在建立易学知识库的过程中,仅仅有向量数据库以及词嵌入模型、分词器是不够的,因为我们有大量的非结构化文本(如doc,pdf)或者是图片需要上传(例如pdf里面有图片),此时词嵌入无法直接向向量数据库中嵌入图片,需要对图片内文字进行识别,转换为文本后才能继续嵌入。
1. 一切的基础:langchain.document_loaders
langchain为我们提供了一个基类:Unstructured File | 🦜️🔗 LangChain
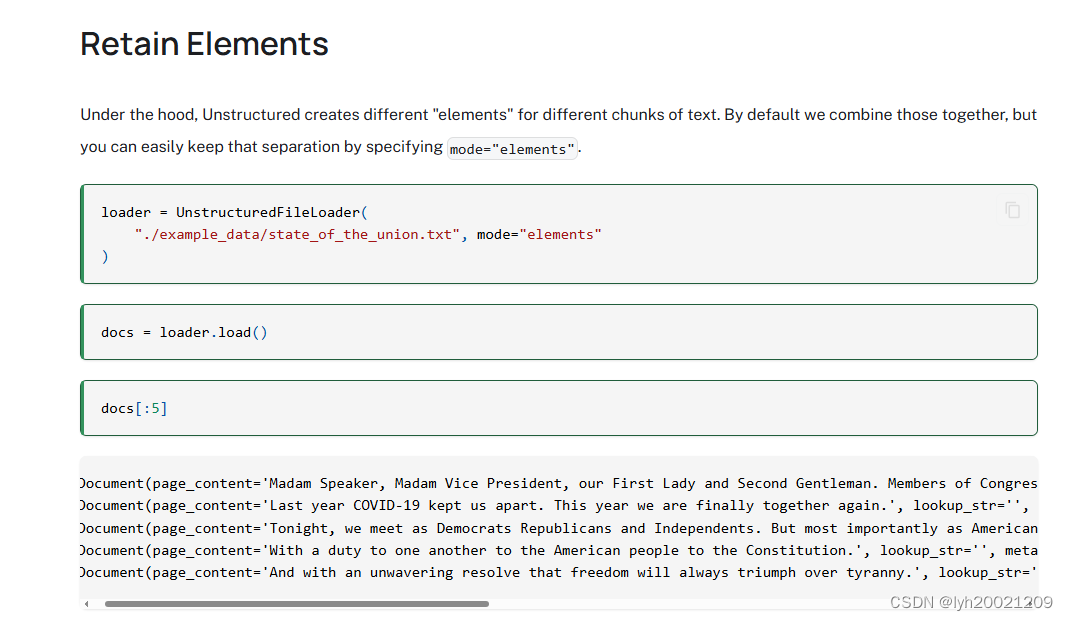
from langchain.document_loaders.unstructured import UnstructuredFileLoader即这个UnstructuredFileLoader,LangChain官方对其介绍是:
This notebook covers how to use
Unstructuredpackage to load files of many types.Unstructuredcurrently supports loading of text files, powerpoints, html, pdfs, images, and more.
这个类专门用来加载文本、ppt、html、pdf、图片等文件。并且提供了一系列划分文本chunk分块分片的策略。
2. 对pdf的加载
不过我们的任务可能会更复杂一点,因为我们有一些易学书籍是图片形式的(保存在pdf中),因此先需要进行ocr识别,然后再作为文本加载。

这里我注意到这些图片可能都是人为拍摄的(因为图片有些略有倾斜,不是规整的),因此就需要制定一套解决方案:
- 先读取pdf中的每一页(这里使用了pyMuPDF里的fitz包)GitHub - pymupdf/PyMuPDF: PyMuPDF is a high performance Python library for data extraction, analysis, conversion & manipulation of PDF (and other) documents.PyMuPDF is a high performance Python library for data extraction, analysis, conversion & manipulation of PDF (and other) documents. - pymupdf/PyMuPDF
 https://github.com/pymupdf/PyMuPDF.git
https://github.com/pymupdf/PyMuPDF.git - 对于文本我们可以直接加载
- 对于图片
- 先把图片转正
- 然后利用ocr识别图片
- 将识别结果加载到内存,并嵌入转储到向量数据库
2.1. OCR识别实例
这一块我用了一个开源库:PaddleOCR
PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices) (github.com)![]() https://github.com/PaddlePaddle/PaddleOCR可以通过:
https://github.com/PaddlePaddle/PaddleOCR可以通过:
pip install rapidocr_paddle
进行下载安装。
或者onnx格式的
pip install rapidocr_onnxruntime
随后即可通过RapidOCR()进行实例初始化并返回该对象。
2.2. 图像旋转
图像文本分离
首先我们要把图像和文本分离开来,因为文本可以直接加载,不需要ocr识别:
for i, page in enumerate(doc):b_unit.set_description("RapidOCRPDFLoader context page index: {}".format(i))b_unit.refresh()text = page.get_text("")resp += text + "\n"img_list = page.get_image_info(xrefs=True)for img in img_list:这里b_unit是tqdm这个进度条库的组件,用来显示pdf文件的文本加载到哪一页了。
b_unit = tqdm.tqdm(total=doc.page_count, desc="RapidOCRPDFLoader context page index: 0")效果类似于下面的:

