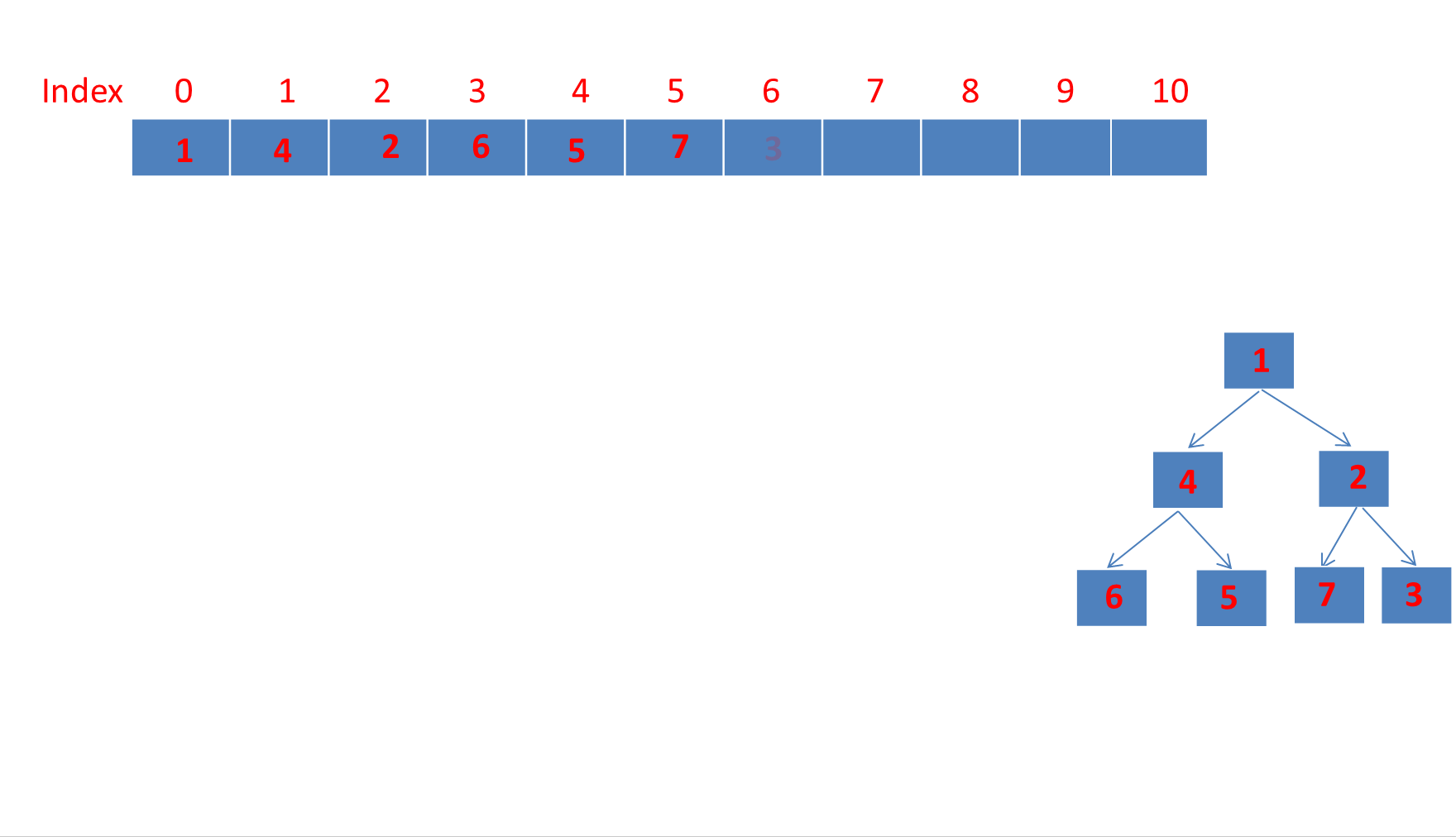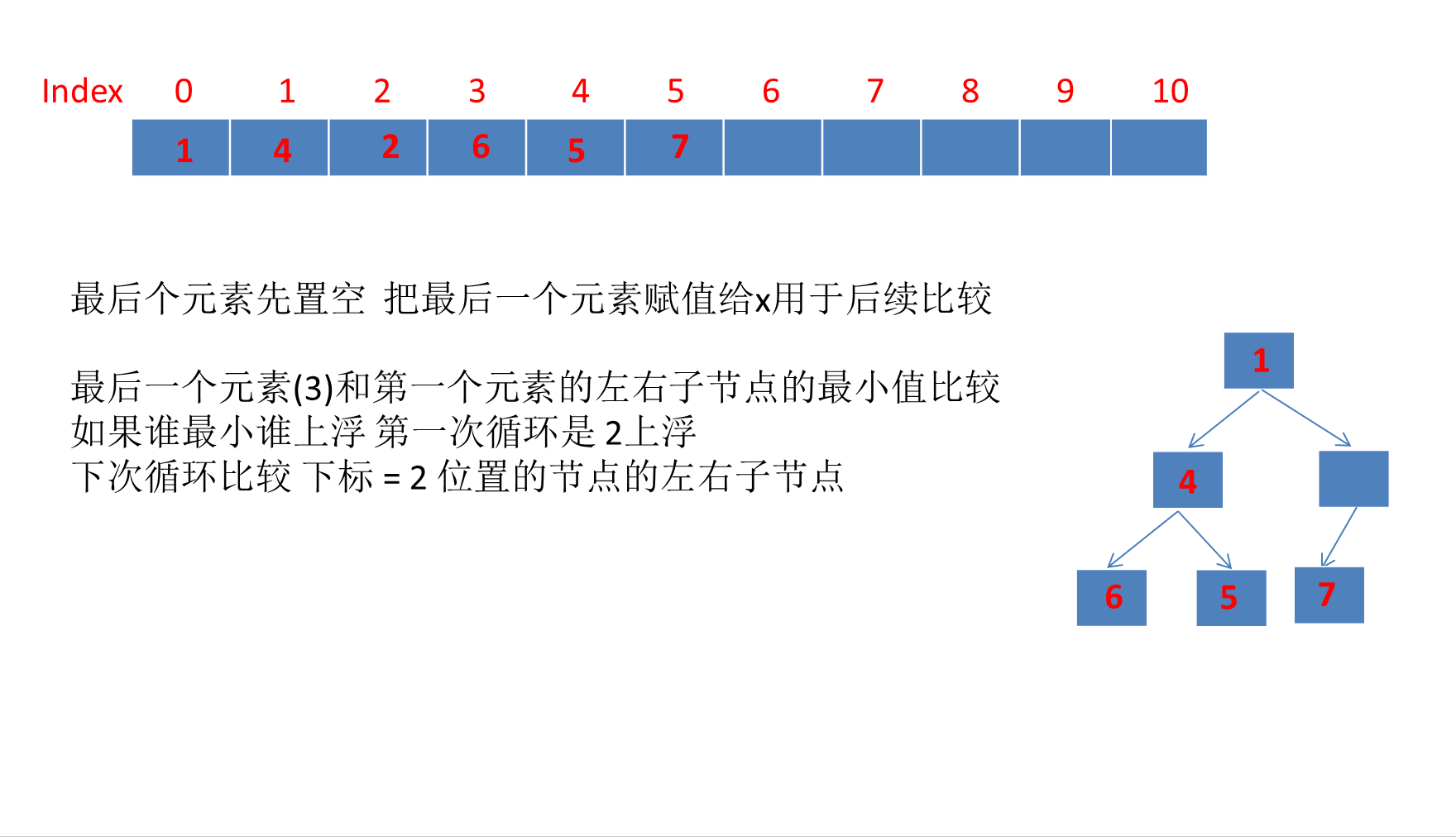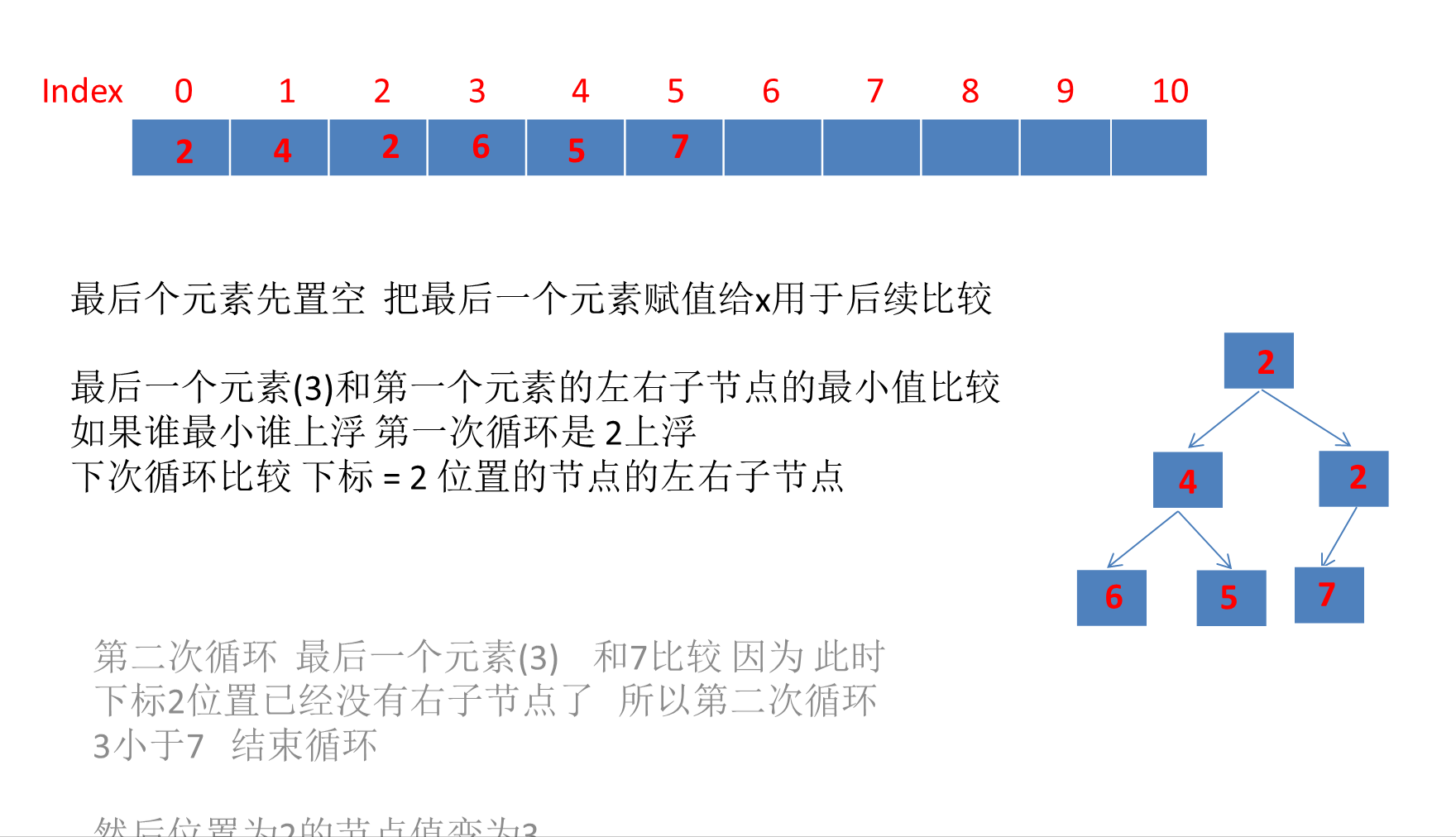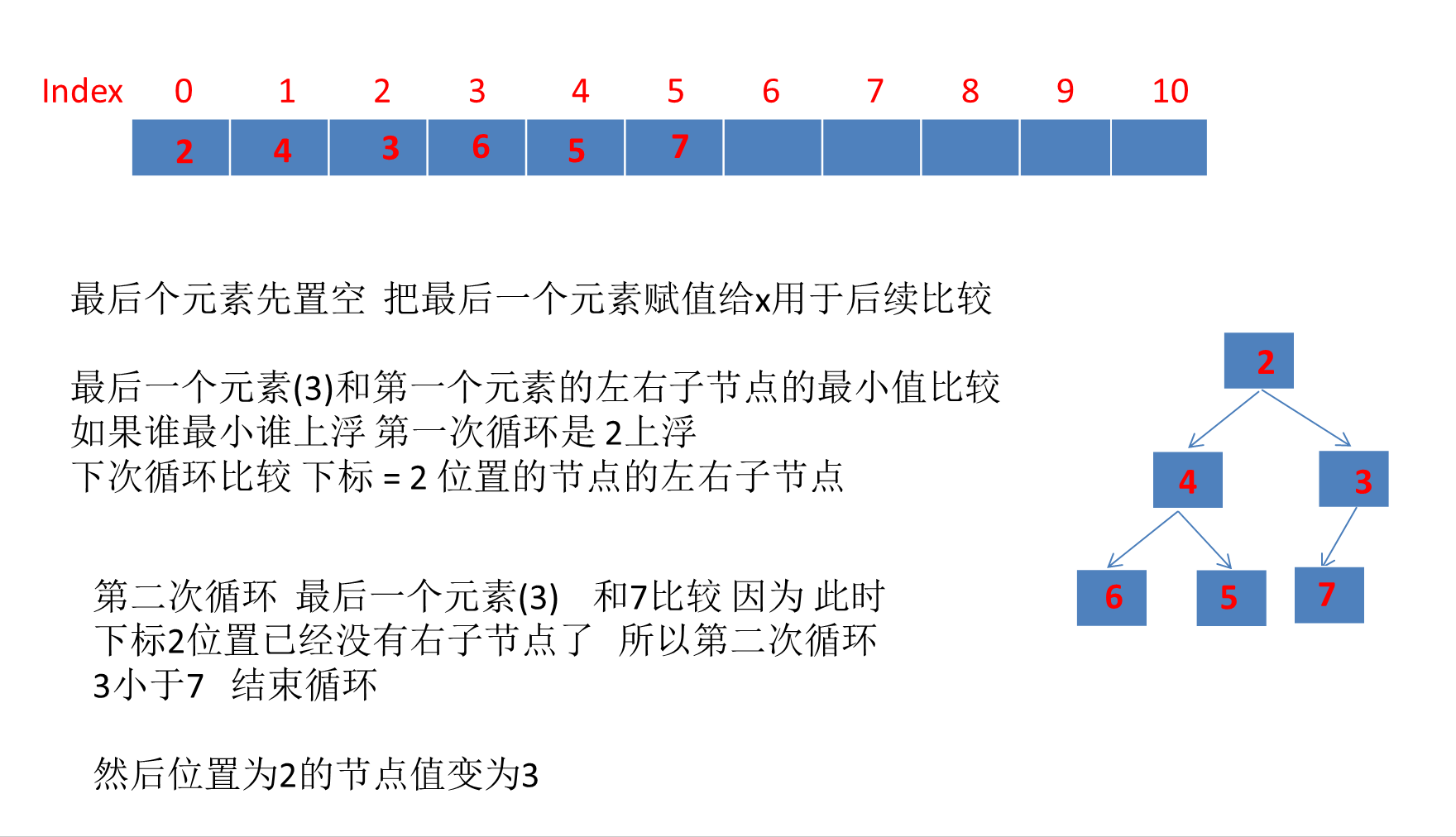
在Django中 , URL配置 ( 通常称为URLconf ) 是定义网站结构的基础 , 它充当着Django所支撑网站的 '目录' .
URLconf是一个映射表 , 用于将URL模式 ( patterns ) 映射到Python的视图函数或类视图上 .
这种映射机制是Django处理HTTP请求的基础 , 它决定了当客户端发送请求时 , Django如何调用相应的视图函数来生成并返回响应 .
通过URLconf , 开发者能够清晰地定义网站中各个URL地址与视图函数之间的关联关系 , 从而构建出结构清晰 , 易于维护的Web应用程序 . 具体来说 , 路由的作用可以概括为以下几点 :
* 1. 映射URL到视图 : 路由系统允许你将特定的URL模式映射到Python的视图函数或类视图上 . 当用户或客户端向Django服务器发送一个请求时 , Django会根据配置的URL模式来查找匹配的视图 , 并调用该视图来处理请求 . * 2. URL模式匹配 : 可以使用path ( ) 函数来定义简单的 , 非正则表达式的URL模式 , 或者使用re_path ( ) ( 或别名url ( ) ) 函数来定义更复杂的 , 基于正则表达式的URL模式 . 这些模式可以包含变量部分 , 这些部分会被捕获并传递给相应的视图函数或类视图 . * 3. 参数传递 : 通过URL模式中的变量部分 , 可以将参数传递给视图函数或类视图 . 这些参数可以是路径的一部分 ( 如文章ID ) , 也可以是查询字符串中的值 . 视图函数或类视图可以使用这些参数来定制其响应 , 例如获取特定ID的文章数据 . * 4. URL反向解析 : 在Django中 , 可以为URL模式指定一个名称 ( 使用name参数 ) . 然后 , 可以使用reverse ( ) 函数 ( 在Python代码中 ) 或 { % url % } 模板标签 ( 在模板中 ) 来根据这个名称动态地生成URL . 这被称为URL的反向解析 , 它使得在应用程序中引用URL变得更加灵活和可维护 . * 5. URL命名空间 : 在大型项目中 , 可能会有多个应用程序共享相同的URL空间 . 为了避免命名冲突 , Django提供了URL命名空间的概念 , 通过命名空间 , 可以为每个应用程序的URL模式指定一个前缀或名称 , 从而确保在反向解析时能够正确地解析出所需的URL . * 6. HTTP方法处理 : 虽然路由本身并不直接处理HTTP方法 ( 如GET , POST , PUT , DELETE等 ) , 但可以通过在视图中使用装饰器 ( 如 @ require_http_methods ) 或类视图的dispatch ( ) 方法来指定视图应响应哪些HTTP方法 . 这样 , 可以根据HTTP方法的不同来执行不同的操作 . * 7. 中间件和异常处理 : 虽然这不是路由的直接作用 , 但路由系统与Django的中间件和异常处理机制密切相关 . 当请求到达Django服务器时 , 它会首先经过一系列中间件的处理 , 然后才会进入路由系统 . 同样 , 如果在视图处理过程中发生异常 , Django会调用相应的异常处理机制来处理这些异常 . 总之 , Django的路由系统是应用程序的核心组成部分之一 , 它负责将客户端的请求映射到相应的视图上 , 并传递必要的参数 .
