中风是危害人们健康的重大疾病之一,根据医学杂志《柳叶刀》发表的一篇文章中的数据,中风在我国居民死亡原因中高居第一位,而且我国居民的中风的比例也是世界上最高的之一。因此,了解居民的身体状况与出现中风的联系,进而分析中风的成因,实现对不同的人群,有针对性的采取预防的措施,是有积极的意义的。
附件1中随机搜集了5000多个人的数据,请你根据附件1中的信息,作以下分析:
- 数据中列举的各因素中,哪些对中风的影响较大?给出你的排序,并分析各因素的不同取值与中风发病率的关系。
- 利用这些数据,寻找出几个最容易出现中风的小的群体,(一般人数不超过总人数的5%), 分析这些群体的个体特征。
- 建立数学模型,对不同的人分析其中风的可能性大小。并利用你的模型对附件2中的10个人按中风可能性大小排序。
from google.colab import drive
drive.mount('/content/drive')Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
%cd /content/drive/My Drive
!pwd/content/drive/My Drive /content/drive/My Drive
import matplotlib.font_manager as mfm
font_path="/content/drive/My Drive/Colab Notebooks/simhei.ttf"
prop=mfm.FontProperties(fname=font_path)%cd ./Colab Notebooks/XXXXX
!pwd/content/drive/My Drive/Colab Notebooks/XXXXX /content/drive/My Drive/Colab Notebooks/XXXXX
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsimport warnings
warnings.filterwarnings("ignore")data=pd.read_csv('附件1.csv')#读取
excel2=pd.read_excel('附件2.xlsx')backup=data.copy()#备份
excel1=data
print('查看病例数据的大小:',excel1.shape)
length_excel1=excel1.shape[0]查看病例数据的大小: (5110, 12)
print('查看病例数据的变量信息:')#观察有多少缺少值
print(excel1.info())查看病例数据的变量信息: <class 'pandas.core.frame.DataFrame'> RangeIndex: 5110 entries, 0 to 5109 Data columns (total 12 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 5110 non-null int64 1 gender 5110 non-null object 2 age 5110 non-null float643 hypertension 5110 non-null int64 4 heart_disease 5110 non-null int64 5 ever_married 5110 non-null object 6 work_type 5110 non-null object 7 Residence_type 5110 non-null object 8 avg_glucose_level 5110 non-null float649 bmi 4909 non-null float6410 smoking_status 5110 non-null object 11 stroke 5110 non-null int64 dtypes: float64(3), int64(4), object(5) memory usage: 479.2+ KB None
print("每个病例数据的内容分布")#观察每项数据有多少个
print(excel1['gender'].value_counts(),'\n\n')
print(excel1['age'].value_counts(),'\n\n')
print(excel1['hypertension'].value_counts(),'\n\n')
print(excel1['heart_disease'].value_counts(),'\n\n')
print(excel1['ever_married'].value_counts(),'\n\n')
print(excel1['work_type'].value_counts(),'\n\n')
print(excel1['Residence_type'].value_counts(),'\n\n')
print(excel1['avg_glucose_level'].value_counts(),'\n\n')
print(excel1['bmi'].value_counts(),'\n\n')
print(excel1['smoking_status'].value_counts(),'\n\n')