图像尺寸检查
在处理图像的过程中,可能会因为一些小图像影响处理效率,因为小图像中包含的信息可能在视觉效果上很模糊,导致ocr难以识别出文字。因此我们要筛选掉那些过小的图像:
if xref := img.get("xref"):bbox = img["bbox"]# 检查图片尺寸是否超过设定的阈值if ((bbox[2] - bbox[0]) / (page.rect.width) < PDF_OCR_THRESHOLD[0]or (bbox[3] - bbox[1]) / (page.rect.height) < PDF_OCR_THRESHOLD[1]):continue这里我们通过图像的包围盒(bounding box)与整个页面的长宽的比值判断这个图片是否“过小"。其中:
bbox = [ x0,y0,x1,y1 ]
即图像矩形边界框的坐标。这里如果长宽比值过小,我们就跳过这个图像,继续处理图像列表中的下一个。
获取图像像素矩阵以及图像对象
剩下的图像就都是当前页面中比较容易识别文字的图像了。不过正如我在上面提到过的,这些图片可能因为人为拍摄时的角度问题,不够”正“。为了让他们够正,我们要对图像的像素矩阵进行旋转。(注意是对像素进行旋转,包围盒是正的,里面的图像像素可能是歪的)第一步就是要先获取像素矩阵。
pix = fitz.Pixmap(doc, xref)- 从打开的PDF文档(
doc)中,使用给定的交叉引用(xref)来定位页面或页面的一部分。 - 创建一个
Pixmap对象,它包含了定位到的页面区域的图像数据。
Pixmap 对象可以用于各种操作,比如图像处理、提取文本、转换格式等。例如,你可以对 pix 对象调用方法来获取图像的宽度、高度、像素数据,旋转角度等。
然后我们从Pixmap中获取这个图像的像素矩阵(先用numpy库获取所有像素采样点,然后把buffer重塑为原始图像宽高的像素矩阵):
if int(page.rotation)!=0: #如果Page有旋转角度,则旋转图片img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.height, pix.width, -1)随后我们利用Python Image Library(PIL)库,把这个矩阵转换为一个python图像(可能会疑惑怎么获取了像素矩阵还要转为Python图像,因为Pixmap那个里面的sample点不能直接用来做ocr识别,他接收的就是ndArray,然后ocr接收的是BGR三通道的图像,但我们获取的像素矩阵是RGB的,所以还得用PIL和OpenCV库转一下三通道背景,然后才能传到ocr函数里面去):
tmp_img = Image.fromarray(img_array)
ori_img = cv2.cvtColor(np.array(tmp_img),cv2.COLOR_RGB2BGR)图像旋转
接下来就是比较重要的一环,旋转图像:
def rotate_img(img, angle):h, w = img.shape[:2]rotate_center = (w/2, h/2)#获取旋转矩阵# 参数1为旋转中心点;# 参数2为旋转角度,正值-逆时针旋转;负值-顺时针旋转# 参数3为各向同性的比例因子,1.0原图,2.0变成原来的2倍,0.5变成原来的0.5倍M = cv2.getRotationMatrix2D(rotate_center, angle, 1.0)#计算图像新边界new_w = int(h * np.abs(M[0, 1]) + w * np.abs(M[0, 0]))new_h = int(h * np.abs(M[0, 0]) + w * np.abs(M[0, 1]))#调整旋转矩阵以考虑平移M[0, 2] += (new_w - w) / 2M[1, 2] += (new_h - h) / 2rotated_img = cv2.warpAffine(img, M, (new_w, new_h))return rotated_img首先我们先获取图像对象的宽和高,然后宽高中间的位置就是旋转中心(还是再强调一遍,图像本身不是歪的,是图像内容歪了!我们要旋转的是图像的像素点!)
OpenCV提供了一个矩阵旋转的函数,getRotationMatrix2D,第一个参数接收旋转中心,第二个参数接收旋转角度,第三个参数接收scale缩放因子,这里我们不缩放。
随后我们要用到计算机图形学/线性代数中的仿射变换:
首先,我们先来推导一下旋转矩阵:假设二维向量(x,y)绕原点逆时针旋转了角度,求旋转后的二维向量。
我们可以利用极坐标法来求解这个问题:
设:
同时,向量(x,y)与x正半轴的夹角为。则
则旋转后的坐标
根据三角函数的和差公式:
结合上述(1) (2) (3) (4)式可得:
整理为仿射矩阵可得:
其中:
M是仿射变换矩阵。是旋转角度。
和
是旋转后的图像中心点在原始图像中的平移量。
则将M作用于任意一个像素点(x,y,1)得到(x',y'):(注意这里是齐次坐标)
同样,我们可以将原先的(width,height)视作(x,y)元组,计算旋转后图像的新边界。
#计算图像新边界
new_w = int(h * np.abs(M[0, 1]) + w * np.abs(M[0, 0]))
new_h = int(h * np.abs(M[0, 0]) + w * np.abs(M[0, 1]))随后将旋转得到的图像像素平移至包围盒中心。
#调整旋转矩阵以考虑平移
M[0, 2] += (new_w - w) / 2
M[1, 2] += (new_h - h) / 2最后我们通过OpenCV提供的仿射变换函数,将该矩阵作用到图像上:
rotated_img = cv2.warpAffine(img, M, (new_w, new_h))至此,图像旋转完毕。
在具体使用这个rotate_img时,传入的旋转角为:
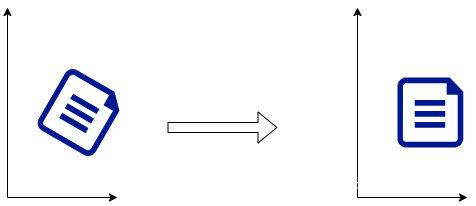
例如,一开始这个图像顺时针旋转了45°,那么我们转360-45相当于让他转了一圈,再往回倒45°,就转正了。
rot_img = rotate_img(img=ori_img, angle=360-page.rotation)2.3. 案例
这里可以看一个例子,展示一下ocr识别的效果。(这里我就不用那个易学书籍的例子了,因为之前跑的时候没截图,跑一次要很久很久,一本书200页)

识别效果如下:

可以看到都是可以识别出来的。而且结果也很精准(只要图片不是太糊)。