原文标题: BiasAdv: Bias-Adversarial Augmentation for Model Debiasing
原文代码: 暂无
发布年度: 2023
发布期刊: CVPR
摘要
Neural networks are often prone to bias toward spurious correlations inherent in a dataset, thus failing to generalize unbiased test criteria. A key challenge to resolving the issue is the significant lack of bias-conflicting training data (i.e., samples without spurious correlations). In this paper, we propose a novel data augmentation approach termed BiasAdversarial augmentation (BiasAdv) that supplements biasconflicting samples with adversarial images. Our key idea is that an adversarial attack on a biased model that makes decisions based on spurious correlations may generate synthetic bias-conflicting samples, which can then be used as augmented training data for learning a debiased model. Specifically, we formulate an optimization problem for generating adversarial images that attack the predictions of an auxiliary biased model without ruining the predictions of the desired debiased model. Despite its simplicity, we find that BiasAdv can generate surprisingly useful synthetic bias-conflicting samples, allowing the debiased model to learn generalizable representations. Furthermore, BiasAdv does not require any bias annotations or prior knowledge of the bias type, which enables its broad applicability to existing debiasing methods to improve their performances. Our extensive experimental results demonstrate the superiority of BiasAdv, achieving state-of-the-art performance on four popular benchmark datasets across various bias domains.
背景
现实世界的数据集通常本质上是有偏差的,其中某些视觉属性与类标签虚假相关。例如,如图 1 所示,考虑猫和狗之间的二元分类任务,但是数据集由大多数室内的猫和大多数室外的狗组成。当在这样一个有偏差的数据集上进行训练时,神经网络经常学习意想不到的捷径(例如,基于背景的预测)并且无法在新的无偏见测试环境中进行概括。
为了解决这个问题,传统方法利用了详细偏差注释或偏差类型的先验知识。然而,偏差注释的获取成本高昂且费力,并且提前假设某些偏差类型限制了普遍适用于各种偏差类型的能力。为了训练没有偏差注释的去偏差模型,最近研究的通常利用故意偏差模型作为辅助模型,因为偏差属性易于学习。本质上,这些方法基于辅助模型识别偏差冲突样本,并以更关注识别样本的方式训练去偏差模型(即基于辅助模型重新加权)。尽管最近的重新加权方法在没有偏差注释的去偏差方面取得了显着的成功,但它们具有固有的局限性;由于偏差冲突样本的数量通常太小,模型无法学习可概括的表示,因此模型很容易过度拟合。因此,重新加权方法会受到偏差引导样本性能下降的影响,这就提出了一个问题:这些方法是否真正使模型去偏差,或者只是使模型偏向非预期的方向。
