文章目录
- LLM 概述
- 理解 Transformer 架构及其在 LLM 中的作用
- 解密 GPT 模型的标记化和预测步骤
想象这样⼀个世界:在这个世界里,你可以像和朋友聊天⼀样快速地与计算机交互。那会是怎样的体验?你可以创造出什么样的应用程序?这正是OpenAI 努力构建的世界,它通过其 GPT 模型让设备拥有与⼈类对话的能力。作为人工智能(artificial intelligence,AI)领域的最新成果,GPT-4 和其他 GPT 模型是基于⼤量数据训练而成的大语言模型 (large language model,LLM),它们能够以非常高的准确性识别和生成人类可读的文本。
这些 AI 模型的意义远超简单的语音助手。多亏了 OpenAI 的模型,开发人员现在可以利用自然语言处理(natural language processing,NLP)技术创建应用程序,使其以⼀种曾经只存在于科幻小说中的方式理解我们的需求。从学习和适应个体需求的创新型客户支持系统,到理解每个学生独特的学习风格的个性化教学工具,GPT-4 和 ChatGPT 打开了⼀扇门,让⼈们看见⼀个充满可能性的全新世界。GPT-4 和 ChatGPT 究竟是什么?
LLM 概述
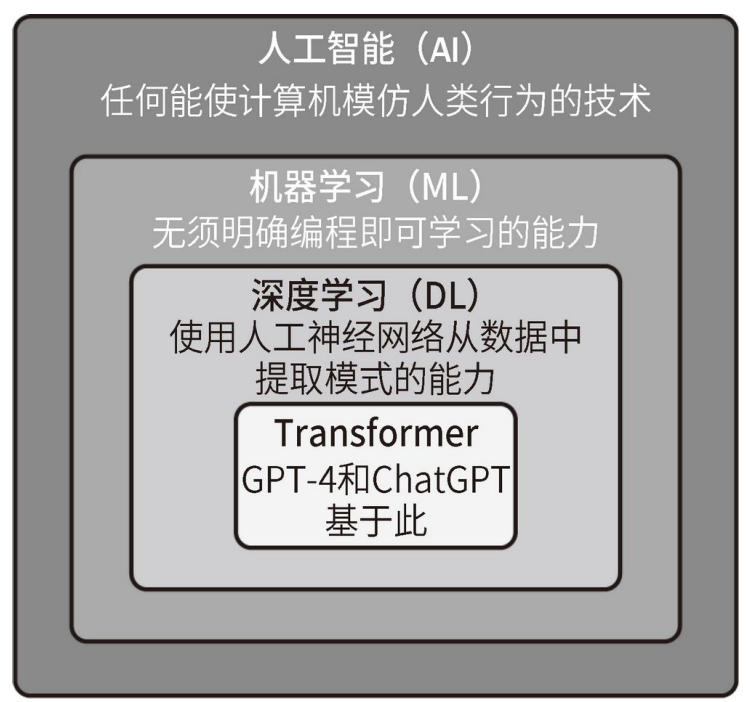
作为 LLM,GPT-4 和 ChatGPT 是 NLP 领域中最新的模型类型,NLP 是机器学习和⼈⼯智能的⼀个子领域。在深⼊研究 GPT-4 和 ChatGPT 之前,有必要了解 NLP 及其相关领域。AI 有不同的定义,但其中⼀个定义或多或少已成为共识,即 AI 是⼀类计算机系统,它能够执行通常需要⼈类智能才能完成的任务。根据这个定义,许多算法可以被归为 AI 算法,比如导航应用程序所用的交通预测算法或策略类视频游戏所用的基于规则的系统。从表面上看,在这些示例中,计算机似乎需要智能才能完成相关任务。
机器学习(machine learning,ML)是 AI 的⼀个子集。在 ML 中,我们不试图直接实现 AI 系统使用的决策规则。相反,我们试图开发算法,使系统能够通过示例自己学习。自从在 20 世纪 50 年代开始进行 ML 研究以来,⼈们已经在科学文献中提出了许多 ML 算法。在这些 ML 算法中,深度学习(deep learning,DL)算法已经引起了广泛关注。DL 是 ML 的⼀个分支,专注于受大脑结构启发的算法。这些算法被称为人工神经网络(artificial neural network)。它们可以处理⼤量的数据,并且在图像识别、语音识别及 NLP 等任务上表现出色。
GPT-4 和 ChatGPT 基于⼀种特定的神经网络架构,即 Transformer。Transformer 就像阅读机⼀样,它关注句子或段落的不同部分,以理解其上下文并产生连贯的回答。此外,它还可以理解句子中的单词顺序和上下文意思。这使 Transformer 在语⾔翻译、问题回答和文本生成等任务中非常有效。