print(excel1['stroke'].value_counts())每个病例数据的内容分布 Female 2994 Male 2115 Other 1 Name: gender, dtype: int64 78.00 102 57.00 95 52.00 90 54.00 87 51.00 86... 1.40 3 0.48 3 0.16 3 0.40 2 0.08 2 Name: age, Length: 104, dtype: int64 0 4612 1 498 Name: hypertension, dtype: int64 0 4834 1 276 Name: heart_disease, dtype: int64 Yes 3353 No 1757 Name: ever_married, dtype: int64 Private 2925 Self-employed 819 children 687 Govt_job 657 Never_worked 22 Name: work_type, dtype: int64 Urban 2596 Rural 2514 Name: Residence_type, dtype: int64 93.88 6 91.68 5 91.85 5 83.16 5 73.00 5.. 111.93 1 94.40 1 95.57 1 66.29 1 85.28 1 Name: avg_glucose_level, Length: 3979, dtype: int64 28.7 41 28.4 38 26.7 37 27.6 37 26.1 37.. 48.7 1 49.2 1 51.0 1 49.4 1 14.9 1 Name: bmi, Length: 418, dtype: int64 never smoked 1892 Unknown 1544 formerly smoked 885 smokes 789 Name: smoking_status, dtype: int64 0 4861 1 249 Name: stroke, dtype: int64
print('查看病例数据的数值变量的描述性分析:')#对于数值型变量,观察数值范围
print(excel1['age'].describe(),'\n\n')
print(excel1['avg_glucose_level'].describe(),'\n\n')
print(excel1['bmi'].describe(),'\n\n')查看病例数据的数值变量的描述性分析: count 5110.000000 mean 43.226614 std 22.612647 min 0.080000 25% 25.000000 50% 45.000000 75% 61.000000 max 82.000000 Name: age, dtype: float64 count 5110.000000 mean 106.147677 std 45.283560 min 55.120000 25% 77.245000 50% 91.885000 75% 114.090000 max 271.740000 Name: avg_glucose_level, dtype: float64 count 4909.000000 mean 28.893237 std 7.854067 min 10.300000 25% 23.500000 50% 28.100000 75% 33.100000 max 97.600000 Name: bmi, dtype: float64
excel1 = excel1.fillna(np.mean(excel1['bmi']))#bmi数据有遗漏,用平均值填充变量
excel1.drop(excel1[excel1['gender'] == 'Other'].index, inplace= True)print('查看附件1病例数据大小:',excel1.shape)
print('查看附件2预测数据大小:',excel2.shape)
length_excel1=excel1.shape[0]
length_excel2=excel2.shape[0]查看附件1病例数据大小: (5109, 12) 查看附件2预测数据大小: (10, 12)
#把两个数据放一起处理
all_data = pd.concat((excel1, excel2)).reset_index(drop=True)#合并
all_data.drop(columns=['id'],axis=1,inplace=True)#丢弃id
all_data.drop(columns=['gender'],axis=1,inplace=True)#丢弃id
print('查看去掉id列后所有数据的大小:',all_data.shape)查看去掉id列后所有数据的大小: (5119, 10)
all_data[['hypertension', 'heart_disease', 'stroke']] = all_data[['hypertension', 'heart_disease', 'stroke']].astype(str)#改变数据类型 int转object
print('查看所有变量信息:')
print(all_data.info())查看所有变量信息: <class 'pandas.core.frame.DataFrame'> RangeIndex: 5119 entries, 0 to 5118 Data columns (total 10 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 5119 non-null float641 hypertension 5119 non-null object 2 heart_disease 5119 non-null object 3 ever_married 5119 non-null object 4 work_type 5119 non-null object 5 Residence_type 5119 non-null object 6 avg_glucose_level 5119 non-null float647 bmi 5119 non-null float648 smoking_status 5119 non-null object 9 stroke 5119 non-null object dtypes: float64(3), object(7) memory usage: 400.0+ KB None