为了解决上述问题,最近提出了数据增强方法来补充偏差冲突的样本。例如,BiaSwap进行图像到图像的翻译来合成偏差冲突的样本。然而,它需要对复杂且昂贵的图像翻译模型进行精细训练,限制了其适用性。另一方面,DFA 利用基于偏差引导和偏差冲突特征之间的解开表示的特征级交换。然而,在现实世界的数据集上学习解开的表示通常具有挑战性。
创新点
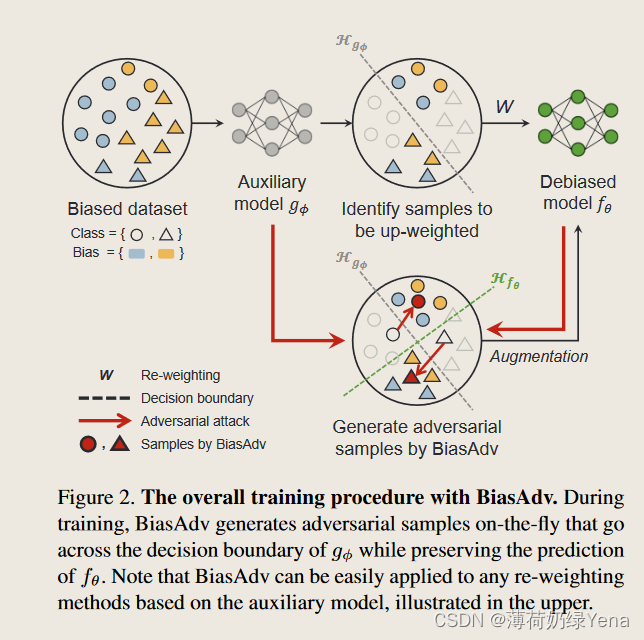
在本文中,我们设计了一种更简单但更有效的方法来生成偏差冲突样本,创造了偏差对抗增强(BiasAdv)。图 1 显示了 BiasAdv 的概述。我们利用一个辅助模型来有意学习有偏差的捷径。 BiasAdv 的关键思想是,对有偏差的辅助模型的对抗性攻击可能会生成改变输入图像(即偏差冲突样本)的偏差线索的对抗性图像。具体来说,我们制定了一个优化问题来生成对抗性图像,该图像攻击有偏差的辅助模型的预测,而不破坏所需的去偏差模型的预测。然后,生成的对抗图像用作附加训练数据来训练去偏模型。值得注意的是,与之前的数据增强方法]不同,BiasAdv不需要复杂的图像转换模型或解缠结表示,因此它可以无缝地应用于任何基于偏置模型的去偏置方法。
模型
本文考虑学习一个分类器的任务,该分类器在存在数据集偏差的情况下将输入图像 x ∈ X 分类为 C 类 y ∈ Y 之一。具体来说,我们考虑一个有偏差的训练数据集 D = {(xi, yi)}N i=1,其中图像 x 的某个视觉属性 a ∈ A 与类标签 y 虚假相关,而实际上两者之间没有因果关系。
原任务目标:

近年来,重新加权方法得到了广泛的研究。基于偏差属性 a 比其他内在属性更优先被学习的假设,这些方法采用辅助分类模型 gφ : X → Y 由 φ ε Φ 参数化,该模型被有意训练以做出有偏差的决策(即,根据 a) 预测 y。
基于辅助模型gφ,重新加权方法首先识别偏差冲突样本,然后训练模型fθ以强调所识别的偏差冲突样本的方式去偏差。定义如下:

其中W(x,y;θ,φ)表示(x,y)的样本权重。这种方法会有过拟合导致泛化表达能力下降的问题。
- Bias-Adversarial Augmentation
给定训练对 (x, y) ∈ D,BiasAdv 的目标是生成对抗性图像 xadv,它可以充当合成偏差冲突样本,用于训练去偏差模型 fθ。我们利用偏置模型 gφ 作为辅助模型。因此,为了确保只有偏差属性受到攻击,我们约束 xadv 不影响去偏差模型 fθ 的类预测。为此,BiasAdv通过解决以下优化问题来生成xadv,
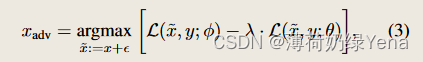
其中 L 表示交叉熵损失。第一项攻击 gφ 的预测,而第二项保留 fθ 的预测,从而防止内在属性受到对抗性扰动的损害。简而言之,BiasAdv 将原始图像 x 转换为穿过 gφ 的决策边界,同时保留 fθ 的预测。
然后,生成的对抗性示例 xadv 用作学习去偏模型 fθ 的附加训练数据。具体来说,我们使用对抗数据和原始数据的混合来训练 fθ,最小化定义为的 Ra (θ),

其中 ω x 和 ω adv 分别表示 x 和 x adv 的样本权重。对于 ω x ,我们可以利用方程 1 中现有的重新加权公式 W(x, y; θ, φ)。 (2) 定义 ω x = W(x, y; θ, φ)。也就是说,BiasAdv 可以与任何现有的利用辅助模型的重新加权方法相结合。在这种情况下,我们设计 ω adv 来权衡样本权重 ω x ,如下所示: ω adv = β · (1 − ω x ) 其中 β > 0 表示控制对抗性数据重要性的超参数。
实验
评估指标:对于定量评估,我们采用了三个指标;平均(即所有样本的准确度 (%))、冲突(即偏差冲突样本的准确度 (%))和最差组(即各组之间的最小准确度 (%),其中每个组由类标签定义,并且偏差属性)。
1.主要结果
bias_conflicting样本的比例越高,模型的整体效果就会越好。将本文的方法与目前reweighting的方法进行结合,得到的效果有较大的提升,并且在模型结合后超越了所有的方法,达到了最好的效果。
2.分析
- BiasAdv 是否会生成偏差冲突的样本?
