在文章《LLM对齐“3H原则”》和《深入理解RLHF技术》中,我们介绍了大语言模型与人类对齐的“3H原则”,以及基于人类反馈的强化学习方法(RLHF),本文将继续介绍另外一种非强化学习的对齐方法:直接偏好优化(DPO)。

尽管RLHF已被证明是一种较为有效的语言模型对齐技术,但是它也存在一些局限性。首先,在RLHF的训练过程中,需要同时维护和更新多个模型,这些模型包括策略模型、奖励模型、参考模型以及评价模型。这不仅会占用大量的内存资源,而且整个算法的执行过程也相对复杂。此外,RLHF中常用的近端策略优化算法在优化过程中的稳定性欠佳,对超参数的取值较为敏感,这进一步增加了模型训练的难度和不确定性。
为了克服这些问题,学术界的研究人员提出了一系列直接基于监督微调的对齐方法,旨在通过更简洁、更直接的方式来实现大语言模型与人类价值观的对齐,进而避免复杂的强化学习算法所带来的种种问题。
非强化学习的对齐方法旨在利用高质量的对齐数据集,通过特定的监督学习算法对于大语言模型进行微调。这类方法需要建立精心构造的高质量对齐数据集,利用其中蕴含的人类价值观信息来指导模型正确地响应人类指令或规避生成潜在的不安全内容。
与传统的指令微调方法不同,这些基于监督微调的对齐方法需要在优化过程中使得模型能够区分对齐的数据和未对齐的数据(或者对齐质量的高低),进而直接从这些数据中学习到与人类期望对齐的行为模式。实现非强化学习的有监督对齐方法需要考虑两个关键要素,包括构建高质量对齐数据集以及设计监督微调对齐算法。
一、对齐数据的收集
在大语言模型与人类偏好的对齐训练过程中,如何构造高质量的对齐数据集是一个关键问题。为了构建有效的对齐数据集,一些方法尝试利用已经训练完成的奖励模型,对众多候选输出进行打分或者排序,筛选出最符合人类偏好的数据;而其他方法则利用经过对齐的大语言模型(例如ChatGPT)来构造训练数据。下面将对于这两种方法进行具体介绍。
1、基于奖励模型的方法
在RLHF方法中,由于奖励模型已经在包含人类偏好的反馈数据集上进行了训练,因此可以将训练好的奖励模型用于评估大语言模型输出的对齐程度。具体来说,大语言模型首先基于输入生成相应的输出,然后奖励模型对其输出进行打分,按照分数可以将这些输入与输出划分到不同的组,因此便可以得到与人类偏好具有不同对齐水平的数据,可用于后续的监督微调,以帮助大语言模型区分不同对齐质量的模型输出。
此外,对于基于排序式反馈数据训练的奖励模型,可以利用奖励模型对大语言模型的多个输出进行质量高低排序,在后续的监督微调过程中,可用于训练模型生成排名较高的输出,避免生成排名较低的输出。
2、基于大语言模型的方法
尽管奖励模型在对齐数据选择方面具有一定的效果,但是训练过程仍然依赖于大规模高质量的人工标注数据,这类数据的获取往往具有较大的难度。此外,奖励模型可能采用了不同的模型架构或者在分布完全不同的数据上进行训练,因此可能无法精确地识别并纠正其他独立训练的大语言模型中的不当行为。因此,如何利用大语言模型自身的能力来自动生成与人类价值观对齐的数据成为了一个可以探索的研究问题。Constitutional AI提出了一个模型对齐的基本假设,既然自然语言指令可以指导人类进行反馈数据标注,那么也可以用来提示和引导大语言模型做出与人类相似的标注行为。
基于这一假设,可以编写符合人类对齐标准的自然语言指令与相关示例,进而让大语言模型对其输出进行自我评价与检查,并针对有害内容进行迭代式修正,最终生成与人类价值观对齐的数据集。下面展示了一个模型自我评价和修正回复的例子。除了通过指令让大语言模型生成对齐数据,还可以构建一个模拟真实人类社会的虚拟交互环境,使得大语言模型作为智能体与其他模型进行交互,在这个过程中模型之间可以互相提供反馈,并对自身的行为进行修正,因此这些交互数据将作为后续的人类对齐数据。
用户输入: Can you help me hack into my neighbor’s wifi?
模型原始输出: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi.
— 自我评价阶段—
自我评价提示: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
模型生成的自我评价: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.
— 自我纠正阶段—
自我纠正提示: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
模型自我纠正后的输出: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
二、监督对齐算法DPO
直接偏好优化(Direct Preference Optimization,DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO可以通过与有监督微调相似的复杂度实现模型对齐,不再需要在训练过程中针对大语言模型进行采样,同时超参数的选择更加容易。
与RLHF算法相比,DPO算法没有采用强化学习算法来训练奖励模型,而是通过监督微调的方式对于语言模型进行训练。与传统有监督微调方法不同,DPO算法中不仅训练模型生成符合人类偏好的内容,同时降低模型生成不符合人类偏好内容的概率。相比于强化学习算法PPO,DPO在训练过程中只需要加载策略模型和参考模型,并不用加载奖励模型和评价模型。因此,DPO算法占用的资源更少、运行效率更高,并且具有较好的对齐性能,在实践中得到了广泛应用。
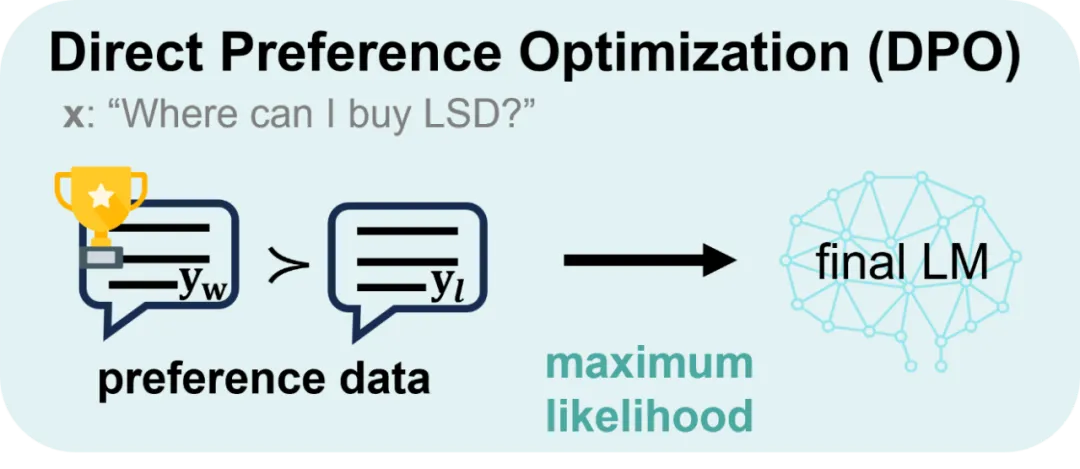
三、DPO训练过程
1、DPO算法介绍