通过合理地配置和使用路由系统 , 可以构建出灵活 , 可扩展且易于维护的Web应用程序 .
在Django 2.0 及以后版本中推荐使用path ( ) 函数来定义URL模式与视图函数之间的映射关系 , 而在处理正则表达式路径时则使用re_path ( ) .
path ( ) 函数与re_path ( ) 函数是在Django的django . urls模块中定义的 , 通常从该模块中导入它 , 以便在项目的urls . py文件中使用 . 查看函数的定义文件 : D : \ Python \ Python38 \ Lib \ site-packages \ django \ urls \ conf . py .
path原本是在conf . py中 , 但是在urls包的__init__ . py中导入了conf . py的path函数 , 所有直接在django . urls中导入即可 .
path = partial( _path, Pattern= RoutePattern)
re_path = partial( _path, Pattern= RegexPattern)
path ( ) 函数与re_path ( ) 函数是通过Python特性 ( functools . partial ) 来定义的 , 以便在内部实现一些默认参数或行为的封装 .
不需要关心它们是如何被定义的 , 只需要将它们当作普通的函数来使用即可 .
下面的代码片段是Django框架中用于说明urls . py文件配置的注释和示例 .
"""my_site URL ConfigurationThe `urlpatterns` list routes URLs to views. For more information please see:https://docs.djangoproject.com/en/3.2/topics/http/urls/
Examples:
Function views1. Add an import: from my_app import views2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views1. Add an import: from other_app.views import Home2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf1. Import the include() function: from django.urls import include, path2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
表述的意思如下 :
* URL Configuration : 这是urls . py文件的配置说明 .
* urlpatterns list : urlpatterns是一个列表 , 其中包含了多个path ( ) 或re_path ( ) 对象 , 用于定义URL到视图的映射 . 最后,文档还提供了一个链接到Django官方文档的URL,其中包含了更多关于URL配置的信息和示例。
* Examples : 实例 .
* Function views : 视图函数 . 首先 , 从某个应用 ( 例如my_app ) 中导入视图函数 . 然后 , 在urlpatterns中添加一个path ( ) 对象 , 将根URL ( '' ) 映射到views . home视图函数 , 并为其指定一个名字home . 根URL ( '' ) 也就是 127.0 .0 .1 : 8000 , 不携带任何请求地址 .
* Class-based views : 视图类 . 首先 , 从另一个应用 ( 例如other_app ) 的视图模块中导入一个基于类的视图 ( 例如Home ) . 然后 , 在urlpatterns中添加一个path ( ) 对象 , 将根URL ( '' ) 映射到Home . as_view ( ) 方法 ( 这是Django类视图的调用方式 ) , 并为其指定一个名字home .
* Including another URLconf : 包括另一个URL配置 . 首先 , 从django . urls模块中导入include ( ) 函数和path ( ) 对象 . 然后 , 在urlpatterns中添加一个path ( ) 对象 , 将 / blog / 前缀的所有URL映射到blog . urls中的URL配置 . 这意味着 , 如果有多个应用或功能区域 , 可以为每个区域创建一个单独的urls . py文件 , 并在主urls . py文件中使用include ( ) 函数来包含它们 .
path ( ) 是Django 2.0 及更高版本中引入的新函数 , 它使用了一种更简洁 , 更明确的方式来定义URL模式 , 通过内置的转换器来捕获URL中的值 .
path ( ) 函数的参数如下 : from django . urls import path
. . .
path ( route , view , kwargs = None , name = None ) 参数说明 :
* 1. route ( 必需 ) , 一个字符串 , 表示URL的路径模式 . 这个字符串可以包含字符串文字 ( 比如 / articles / ) 和一些特殊的模式匹配符号 . 可以通过转换器来捕获URL中的值 , 例如 : < int : year > 会捕获一个整数 , 并将其作为名为year的关键字参数传递给视图函数 .
* 2. view ( 必需 ) , 一个视图函数或视图类的as_view ( ) 方法的引用 . 当用户访问匹配route的URL时 , Django将调用这个视图 .
* 3. kwargs ( 可选 ) : 一个字典 , 用于向视图传递额外的关键字参数 . 这些参数在视图函数内部可以通过 * * kwargs语法接收 .
* 4. name ( 可选 ) : 一个字符串 , 用于给URL模式命名 . 这个名字可以在Django的模板 , 视图和其他地方通过reverse ( ) 函数或 { % url % } 模板标签来引用 .
下面是一个使用path函数的示例 :
from django. urls import path
from . import views urlpatterns = [ path( 'articles/<int:year>/' , views. year_archive, { 'foo' : 'bar' } , name= 'articles_year_archive' ) ,
]
在这个例子中 , path函数定义了一个URL路径模式 'articles/<int:year>/' , 该模式匹配任何以 / articles / 开头并跟随一个整数的URL .
当用户访问这样的URL时 , Django将调用views . year_archive视图函数 , 并将URL中的整数部分作为year参数传递给视图 . 此外 , 通过kwargs = { 'foo' : 'bar' } , 向视图传递了一个额外的关键字参数foo , 其值为 'bar' .
在views . year_archive视图函数中 , 可以通过 * * kwargs来接收这个参数 . 最后 , name = 'articles_year_archive' 为这个 URL 模式命名 ,
以便在Django的其他地方通过reverse ( 'articles_year_archive' , args = [ 2023 ] ) 来引用它 .
这里的args参数是一个包含要传递给视图的额外位置参数的列表 .
在Django的URL配置中 , 通常使用path转换器来定义URL模式 ,
并且这些转换器通常被视为位置参数 , 因为它们是根据在URL中出现的顺序来确定的 . 以下是一个例子 , 展示如何使用path来捕获位置参数 , 并在视图函数中接收它们 :
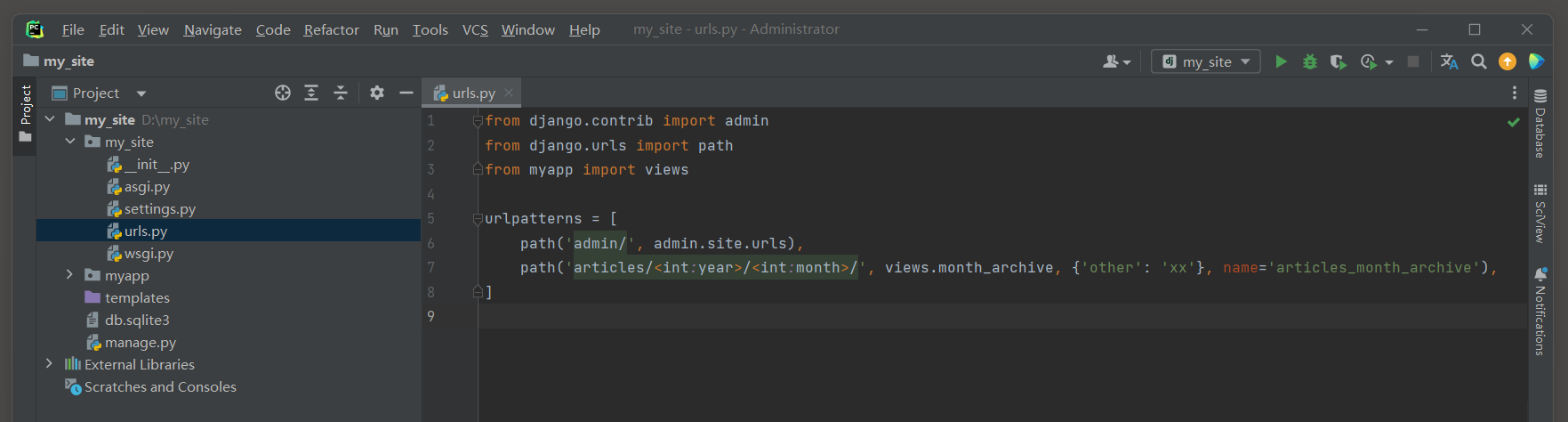
from django. contrib import admin
from django. urls import path
from myapp import viewsurlpatterns = [ path( 'admin/' , admin. site. urls) , path( 'articles/<int:year>/<int:month>/' , views. month_archive, { 'other' : 'xx' } , name= 'articles_month_archive' ) ,
]
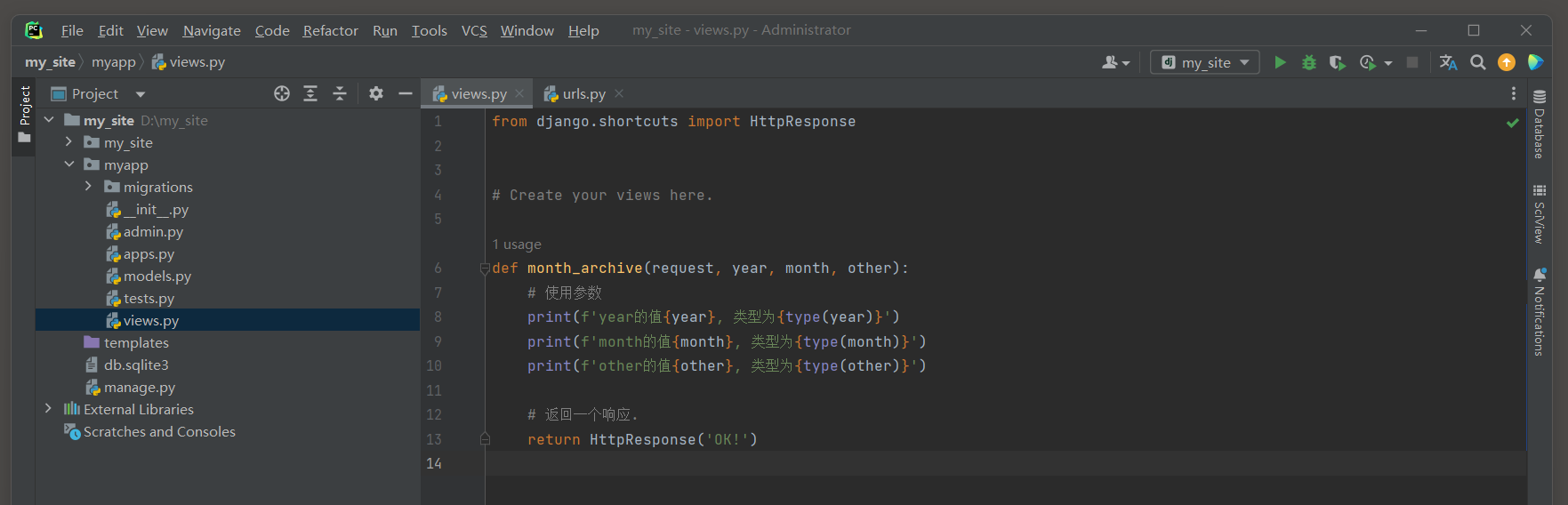
from django. shortcuts import HttpResponsedef month_archive ( request, year, month, other) : print ( f'year的值 { year} , 类型为 { type ( year) } ' ) print ( f'month的值 { month} , 类型为 { type ( month) } ' ) print ( f'other的值 { other} , 类型为 { type ( other) } ' ) return HttpResponse( 'OK!' )
在上面的例子中 , < int : year > 和 < int : month > 是URL路径中的模式匹配部分 , 它们分别捕获一个整数作为year和month .
当Django匹配到这个URL时 , 它会调用views . month_archive视图函数 , 并将捕获到的year和month值作为位置参数传递给它 . 注意 , path函数中的模式匹配部分 ( 如 < int : year > ) 定义了一个 '转换器' , 用于将URL中的文本转换为Python中的数据类型 .
在这个例子中 , int转换器将URL中的文本转换为整数 . Django还提供了其他转换器 , 如str , slug , uuid等 .
/articles/是一个固定的字符串前缀, 它不会被当作参数捕获 .
< int : year > 和 < int : month > 是URL路径转换器 , 用于捕获整数并作为参数传递给month_archive视图函数 .
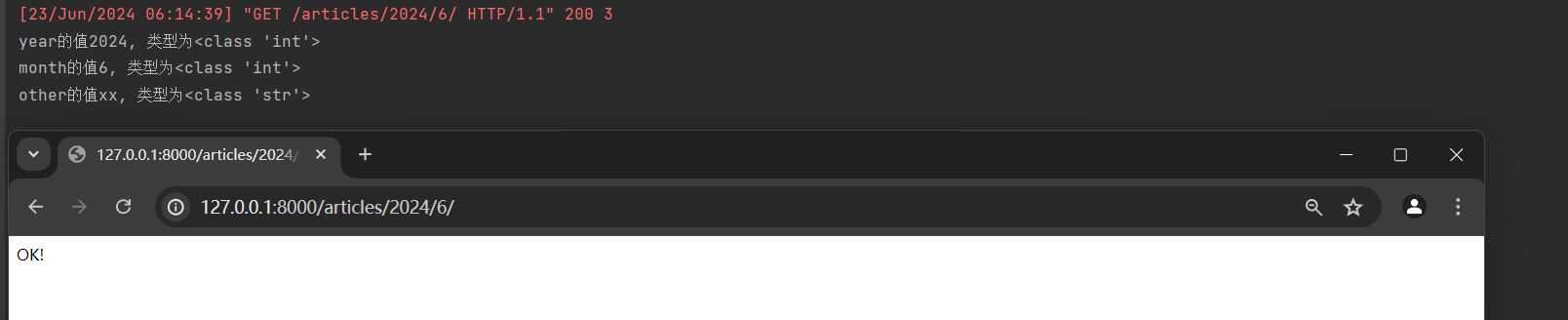
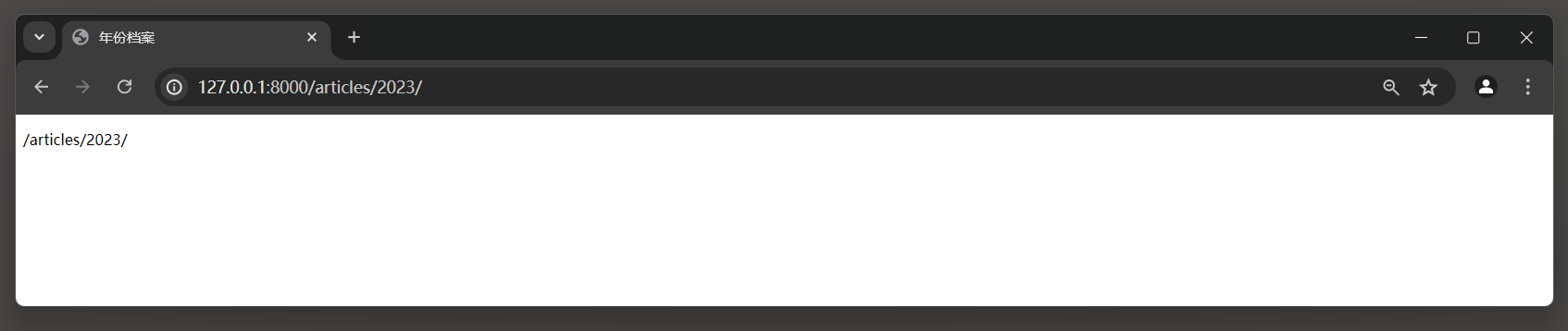
访问 : 127.0 .0 .1 : 8000 /articles/ 2024 / 6 /时, Django会将 2024 作为year参数 , 6 作为month参数传递给month_archive视图函数 .
在Django的URL配置中 , path函数允许使用转换器 ( converters ) 来匹配和捕获URL中的特定部分 .
转换器是一种特殊的语法 , 用于定义URL中某个部分应该匹配什么类型的数据 . 以下是关于URL转换器的基本规则和如何使用它们的概述 :
* 1. 使用尖括号捕获值 : 在Django的URL配置中 , 可以使用尖括号 ( < 和 > ) 来定义应该从URL中捕获的部分 . 捕获的部分将作为关键字参数传递给相应的视图函数 .
* 2. 指定转换器类型 : 在尖括号内部 , 可以指定一个转换器类型 , 用于定义捕获值的预期数据类型 . 例如 , < int : name > 表示捕获一个整数 , 并将其命名为name .
