在临床肿瘤学领域,多模态人工智能(AI)系统通过解读各类医学数据,展现出提升临床决策的潜力。然而,这些模型在所有医学领域中的有效性尚未确定。本文介绍了一种新型的多模态医疗AI方法,该方法利用大型语言模型(LLM)作为中央推理引擎,自主协调和部署一系列专业化的医疗AI工具。通过一系列临床肿瘤学场景验证了该系统的性能,这些场景紧密模拟了典型的患者护理工作流程。
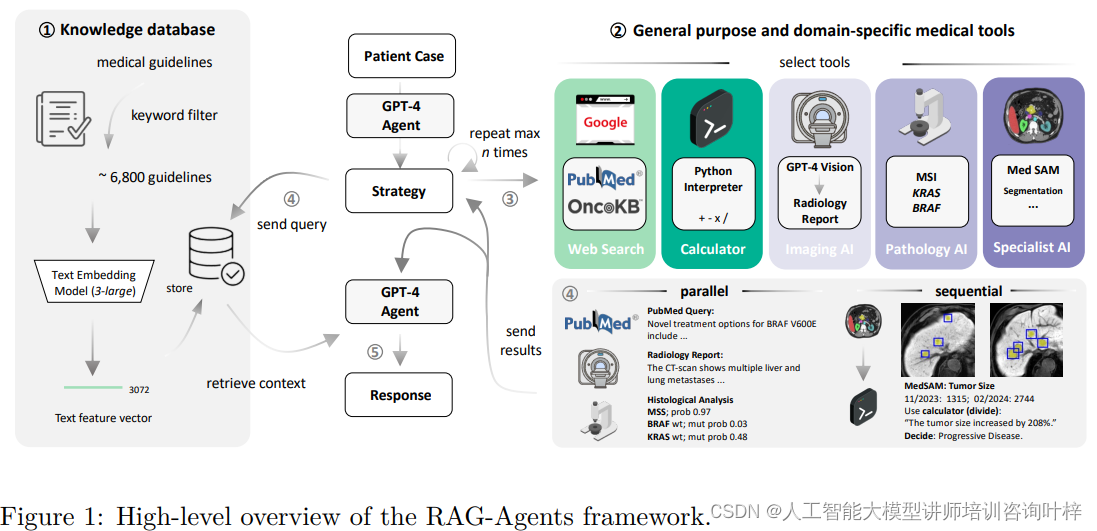
这个框架图展示了系统如何访问包含医疗文档、临床指南和评分工具的策划知识数据库,以及如何通过关键字过滤和文本嵌入来精炼数据库。其核心理念在于利用大型语言模型(LLM)作为中央推理引擎,而不是构建一个包含所有功能的通用多模态基础模型。这种方法的关键在于,它不是试图让一个模型完成所有任务,而是通过一个大型的语言模型来协调和使用一系列专业化的单模态深度学习模型,每种模型都针对特定的医疗任务进行了优化。
例如,系统使用了专门的视觉模型API来处理MRI和CT扫描,并生成放射学报告。这表明AI代理能够解读医学影像数据,并将其转化为对临床决策有用的信息。系统还包括了MedSAM工具,这是一个用于医学图像分割的工具,它可以帮助识别和量化图像中的特定结构,比如肿瘤的大小和形状。这对于评估疾病进展和治疗效果至关重要。
系统还包括了直接从常规组织病理学幻灯片中检测遗传变异的视觉变换器模型。这些模型能够分析组织样本的视觉特征,并预测是否存在特定的遗传变异,如KRAS和BRAF突变,这些信息对于选择靶向治疗至关重要。
构建和评估AI代理系统的方法如下,这个系统旨在通过集成多种工具和数据源来提高临床决策的质量。
数据集组成和数据收集: 为了确保AI系统能够提供基于最新和准确医疗知识的建议,研究者们从多个高质量的医疗来源编制了一个综合数据集。这个数据集不仅包括了广泛的医学知识,还特别强调了肿瘤学方面的信息。研究者们选择了六个主要的数据源,包括MDCalc、UpToDate、MEDITRON项目、美国临床肿瘤学会(ASCO)、欧洲医学肿瘤学会(ESMO)的临床实践指南,以及德国医学肿瘤学会(DGHO)的指南。这些来源提供了包括临床评分、一般医疗建议和专业肿瘤学信息在内的丰富内容。研究者们通过应用关键词过滤,针对特定用例筛选了相关文档,确保了数据集的相关性和最新性。
从PDF文件中提取信息: 从PDF文档中提取文本是一个挑战,因为PDF文件通常为了阅读方便而设计,而不是为了结构化的数据处理。使用传统的工具如PyPDF2或PyMuPDF可能会遇到标题、子标题和关键信息的不规则排列问题。为了保持医学文档结构的完整性并确保提取的信息在上下文中是连贯的,研究者们采用了GROBID工具。GROBID是一个专为将非结构化PDF数据转换为标准化TEI格式而开发的Java应用程序和机器学习库。它通过对科学和技术文章的训练,能够有效地解析医学文档,保留文本层次结构,并生成关键的元数据,如文档和期刊标题、作者、页码、出版日期和下载URL。通过GROBID处理后,研究者们进一步清洗了数据,去除了无关信息,并标准化了文本格式,以便于后续处理。
代理组成: AI代理的架构包括了几个关键组件。首先是检索增强生成(RAG)数据库的创建,它结合了大型语言模型(LLM)的生成能力和文档检索,以提供特定领域的医学知识。RAG框架涉及将原始文本数据转换为数值向量表示(即嵌入),并将这些嵌入存储在向量数据库中,与元数据和原始文本一起进行索引。研究者们使用了OpenAI的文本嵌入模型来生成不同长度文本片段的嵌入,并将它们存储在本地向量数据库中,以便进行高效的查找操作。
