【大模型驯化-Prompt】企业级大模型Prompt调试技巧
本次修炼方法请往下查看

🌈 欢迎莅临我的博客个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地!
🎇 免费获取相关内容文档关注: 微信公众号 发送 pandas 即可获取
🎇 相关内容视频**讲解 B站
🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,熟练掌握机器、深度学习等各类应用算法原理和项目实战经验。
🔧 技术专长: 在机器学习、搜索、广告、推荐、CV、NLP、多模态、数据分析等算法相关领域有丰富的项目实战经验。已累计为求职、科研、学习等需求提供近千次有偿|无偿定制化服务,助力多位小伙伴在学习、求职、工作上少走弯路、提高效率,近一年好评率100% 。
📝 博客风采: 积极分享关于机器学习、深度学习、数据分析、NLP、PyTorch、Python、Linux、工作、项目总结相关的实用内容。
🌵文章目录🌵
- 🎯 一、基本介绍
- 💡 2. 使用方法
- 2.1 网页版
- 2.1 接口版
- 🔍 3. Prompt的一些创建心得
- 🔧 4. Prompt高阶用法
下滑查看解决方法
🎯 一、基本介绍
Prompt 工程是创建提示或指导像 ChatGPT 这样的语言模型输出的过程。它允许用户控制模型的输出并生成符合其特定需求的文本。
prompt的设计一定要有逻辑和系统性,现在大模型对于文本的分类、抽取、生成、理解等nlp任务都特别的强大,在通用的领域里面基本不会比传统的模型效果差,但是受限于gpu资源和预算,目前对于大规模的任务很多都是通过大模型进行样本的修正和标注,在用小模型进行在线部署,后续如果性能提高、费用降低很多之前的小模型都会基于大模型进行任务的处理。
- prompt的三要素:
- 任务:对提示要求模型生成的内容进行清晰而简洁的陈述。
- 指令:在生成文本时模型应遵循的指令。
- 角色:模型在生成文本时应扮演的角色。
- 对于prompt来说,最为重要的几个点,就是上面的三个要素,在设计prompt时,一定需要表达明确和具体,从而使得整体prompt逻辑顺畅。
💡 2. 使用方法
2.1 网页版
大模型的发展使得当前的工作效率都有了极大的提升,当前不管是pm、运营、研发都不得不提升对大模型的使用,下面介绍一些免费的网页版本大模型使用方法,具体主要有如下的一些工具:
kimi: 网页地址,这个对话助手是用来写长文章、看论文的超级好手,下面为一个例子具体怎么去用来看论文:
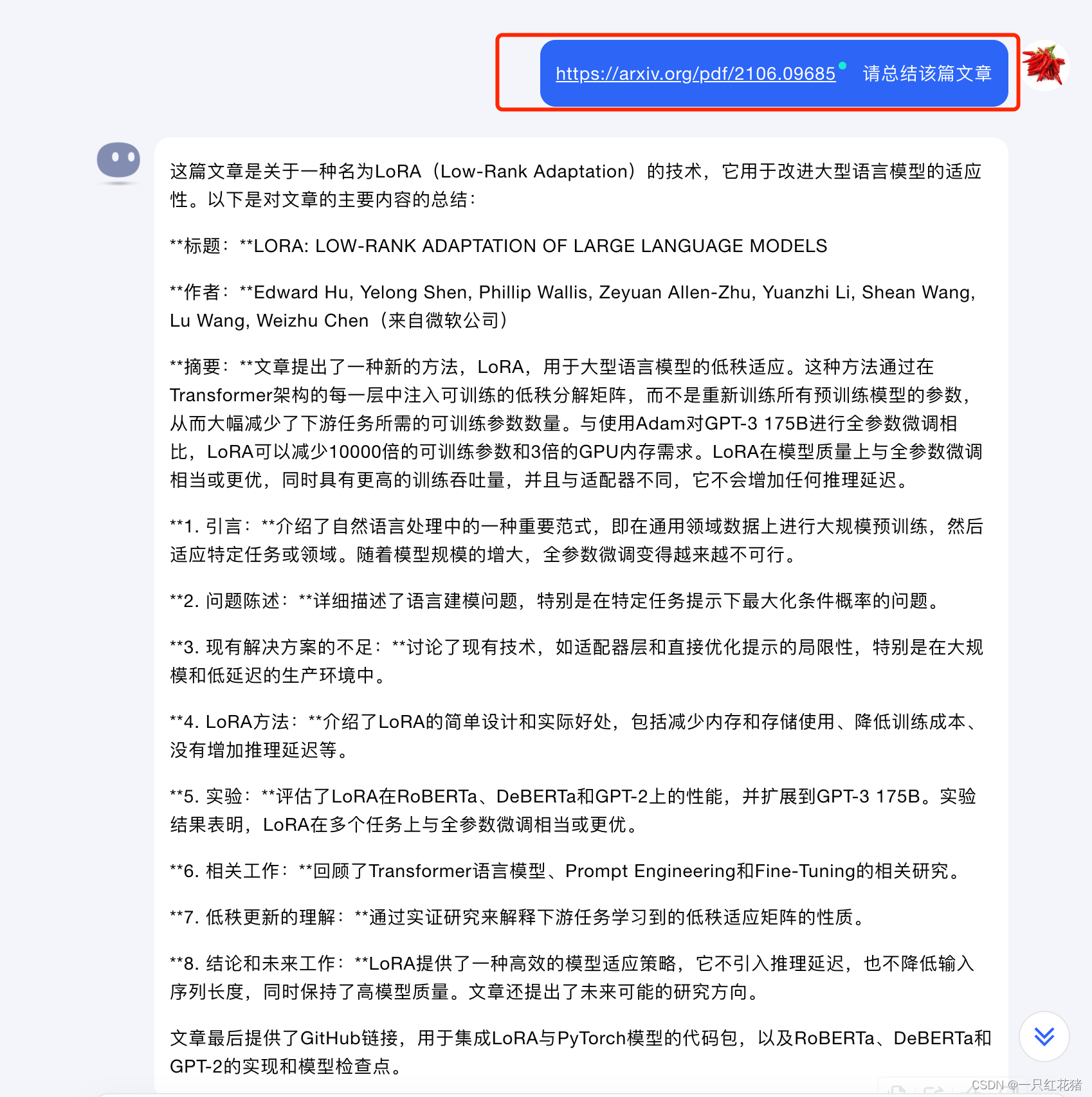
对于上述图片中红色框中的东西就是为prompt,对于大多数非大模型开发者来说,都是通过网页对话的方式进行,如上述的prompt为对论文进行摘要,如果想要输出一定的格式,则需要修改上述的输入为:
https://arxiv.org/pdf/2106.09685 请总结该篇文章,输出格式为:
1. 核心思想总结; 2. 论文中的创新点总结; 3. 数据对比理论推导详细介绍豆包:地址,这个产品为字节旗下的ai产品,在语音对话上面有极大的优势,可以用来锻炼英语,大家感兴趣的可以下载app来玩玩,目前在产品体验上面还是相当不错的
2.1 接口版
对于大多数的大模型开发者来说,网页版都只能是临时的处理一个特定的任务,而在企业工作时,通常需要对多个数据进行处理,下面以chatgpt为主的代码调用方法:
from openai import OpenAI