* 3. Django内置了一些常用的转换器类型 , 包括 : - str : 匹配任何非空字符串 , 但不包括斜杠 ( / ) , 如果没有指定转换器 , 则默认使用此类型 . 浮点型可以先使用字符串获取 , 在视图函数中自己转换 . - int : 匹配零或任何正整数 . - slug : 匹配由ASCII字母或数字以及连字符 ( - ) 或下划线 ( _ ) 组成的字符串 . 注意 : slug能够转换uuid . slug是一个常见的术语 , 用于描述一个简短的 , 人类可读的 , URL友好的字符串 . 它通常用于代替可能包含空格 , 特殊字符或其他非URL友好字符的更长或更复杂的字符串 , 例 : 'my site' - > 'my-site' . - uuid : 匹配格式化的UUID , 为了防止多个URL模式之间的冲突 , 必须包含连字符 ( - ) 来限制其格式 . - path : 匹配任何非空字符串 , 包括斜杠 ( / ) . 这允许你匹配完整的URL路径 . 还可以定义自己的转换器类型 , 以满足特定的需求 . 如果输入的字符串无法被转换器正确转换 , 它会直接返回一个 404 错误 , 表示找不到与请求的URL相匹配的页面 .
要使用转换器 , 需要在URL模式中的变量部分指定转换器类型 , 如下所示 :
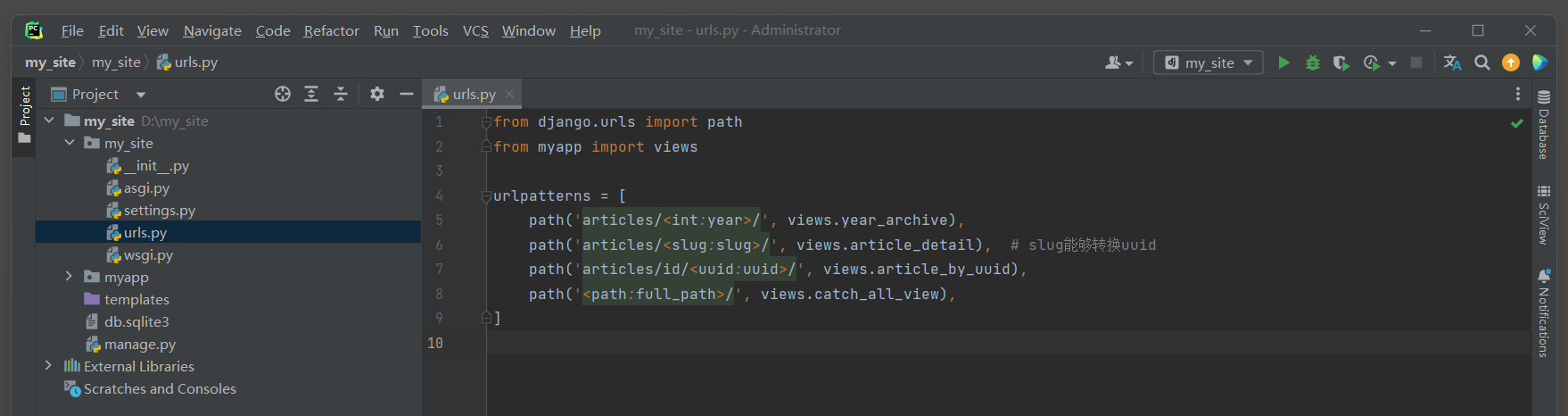
from django. urls import path
from myapp import viewsurlpatterns = [ path( 'articles/<int:year>/' , views. year_archive) , path( 'articles/<slug:slug>/' , views. article_detail) , path( 'articles/id/<uuid:uuid>/' , views. article_by_uuid) , path( '<path:full_path>/' , views. catch_all_view) ,
]
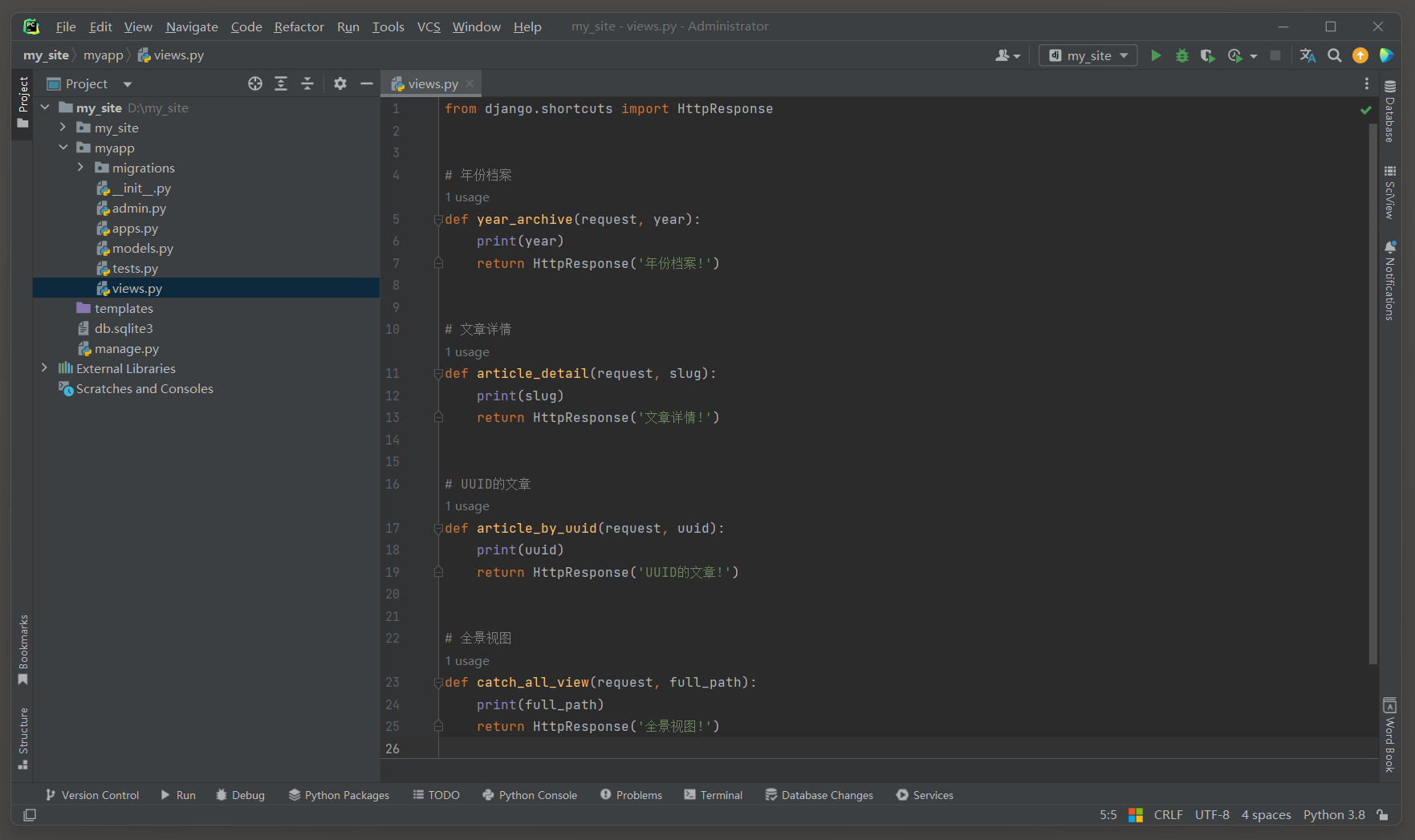
from django. shortcuts import HttpResponse
def year_archive ( request, year) : print ( year) return HttpResponse( '年份档案!' )
def article_detail ( request, slug) : print ( slug) return HttpResponse( '文章详情!' )
def article_by_uuid ( request, uuid) : print ( uuid) return HttpResponse( 'UUID的文章!' )
def catch_all_view ( request, full_path) : print ( full_path) return HttpResponse( '全景视图!' )
测试 1 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2024 / , 调用views . year_archive视图 ,
视图将接收一个名为year的关键字参数 , 它是一个整数 .
测试 2 , 访问 : 127.0 .0 .1 : 8000 /articles/my-blog/ , 调用views . article_detail视图 ,
视图将接收一个名为slug的关键字参数 , 它是一个slug字符串 .
测试 3 , 访问 : http : / / 127.0 .0 .1 : 8000 /articles/id/f47ac10b- 58 cc- 4372 -a567- 0e02 b2c3d479 / , 调用views . article_by_uuid视图 ,
视图将接收一个名为uuid的关键字参数 , 它是一个UUID字符串 .
测试 4 , 访问 : http : / / 127.0 .0 .1 : 8000 /vip/login/?user=kid&pwd= 123 , 调用views . catch_all_view视图 ,
视图将接收一个名为full_path的关键字参数 , 它是一个包含整个URL路径的字符串 .
re_path ( ) ( 之前叫做url ( ) ) 使用标准的Python正则表达式字符串来定义URL模式 .
这对于需要更复杂的URL匹配模式的情况非常有用 , 与path ( ) 函数相比 , re_path ( ) 提供了更多的灵活性和控制能力 .
它提供了更多的灵活性 , 但也可能使URL模式更难以阅读和维护 .
在Python字符串中使用正则表达式时 , 前面的r或R前缀表示这是一个原始字符串 ( raw string ) .
在原始字符串中 , 反斜杠 \ 不会被当作转义字符 . 这对于正则表达式来说很有用 , 因为正则表达式经常使用反斜杠作为转义字符 .
对于Django的path ( ) , 通常不需要原始字符串 , 因为它不使用正则表达式 .
但对于re_path ( ) , 如果正则表达式中使用了反斜杠 , 那么使用原始字符串是个好习惯 , 以避免转义字符的干扰 .
正则表达式中的 ^ 符号表示字符串的开始 , 而$符号表示字符串的结束 .
当定义一个URL模式时 , 以 ^ 开头确保了这个模式只从URL路径的开始处进行匹配 , 而以$结尾则确保了这个模式必须匹配到URL路径的末尾 .
这样 , 可以精确地控制整个URL路径应该与模式完全匹配 .
例如 , 如果有一个URL模式定义为 :
from django. urls import re_path urlpatterns = [ re_path( r'^url_pattern/$' , view_function, name= 'name' ) ,
]
r '^url_pattern/$' : 正则表达式字符串 , 表示要匹配的URL模式 . 其他参数与path ( ) 函数相同 .
这个模式只会匹配完整的URL路径 '/url_pattern/' , 而不会匹配到类似 '/url_pattern/something_else' 这样的路径 ,
因为后者在 'url_pattern/' 后面还有额外的字符 , 而$符号要求匹配必须在此结束 .
如果不使用$结尾 , 比如定义为r '^url_pattern/' , 那么这个模式将会匹配任何以 '/url_pattern/' 开头的URL ,
例如 '/url_pattern/' , '/url_pattern/extra' , '/url_pattern/anything/else' 等都会被这个模式匹配 ,
这可能不是你想要的结果 , 特别是有其他URL模式需要以 '/url_pattern/' 作为前缀时 .
因此 , 使用$结尾可以帮助你精确地定义URL模式 , 并确保只有完全符合该模式的URL才会被匹配 .
使用re_path ( ) 时 , 可以使用正则表达式和圆括号来捕获值 , 并使用?P < name > 语法来命名它们 .
from django. urls import re_path
from . import views urlpatterns = [ re_path( r'^articles/(?P<year>\d+)/$' , views. year_archive, name= 'year_archive' ) ,
]
在这个例子中 , 正则表达式r '^articles/(?P<year>\d+)/$' 定义了一个URL模式 , 该模式匹配以 / articles / 开头 ,
后面跟着一个或多个数字 ( \ d + ) , 并且后面没有其他字符 ( $表示字符串的结尾 ) 的URL .
数字部分被 ( ?P < year > \ d + ) 捕获 , 并命名为year . 当Django收到一个匹配这个URL模式的请求时 , 它会调用views . year_archive视图 , 并将捕获的年份作为名为year的关键字参数传递给它 .
例如 , 如果请求的URL是 / articles / 2023 /, 那么year_archive视图将收到一个名为year的参数 , 其值为 2023.
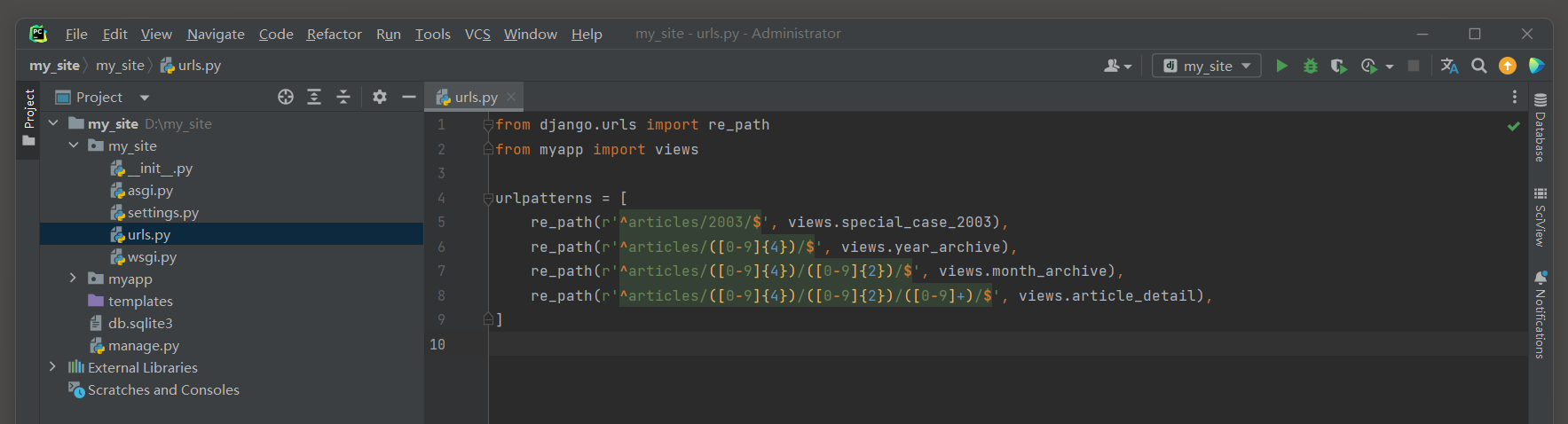
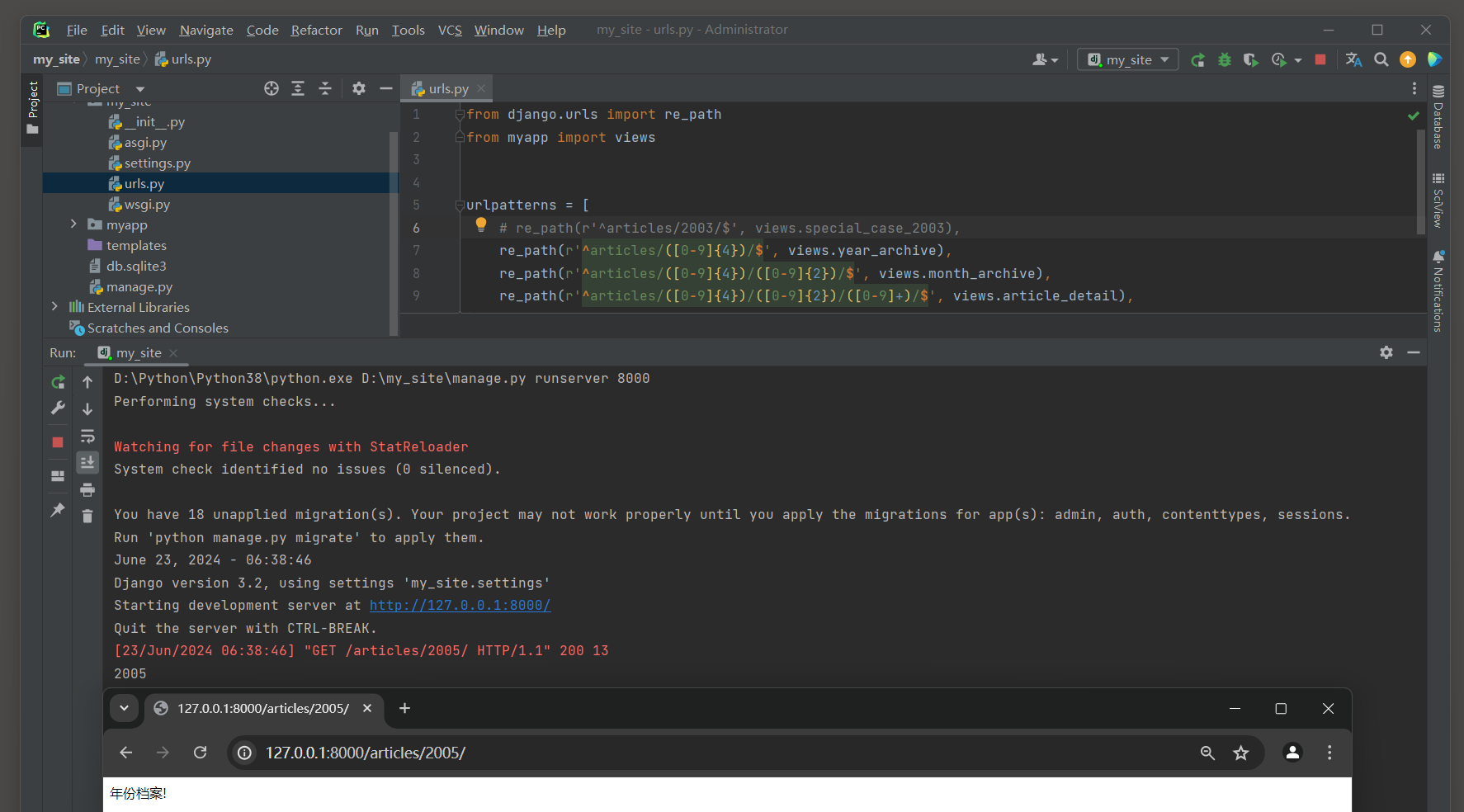
from django. urls import re_path
from myapp import viewsurlpatterns = [ re_path( r'^articles/2003/$' , views. special_case_2003) , re_path( r'^articles/([0-9]{4})/$' , views. year_archive) , re_path( r'^articles/([0-9]{4})/([0-9]{2})/$' , views. month_archive) , re_path( r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$' , views. article_detail) ,