代理的另一个重要组成部分是工具的利用。研究者们为LLM配备了一系列工具,包括通过Google自定义搜索API进行网络搜索、定制PubMed查询、调用GPT-4 Vision模型进行医学影像分析、MedSAM进行图像分割,以及访问OncoKB数据库获取精准肿瘤学信息。这些工具被集成到代理中,使其能够执行复杂的任务,如分析CT或MRI扫描、预测组织病理学幻灯片中的遗传变异等。
代理的检索和响应生成模块使用DSPy库来实现LLM调用的模块化组合。代理接收原始患者上下文、提出的问题以及工具应用的结果作为输入。然后,它使用链式推理将初始用户查询分解为更细粒度的子查询,并从向量数据库中检索与每个子查询最相关的文档段落。这些数据被组合、去重、重新排序,然后转发到LLM以生成最终答案。在生成答案之前,代理被指导生成一个逐步策略,包括识别可能有助于细化和个性化建议的缺失信息。

图2详细展示了AI代理在患者案例评估中的完整流程及其有效性。以患者X的情况为例,这一部分详细说明了代理如何接收输入、部署工具,并最终生成响应。
在最初的“工具”阶段,AI代理首先从患者数据中识别出肿瘤的位置,并使用MedSAM工具生成分割掩模。通过测量分割区域的面积,代理能够计算出肿瘤随时间的进展情况。在这个案例中,模型计算出肿瘤面积增加了3.89倍,这表明了病情的恶化。
接着,AI代理参考了OncoKB数据库中的突变信息,这些信息来自患者的背景(包括BRAF V600E和CD74-ROS1的变异融合)。此外,代理还通过PubMed和Google进行了文献搜索,以获取更多相关信息。在组织学建模方面,代理采用了简化的STAMP流程,其中省去了计算特征向量的步骤,这是为了便于处理而提前完成的。代理执行的第二步是选择感兴趣的目标和患者数据的位置,并执行相应的视觉变换器模型。
随后的阶段涉及通过RAG(检索增强生成)进行数据检索,并生成最终的响应。图2的Panel B展示了由四名医学专家进行的手动评估的结果。评估指标包括“工具使用”、“完整性”、“有帮助性”、“正确性”、“错误性”和“有害性”。
“工具使用”指标反映了代理实际使用的工具与预期使用工具的比例(32/33),意味着代理在33次预期中成功使用了32次工具。“完整性”(63/67)衡量的是代理准确识别或提出的专家预期答案的比例。“有帮助性”量化了模型实际回答的用户所有问题或指令中的子问题的比例(33/37)。“正确性”(131/140)、“错误性”(6/140)和“有害性”(3/140)分别代表相对于总响应数量的准确、不正确(但无害)和有害响应的比例。这里,每个回答都被视为一个段落。
评估还衡量了提供的引用是否正确(141/171)、不相关(11/171,引用内容与模型的陈述不对应)或错误(3/171)。这些结果显示了AI代理在患者案例评估中的全面性能,并且是通过所有观察者的多数票得出的结果。
为了验证系统的性能,研究者们设计了一系列临床肿瘤学场景,这些场景模拟了真实的患者护理工作流程。在这些场景中,AI代理需要处理包括文本、图像和基因数据在内的多模态数据,并提供决策支持。研究结果表明,AI代理在选择和使用适当的工具方面表现出了97%的高准确率,这意味着它能够根据患者情况正确选择需要使用的工具。