all_data=pd.get_dummies(all_data, drop_first=True)#字符串变量整形处理#把不同的变量内容转化为0,1分布#哑变量处理from sklearn.preprocessing import StandardScaler
#s = StandardScaler()
all_data[['bmi', 'avg_glucose_level', 'age']] = StandardScaler().fit_transform(all_data[['bmi', 'avg_glucose_level', 'age']])#特征标准化#object转uint8print('\n查看特征标准化后所有变量信息:')
print(all_data.info())查看特征标准化后所有变量信息: <class 'pandas.core.frame.DataFrame'> RangeIndex: 5119 entries, 0 to 5118 Data columns (total 16 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 5119 non-null float641 avg_glucose_level 5119 non-null float642 bmi 5119 non-null float643 hypertension_1 5119 non-null uint8 4 heart_disease_1 5119 non-null uint8 5 ever_married_Yes 5119 non-null uint8 6 work_type_Never_worked 5119 non-null uint8 7 work_type_Private 5119 non-null uint8 8 work_type_Self-employed 5119 non-null uint8 9 work_type_children 5119 non-null uint8 10 Residence_type_Urban 5119 non-null uint8 11 smoking_status_formerly smoked 5119 non-null uint8 12 smoking_status_never smoked 5119 non-null uint8 13 smoking_status_smokes 5119 non-null uint8 14 stroke_1.0 5119 non-null uint8 15 stroke_nan 5119 non-null uint8 dtypes: float64(3), uint8(13) memory usage: 185.1 KB None
excel1=all_data[:length_excel1]
excel2=all_data[length_excel1:]
print('最终病例集数量:',excel1.shape)
print('最终预测集数量:',excel2.shape)最终病例集数量: (5109, 16) 最终预测集数量: (10, 16)
X=excel1.drop(['stroke_1.0'],axis=1)
Y=excel1['stroke_1.0']
z=excel2.drop(['stroke_1.0'],axis=1)from sklearn.model_selection import train_test_splitx_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=1024)
print('查看划分的训练集的组成:\n',y_train.value_counts())
print('查看划分的测试集的组成:\n',y_test.value_counts())查看划分的训练集的组成:0 3881 1 206 Name: stroke_1.0, dtype: int64 查看划分的测试集的组成:0 979 1 43 Name: stroke_1.0, dtype: int64
from imblearn.over_sampling import RandomOverSampler
over=RandomOverSampler(sampling_strategy=1)
x_smote,y_smote=over.fit_resample(x_train,y_train)
print('查看过采样的训练集的组成:\n',y_smote.value_counts())
print('查看过采样的测试集的组成:\n',y_test.value_counts())
查看过采样的训练集的组成:0 3881 1 3881 Name: stroke_1.0, dtype: int64 查看过采样的测试集的组成:0 979 1 43 Name: stroke_1.0, dtype: int64
'''
from imblearn.under_sampling import RandomUnderSampler
over=RandomUnderSampler(random_state=42)
x_smote,y_smote=over.fit_resample(x_train,y_train)
print('查看过采样的训练集的组成:\n',y_smote.value_counts())
print('查看过采样的测试集的组成:\n',y_test.value_counts())