NLP 是 AI 的⼀个子领域,专注于使计算机能够处理、解释和⽣成⼈类语言。现代 NLP 解决方案基于 ML 算法。NLP 的目标是让计算机能够处理自然语言文本。这个目标涉及诸多任务,如下所述。将输⼊文本归为预定义的类别。这类任务包括情感分析和主题分类。比如,某公司使用情感分析来了解客户对其服务的意见。电子邮件过滤是主题分类的⼀个例子,其中电子邮件可以被归类为“个⼈邮件”“社交邮件”“促销邮件”“垃圾邮件”等。
将文本从⼀种语言自动翻译成另⼀种语言。请注意,这类任务可以包括将代码从⼀种程序设计语言翻译成另⼀种程序设计语言,比如从 Python翻译成 C++。根据给定的文本回答问题。比如,在线客服门户网站可以使用 NLP 模型回答关于产品的常见问题;教学软件可以使用 NLP 模型回答学生关于所学主题的问题。根据给定的输入文本(称为提示词 )生成连贯且相关的输出文本。
如前所述,LLM 是试图完成文本生成任务的⼀类 ML 模型。LLM 使计算机能够处理、解释和生成⼈类语言,从而提高⼈机交互效率。为了做到这⼀点,LLM 会分析大量文本数据或基于这些数据进行训练,从而学习句子中各词之间的模式和关系。这个学习过程可以使用各种数据源,包括维基百科、Reddit、成千上万本书,甚至互联网本身。在给定输⼊文本的情况下,这个学习过程使得 LLM 能够预测最有可能出现的后续单词,从而生成对输入文本有意义的回应。于 2023 年发布的⼀些现代语言模型非常庞大,并且已经在⼤量⽂本上进行了训练,因此它们可以直接执行大多数 NLP 任务,如文本分类、自动翻译、问题回答等。GPT-4 和 ChatGPT 是在文本⽣成任务上表现出色的 LLM。
LLM 的发展可以追溯到几年前。它始于简单的语言模型,如 n-gram 模型。n-gram 模型通过使用词频来根据前面的词预测句子中的下⼀个词,其预测结果是在训练⽂本中紧随前面的词出现的频率最高的词。虽然这种方法提供了不错的着手点,但是 n-gram 模型在理解上下文和语法方面仍需改进,因为它有时会生成不连贯的文本。为了提高 n-gram 模型的性能,⼈们引⼊了更先进的学习算法,包括循环神经网络(recurrent neural network,RNN)和长短期记忆(long short-term memory,LSTM)网络。与 n-gram 模型相比,这些模型能够学习更长的序列,并且能够更好地分析上下文,但它们在处理大量数据时的效率仍然欠佳。尽管如此,在很长的⼀段时间里,这些模型算是最高效的,因此在自动翻译等任务中被⼴泛使用。
理解 Transformer 架构及其在 LLM 中的作用
Transformer 架构彻底改变了 NLP 领域,这主要是因为它能够有效地解决之前的 NLP 模型(如 RNN)存在的⼀个关键问题:很难处理长文本序列并记住其上下文。换句话说,RNN 在处理长文本序列时容易忘记上下文(也就是臭名昭著的“灾难性遗忘问题”),Transformer 则具备高效处理和编码上下文的能力。这场革命的核心支柱是注意力机制,这是⼀个简单而又强大的机制。模型不再将文本序列中的所有词视为同等重要,而是在任务的每个步骤中关注最相关的词。交叉注意力和自注意力是基于注意力机制的两个架构模块,它们经常出现在 LLM 中。Transformer 架构⼴泛使用了交叉注意力模块和自注意力模块。