def get_chatgpt_result(prompt_info):"""chatgpt的运行结果"""client = OpenAI(api_key="sk-xxx",)messages = [{"role": "user", "content": prompt_info}]response = client.chat.completions.create(model="gpt-3.5-turbo",messages=messages,temperature=0, # this is the degree of randomness of the model's output)return response.choices[0].message["content"]如上述的代码所示,通过接口调用chatgpt相对来说也比较简单,只需要修改里面的参数传入即可
🔍 3. Prompt的一些创建心得
prompt 通用的一些提示词 :生成、总结、严格按照、提取、xx专家
- 提示技巧
- 具体的模板为:按照以下指示生成[任务]:[指令]
- 其中任务指的是具体的目标,指令指的是生成目标的要求
- 具体的例子:按照以下指示生成【符合相关法律法规的法律文件】:【文件应符合相关法律法规】
- 角色技巧
- 具体的模板为:作为[角色]生成[任务]
- 其中角色指的是在生产任务时某个领域的专家,任务就是具体的目标
- 具体的例子:作为【律师】,生成【法律文件】
- 提示+角色
- 将上述两个技巧结合起来的具体例子如下所示:
- 任务:为新智能手机生成产品描述
- 指令:描述应该是有信息量的,具有说服力,并突出智能手机的独特功能
- 角色:市场代表 种子词:“创新的”
- 提示公式:作为市场代表,生成一个有信息量的、有说服力的产品描述,突出新智能手机的创新功能。该智能手机具有以下功能【插入您的功能】
- 对比提示
- 具体的模板为:基于[数量]个示例生成文本,这种方式可以使得模型聚焦到某一个点上,大幅提升模型对文本的理解能力,在特定的任务上使用比较多
- 其中数量为某一个任务的现实存在的对比对象
- 使用少量示例【3个其他电子阅读器】为这款新电子阅读器生成评论
- 思考提示
- 具体的模板:【让我们思考|讨论|谈谈|等一下】+ 任务,该方法在用于生成式内容中比较常用,可以模拟一个人去思考具体的任务,在相对推理的提示中用的比较多
- 具体的例子:【让我们讨论】人工智能的当前状态
- 自洽提示
- 用于确保ChatGPT的输出与提供的输入一致。这种技术对于事实核查、数据验证或文本生成中的一致性检查等任务非常有用。
- 具体公式:【生成】与以下产品信息一致的产品评论【插入产品信息】
- 具体例子:以与提供的上下文一致的方式完成以下句子【插入句子】
- 任务:检查给定新闻文章的一致性
输入文本:“文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
提示公式:“请确保以下文本是自洽的:文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
- 种子词提示
- 种子词提示是一种通过提供特定的种子词或短语来控制ChatGPT输出的技术。种子词提示的提示公式是种子词或短语
- 具体的模板:请根据以下【种子词】生成文本
- 具体例子:作为研究员,请在与种子词“科学”相关且以研究论文的形式书写的情况下完成以下句子:【插入句子】
- 整合提示
- 这种方法的具体作用用于将当前的信息和目前已经存在的信息进行融合到一起,生成新的信息的过程
