PEFT库进行ChatGLM3-6B模型LORA高效微调
- LORA微调ChatGLM3-6B模型
- 安装相关库
- 使用ChatGLM3-6B
- 模型GPU显存占用
- 准备数据集
- 加载模型
- 加载数据集
- 数据处理
- 数据集处理
- 配置LoRA
- 配置训练超参数
- 开始训练
- 保存LoRA模型
- 模型推理
- 从新加载
- 合并模型
- 使用微调后的模型
LORA微调ChatGLM3-6B模型
本文基于transformers、peft等框架,对ChatGLM3-6B模型进行Lora微调。
LORA(Low-Rank Adaptation)是一种高效的模型微调技术,它可以通过在预训练模型上添加额外的低秩权重矩阵来微调模型,从而仅需更新很少的参数即可获得良好的微调性能。这相比于全量微调大幅减少了训练时间和计算资源的消耗。
安装相关库
pip install ransformers==4.37.2 peft==0.8.0 accelerate==0.27.0 bitsandbytes
使用ChatGLM3-6B
直接调用ChatGLM3-6B模型来生成对话
from transformers import AutoTokenizer, AutoModelmodel_id = "/root/work/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
#model = AutoModel.from_pretrained(model_id, trust_remote_code=True).half().cuda()
model = AutoModel.from_pretrained(model_id, trust_remote_code=True, device='cuda')model = model.eval()
response, history = model.chat(tokenizer, "你好", history=history)
print(response)
模型GPU显存占用
默认情况下,模型以半精度(float16)加载,模型权重需要大概 13GB显存。
获取当前模型占用的GPU显存
memory_bytes = model.get_memory_footprint()
# 转换为GB
memory_gb = memory_footprint_bytes / (1024 ** 3)
print(f"{memory_gb :.2f}GB")
注意:与实际进程占用有差异,差值为预留给PyTorch的显存
准备数据集
准备数据集其实就是指令集构建,LLM的微调一般指指令微调过程。所谓指令微调,就是使用的微调数据格式、形式。
训练目标是让模型具有理解并遵循用户指令的能力。因此在指令集构建时,应该针对目标任务,针对性的构建任务指令集。
这里使用alpaca格式的数据集,格式形式如下:
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)",},"system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]
]
instruction:用户指令,要求AI执行的任务或问题input:用户输入,是完成用户指令所必须的输入内容,就是执行指令所需的具体信息或上下文output:模型回答,根据给定的指令和输入生成答案
这里根据企业私有文档数据,生成相关格式的训练数据集,大概格式如下:
[{"instruction": "内退条件是什么?","input": "","output": "内退条件包括与公司签订正式劳动合同并连续工作满20年及以上,以及距离法定退休年龄不足5年。特殊工种符合国家相关规定可提前退休的也可在退休前5年内提出内退申请。"},
]
加载模型
from transformers import AutoModel, AutoTokenizermodel_id = "/root/work/chatglm3-6b"
model = AutoModel.from_pretrained(model_id, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
加载数据集
from datasets import load_datasetdata_id="/root/work/jupyterlab/zd.json"
dataset = load_dataset("json", data_files=data_id)
print(dataset["train"])
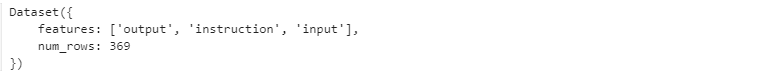
数据处理
Lora训练数据是需要经过tokenize编码处理,然后后再输入模型进行训练。一般需要将输入文本编码为
input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
需要定义一个预处理函数,这个函数用于对每一个样本,编码其输入、输出文本并返回一个编码后的字典。
# tokenize_func 函数
def tokenize_func(example, tokenizer, ignore_label_id=-100):"""对单个数据样本进行tokenize处理。参数:example (dict): 包含'content'和'summary'键的字典,代表训练数据的一个样本。tokenizer (transformers.PreTrainedTokenizer): 用于tokenize文本的tokenizer。ignore_label_id (int, optional): 在label中用于填充的忽略ID,默认为-100。返回:dict: 包含'tokenized_input_ids'和'labels'的字典,用于模型训练。"""prompt_text = '' # 所有数据前的指令文本max_input_length = 512 # 输入的最大长度max_output_length = 1536 # 输出的最大长度# 构建问题文本question = prompt_text + example['instruction']if example.get('input', None) and example['input'].strip():question += f'\n{example["input"]}'# 构建答案文本answer = example['output']# 对问题和答案文本进行tokenize处理q_ids = tokenizer.encode(text=question, add_special_tokens=False)a_ids = tokenizer.encode(text=answer, add_special_tokens=False)# 如果tokenize后的长度超过最大长度限制,则进行截断if len(q_ids) > max_input_length - 2: # 保留空间给gmask和bos标记q_ids = q_ids[:max_input_length - 2]if len(a_ids) > max_output_length - 1: # 保留空间给eos标记a_ids = a_ids[:max_output_length - 1]# 构建模型的输入格式input_ids = tokenizer.build_inputs_with_special_tokens(q_ids, a_ids)question_length = len(q_ids) + 2 # 加上gmask和bos标记# 构建标签,对于问题部分的输入使用ignore_label_id进行填充labels = [ignore_label_id] * question_length + input_ids[question_length:]return {'input_ids': input_ids, 'labels': labels}
进行数据映射处理,同时删除特定列
# 获取 'train' 部分的列名
column_names = dataset['train'].column_names # 使用lambda函数调用tokenize_func函数,并传入example和tokenizer作为参数
tokenized_dataset = dataset['train'].map(lambda example: tokenize_func(example, tokenizer),batched=False, # 不按批次处理remove_columns=column_names # 移除特定列(column_names中指定的列)
)
执行print(tokenized_dataset[0]),打印tokenize处理结果

