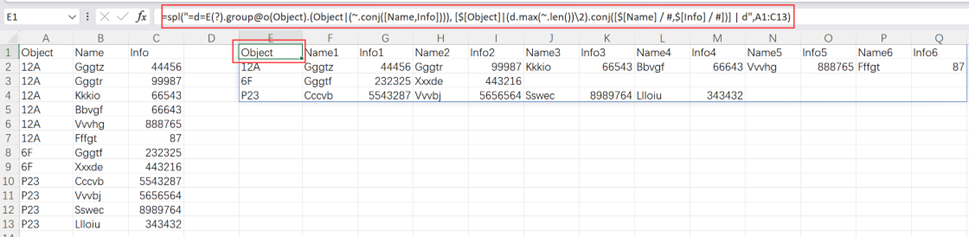
由于 Transformer 模型中自注意力模块具有置换不变性,因此仅使用注意力机制无法捕捉序列中的顺序关系,从而退化为“词袋模型”。为了解决这一问题,需要引入位置编码(Position Embedding, PE)对于序列信息进行精确建模,从而将绝对或相对位置信息整合到模型中。
什么是位置编码?
Transformer 位置编码描述了一个实体在序列中的位置,它为每个位置分配一个独特的表示。在 Transformer 模型中,有很多原因导致我们不使用单个数字(例如索引值)来表示项目的位置。
- 对于长序列,索引值可能会变得非常大。
- 如果将索引值归一化到 0 到 1 之间,则可能会对不同长度的序列造成问题,因为它们的归一化方式不同。
Transformer 使用一种巧妙的位置编码方案,其中每个位置/索引都被映射到一个向量。因此,位置编码层的输出是一个矩阵,其中矩阵的每一行表示一个编码后的对象,该对象与其位置信息相加。下图展示了一个仅对位置信息进行编码的矩阵示例。
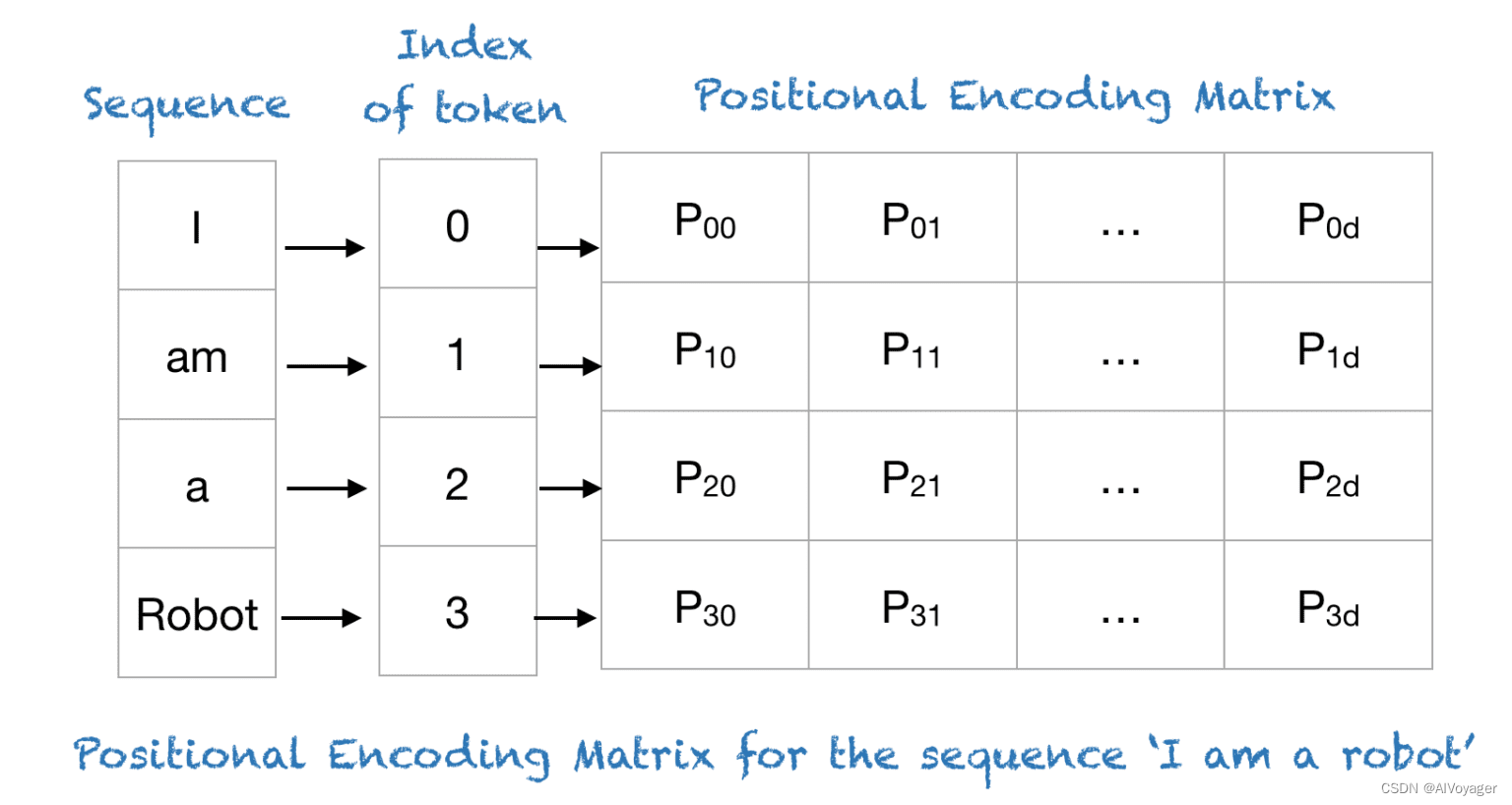
总而言之,位置编码为序列中的每个位置提供了一个独特的向量表示,从而解决了使用简单索引值所面临的挑战。
下表显示了“I am a robot的位置编码矩阵。事实上,对于n=100和d=4的任何四个字母的短语,位置编码矩阵都是相同的。

简单的代码实现
import numpy as np
import matplotlib.pyplot as pltdef getPositionEncoding(seq_len, d, n=10000):P = np.zeros((seq_len, d))for k in range(seq_len):for i in np.arange(int(d/2)):denominator = np.power(n, 2*i/d)P[k, 2*i] = np.sin(k/denominator)P[k, 2*i+1] = np.cos(k/denominator)return PP = getPositionEncoding(seq_len=4, d=4, n=100)
print(P)
输出:
[[ 0. 1. 0. 1. ][ 0.84147098 0.54030231 0.09983342 0.99500417][ 0.90929743 -0.41614684 0.19866933 0.98006658][ 0.14112001 -0.9899925 0.29552021 0.95533649]]
def plotSinusoid(k, d=512, n=10000):