]
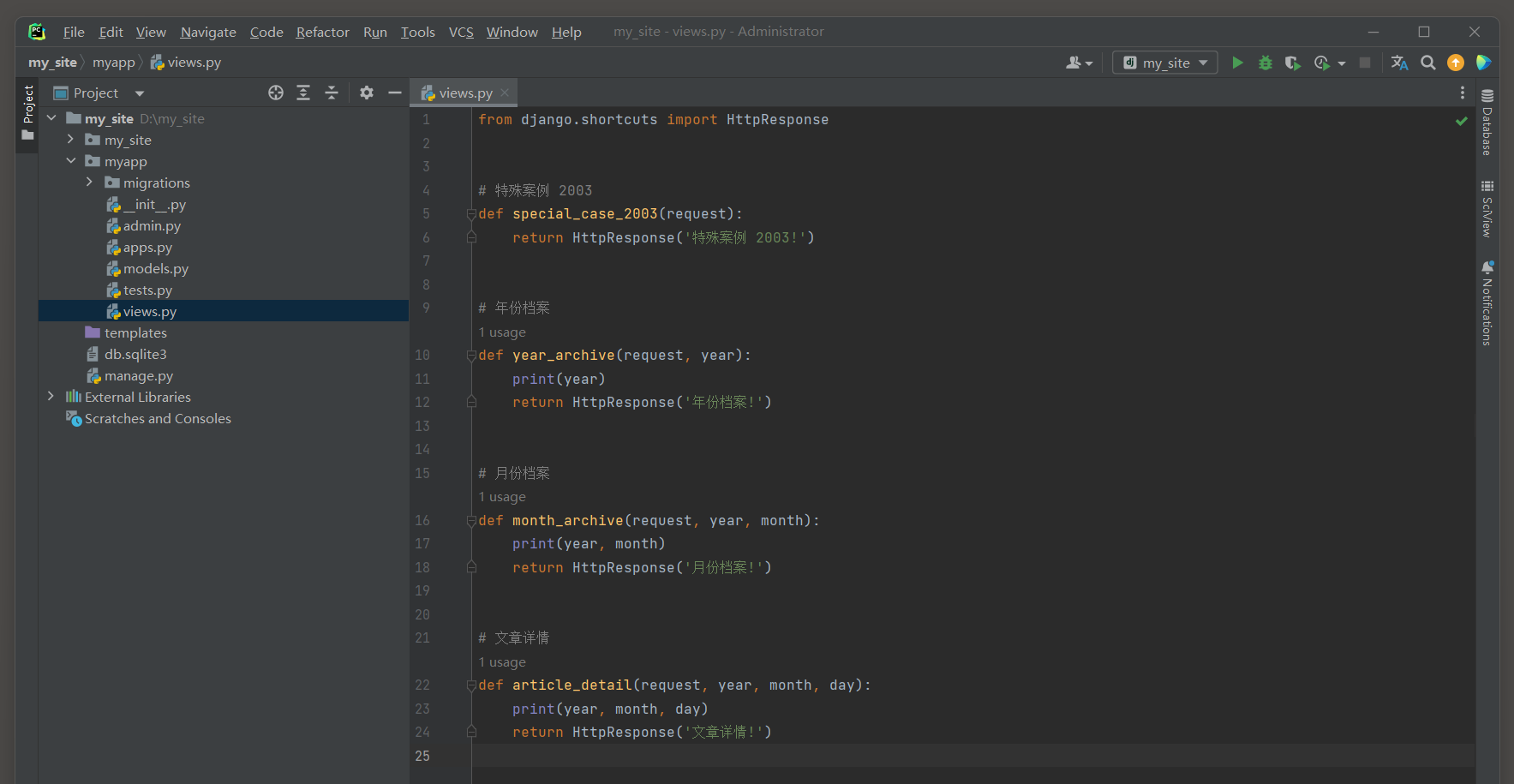
from django. shortcuts import HttpResponse
def special_case_2003 ( request) : return HttpResponse( '特殊案例 2003!' )
def year_archive ( request, year) : print ( year) return HttpResponse( '年份档案!' )
def month_archive ( request, year, month) : print ( year, month) return HttpResponse( '月份档案!' )
def article_detail ( request, year, month, day) : print ( year, month, day) return HttpResponse( '文章详情!' )
列举一些请求对URL匹配和视图调用进行更详细的解释 :
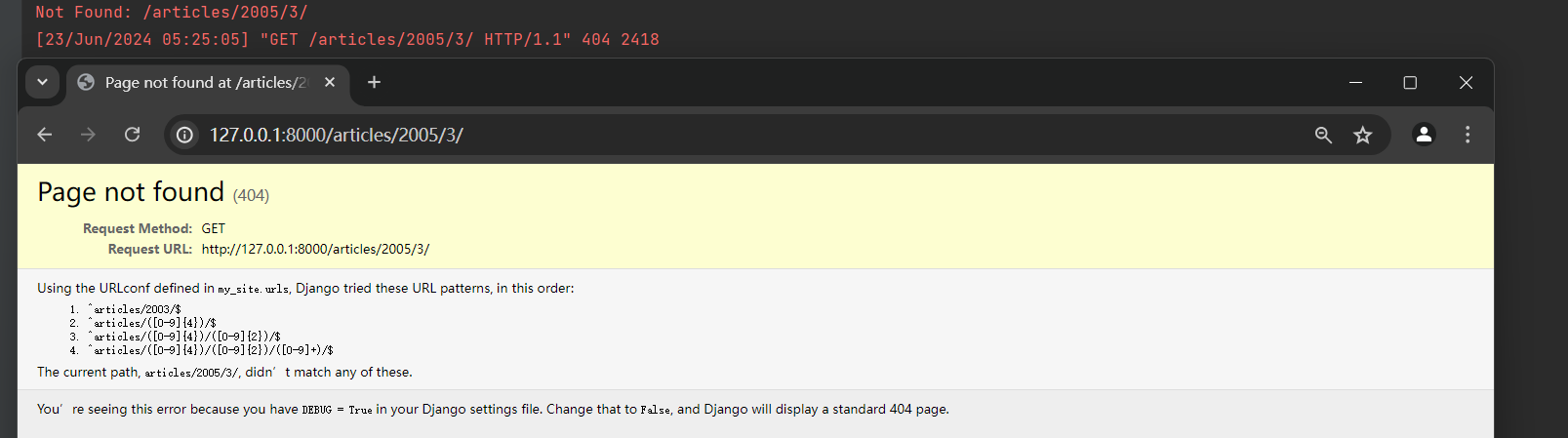
* 1. /articles/ 2005 / 03 / 请求 : 这个请求会匹配到列表中的第三个模式 . Django将调用 views . month_archive ( request , '2005' , '03' ) , 其中 '2005' 和 '03' 是从URL中捕获到的年份和月份 .
* 2. /articles/ 2005 / 3 / 请求 : 这个请求不匹配任何URL模式 , 因为第三个模式要求月份必须是两个数字 . Django会返回一个 404 页面 ( Page not found ( 404 ) ) , 因为它没有找到匹配的URL模式 .
* 3. /articles/ 2003 / 请求 : 这个请求会匹配到列表中的第一个模式而不是第二个模式 . 因为模式是按顺序匹配的并且第一个模式首先测试匹配成功 . Django将调用 views . special_case_2003 ( request ) .
* 4. /articles/ 2003 请求 ( 没有末尾的反斜杠 ) : 如果APPEND_SLASH设置是True ( Django的默认设置 ) , Django会尝试自动重定向到 / articles / 2003 /. 如果这个重定向被允许 ( 比如 , 没有中间件阻止它 ) , 那么它会再次尝试匹配URL模式 , 这次会匹配到第一个模式 . Django将调用 views . special_case_2003 ( request ) 。 如果APPEND_SLASH被设置为False或者重定向被阻止 , Django会返回一个 404 页面 .
* 5. /articles/ 2003 / 03 / 03 / 请求 : 这个请求会匹配到列表中的最后一个模式 . Django将调用views . article_detail ( request , '2003' , '03' , '03' ) , 其中 '2003' , '03' 和 '03' 是从URL中捕获到的年份 , 月份和文章ID ( 或其他标识符 ) . 请注意 , 对于捕获的URL参数 , Django默认会作为位置参数传递给视图函数 .
如果想要将它们作为关键字参数传递 , 需要在视图中指定默认参数或重写URL配置以使用命名捕获组 .
命名捕获组是在path ( ) 中使用转换器 , 而re_path ( ) 使用位置参数和圆括号捕获组 .
测试 1 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2005 / 03 / .
测试 2 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2005 / 3 / .
在Django框架中 , DEBUG设置控制了Django项目的调试模式 .
当在settings . py文件中设置DEBUG = True时 , Django会提供更详细的错误信息 , 并且这些错误信息会以HTML页面的形式返回给浏览器 .
这有助于开发者在开发过程中快速定位和解决问题 . 然而 , 将DEBUG设置为True也会带来一些安全风险 , 因为它会暴露项目的内部结构和可能的敏感信息 .
因此 , 在生产环境中部署Django应用时 , 强烈建议将DEBUG设置为False .
另外 , 如果希望在生产环境中仍然能够捕获并记录错误信息 , 而不是直接显示给用户 ,
可以考虑使用Django的日志系统或其他第三方错误跟踪服务来监控和记录错误 . 遇到了页面形式的错误信息 , 可以按照以下步骤进行解决错误 :
* 1. 查看错误信息 : 仔细阅读错误信息 , 了解错误的原因 . Django通常会提供详细的错误描述和堆栈跟踪 , 帮助定位问题所在 .
* 2. 检查代码 : 根据错误信息中提供的线索 , 检查你的代码 . 可能是某个视图函数出现了问题 , 或者是模板中的某个变量没有正确传递 .
* 3. 修复问题 : 一旦找到问题所在 , 进行相应的修复 . 可能是修改代码逻辑 , 添加必要的错误处理或者调整配置 .
* 4. 测试 : 在修复问题后 , 重新运行项目并测试以确保问题已经解决 .
测试 3 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2003 / .
测试 4 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2003 .
测试 5 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2005 / 03 / 03 / .
测试 6 , 注销路由 : re_path ( r '^articles/2003/$' , views . special_case_2003 ) ,
访问 : 127.0 .0 .1 : 8000 /articles/ 2005 / .
在正则表达式中 , 命名捕获组 ( 有名分组 ) 是一种特殊类型的捕获组 , 它允许你为捕获的内容分配一个名字 ,
这样在后续处理时可以更容易地通过名字来引用捕获的内容 .
在Django的URL配置中 , 使用re_path函数来定义URL模式时 , 命名捕获组特别有用 ,
因为它们允许你以更具可读性的方式将匹配到的URL部分传递给视图函数 . 命名捕获组的语法是在正则表达式中使用 ( ?P < name > pattern ) , 其中name是你给捕获组命名的名称 , pattern是要匹配的正则表达式模式 .
捕获的值会作为关键字参数 ( keyword arguments_传递给相应的视图函数 .
以下是一个使用命名捕获组的例子 :
from django. urls import re_path
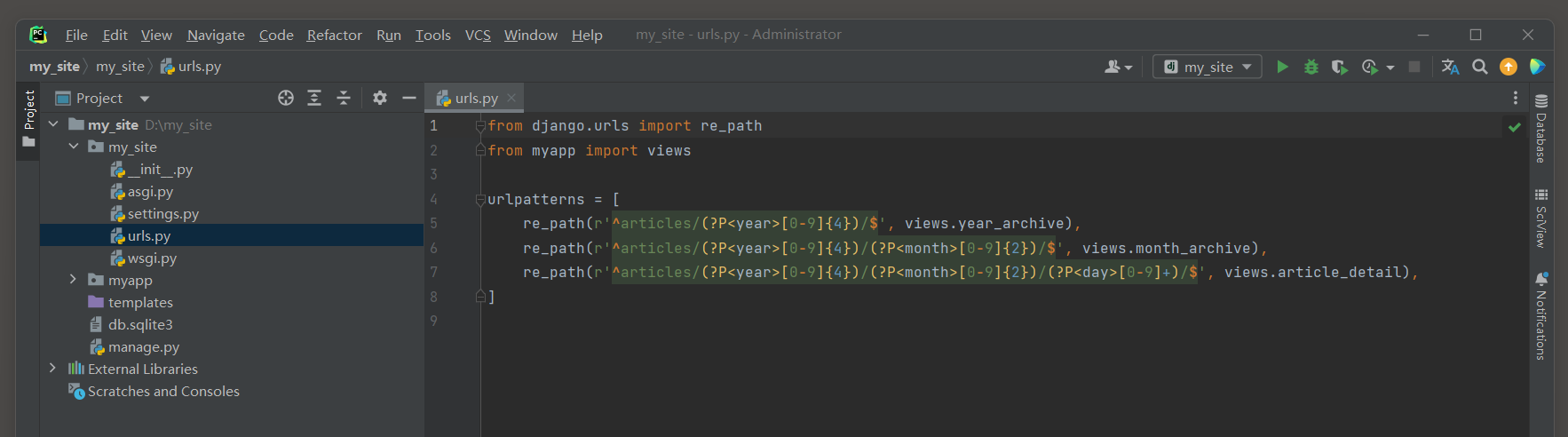
from myapp import viewsurlpatterns = [ re_path( r'^articles/(?P<year>[0-9]{4})/$' , views. year_archive) , re_path( r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$' , views. month_archive) , re_path( r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]+)/$' , views. article_detail) ,
]
from django. shortcuts import HttpResponse
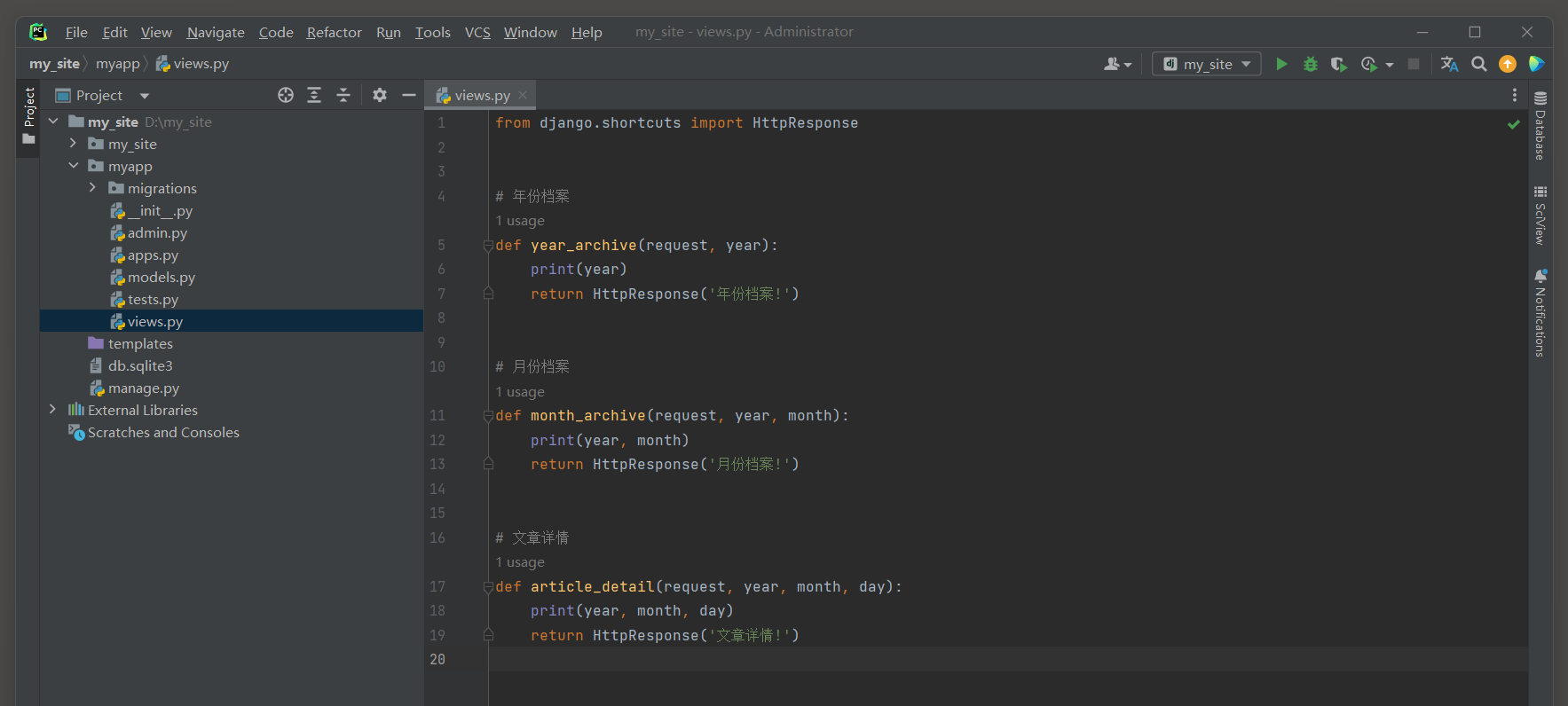
def year_archive ( request, year) : print ( year) return HttpResponse( '年份档案!' )
def month_archive ( request, year, month) : print ( year, month) return HttpResponse( '月份档案!' )
def article_detail ( request, year, month, day) : print ( year, month, day) return HttpResponse( '文章详情!' )
启动项目 , 分别访问 :
127.0 .0 .1 : 8000 /articles/ 2024 / ,
127.0 .0 .1 : 8000 /articles/ 2024 / 06 / ,
127.0 .0 .1 : 8000 /articles/ 2024 / 06 / 23 / .