'''"\nfrom imblearn.under_sampling import RandomUnderSampler\nover=RandomUnderSampler(random_state=42)\nx_smote,y_smote=over.fit_resample(x_train,y_train)\nprint('查看过采样的训练集的组成:\n',y_smote.value_counts())\nprint('查看过采样的测试集的组成:\n',y_test.value_counts())\n"
x_train=x_smote
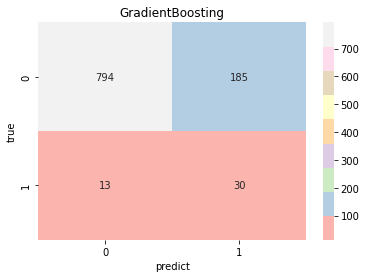
y_train=y_smotefrom sklearn.metrics import accuracy_score,roc_auc_score,classification_report,confusion_matrix,roc_curvedef model_choose(names, models, colors, pres):plt.figure(figsize=(5,5))#设置画布大小#plt.rcParams['font.sans-serif'] =['SimHei']#设置字体for (name, model, color) in zip(names, models, colors):model.fit(x_train, y_train)#训练模型y_pre=model.predict(x_test)#得预测值print('\n\n')print(name,'Accuracy:',accuracy_score(y_test,y_pre))#计算准确率score=model.predict_proba(x_test)[:,1]print(name,'AUC:', roc_auc_score(y_test,score))#计算AUCprint(classification_report(y_test, y_pre))#其它数值计算fpr,tpr,thresholds=roc_curve(y_test, score)#画ROC曲线plt.plot(fpr, tpr, color=color, lw=1, label=f'{name} AUC= {roc_auc_score(y_test,score)}')plt.axis('square')plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('各类模型ROC曲线对比',fontproperties=prop) plt.legend(loc="lower right") plt.savefig('各类型模型ROC曲线对比')plt.show()countnum=0for (name, model, color, z_pre) in zip(names, models, colors, pres):model.fit(x_train, y_train)y_pre=model.predict(x_test)#得预测值z_pre=model.predict_proba(z)[:,1]#对附件二的十个人进行预测概率model_pre[countnum]=z_precountnum+=1#print(z_pre)cm=confusion_matrix(y_test,y_pre)#画混淆矩阵/热力图ax=sns.heatmap(cm,cmap='Pastel1',annot=True,fmt='g',xticklabels=['0','1'],yticklabels=['0','1'])ax.set_title(name)ax.set_xlabel('predict')ax.set_ylabel('true')plt.savefig(name)plt.show()#逻辑回归
from sklearn.linear_model import LogisticRegression
model1=LogisticRegression()
#k近邻
from sklearn.neighbors import KNeighborsClassifier
model2=KNeighborsClassifier(n_neighbors=10)
#决策树
from sklearn.tree import DecisionTreeClassifier
model3=DecisionTreeClassifier()
#随机森林
from sklearn.ensemble import RandomForestClassifier
model4=RandomForestClassifier(n_estimators=300)
#向量机
from sklearn.svm import SVC
model5=SVC(kernel='rbf', probability=True)
#梯度下降
from sklearn.linear_model import SGDClassifier
model6=SGDClassifier(random_state=12, loss='log')
#梯度上升
from sklearn.ensemble import GradientBoostingClassifier
model7=GradientBoostingClassifier(random_state=6)model_name=['Logistic','KNeighbors','DecisionTree','RandomForest','SVC','SGD','GradientBoosting']
model_type=[model1,model2,model3,model4,model5,model6,model7]
model_color = ['yellow', 'aqua', 'lawngreen', 'fuchsia', 'orange', 'r', 'pink']