- 具体公式:将以下信息与关于[具体主题]的现有知识整合:[插入新信息]
- 多项式提示
- 这种技术向模型提供一个问题或任务以及一组预定义的选项作为潜在答案,通过这种方法可以取代传统技术来进行文本分类的技术
- 具体的模板:通过选择以下选项之一回答以下问题:[插入问题] [插入选项1] [插入选项2] [插入选项3]
- 通过改写上述的模板,增加每个选项的解释,和输出要求就可以得到使用gpt进行文本分类的效果,而且准确率都比较高
- 控制提示
- 控制生成提示是一种技术,可让模型在生成文本时对输出进行高度控制。该方法在文本生成的时候特别的适用,通过设计一个生成模板,使得生成的内容按照一定的逻辑进行输出
- 具体的模板:生成遵循以下语法规则的文本:[插入规则]:[插入上下文]
- 抽取提示
- 允许模型在保留其主要思想和信息的同时生成给定文本的较短版本。该方法主要应用在文本的摘要生成中,通过设计对长文本进行主题思想的提取得到想要的核心内容
- 具体模板:【规则】+【文章】
- 这种方法在目前的文本摘要抽取中用的比较多,具体会和控制提示一起连用,用控制提示来制定抽取的规则
- 对抗提示
- 它允许模型生成抵抗某些类型的攻击或偏见的文本,种技术可用于训练更为稳健和抵抗某些类型攻击或偏见的模型。
- 具体模板:生成难以分类为【插入标签】的文本
- 这种方法通常用来进行传统分类模型的样本微调,通过gpt生成大量传统模型无法进行分类的样本,从而丰富传统模型的样本,使得模型的样本更加丰富,最后提升传统模型的鲁棒性
- 聚类提示
- 聚类提示是一种技术,它可以让模型根据某些特征或特点将相似的数据点分组在一起,这种方法可以取代传统的基于机器学习聚类的方法
- 具体的模板:将以下新闻文章根据主题分组成簇:【插入文章】
- 该方法通常和控制提示一起连用,将控制提示作为聚类的解释说明和游戏规则进行设计
- 强化学习提示
- 强化学习提示是一种技术,可以使模型从过去的行动中学习,并随着时间的推移提高其性能
- 具体模板:使用强化学习将以下文本[插入文本]从[插入语言]翻译成[插入语言]
- 这种方法在于想要生成与之对应的文本风格
- ner提取学习
- ner模型在文本理解和抽取里面是一个比较重要的模型,目前基于gpt进行ner的抽取相对传统的方法准确率基本不会差
- 具体模板:[插入文章]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期
🔧 4. Prompt高阶用法
通常企业里面实际操作时,我们通常提取的prompt特别的长,但是输入的文本都比较短,这个时候如果每次循环的调用会使得整个模型的耗费特别的多,因此,我们需要将多个输入合并一个batch的输入进行判断,可以极大的降低输入token的耗费情况,具体的实现代码如下所示:
import openai
import re
import datetime
import pandas as pd
import time
import math