在Django中 , URL末尾的反斜杠 ( / ) 不是必须的 , Django会在用户省略了末尾的反斜杠时自动尝试重定向到带有反斜杠的URL .
使用上例代码测试 , 启动项目 , 分别访问 :
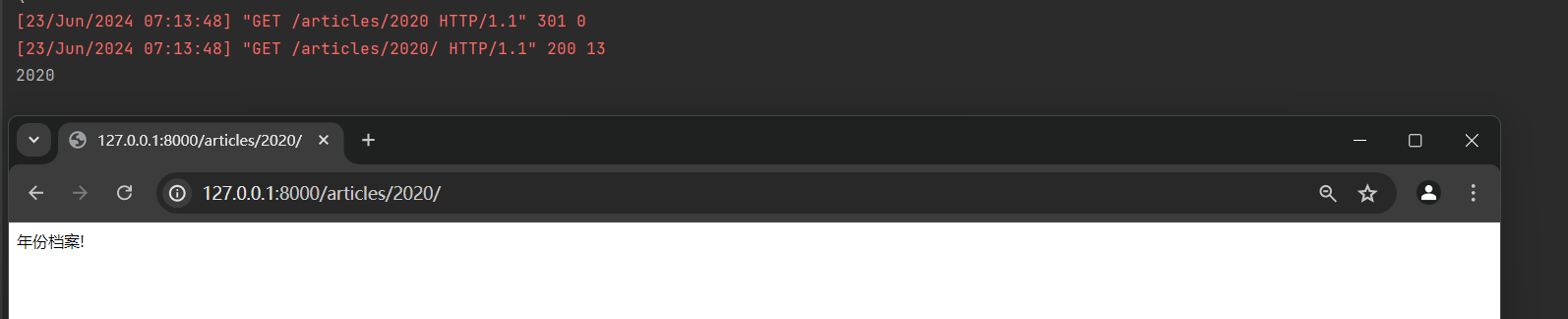
127.0 .0 .1 : 8000 /articles/ 2024 / ,
127.0 .0 .1 : 8000 /articles/ 2020 .
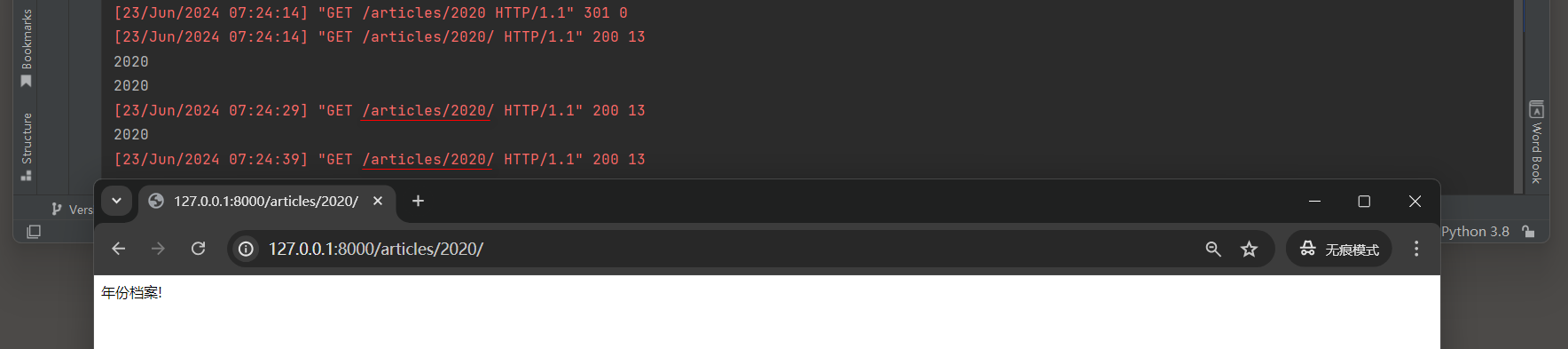
后续你在浏览器中直接输入 : 127.0 .0 .1 : 8000 /articles/ 2020 而没有末尾斜杠时 , 浏览器自动加上了斜杠 ,
这是因为浏览器记住了之前的重定向行为 , 并尝试通过修改URL来避免将来再次发生重定向 .
这通常是浏览器为了改善用户体验而做的优化 , 因为重定向会增加请求的延迟 . 浏览器自动添加斜杠的行为与缓存机制没有直接关系 .
这是浏览器处理重定向的一种策略 , 而不是通过缓存来实现的 .
即使你禁用了缓存 , 浏览器仍然会记住之前的重定向行为 , 并尝试在后续请求中自动修正URL , 以避免不必要的重定向 .
如果不想实现自动实现可以在配置文件中设置 : APPEND_SLASH = False , 这将修改Django的默认追加反斜杆的行为 .
在Django的urlpatterns列表中 , URL模式是按照列表中的顺序从上往下逐一进行匹配的 .
一旦找到一个匹配成功的URL模式 , Django就会停止继续查找并调用与该模式关联的视图函数或类 . 这意味着 , 如果有两个具有重叠或相似正则表达式的URL模式 , 并且它们被定义在urlpatterns中的顺序不当 ,
那么可能会导致期望的视图函数或类没有被调用 , 而是调用了在列表中位置更靠前但匹配不那么精确的模式所对应的视图 . 为了避免这种情况 , 应该尽可能的使URL模式具有明确的区分度 , 避免使用过于宽泛的正则表达式 .
将更具体 , 更精确的URL模式放在列表的前面 , 而将更宽泛 , 更通用的模式放在后面 .
下面是一个具体的例子 , 说明了为什么顺序很重要 , 以及如何组织它们以避免潜在的问题 .
假设我们有一个网站 , 它有两个视图 : 一个用于显示博客文章的详细页面 , 另一个用于显示所有文章列表的页面 .
博客文章URL通常会有ID , 而文章列表页面的URL是固定的 .
如果我们不按照最佳实践来定义URL模式 , 可能会遇到不期望的行为 .
以下是一个可能导致问题的例子 :
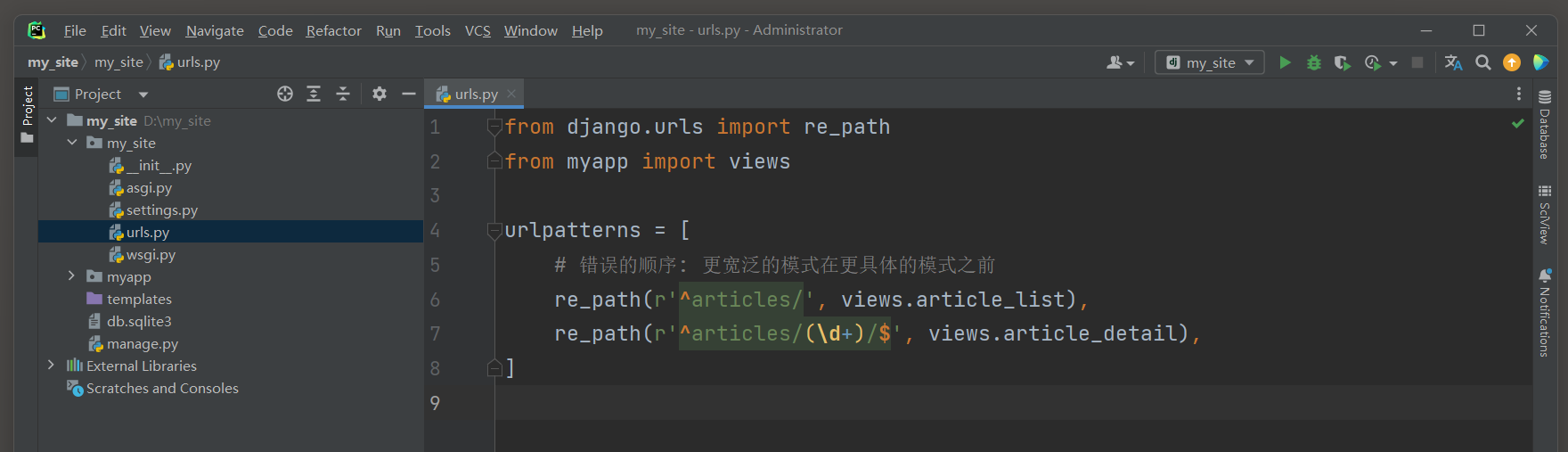
from django. urls import re_path
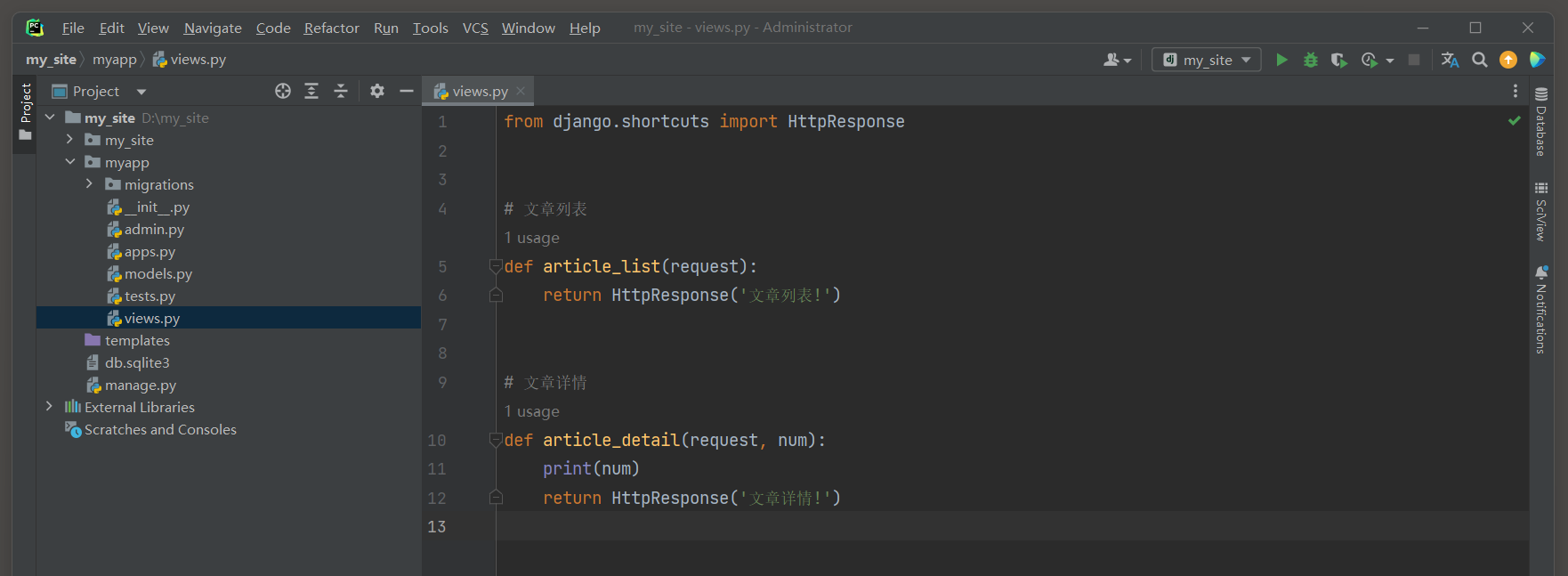
from myapp import viewsurlpatterns = [ re_path( r'^articles/' , views. article_list) , re_path( r'^articles/(\d+)/$' , views. article_detail) ,
]
from django. shortcuts import HttpResponse
def article_list ( request) : return HttpResponse( '文章列表!' )
def article_detail ( request, num) : print ( num) return HttpResponse( '文章详情!' )
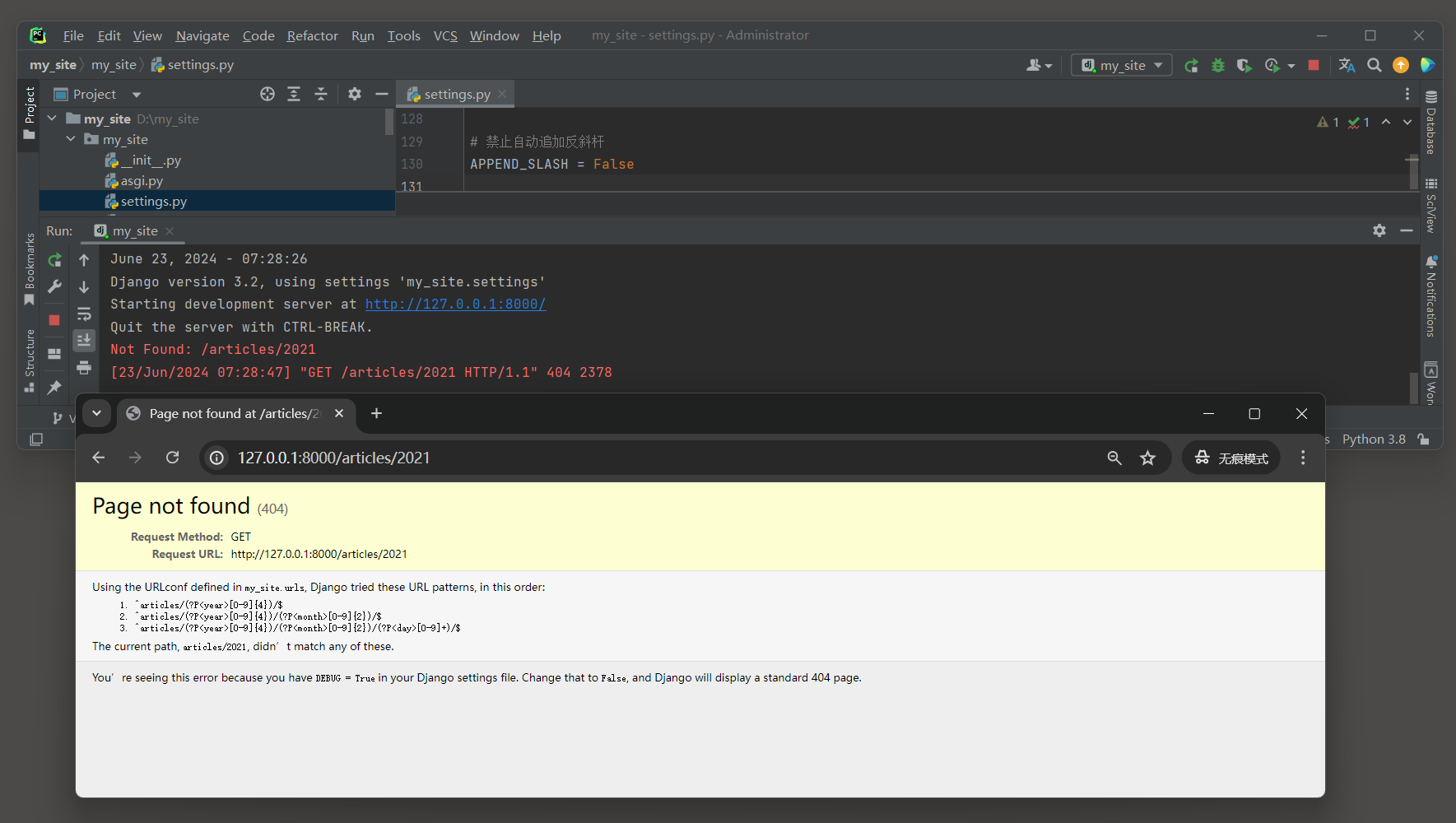
在上述例子中 , 如果尝试访问一个具体文章的URL , 如 '/articles/123/' , Django会首先尝试匹配第一个模式 '^articles/' ,
但这个模式只匹配到URL的根路径 '/articles/' , 并不包含后面的ID .
然而 , 由于Django会按照urlpatterns列表中的顺序进行匹配 , 并且一旦找到匹配项就会停止查找 ,
所以即使第二个模式 '^articles/(\d+)/$' 实际上是一个更精确的匹配 , 它也不会被调用 .
启动项目访问 : http : / / 127.0 .0 .1 : 8000 /articles/ 123 / , 调用views . article_list视图 .