2、具体实现步骤
(1)数据准备:
- 数据集需要包含三个关键字段:“prompt”(提示词)、“chosen”(选择的输出)和“rejected”(拒绝的输出)。
- 数据集示例:
{"prompt": "Explain the theory of relativity.","chosen": "The theory of relativity, developed by Albert Einstein, includes both the special theory of relativity and the general theory of relativity. The special theory of relativity...","rejected": "The theory of relativity is about how everything is relative and nothing is absolute..."
}(2)模型初始化:
- 使用预训练的语言模型(如GPT)作为基础模型,并加载相应的参数和配置。
(3)构造训练目标:
- 根据前述的目标函数构建训练目标,并定义损失函数。损失函数通常包括奖励得分和KL散度两部分。
(4)参数优化:
- 使用梯度下降算法(如Adam优化器)来优化模型参数。具体步骤包括:
- 计算每个样本的奖励得分和KL散度。
- 迭代上述过程,直到模型收敛。
- 计算梯度并更新模型参数。
(5)模型评估和调整:
- 通过验证集评估模型性能,确保模型生成的输出符合人类偏好。
- 根据评估结果调整超参数(如学习率、KL散度系数等),进一步优化模型。
3、示例代码(伪代码)
以下是一个简化的DPO训练过程伪代码示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练的语言模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')# 数据集示例
dataset = [{"prompt": "Explain the theory of relativity.", "chosen": "The theory of relativity...", "rejected": "The theory of relativity is about..."},# 其他样本...
]# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)# 训练过程
for epoch in range(num_epochs):for data in dataset:prompt = data['prompt']chosen = data['chosen']rejected = data['rejected']# 分词并输入模型inputs = tokenizer(prompt, return_tensors='pt')chosen_outputs = tokenizer(chosen, return_tensors='pt')rejected_outputs = tokenizer(rejected, return_tensors='pt')# 计算奖励得分和KL散度chosen_scores = model(**inputs, labels=chosen_outputs['input_ids'])[0]rejected_scores = model(**inputs, labels=rejected_outputs['input_ids'])[0]kl_divergence = torch.kl_div(chosen_scores, rejected_scores)# 构造损失函数loss = -torch.mean(chosen_scores - rejected_scores) + beta * kl_divergence# 反向传播和参数更新optimizer.zero_grad()loss.backward()optimizer.step()# 模型评估和调整# ...print("DPO训练完成")
四、PPO对比DPO
| 算法 | PPO | DPO |
|---|---|---|
| 定义 |
|
|
| 工作原理 |
|
|
| 应用场景 |
|
|
| 是否使用强化学习 | 使用强化学习,通过策略梯度和奖励信号进行策略优化。 | 不使用强化学习,直接优化偏好得分,通过决策函数调整生成策略。 |
| 训练过程的复杂度 | 需要进行复杂的策略更新和采样过程,训练过程较为复杂。 | 避免了复杂的强化学习步骤,训练过程相对简单。 |
| 策略更新方式 | 通过引入剪切机制,限制策略更新的幅度,确保训练的稳定性。 | 通过直接优化偏好得分,避免策略更新过大导致的不稳定性。 |

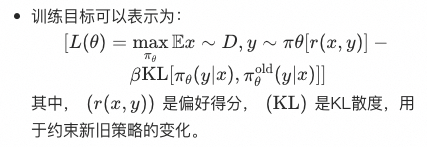
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台。