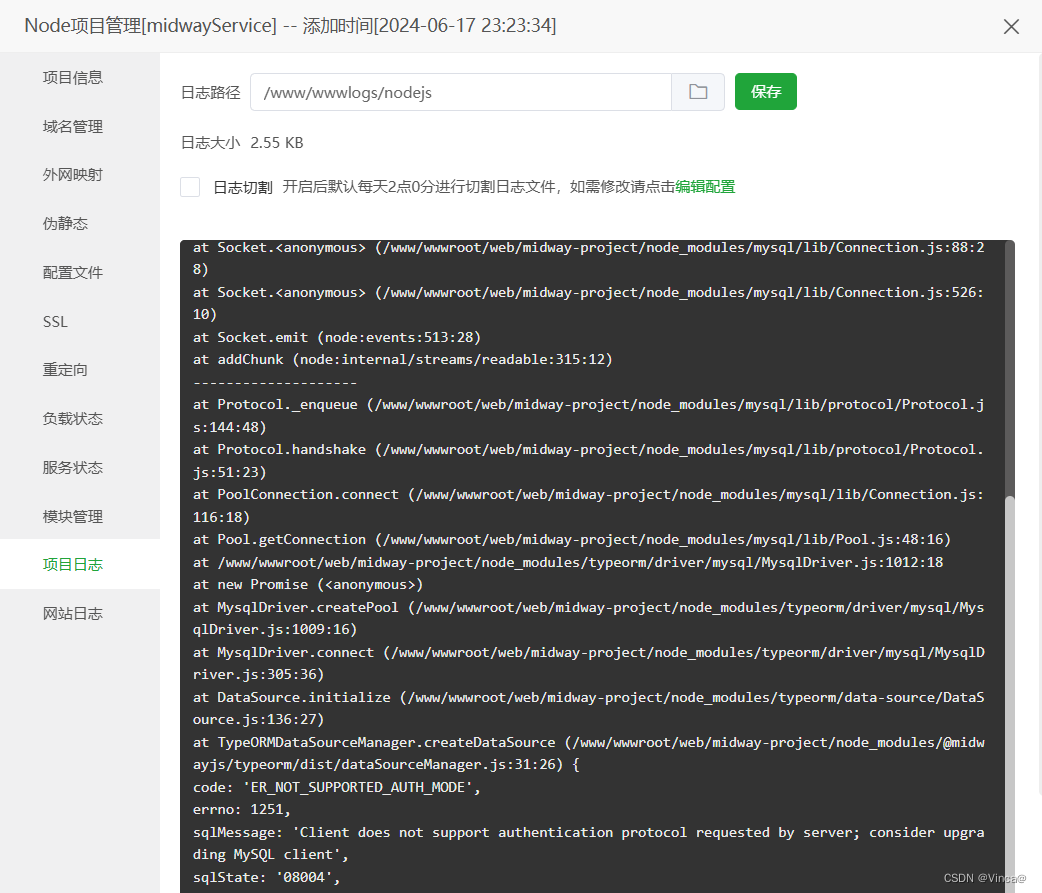
完整代码、数据集和相应的报告 链接已经放在了正文最下方, 供大家参考学习
摘要
本文探讨了中文垃圾短信分类的问题,通过收集实际数据集,运用多种机器学习算法进行分类,并对比了不同算法在垃圾短信分类任务上的性能。本研究旨在提高中文垃圾短信的识别准确率,为构建更健康的通信环境提供技术支持。
关键词:数据规范化,朴素贝叶斯、随机森林,决策树、垃圾短信、文本分类
数据集介绍
本研究使用了一个包含大量中文短信的数据集,该数据集包括了约 70 万条数据,有 3 个字段 label、 message 和 msg_new, 分别代表了短信的类别、短信的内容和分词后的短信,其中0 代表正常的短信,1 代表恶意的短信, 中文分词工具采用jieba, 已经将短信内容处理好。 下面是正常短信和恶意短信的举例:

导入程序必要的库
import warnings
warnings.filterwarnings