为了避免这种情况 , 应该将更具体 , 更精确的URL模式放在列表的前面 , 而将更宽泛 , 更通用的模式放在后面 :
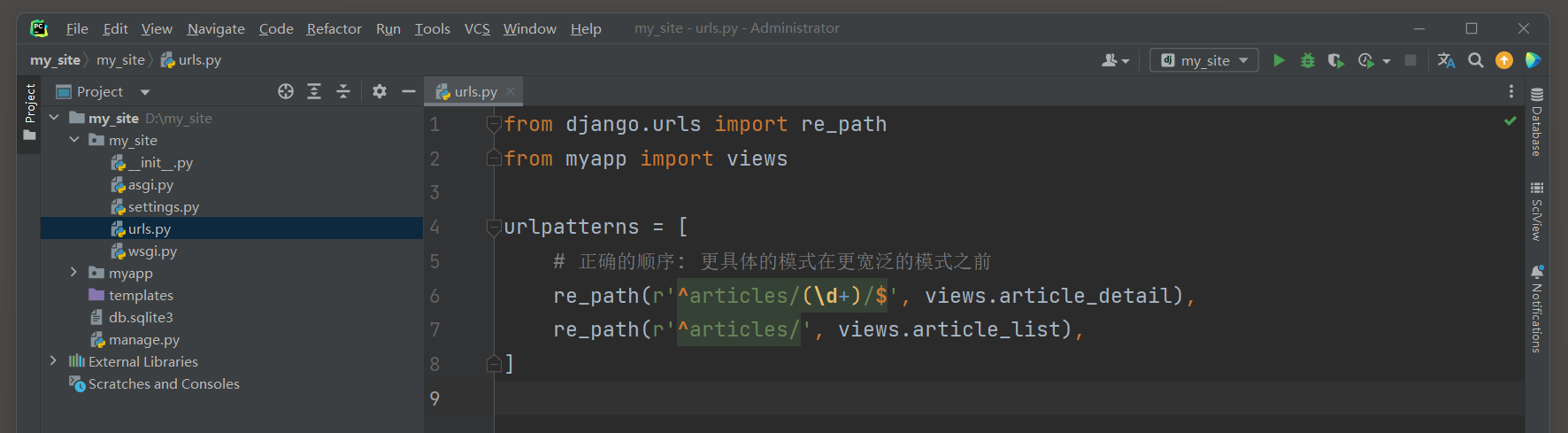
from django. urls import re_path
from myapp import viewsurlpatterns = [ re_path( r'^articles/(\d+)/$' , views. article_detail) , re_path( r'^articles/' , views. article_list) ,
]
现在 , 当尝试访问 '/articles/123/' 时 , Django会首先尝试匹配 '^articles/(\d+)/$' , 这是一个更具体的模式 , 并且会成功匹配到 .
因此 , 它会调用views . article_detail视图来处理这个请求 , 这是我们所期望的 .
启动项目访问 : http : / / 127.0 .0 .1 : 8000 /articles/ 123 / , 调用views . article_detail视图 .
在Django中 , 路由分发 ( URLconf ) 是一个非常重要的概念 , 它允许你将URL模式映射到Python的视图函数或类视图 ( 基于类的视图 ) .
当Django项目变得越来越大 , 包含多个应用 ( app ) 时 , 使用路由分发可以使URL配置更加模块化和可维护 .
以下是使用路由分发的基本步骤 :
* 1. 在每个应用中定义URL模式 : 在应用目录 ( 比如myapp / ) 下 , 创建一个名为urls . py的文件 , 并在其中定义该应用的URL模式 .
* 2. 在主项目的urls . py中进行路由分发 : 在Django项目目录下 , 找到并编辑urls . py文件 . 使用include ( ) 函数来包含其他应用的URL配置 .
from django. urls import path
from . import views urlpatterns = [ path( 'my_view/' , views. my_view) ,
]
from django. shortcuts import HttpResponsedef my_view ( request) : return HttpResponse( 'my_site!' )
from django. contrib import admin
from django. urls import include, path urlpatterns = [ path( 'admin/' , admin. site. urls) , path( 'myapp/' , include( 'myapp.urls' ) ) ,
]
现在 , 当用户访问 : 127.0 .0 .1 : 8000 /myapp/my_view/时, Django将查找myapp . urls中的URL模式 , 并调用myapp . views . my_view视图函数 .
当Django处理一个请求时 , 它会从根urlpatterns列表开始 , 按照定义的顺序查找匹配的URL模式 .
如果它找到一个include ( ) 函数 , Django会临时切换到该include ( ) 所指向的应用的urlpatterns列表 , 并在那个列表中进行查找 .
Django的路由分发功能是非常灵活的 , 不仅限于应用 ( app ) 级别 .
可以在任何urls . py文件中使用include ( ) 函数来组织URL模式 , 以便更好地管理URL配置 . 多层路由分发是在Django项目中 , 为了组织和管理复杂的URL路由结构而采用的一种技术 .
当项目中的URL路由变得非常多和复杂时 , 将路由配置分解为多个文件 , 并在主路由配置文件中使用include ( ) 函数将它们包含进来 ,
可以使路由结构更清晰 , 易于维护 .
在Django中 , 可以创建多个urls . py文件 , 并在它们之间创建层次结构 , 从而实现多层路由分发 .
以下是一个简单的例子来说明这个概念 .
项目级别的urls . py : 这是项目的根路由配置文件 , 通常位于项目的根目录下 .
这个文件会包含一些基本的路由 , 以及使用include ( ) 函数包含其他应用的路由 .
from django. urls import include, path urlpatterns = [ path( 'app1/' , include( 'app1.urls' ) ) , path( 'app2/' , include( 'app2.urls' ) ) ,
]
应用级别的urls . py : 每个Django应用都可以有自己的urls . py文件 , 通常位于应用的目录下 .
这个文件会包含该应用特有的URL路由 .
from django. urls import path
from . import views urlpatterns = [ path( '' , views. app1_index) , path( 'detail/<int:pk>/' , views. app1_detail) ,
]
子应用或模块的urls . py ( 可选 ) : 如果应用很大 , 还可以进一步将路由配置分解为子模块或子应用的urls . py文件 .
这有助于进一步组织和管理URL路由 .
from django. urls import path
from . import views urlpatterns = [ path( '' , views. subapp_index, ) ,
]
多层路由分发是Django中一种强大的工具 , 可以帮助组织和管理大量的URL路由 .
但是过度嵌套可能会使URL配置变得难以理解和维护 , 所以应该谨慎使用 .
在使用Django项目时 , 一个常见的需求是获得URL的最终形式 ,
以用于嵌入到生成的内容中 ( 视图中和显示给用户的URL等 ) 或者用于处理服务器端的导航 ( 重定向等 ) . 在Django中 , 强烈建议避免硬编码URL ( 手写完整的URL字符串 ) , 因为这既费力又容易出错 .
当URL结构发生变化时 , 需要手动更新所有硬编码的URL , 这会导致大量的维护工作 . 相反 , Django提供了反向解析 ( Reverse URL Resolution ) 机制 , 这是一种与URL配置 ( URLconf ) 紧密集成的URL生成方法 .
使用反向解析 , 可以根据URL的名称和可选参数动态地生成URL , 而无需关心具体的URL路径 .
这样 , 即使URL结构发生变化 , 只需更新URL配置 , 而无需在整个项目中搜索和替换硬编码的URL . 反向解析通常通过django . urls . reverse ( ) 函数或模板中的 { % url % } 标签来实现 .
在Django的URL配置中 , path ( ) 函数的name参数可以为URL进行 '命名' ( naming ) .
这个命名允许你在Django模板 , 视图或其他地方通过名称来引用特定的URL模式 , 而不是硬编码URL字符串 .
from django. contrib import admin
from django. urls import path, includeurlpatterns = [ path( 'admin/' , admin. site. urls) , path( 'myapp/' , include( 'myapp.urls' ) ) ,
]
from django. urls import path
from . import viewsurlpatterns = [ path( 'articles/<int:year>/' , views. year_archive, name= 'year_archive' )
] 上例中 : path ( 'articles/<int:year>/' , views . year_archive , name = 'year_archive' ) ,
定义一个URL模式 , 它接受一个整数作为year参数 , 并映射到views . year_archive视图 .
同时 , 给这个URL模式起了一个名字year_archive .
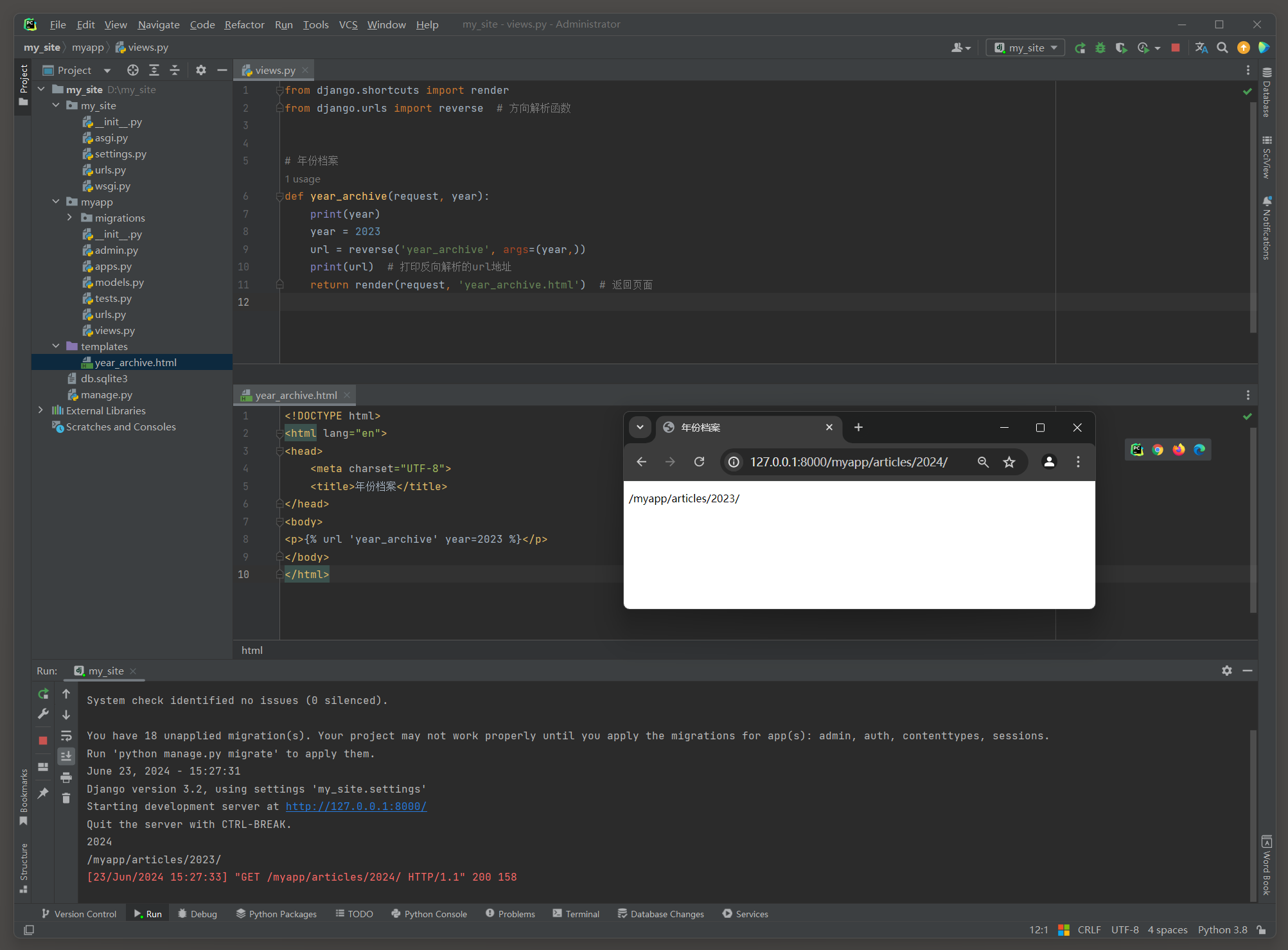
from django. shortcuts import render
from django. urls import reverse
def year_archive ( request, year) : print ( year) year = 2023 url = reverse( 'year_archive' , args= ( year, ) ) print ( url) return render( request, 'year_archive.html' ) 在Django视图中 , 根据这个名称使用可django . urls . reverse ( ) 函数生成URL .
在视图中使用reverse ( ) 函数时 , 需要传递一个元组args来匹配URL模式中的变量 ( 如果有的话 ) .
在上面的例子中 , 传递了一个包含year的元组作为参数 .
如果URL模式包含关键字参数 ( re_path的命名捕获组 ) , 可以使用kwargs代替args .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < p> </ p> </ body> </ html> 在Django模板中 , 根据这个名称使用 { % url % } 模板标签生成URL .
例如 : < p > { % url 'year_archive' year = 2023 % } < / p >
在这个例子中 , Django将查找名为year_archive的URL模式 ,
并使用提供的参数 ( 在这里是 2023 ) 来填充 < int : year > 部分 , 从而生成完整的URL .
名称空间 ( namespace ) 在Django中通常用于处理URL的命名空间冲突 , 特别是在使用include ( ) 函数将URL配置分割成多个小文件时 .
通过为不同的URL配置设置不同的名称空间 , 可以确保相同的URL名称在不同的配置中不会发生冲突 .
可以在include ( ) 函数中使用namespace参数来定义命名空间 .
from django. contrib import admin
from django. urls import path, includeurlpatterns = [ path( 'admin/' , admin. site. urls) , path( 'myapp1/' , include( 'myapp.urls' , namespace= 'myapp1' ) ) , path( 'myapp2/' , include( 'myapp.urls' , namespace= 'myapp2' ) ) ,
] 然后 , 在模板或视图中引用URL时 , 可以使用 { % url 'myapp1:my_view' % } 或reverse ( 'myapp1:my_view' ) 来区分它们 . zb
在Django中 , 如果没有使用命名空间 ( namespace ) , 当多个应用中的URL模式使用相同的名称时 , 就会发生名称冲突 .
以下是一个冲突的例子 :
假设有两个Django应用 , app1和app2 , 每个应用都有自己的urls . py文件 , 并且没有在项目的根urls . py文件中使用命名空间 .