交叉注意力有助于模型确定输入文本的不同部分与输出⽂本中下⼀个词的相关性。它就像⼀盏聚光灯,照亮输⼊文本中的词或短语,并突出显示预测下⼀个词所需的相关信息,同时忽略不重要的细节。为了说明这⼀点,让我们以⼀个简单的句子翻译任务为例。假设输入文本
是这样⼀个英语句子:Alice enjoyed the sunny weather in Brussels(Alice 很享受布鲁塞尔阳光明媚的天气)。如果目标语言是法语,那么输出文本应该是:Alice a profité du temps ensoleillé à Bruxelles。在这个例子中,让我们专注于生成法语单词 ensoleillé,它对应原句中的 sunny。对于这个预测任务,交叉注意力模块会更关注英语单词 sunny 和 weather,因为它们都与ensoleillé 相关。通过关注这两个单词,交叉注意力模块有助于模型为句子的这⼀部分生成准确的翻译结果,如下图所示。

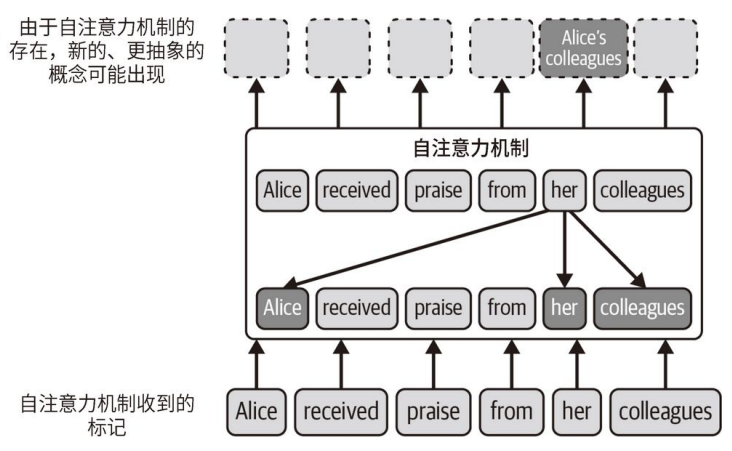
自注意力机制是指模型能够关注其输入文本的不同部分。具体到 NLP 领域,自注意力机制使模型能够评估句子中的每个词相比于其他词的重要性。这使得模型能够更好地理解各词之间的关系,并根据输入文本中的多个词构建新概念。来看⼀个更具体的例子。考虑以下句子:Alice received praise from her colleagues(Alice 受到同事的赞扬)。假设模型试图理解 her 这个单词的意思。自注意力机制给句子中的每个单词分配不同的权重,突出在这个上下文中与 her 相关的单词。在本例中,自注意力机制会更关注 Alice 和 colleagues 这两个单词。如前所述,自注意力机制帮助模型根据这些单词构建新概念。在本例中,可能出现的⼀个新概念是 Alice’s colleagues,如下图所示。
与 RNN 不同,Transformer 架构具有易于并行化的优势。这意味着 Transformer 架构可以同时处理输入文本的多个部分,而无须顺序处理。这样做可以提高计算速度和训练速度,因为模型的不同部分可以并行工作,而无须等待前⼀步骤完成。基于 Transformer 架构的模型所具备的并行处理能力与图形处理单元(graphics processing unit,GPU)的架构完美契合,后者专用于同时处理多个计算任务。由于高度的并行性和强大的计算能力,GPU 非常适合用于训练和运行基于 Transformer 架构的模型。硬件上的这⼀进展使数据科学家能够在大型数据集上训练模型,从而为开发 LLM 铺平了道路。
Transformer 架构由来自谷歌公司的 Ashish Vaswani 等⼈在 2017 年的论文“Attention Is All You Need”中提出,最初用于序列到序列的任务,如机器翻译任务。标准的Transformer 架构有两个主要组件:编码器和解码器,两者都十分依赖注意力机制。编码器的任务是处理输入文本,识别有价值的特征,并生成有意义的文本表示,称为嵌入(embedding)。解码器使用这个嵌入来生成⼀个输出,比如翻译结果或摘要文本。这个输出有效地解释了编码信息。
