:

def __call__(self, df):
def normalize(x, min_val=self.min_val, max_val=self.max_val):
return (x - min_val) / (max_val - min_val)
这里的预处理需要格外小心,不能引入未来函数。
本质是是做归一化,避免量纲不同,模型训练失真。
研报结论是CSMinMax效果最好,所谓CSMinMax就是在截面(时间,即calc_by_date),也就是每天对因子数据进行MinMax的归一化。——这一点上符合逻辑,从机器学习的角度,每天的数据是一个样本,而样本进行minmax,相对大小没有发生改变,只是“归一化”到0-1之间,更符合特定分布。
def cs_minmax(se: pd.Series):return (se - se.min()) / (se.max() - se.min())
后续可以引入lightGBM机器学习模型,进行训练和策略开发。
有同学在问的优惠券:
阅读
《特斯拉传-万物皆我》,这本书读完了。
与其说读完了,不如说翻完了。
这本书确实写得一般,不同于传统传记,他的写作,更像是要与特斯拉融入一体,那种半梦半醒,活在自我构建的世界,那种感觉。
一个不为名,不为钱的怪才,狂热的科学实验爱好者。
注定是孤独的。
普通人无法成为特斯拉、图灵,我想也不愿意身边的人,成为他们。
但我们有可能“成为”爱迪生。——实用主义,解决问题,有美满的家庭,儿女成群,世人拥戴。
我想,只是欲望不过度,不伤害其他人,一定的财富与名利是好的。
本周要的书,估计是《点亮黑夜——爱迪生传》。
由于有这一次教训,我特意在电子书平台看了半章,确保内容不会再出现这样的问题。
“FIRE与退休”
之前聊过比较多“FIRE——财务自由,提前退休”的方式,也聊过“500,10%”的财务自由逻辑。
现在把这种方式,归入ABCZ的Z计划。
因为所谓退休,是一种心态。
即你不为设想中的明天而放弃今天的生活,就是退休的状态。
比如,你能很大程度上享受当下在做的事情,或者工作,就是一个退休之状态。
历史文章:
【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
AI量化实验室——2024量化投资的星辰大海