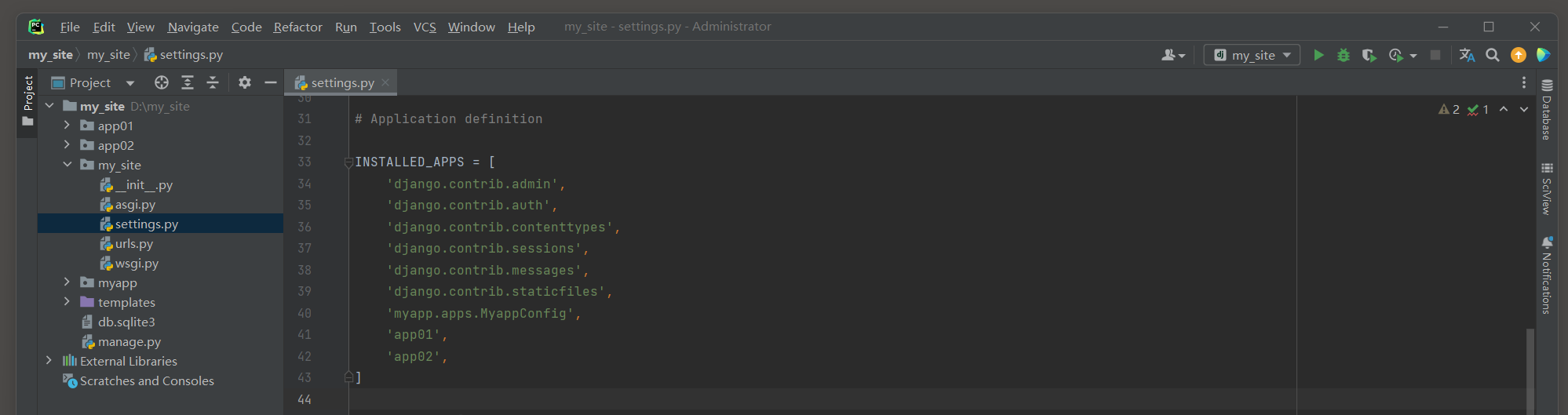
PS D: \my_site> django- admin startapp app01
PS D: \my_site> django- admin startapp app02
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'myapp.apps.MyappConfig' , 'app01' , 'app02' ,
]
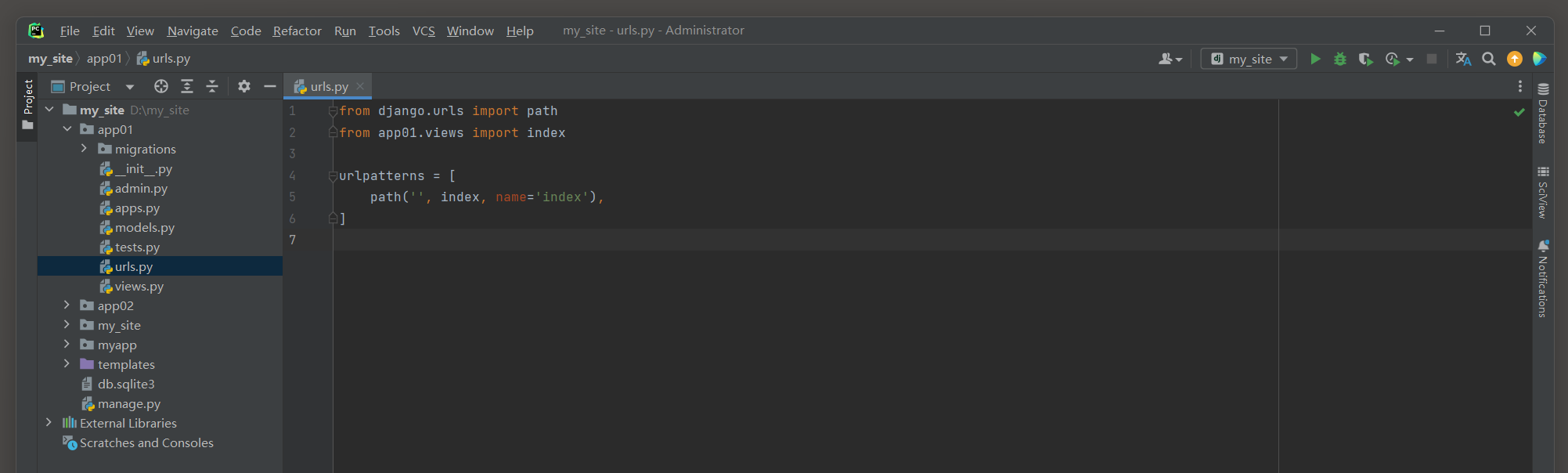
from django. urls import path
from app01. views import index urlpatterns = [ path( '' , index, name= 'index' ) ,
]
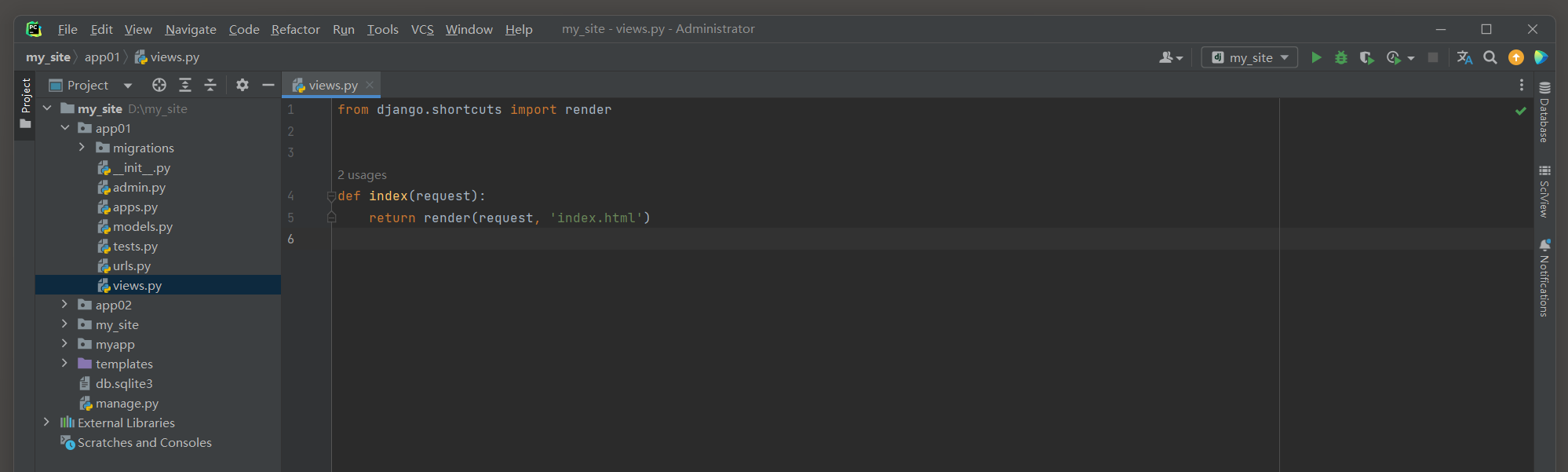
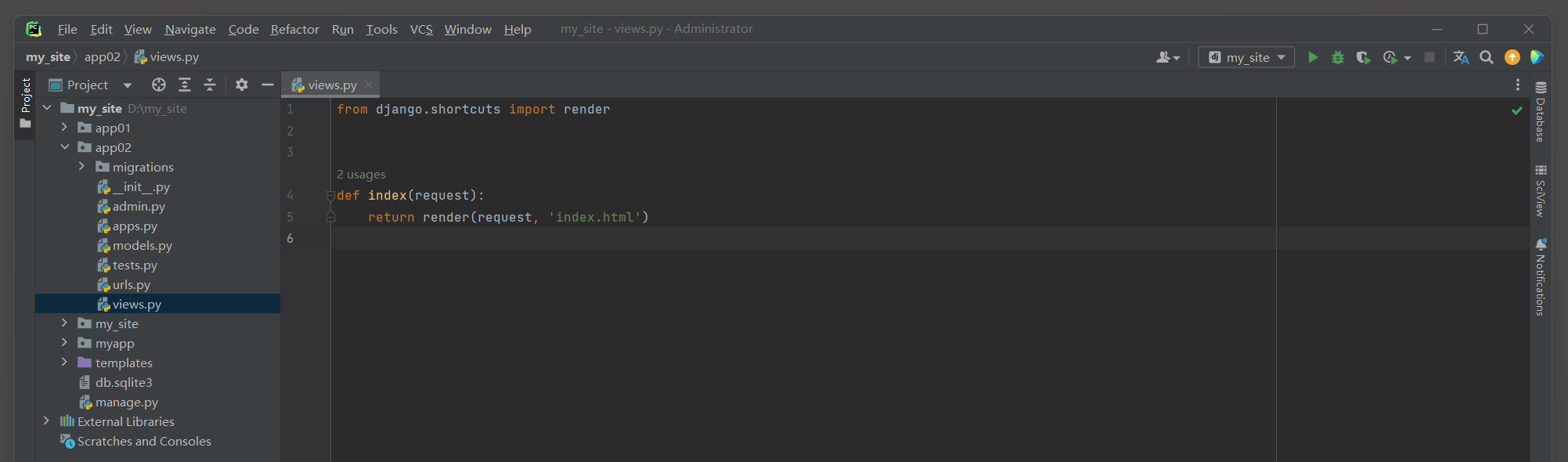
from django. shortcuts import renderdef index ( request) : return render( request, 'index.html' )
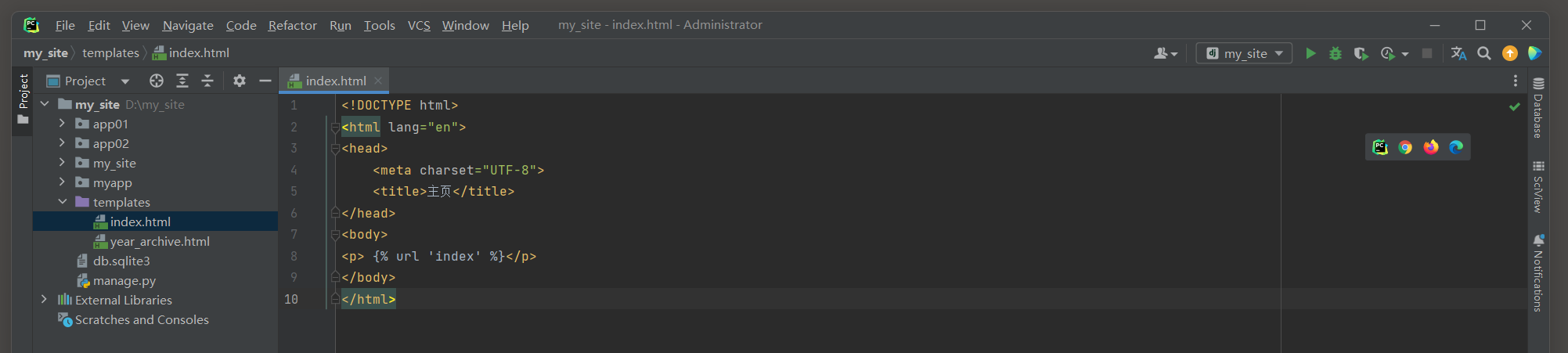
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < p> </ p> </ body> </ html>
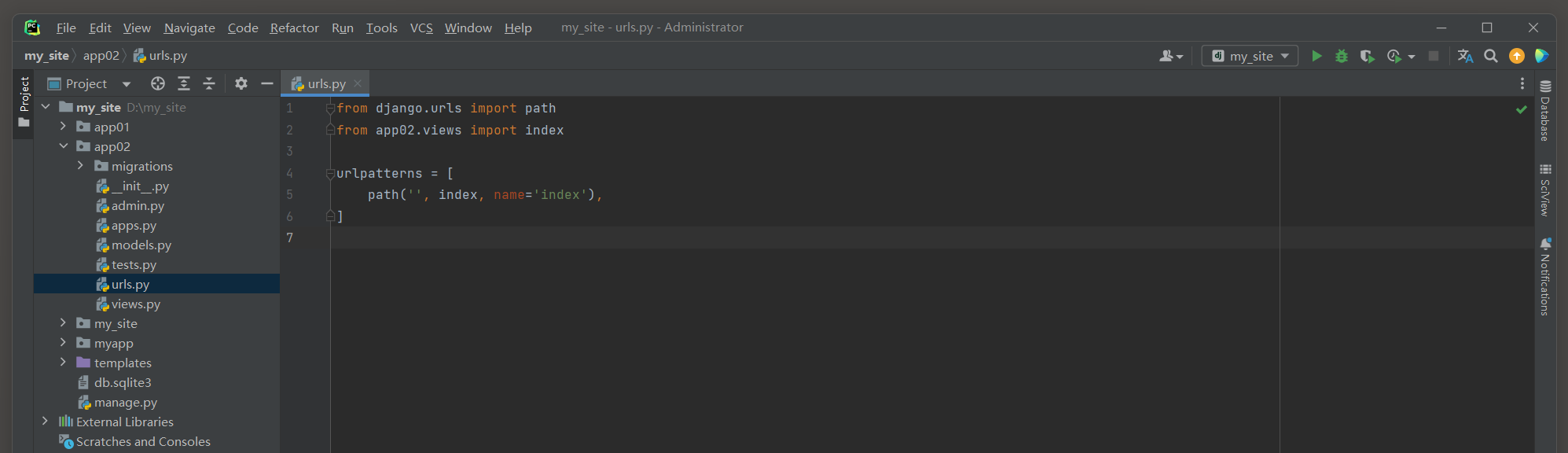
from django. urls import path
from app02. views import index urlpatterns = [ path( '' , index, name= 'index' ) ,
]
from django. shortcuts import renderdef index ( request) : return render( request, 'index.html' )
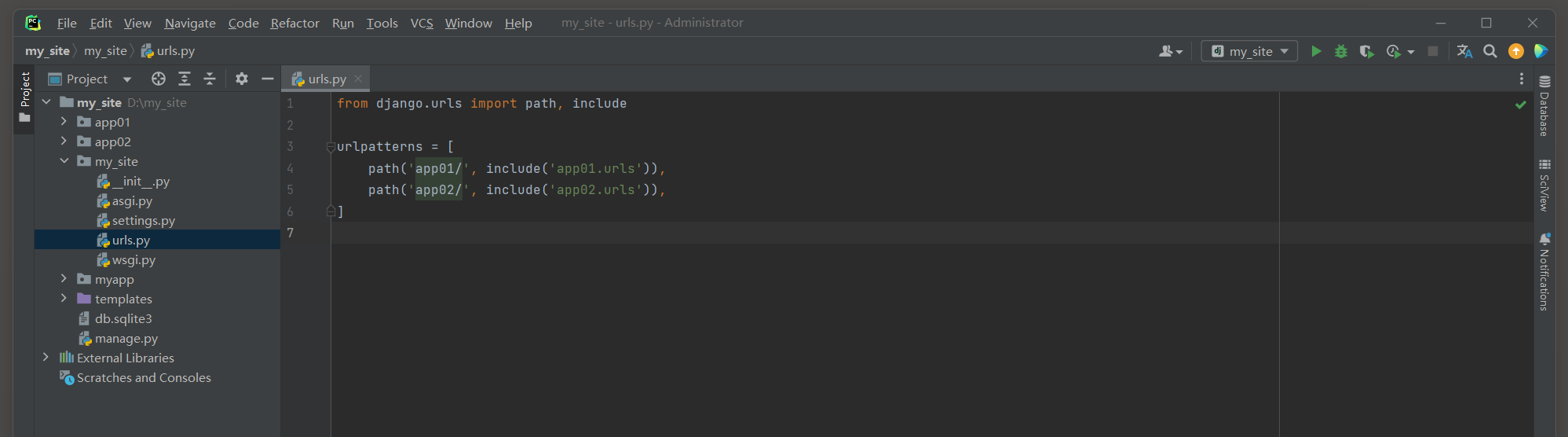
from django. urls import path, includeurlpatterns = [ path( 'app01/' , include( 'app01.urls' ) ) , path( 'app02/' , include( 'app02.urls' ) ) ,
]
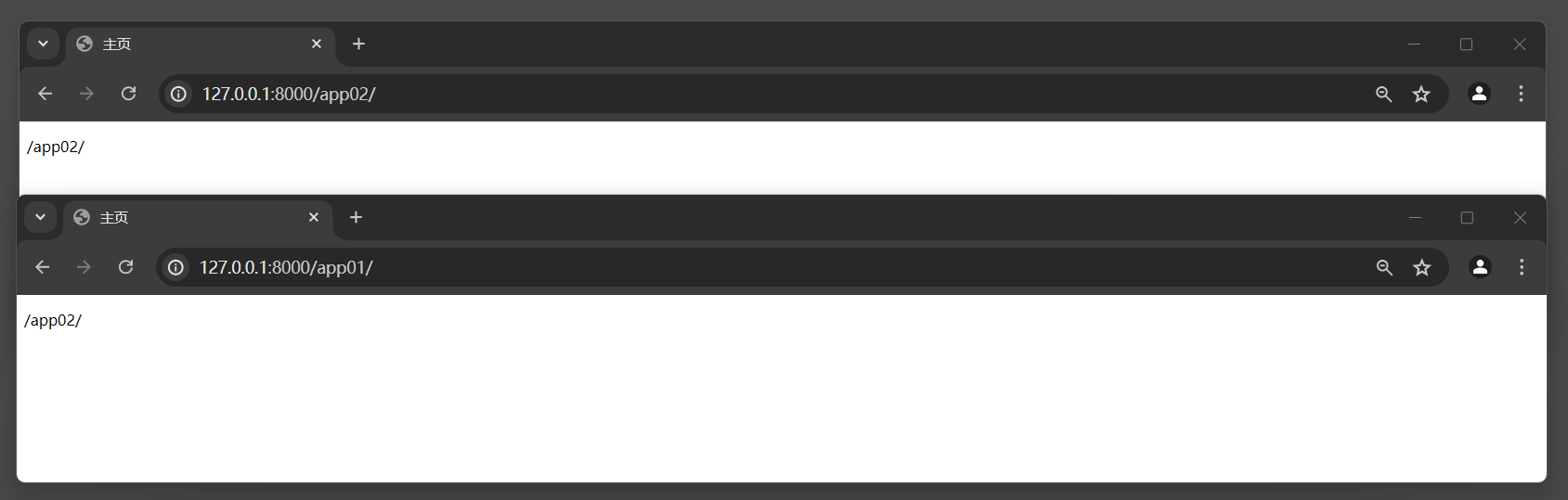
在这个例子中 , app01和app02都定义了一个名为index的URL模式 .
如果没有为include ( ) 函数定义namespace参数 , 并且两个不同应用中的URL模式有相同的名称 ( index ) ,
那么Django将无法区分它们 , 并会默认使用在urlpatterns列表中最后定义的URL .