数据集处理
还需要使用一个数据收集器,可以使用transformers 中的DataCollatorForSeq2Seq数据收集器
from transformers import DataCollatorForSeq2Seqdata_collator = DataCollatorForSeq2Seq(tokenizer,model=model,label_pad_token_id=-100,pad_to_multiple_of=None,padding=True
)
或者自定义实现一个数据收集器
import torch
from typing import List, Dict, Optional# DataCollatorForChatGLM 类
class DataCollatorForChatGLM:"""用于处理批量数据的DataCollator,尤其是在使用 ChatGLM 模型时。该类负责将多个数据样本(tokenized input)合并为一个批量,并在必要时进行填充(padding)。属性:pad_token_id (int): 用于填充(padding)的token ID。max_length (int): 单个批量数据的最大长度限制。ignore_label_id (int): 在标签中用于填充的ID。"""def __init__(self, pad_token_id: int, max_length: int = 2048, ignore_label_id: int = -100):"""初始化DataCollator。参数:pad_token_id (int): 用于填充(padding)的token ID。max_length (int): 单个批量数据的最大长度限制。ignore_label_id (int): 在标签中用于填充的ID,默认为-100。"""self.pad_token_id = pad_token_idself.ignore_label_id = ignore_label_idself.max_length = max_lengthdef __call__(self, batch_data: List[Dict[str, List]]) -> Dict[str, torch.Tensor]:"""处理批量数据。参数:batch_data (List[Dict[str, List]]): 包含多个样本的字典列表。返回:Dict[str, torch.Tensor]: 包含处理后的批量数据的字典。"""# 计算批量中每个样本的长度len_list = [len(d['input_ids']) for d in batch_data]batch_max_len = max(len_list) # 找到最长的样本长度input_ids, labels = [], []for len_of_d, d in sorted(zip(len_list, batch_data), key=lambda x: -x[0]):pad_len = batch_max_len - len_of_d # 计算需要填充的长度# 添加填充,并确保数据长度不超过最大长度限制ids = d['input_ids'] + [self.pad_token_id] * pad_lenlabel = d['labels'] + [self.ignore_label_id] * pad_lenif batch_max_len > self.max_length:ids = ids[:self.max_length]label = label[:self.max_length]input_ids.append(torch.LongTensor(ids))labels.append(torch.LongTensor(label))# 将处理后的数据堆叠成一个tensorinput_ids = torch.stack(input_ids)labels = torch.stack(labels)return {'input_ids': input_ids, 'labels': labels}
data_collator = DataCollatorForChatGLM(pad_token_id=tokenizer.pad_token_id)
配置LoRA
在peft中使用LoRA非常简单。借助PeftModel抽象,可以快速将低秩适配器(LoRA)应用到任意模型中。
在初始化相应的微调配置类(LoraConfig)时,需要显式指定在哪些层新增适配器(Adapter),并将其设置正确。
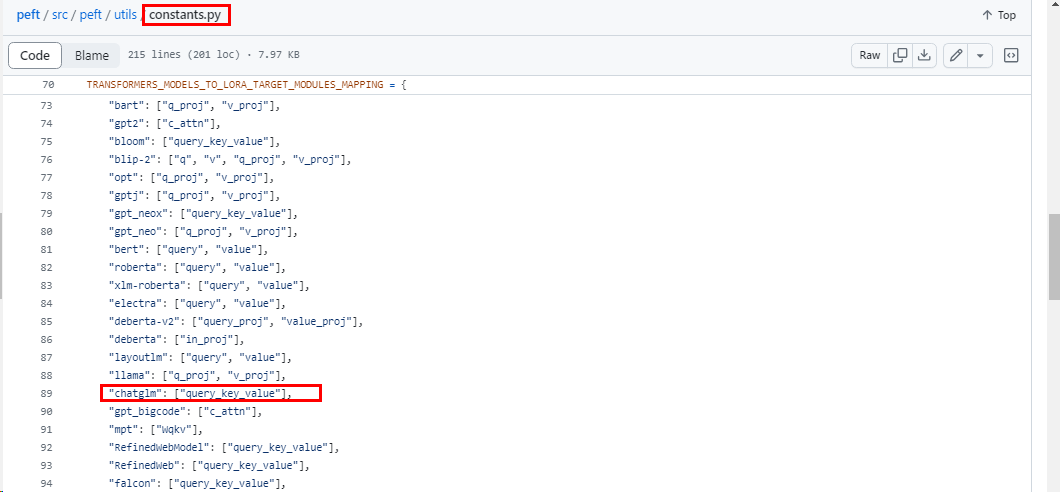
ChatGLM3-6B模型通过以下方式获取需要训练的模型层的名字
from peft.utils import TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPINGtarget_modules = TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING['chatglm']
在PEFT库的 constants.py 文件中定义了不同的 PEFT 方法,在各类大模型上的微调适配模块。
主要是配置LoraConfig类,其中可以设置很多参数,但主要参数只有几个
# 从peft库导入LoraConfig和get_peft_model函数
from peft import LoraConfig, get_peft_model, TaskType# 创建一个LoraConfig对象,用于设置LoRA(Low-Rank Adaptation)的配置参数
config = LoraConfig(r=8, # LoRA的秩,影响LoRA矩阵的大小lora_alpha=32, # LoRA适应的比例因子# 指定需要训练的模型层的名字,不同模型对应层的名字不同# target_modules=["query_key_value"],target_modules=target_modules,lora_dropout=0.05, # 在LoRA模块中使用的dropout率bias="none", # 设置bias的使用方式,这里没有使用bias# task_type="CAUSAL_LM" # 任务类型,这里设置为因果(自回归)语言模型task_type=TaskType.CAUSAL_LM
)# 使用get_peft_model函数和给定的配置来获取一个PEFT模型
model = get_peft_model(model, config)# 打印出模型中可训练的参数
model.print_trainable_parameters()