图 3 显示了 BiasAdv 生成的对抗图像的示例。尽管 BiasAdv 明显改变了 g φ 的预测(即老 → 年轻),同时保留了 fθ 的预测。
为了验证 BiasAdv 从网络角度生成有意义的偏差冲突样本,使用 t-SNE对原始偏差引导样本、原始偏差冲突样本和 BiasAdv 生成的样本的倒数第二个特征进行可视化和比较。偏见引导样本和偏见冲突样本彼此分开分布。值得注意的是,BiasAdv 生成的样本与偏差冲突的样本重叠。这一观察结果表明,BiasAdv 的这些合成对抗性图像确实可以作为训练去偏模型的偏差冲突样本,即使对抗性扰动很少在人类水平上被识别。
- 偏差引导样本的性能。
一个良好泛化的模型应该适用于偏差引导样本和偏差冲突样本。因此,我们证明了 BiasAdv 在维持偏差引导样本性能方面的有效性。
在图 5 中,在对于LfF 的情况下,偏差引导样本的性能随着训练的进行而下降,这意味着 LfF 过度拟合了数量不足的偏差冲突样本。另一方面,应用 BiasAdv 保持了良好的偏差引导性能,并在训练结束时实现了显着更高的偏差引导精度。这些结果支持 BiasAdv 有助于学习可泛化表示并减少过度拟合。
- 消融实验
噪声添加:随机模型通过添加随机噪声而不是 BiasAdv 来增强数据。 AdvProp 模型使用对抗性图像来攻击去偏模型而不是辅助模型。最后验证式(3)中BiasAdv的正则化项λ·L(̃x,y;θ)的效果,将λ设置为0。
添加随机噪声会带来轻微的性能提升,但前景并不乐观。然而,AdvProp 添加了攻击去偏模型的对抗性噪声,严重降低了性能。相比之下,仅攻击辅助模型的 BiasAdv (λ = 0) 产生了显着的性能改进。这一观察结果表明,攻击有偏见的辅助模型对于使我们的方法发挥作用至关重要。也就是说,BiasAdv 带来的性能改进归因于合成偏差冲突样本的生成(如图 4 中所述),而不是对抗性图像的正则化能力。最后,使用等式(3)中的正则化项有助于有希望的性能改进。正则化项可防止内在属性受到对抗性扰动的损害,并提高生成样本的质量,从而提供额外的性能增益。
- Grad-CAM 的可视化
在图 6 中,我们显示了用于预测年龄的类激活图。值得注意的是,ERM 和 LfF 突出显示了胡须,这与性别(即男性)密切相关,这意味着这些模型是根据偏差属性做出决策的。仅攻击有偏差的辅助模型 g φ(即 λ = 0)会促使模型关注偏差属性以外的区域,但通常是完全错误的区域,例如背景。通过提出的正则化约束来维持去偏模型 f θ 的预测分数,BiasAdv 有助于更好的语义聚焦,关注年龄预测的判别区域,但与性别无关,例如前额。这些观察结果表明,我们的 BiasAdv 引导去偏模型捕获目标类的内在属性,支持第 4.2 节中提出的无偏测试标准的卓越泛化性能。
- 模型的稳健性。
在表 6 中,我们比较了 ERM、LfF 和 LfF + BiasAdv 的结果。尽管输入图像变化很小,但 ERM 和 LFF 的性能却严重下降。相比之下,应用 BiasAdv 显着提高了模型的稳健性,无论损坏类型如何,都能实现稳健且卓越的性能。