import numpy as npdef get_prompt(info):"""对样本进行标签设置"""prompt_info = ("""你是一个xx专家,根据内容解释:第一大类:个别字、词不文明,包含但不仅限于以下类别,且需要关注谐音等近似词汇和表情包1)涉黄涉性或者言语带有猥亵成分,如:靓女、大美女、丝袜、啪啪、炮、妹子、骚、鸡巴、嫖娼等;2)涉政,如:港澳台等领土范围、国家政权、八嘎牙路、牙路等;3)涉恐,如:虚假不实言论等;请对内容输出一个概率为0-1之间的概率值,1为越不会引发争议和舆情风险,0为越容易引发争议和舆情风险,如果判断为0则把触发的条件也加上:内容评论信息:内容1:xx笔记2:傻狗门卫,睡得跟死猪似的,答案:内容1:1内容2:0,傻狗内容信息:{info}答案:""")# print("---", notes)notes_str = "\n".join(["笔记" + str(index + 1) + ":" + notes[index] for index in range(len(notes))])prompt = prompt_info.format(notes=notes_str)print(prompt)result = openai.ChatCompletion.create(model="gpt-4-0613",# model="gpt-3.5-turbo",user="user参数可传递一个随机id,用于排查问题,例如traceId、uuid、requestId等",messages=[{"role": "user", "content": prompt},])once = result['choices'][0]['message']['content']print("once", once)res = once.split('\n')out = []for tmp in res:try:sp = re.split(":|:", tmp)if len(sp) != 2:out.append(['其他'])continueout.append(sp[-1])except Exception as e:print("-----", e)raise Exception("自定义异常信息")# print(out)return outdef once_request(result, notes, all_notes):label = 'null'label_index = []try:label = get_prompt(notes)except Exception as e:print(f"the openai is error is: {e}")if len(label) == len(notes):result.extend(label)all_notes.extend(notes)notes.clear()if __name__ == '__main__':openai.api_key = "xx"openai.api_base = "xx"once_request_count = 30data = pd.read_csv('xx', sep="\t") result = []cnt = 0notes = []all_notes = []predict = []for i in data.values:notes.append(i[-1])if len(notes) < once_request_count:continueonce_request(result, notes, all_notes)if len(notes) > 0:once_request(result, notes, all_notes)cnt += 1df1 = pd.DataFrame({"text": all_notes,"result": result})print(df1)df1.to_csv('result', index=False, sep='\t')