配置训练超参数
配置训练超参数使用TrainingArguments类,可配置参数同样有很多,但主要参数也是只有几个
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(output_dir=f"{model_id}-lora", # 指定模型输出和保存的目录per_device_train_batch_size=4, # 每个设备上的训练批量大小learning_rate=2e-4, # 学习率fp16=True, # 启用混合精度训练,可以提高训练速度,同时减少内存使用logging_steps=20, # 指定日志记录的步长,用于跟踪训练进度save_strategy="steps", # 模型保存策略save_steps=50, # 模型保存步数# max_steps=50, # 最大训练步长num_train_epochs=1 # 训练的总轮数)
查看添加LoRA模块后的模型
print(model)
开始训练
配置model、参数、数据集后就可以进行训练了
trainer = Trainer(model=model, # 指定训练时使用的模型train_dataset=tokenized_dataset, # 指定训练数据集args=training_args,data_collator=data_collator,
)model.use_cache = False
# trainer.train()
with torch.autocast("cuda"): trainer.train()

注意:
执行
trainer.train()时出现异常,参考:bitsandbytes的issues
保存LoRA模型
lora_model_path = "lora/chatglm3-6b-int8"
trainer.model.save_pretrained(lora_model_path )
#model.save_pretrained(lora_model_path )

模型推理
使用LoRA模型,进行模型推理
lora_model = trainer.model
1.文本补全
text = "人力资源部根据各部门人员"inputs = tokenizer(text, return_tensors="pt").to(0)out = lora_model.generate(**inputs, max_new_tokens=500)
print(tokenizer.decode(out[0], skip_special_tokens=True))

2.问答对话
from peft import PeftModelinput_text = '公司的招聘需求是如何提出的?'
model.eval()
response, history = lora_model.chat(tokenizer=tokenizer, query=input_text)
print(f'ChatGLM3-6B 微调后回答: \n{response}')

从新加载
加载源model与tokenizer,使用PeftModel合并源model与PEFT微调后的参数,然后进行推理测试。
from peft import PeftModel
from transformers import AutoModel, AutoTokenizermodel_path="/root/work/chatglm3-6b"
peft_model_checkpoint_path="./chatglm3-6b-lora/checkpoint-50"model = AutoModel.from_pretrained(model_path, trust_remote_code=True, low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)# 将训练所得的LoRa权重加载起来
p_model = PeftModel.from_pretrained(model, model_id=peft_model_checkpoint_path) p_model = p_model.cuda()
response, history = p_model.chat(tokenizer, "内退条件是什么?", history=[])
print(response)
合并模型
将lora权重合并到大模型中,将模型参数加载为16位浮点数
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch model_path="/root/work/chatglm3-6b"
peft_model_path="./lora/chatglm3-6b-int8"
save_path = "chatglm3-6b-lora"tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto")
model = PeftModel.from_pretrained(model, peft_model_path)
model = model.merge_and_unload()tokenizer.save_pretrained(save_path)
model.save_pretrained(save_path)
查看合并文件
使用微调后的模型
from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("chatglm3-6b-lora", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm3-6b-lora", trust_remote_code=True, device='cuda')model = model.eval()
response, history = model.chat(tokenizer, "内退条件是什么?", history=[])
print(response)