model_pre=[np.array([]),np.array([]),np.array([]),np.array([]),np.array([]),np.array([]),np.array([]),]model_choose(model_name, model_type, model_color, model_pre)Logistic Accuracy: 0.7514677103718199 Logistic AUC: 0.8284438321020501precision recall f1-score support0 0.99 0.75 0.85 9791 0.12 0.79 0.21 43accuracy 0.75 1022macro avg 0.55 0.77 0.53 1022 weighted avg 0.95 0.75 0.83 1022KNeighbors Accuracy: 0.8209393346379648 KNeighbors AUC: 0.7010832125804689precision recall f1-score support0 0.97 0.84 0.90 9791 0.11 0.47 0.18 43accuracy 0.82 1022macro avg 0.54 0.65 0.54 1022 weighted avg 0.94 0.82 0.87 1022DecisionTree Accuracy: 0.9334637964774951 DecisionTree AUC: 0.5428177779889303precision recall f1-score support0 0.96 0.97 0.97 9791 0.14 0.12 0.13 43accuracy 0.93 1022macro avg 0.55 0.54 0.55 1022 weighted avg 0.93 0.93 0.93 1022RandomForest Accuracy: 0.9461839530332681 RandomForest AUC: 0.7939520630923819precision recall f1-score support0 0.96 0.98 0.97 9791 0.17 0.07 0.10 43accuracy 0.95 1022macro avg 0.56 0.53 0.54 1022 weighted avg 0.93 0.95 0.94 1022SVC Accuracy: 0.7436399217221135 SVC AUC: 0.7864218352851747precision recall f1-score support0 0.98 0.75 0.85 9791 0.11 0.70 0.19 43accuracy 0.74 1022macro avg 0.55 0.72 0.52 1022 weighted avg 0.95 0.74 0.82 1022SGD Accuracy: 0.7534246575342466 SGD AUC: 0.8246668408675202precision recall f1-score support0 0.99 0.75 0.85 9791 0.12 0.77 0.21 43accuracy 0.75 1022macro avg 0.55 0.76 0.53 1022 weighted avg 0.95 0.75 0.83 1022GradientBoosting Accuracy: 0.8062622309197651 GradientBoosting AUC: 0.8325533886025133precision recall f1-score support0 0.98 0.81 0.89 9791 0.14 0.70 0.23 43accuracy 0.81 1022macro avg 0.56 0.75 0.56 1022 weighted avg 0.95 0.81 0.86 1022
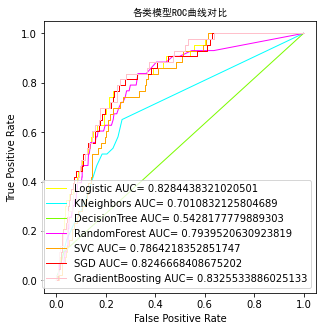
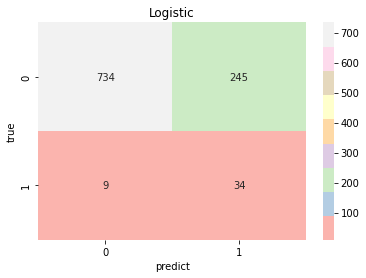
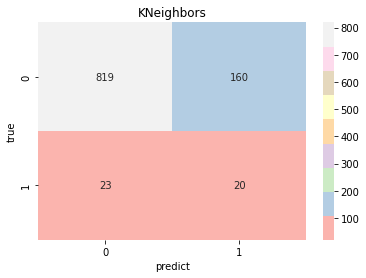
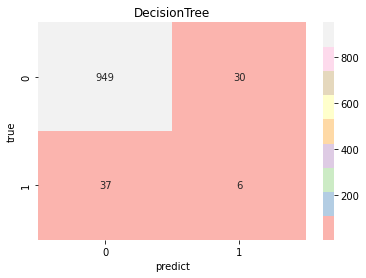
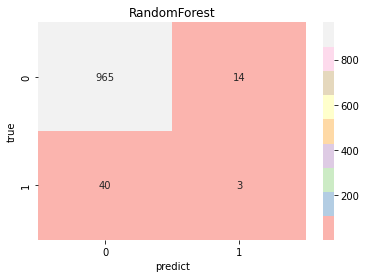
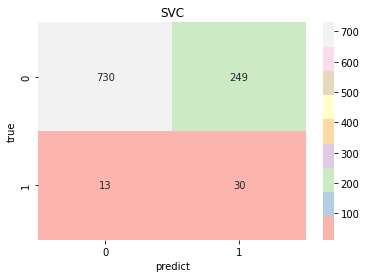
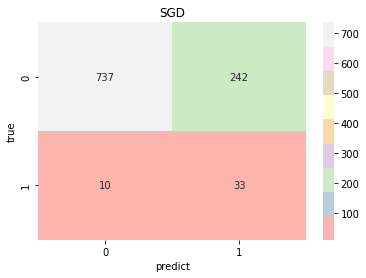
result=(model_pre[0]+model_pre[3]+model_pre[5]+model_pre[6])/4#取效果好的四个模型计算
print(result)#10个人的概率
print(np.sort(result))#概率排序
print(np.argsort(-result)+1)#输出原索引[0.77866337 0.29122944 0.86967168 0.62082311 0.73240077 0.130646320.78216716 0.28405546 0.3040807 0.57776553] [0.13064632 0.28405546 0.29122944 0.3040807 0.57776553 0.620823110.73240077 0.77866337 0.78216716 0.86967168] [ 3 7 1 5 4 10 9 2 8 6]



![[实体关系抽取|顶刊论文]QIDN:Query-based Instance Discrimination Network for Relational Tri](https://img-blog.csdnimg.cn/img_convert/d3769c2c4f4efd23a1a635eaa18398df.png)