1,融合pose.pt(姿态检测)+(安全帽佩戴检测)效果图
实时检测优化后FPS可达20+

2,原理介绍
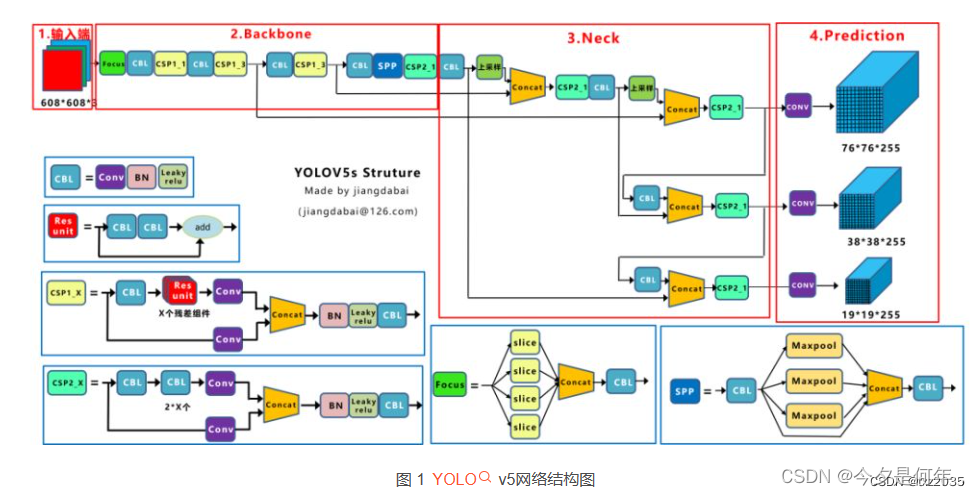
YOLOv5是目前应用广泛的目标检测算法之一,其主要结构分为两个部分:骨干网络和检测头。
输入(Input): YOLOv5的输入是一张RGB图像,它可以具有不同的分辨率,但通常为416x416或512x512像素。这些图像被预处理和缩放为神经网络的输入大小。在训练过程中,可以使用数据增强技术对图像进行随机裁剪、缩放和翻转等操作,以增加数据的丰富性和多样性。
Backbone(主干网络): 主干网络负责提取图像的特征表示,它是整个目标检测算法的核心组件。YOLOv5采用了CSPDarknet作为主干网络。CSPDarknet基于Darknet53并进行了改进。它使用了一种被称为CSP(Cross Stage Partial)的结构,将特征映射划分为两个部分,其中一个部分通过一系列卷积和残差连接进行特征提取,另一个部分则直接传递未经处理的特征,从而提高了特征的表达能力和信息传递效率。
Neck(特征融合模块): Neck模块用于融合来自不同层级的特征图,以获取丰富的语义信息和多尺度感受野。