生成式预训练 Transformer(Generative Pre-trained Transformer,GPT)是⼀类基于 Transformer 架构的模型,专门利用原始架构中的解码器部分。在GPT 中,不存在编码器,因此无须通过交叉注意力机制来整合编码器产生的嵌⼊。也就是说,GPT 仅依赖解码器内部的自注意力机制来生成上下文感知的表示和预测结果。请注意,BERT 等其他⼀些众所周知的模型基于编码器部分,但本书不涉及这类模型。下图展示了 NLP 技术的演变历程。

解密 GPT 模型的标记化和预测步骤
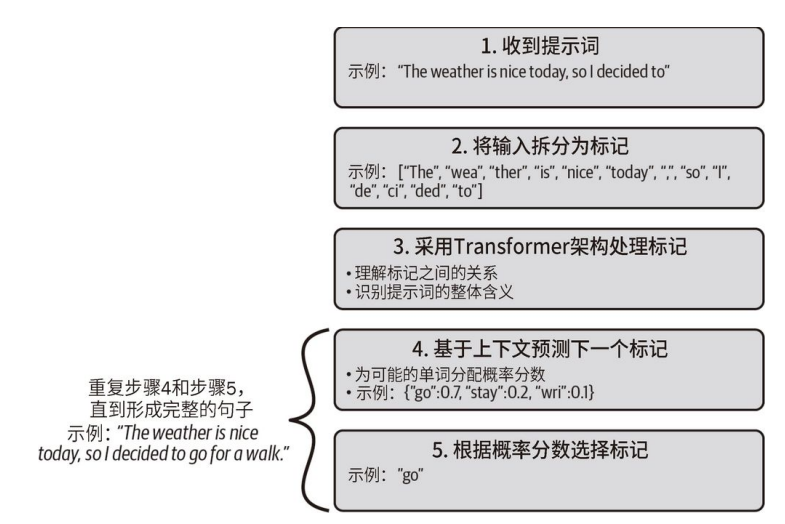
GPT 模型接收⼀段提示词作为输入,然后生成⼀段文本作为输出。这个过程被称为文本补全。举例来说,提示词可以是 The weather is nice today, so Idecided to(今天天气很好,所以我决定),模型的输出则可能是 go for a walk(去散步)。你可能想知道 GPT 模型是如何根据输入的提示词构建输出⽂本的。正如你将看到的,这主要是⼀个概率问题。当 GPT 模型收到⼀段提示词之后,它首先将输入拆分成标记(token)。这些标记代表单词、单词的⼀部分、空格或标点符号。比如,在前面的例子中,提示词可以被拆分成[The, wea, ther, is, nice, today, so, I, de, ci, ded, to]。几乎每个语言模型都配有自己的分词器。截至本书英文版出版之时,GPT-4的分词器还不可用,不过你可以尝试使用 GPT-3 的分词器。
理解标记与词长的⼀条经验法则是,对于英语文本,100 个标记⼤约等于 75 个单词。因为有了注意力机制和 Transformer 架构,LLM 能够轻松处理标记并解释它们之间的关系及提示词的整体含义。Transformer 架构使模型能够高效地识别文本中的关键信息和上下文。为了生成新的句子,LLM 根据提示词的上下文预测最有可能出现的下⼀个标记。OpenAI 开发了两个版本的 GPT-4,上下文窗口大小分别为 8192 个标记和 32 768 个标记 。与之前的循环模型不同,带有注意力机制的Transformer 架构使得 LLM 能够将上下文作为⼀个整体来考虑。基于这个上下文,模型为每个潜在的后续标记分配⼀个概率分数,然后选择概率最高的标记作为序列中的下⼀个标记。在前面的例子中,“今天天气很好,所以我决定”之后,下⼀个最佳标记可能是“去”。
接下来重复此过程,但现在上下文变为“今天天气很好,所以我决定去”,之前预测的标记“去”被添加到原始提示词中。这个过程会⼀直重复,直到形成⼀个完整的句子:“今天天气很好,所以我决定去散步。”这个过程依赖于 LLM 学习从大量文本数据中预测下⼀个最有可能出现的单词的能力。下图展示了这个过程。