在得出正确结论方面,AI代理的准确率达到了93.6%,这表明它能够基于输入的多模态数据,做出符合临床实践的准确判断。此外,AI代理在提供完整和有帮助的建议方面也表现出色,分别达到了94%和89.2%的准确率。这意味着它不仅能够提供全面的建议,而且这些建议对临床决策是有帮助的。
当接到指示时,AI代理能够一贯地引用相关文献,准确率达到了82.5%。这一点非常重要,因为它确保了AI代理提供的决策支持是基于最新的医学证据,有助于提高患者护理的质量。
论文中还提到了一种新的基准策略,旨在克服现有生物医学评估方法的局限性,这些方法往往只针对单一或两种数据模态,并且通常局限于封闭的问题和答案格式。为了更全面地评估所提出的AI系统性能,研究者们开发了一种新的评估方法,它基于一个包含11个现实且多维的患者案例的数据集,这些案例专注于胃肠道肿瘤学。
这个数据集的设计允许AI代理在一个更加开放和复杂的环境中进行评估,更贴近真实的临床情况。每个患者案例都构建得非常详细,包括了患者的医疗历史、诊断、重要的医疗事件以及以前的治疗信息。此外,每个案例还配备了CT或MRI影像资料,这些影像资料可以是连续的随访扫描,用于评估疾病进展或稳定性,或者是同时段的扫描,用于评估肝脏和肺部的状况。组织病理学图像也被包括在内,以提供更全面的病情信息。
为了全面评估所提出的AI系统的性能,研究者们设计了一种新颖的临床案例生成方法。这种方法旨在模拟真实的临床环境,以便更准确地测试AI代理在处理复杂医疗情况时的能力。生成的临床案例专门集中在胃肠道肿瘤学上,包括结直肠癌、胰腺癌、胆管癌和肝细胞癌等多种癌症类型。
每个案例都构建了一个全面的虚构患者档案,其中不仅包括了患者的简要医疗史,如诊断、重要的医疗事件和既往治疗,还结合了CT或MRI影像资料,这些影像资料可能是连续的随访分期扫描,也可能是同时对肝脏和肺部进行的分期扫描。这些影像资料来自网络、癌症影像档案库(Cancer Imaging Archive)以及德国亚琛大学医院诊断和介入放射科的内部资源。在11个案例中有7个包含了组织病理学图像,这些图像资料来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)。
为了评估AI模型处理复杂信息的能力,研究者们在每个患者描述中都加入了有关基因组变异的信息,如突变和基因融合。这些信息对于制定个性化治疗计划至关重要。每个患者案例都设计了多个子任务、子问题和指令,要求AI模型在每一轮中平均处理三到四个子任务。
研究者们开发了一个结构化的评估框架,以系统地评估AI代理在处理临床案例时的表现。这个框架受到了Singhal等人方法的启发,专注于评估代理使用工具的情况、模型产生的文本输出质量,以及提供准确引用的能力。
通过这种详细的人类评估,研究者们能够确保AI代理在提供临床决策支持时,不仅能够准确地应用工具和处理多模态数据,还能够生成高质量、准确、全面且有帮助的输出,并能够适当地引用相关文献来支持其建议。这对于AI系统在临床环境中的实际应用和接受度至关重要。
论文链接:https://arxiv.org/pdf/2404.04667


![CLion2024 for Mac[po] C和C++的跨平台解代码编辑器](https://img-blog.csdnimg.cn/direct/17479a8bf98348d98d9d82f478edba5a.png)