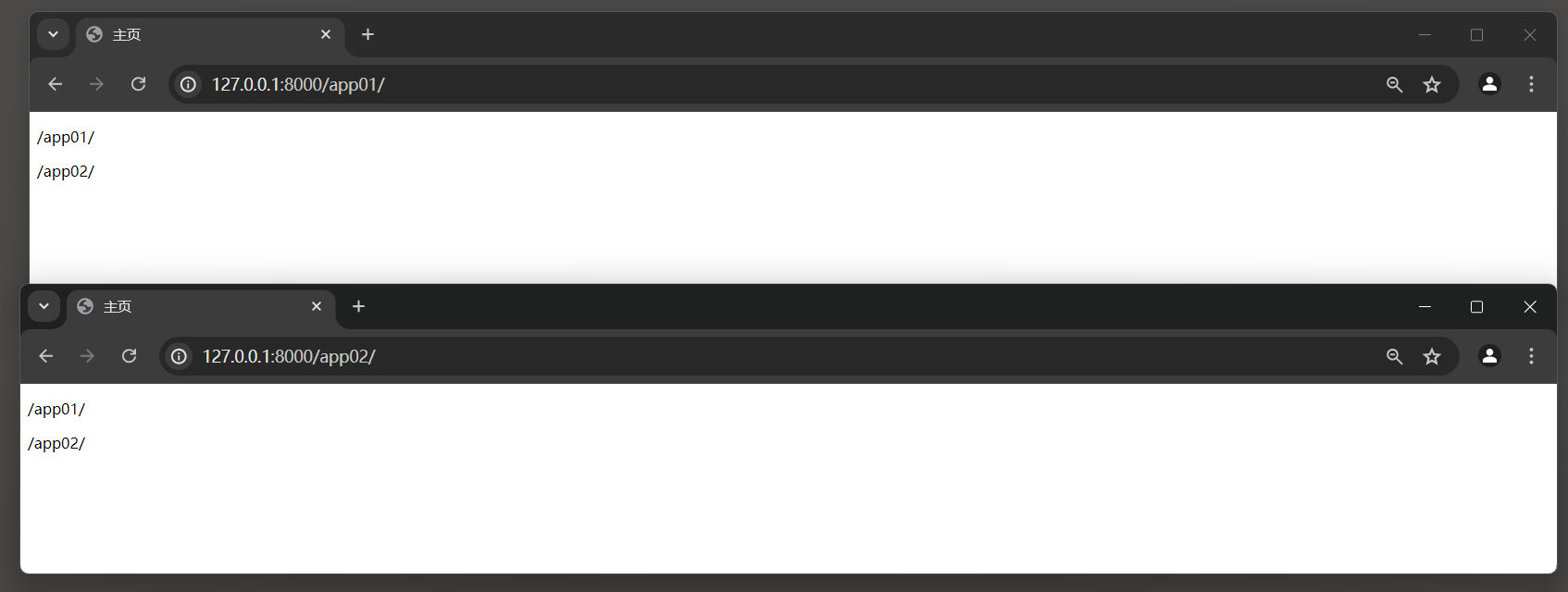
启动项目后 , 访问 : http : / / 127.0 .0 .1 : 8000 /app01/ 与 http : / / 127.0 .0 .1 : 8000 /app02/ 得到的结果是一样的 .
由于app2的URL模式是在app1之后定义的 , 所以当在模板或其他地方使用 { % url 'index' % } 时,Django会找到app2的index URL模式 .
为了避免这种冲突 , 并确保URL名称的唯一性 , 应该为每个包含URL模式的应用使用namespace .
这样 , 就可以通过名称空间化的URL名称来明确指定要访问的URL , 而不用担心名称冲突 .
在Django 2.0 及之后的版本中 , 如果在include ( ) 函数中指定了namespace参数 ,
但是没有在被包含的应用的urls . py中设置app_name属性 , 将会遇到这个ImproperlyConfigured错误 .
Django要求在定义URL配置时为每个命名空间提供一个app_name , 这样可以帮助它更好地组织和识别URL模式 .
为了解决这个问题 , 需要在应用的urls . py文件中设置一个app_name , 以下是如何设置的示例 :
from django. urls import path app_name = 'app01' urlpatterns = [ path( '' , views. index, name= 'index' ) ,
]
from django. urls import path app_name = 'app02' urlpatterns = [ path( '' , views. index, name= 'index' ) ,
]
确保每个需要命名空间的应用的urls . py文件都设置了app_name .
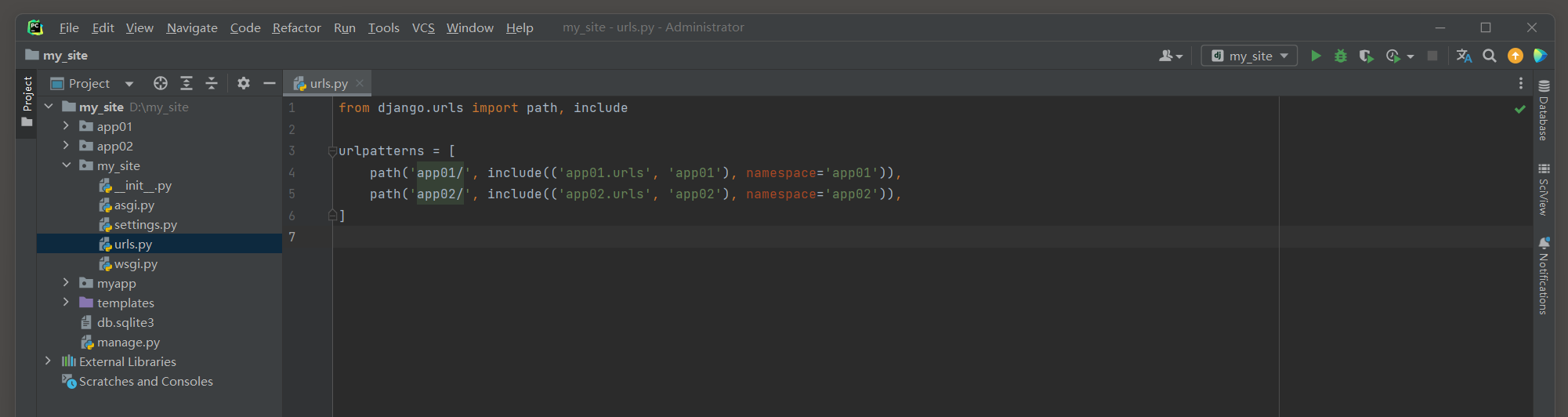
另外 , 如果不想在urls . py中设置app_name , 也可以在include ( ) 函数中直接传递一个包含URL模式和app_name的元组 , 如下所示 :
from django. urls import path, includeurlpatterns = [ path( 'app01/' , include( ( 'app01.urls' , 'app01' ) , namespace= 'app01' ) ) , path( 'app02/' , include( ( 'app02.urls' , 'app02' ) , namespace= 'app02' ) ) ,
]
现在 , 每个应用的URL模式都在其自己的命名空间中 , 因此可以使用app1 : index和app2 : index来唯一地引用它们 , 从而避免了冲突 .
在模板中 , 会这样使用 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < p> </ p> < p> </ p> </ body> </ html> 启动项目后 , 访问 : http : / / 127.0 .0 .1 : 8000 /app01/ 与 http : / / 127.0 .0 .1 : 8000 /app02/ .
这样 , 即使两个应用有相同名称的URL模式 , 也不会再发生冲突 .
总结 : 在Django中 , 反向解析是URL配置中的一个重要概念 , 它允许你基于视图的名称和可选的参数来动态地生成URL .
为了支持这种动态生成URL的功能 , 需要为URL模式指定一个名称 ( name ) .
这些名称在项目的整个URL配置中应该是唯一的 , 但在大型项目中 , 可能会有多个URL配置 , 这时就需要使用命名空间来区分它们 .
在Django中 , 自定义转化器 ( converters ) 允许定义自己的路径转换逻辑 ,
以便在URL匹配时自动将URL中的字符串转换为Python数据类型 , 或者在反向解析URL时将Python数据类型转换为URL中的字符串 . 源码地址 : D : \ Python \ Python38 \ Lib \ site-packages \ django \ urls \ converters . py
自定义的URL转换器通常直接书写一个类 , 并实现to_python和to_url方法和一个regex属性 .
实现步骤 :
* 1. 创建一个类 .
* 2. 定义一个类属性regex , 值通常为正则表达式字符串 .
* 3. 定义to_python ( self , value ) 方法 : 该方法接收一个字符串 ( 从URL中捕获的值 ) , 并返回一个Python数据类型 . 如果URL字符串无法被转换 , 则应该抛出一个ValueError .
* 4. 定义to_url ( self , value ) 方法 : 该方法接收一个Python数据类型 ( 通常是to_python方法返回的类型 ) , 并返回一个字符串 , 该字符串将被用于URL中 . 如果Python字符串无法被转换 , 则应该抛出一个ValueError .
* 5. 定义之后 , 使用register_converter函数来注册的转换器 , 并为转换器去一个名称 .
* 6. 在路由文件中导入自定义转换器 , 使用方式与内置的转换器一样 .
以下是完整的步骤和示例 :
* 1. 定义自定义转换器 : 在应用中的创建一个模块 ( 比如 : converters . py ) , 在模块中定义的转换器类 .
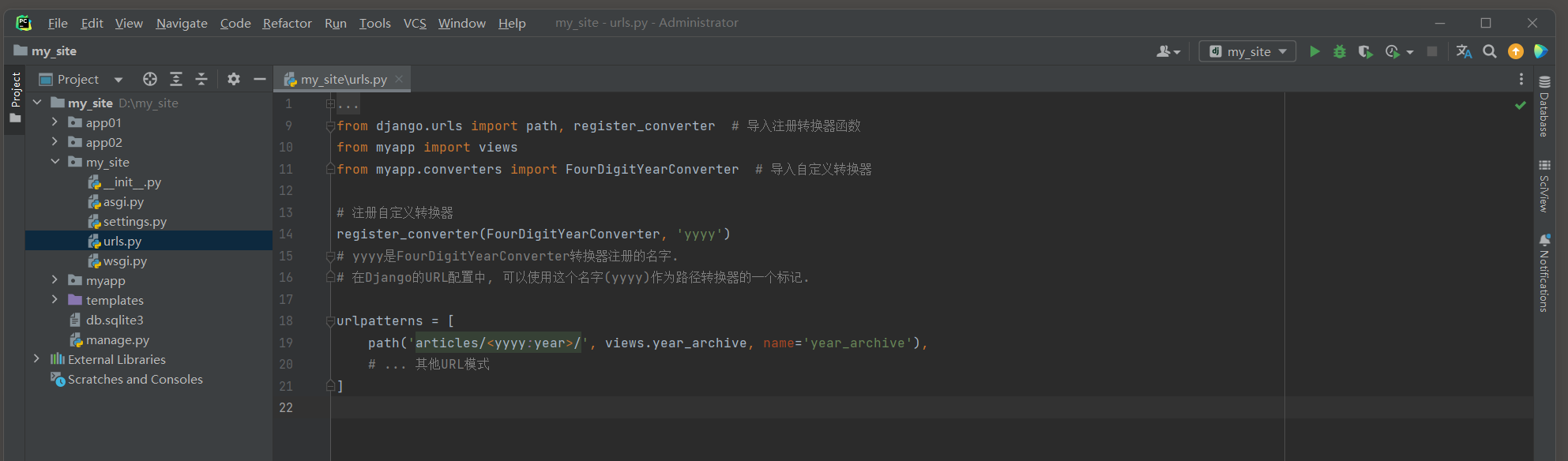
class FourDigitYearConverter : regex = '[0-9]{4}' def to_python ( self, value) : return int ( value) def to_url ( self, value) : return '%04d' % value
* 2. 注册自定义转换器 : 在应用的urls . py文件中 , 使用register_converter函数来注册自定义的转换器 .
from django. urls import path, register_converter
from myapp import views
from myapp. converters import FourDigitYearConverter
register_converter( FourDigitYearConverter, 'yyyy' )
urlpatterns = [ path( 'articles/<yyyy:year>/' , views. year_archive, name= 'year_archive' ) ,
]
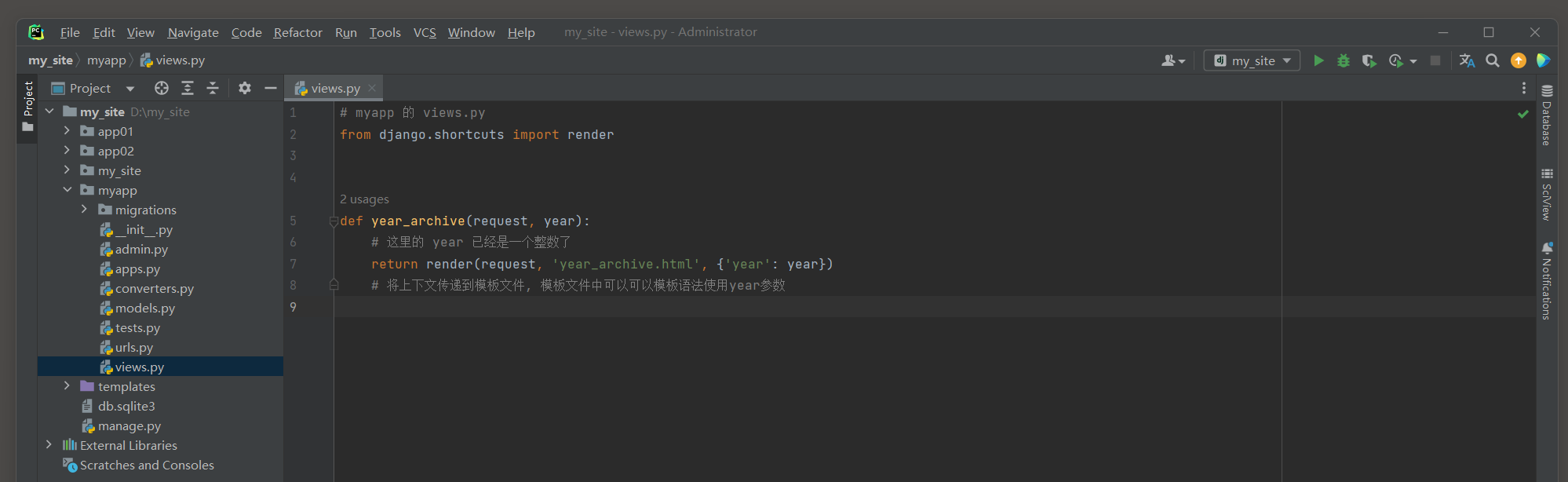
* 3. 在视图函数中使用 : 在视图函数views . year_archive中 , 可以将year参数作为一个整数接收 , 因为它已经通过FourDigitYearConverter的to_python方法被转换了 .
from django. shortcuts import renderdef year_archive ( request, year) : return render( request, 'year_archive.html' , { 'year' : year} )
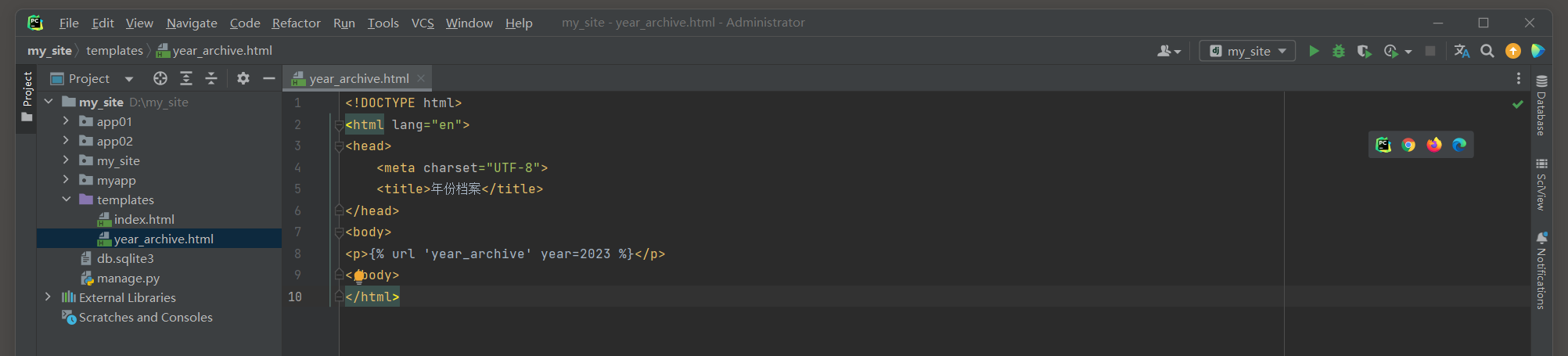
在模板或URL反向引用中使用 : 当想在模板中创建一个链接到year_archive视图的URL时 , 可以使用 { % url % } 模板标签 ,
并且Django将使用FourDigitYearConverter的to_url方法来确保年份以四位数的格式出现在URL中 .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < p> </ p> </ body> </ html>
使用模板语句 , 只需要提供年份的整数形式 ( 在这个例子中是 2023 ) , Django会知道如何将其转换为URL中所需的格式 .
因为Django的URL解析器会自动调用FourDigitYearConverter的to_url方法处理这个转换 .
启动项目 , 访问 : 127.0 .0 .1 : 8000 /articles/ 2023 / .
以下展示了如何以一种更健壮的方式书写自定义转换器 .
from django. urls import register_converter class FourDigitYearConverter : regex = '[0-9]{4}' def to_python ( self, value) : if not value. isdigit( ) or len ( value) != 4 : raise ValueError( "Invalid year format. Should be YYYY." ) return int ( value) def to_url ( self, value) : if not isinstance ( value, int ) : raise ValueError( "Value passed to .to_url() must be an int." ) return str ( value) . zfill( 4 )
register_converter( FourDigitYearConverter, 'yyyy' ) 在上面的代码中 , FourDigitYearConverter类定义了一个正则表达式regex , 用于匹配四位数的年份 .
to_python方法检查传入的字符串是否为四位数的数字 , 并将其转换为整数 .
如果字符串不符合要求 , 则抛出一个ValueError .
to_url方法将整数转换为字符串 , 并确保总是四位数的年份 ( 使用zfill ( 4 ) 方法在左侧填充零 ) ,
例 : { % url 'year_archive' year = 2 % } 将转换为 '/articles/0002/' .





















![[MYSQL] 数据库基础](https://img-blog.csdnimg.cn/direct/f11d29c610164f9ba9a295e77ca15433.png)